
오늘은 다른 사이트의 데이터를 가지고 오는 Scrapping 방식과 Crawling 방식을 알아보겠다.
가장 간단하게 두 방식을 구분해보자면 아래와 같다.
- Scrapping : 다른 사이트 정보를
한 번 가져온다. - Crawling : 다른 사이트 정보를
꾸준히 가져온다.
📌 Scrapping
Scarpping 받아오는 방법 2가지
-
포스트맨, axios로 아래와 같이 받아오기
- 원하는 정보를 뽑은 다음 그것을 저장하여 사용하면 된다. 아래 이미지와 같이 네이버의 코드를 포스트맨에서 get방식으로 html코드를 뽑아올 수 있다. 여기에서 'https://www.naver.com' 은 endpoint가 되는 것이다.
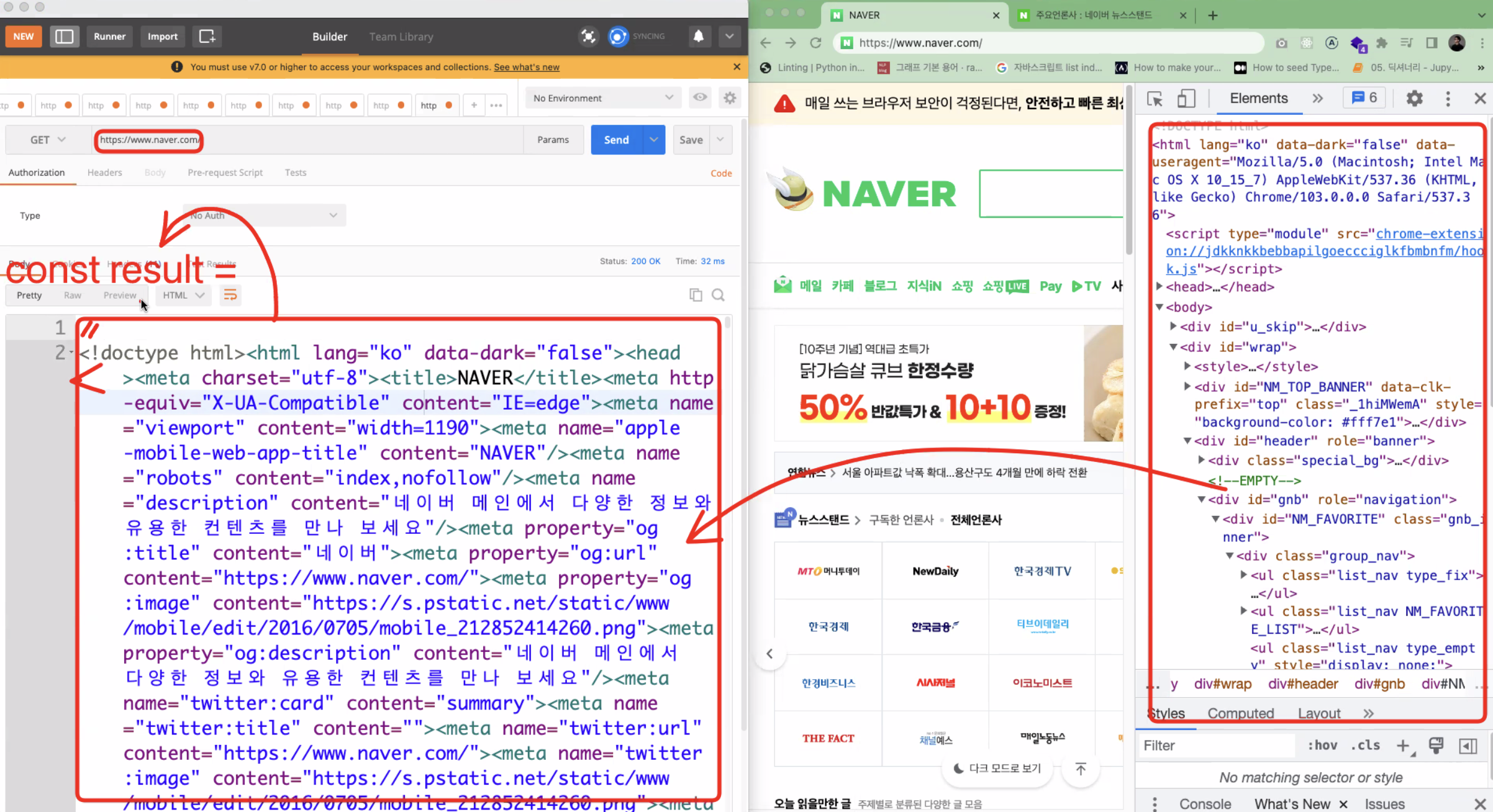
-
터미널에서 curl로 html코드를 받아오기
curl https://www.naver.com
언제 사용할까?
