
우리가 리액트를 이용해 작성하고 있는 프론트엔트 코드가 시간이 지나 규모가 커지더라도 생산성을 유지할 수 있도록 하려면 어떻게 해야 할까요? 어니언 아키텍처를 도입하는 것이 그 방법들 중 하나가 될 수 있을 것입니다. 어니언 아키텍처는 아주 간단한 제약 사항만을 요구하고, 불변성과 함수형 컴포넌트가 기반이 되는 리액트와 잘 어울립니다.
어니언 아키텍처
생산성
생산성이 높은 코드를 설명하기 위해 가독성, 유지보수성 등의 용어를 동원해 말할 수 있지만 모든 용어를 관통하는 개념은 ‘느슨한 결합’일 것입니다. 느슨한 결함은 코드의 부분들 사이의 의존성을 최소화하는 것, 다르게 말하면 어떤 부분의 변화가 다른 부분에 영향을 주는 것을 최소화하는 것입니다.

순수 함수의 최대화
어니언 아키텍처는 순수함수(동일한 입력에 대해 동일한 결과를 리턴하는 함수)를 최대한 많이 작성함으로써 이 목표를 달성하고자 합니다. 리액트는 순수함수로 취급할 수 있는 함수형 컴포넌트를 중심으로 코드를 작성하고, 상태의 불변성을 도입하고 있기 때문에, 어니언 아키텍처를 적용해 사용하기에 좋은 라이브러리라고 할 수 있습니다.
어니언 아키텍처의 계층
어니언 아키텍처는, 특정한 계층을 요구하지는 않지만, 기본적으로는 크게 인터랙션 계층과 도메인 계층으로 구성됩니다. 인터랙션 계층은 데이터베이스를 포함한 ‘전역 상태’로부터 데이터를 가져오고 사용자에게 데이터를 보여주고 사용자로부터 입력을 받는 등의 모든 외부와의 상호작용과 직접적으로 관련된 코드를 포함하는 계층입니다. 도메인 계층은 도메인과 관련된 코드, 더 포괄적으로 말해서 인터랙션 계층이 아닌 모든 코드를 포함하는 계층입니다.
리액트 프로젝트에서의 계층
일반적으로 말해서 인터랙션 계층은 비순수함수로, 도메인 계층은 순수함수로 이루어져 있습니다. 하지만 리액트를 사용한다면 사용자에게 데이터를 보여주는 부분이 순수함수일 수 있기 때문에, 인터랙션 계층을 순수함수로 이루어진 프리젠터 계층과 비순수함수로 이루어진 컨테이너 계층으로 나눌 수 있습니다. 그래서 어니언 아키텍처를 사용한 리액트 프로젝트에서 생산성 향상을 위해 할 일은 컨테이너 계층의 코드 양을 최소화하는 것입니다. 더불어 도메인 계층의 코드를 최대화하면 styled-component와 같은 UI 라이브를 다른 라이브러리로 교체할 때 부담을 줄일 수 있습니다.

함수의 위계화
‘순수함수의 최대화’와 함께 어니언 아키텍처에서 중요한 점은 ‘함수의 위계화’입니다. ‘함수의 위계화’란 호출하는 함수가 호출되는 함수보다 더 높은 계층에 속한다는 것, 다르게 말하면 상위 계층의 함수는 하위 계층의 함수만을 호출해야 한다는 것입니다. (’함수의 위계화’보다는 ‘함수의 계층화’가 더 적합할 수 있지만 ‘계층’이라는 용어가 ‘위계’라는 의미를 포함하지 않는 경우도 있기 때문에, ‘위계’라는 용어를 선택했습니다.)
리액트 프로젝트의 경우, 프리젠터는 도메인 계층의 함수들을 호출하고, 컨테이너는 프리젠터 계층의 함수들을 호출하기 때문에, 가장 큰 규모의 계층들의 위계는 컨테이너, 프리젠터, 도메인의 순서가 됩니다. (아래의 호출 그래프에서 화살표는, 화살표 꼬리 쪽의 함수가 화살표 머리 쪽의 함수를 호출한다는 것을 의미합니다.)

함수 위계화의 특징: 유지보수성
‘함수의 위계화’의 가장 중요한 특징은 상위 계층의 변경이 하위 계층에 영향을 줄 수 없다는 점입니다. 어떤 계층의 코드를 수정하면 그 계층보다 상위의 계층에만 영향을 미치기 때문에 유지보수성이 좋아집니다. 게다가 가장 상위로부터 수정할 코드의 계층까지의 계층의 수가 그 변경이 미치는 영향의 크기를 말해주기 때문에, 코드 변경의 영향을 쉽게 파악할 수 있습니다.
리액트 프로젝트의 경우, 예를 들어 styled-component를 다른 라이브러리로 변경하는 경우, 도메인 계층에 미칠 영향은 전혀 고려할 필요가 없이, 컨테이너에 대한 영향만을 고려하면 됩니다.
어니언 아키텍처에서는, 하위 계층일수록 코드 전체에 미치는 영향이 크기 때문에, 가능하면 하위 계층의 코드는 수정하지 않도록 해야 합니다. 하지만 수정해야 하는 경우를 대비해 ‘추상화 벽’을 설정할 수 있습니다. ‘추상화 벽’이란 상위 계층이 호출할 수 있는 가장 하위의 계층을 말합니다. ‘추상화 벽’을 설정하면 하위 계층이 변경되었을 때 영향을 미칠 수 있는 상위 계층의 한계를 설정하는 것이기 때문에 하위 계층의 변경에 대한 영향을 줄일 수 있습니다.
리액트 프로젝트의 경우, 도메인에 대한 변경이 프리젠터와 컨테이너에 영향을 미치지 않도록 도메인 계층에 속한 계층 중 가장 상위 계층을 추상화 벽으로 설정할 수 있습니다.

함수 위계화의 특징: 가독성
‘함수의 위계화’는 코드의 가독성을 높이는데도 기여합니다. 가독성과 관련된 특징은 ‘관심사의 균질성’(코드의 각 부분이 비슷한 관심사와 관련되어 있음)이라고 말할 수 있을텐데, 관심사는 코드의 ‘일반성’과 크게 관련이 있습니다. 예를 들어, 객체의 특정 값을 변경한 새로운 객체를 리턴하는 함수는 일반적으로 사용될 수 있지만(높은 일반성), 제품의 가격을 변경하는 코드는 구체적인 상황에서 사용됩니다(낮은 일반성).
일반성이 서로 다른 코드들이 동일한 함수에 포함되어 있다면 그 함수의 가독성이 낮다고 말할 수 있습니다. ‘함수의 위계화’는, 마치 햇빛이 분광기를 통과하면 무지개색들로 분해되는 것과 같이, 함수들을 비슷한 일반성을 가진 것들로 정렬시킵니다. 동일한 계층에 속한 함수들은 비슷한 일반성을 가진 함수들로 이루어지고, 가까운 하위 계층의 