- 반복적으로 데이터를 취합하지 않아도 될 경우 사용한다.
- ex) 디스코드에서 공유하고 싶은 주소를 입력한 후 엔터를 친 순간 디스코드 로직에서 네이버쪽으로 스크랩핑해서 가져온 데이터를 뿌려준다.

Cheerio
- 데이터를 뽑을 때 알고리즘을 만들어 뽑아내어 저장을 해줘야하는데, 이 과정을 쉽게끔 도와주는 라이브러리가 바로 Cheerio 이다.
- Cheerio docs 를 참고하여 아래와 같이 작성하여 해당 html에서 원하는 데이터를 가져올 수 있다.
export const createPreferSiteData = async ({ prefer }) => {
const page = await axios.get(prefer)
let result = {
title: '',
description: '',
image: ''
}
const $ = cheerio.load(page.data) //result랑 result.data랑 크게 달라보이지 않음..
$(`meta`).each((_, el) => {
if($(el).attr("property")?.includes("og:title")) {
result.title = $(el).attr("content")
}
if($(el).attr("property")?.includes("og:description")) {
result.description = $(el).attr("content")
}
if($(el).attr("property")?.includes("og:image")) {
result.image = $(el).attr("content")
}
})
return result
}
📌 Crawling
- Crawling 도구들은 브라우저(크로미옴)를 내장하고 있다. 실제 접속하코 클릭할 수 있는 브라우저 창이 있다.
- 크로미옴 브라우저를 확장하여 만든 것이 크롬이다.
언제 사용할까?
- 여러 사진들, 상품 정보들, 주식 정보들 등을 크롤링하여 유용한 상품으로 취합해서 서비스를 할 수 있다.
Puppeteer
- 크롤링에 사용할 수 있는 라이브러리이다.
- Puppeteer docs 를 참고하여 아래와 같이 작성하여 원하는 데이터를 가져올 수 있다.
const coffeeCrawling = async () => {
const browser = await puppeteer.launch()
const page = await browser.newPage()
await page.goto('https://www.starbucks.co.kr/menu/drink_list.do')
await page.waitForTimeout(1000)
let i
for(i=1; i<=32; i++) {
const name = await page.$eval(
`#container > div.content > div.product_result_wrap.product_result_wrap01 > div > dl > dd:nth-child(2) > div.product_list > dl > dd:nth-child(6) > ul > li:nth-child(${i}) > dl > dd`,
(el) => el.textContent
)
const img = await page.$eval(
`#container > div.content > div.product_result_wrap.product_result_wrap01 > div > dl > dd:nth-child(2) > div.product_list > dl > dd:nth-child(6) > ul > li:nth-child(${i}) > dl > dt > a > img`,
(el) => el.getAttribute('src')
)
const coffee = new Coffee({
name,
img
})
await coffee.save()
}
if(i === 33) {
console.log(`총 ${i-1}개의 커피 데이터 가져오기 성공`)
}
await browser.close()
}
코딩은 역시 재밌군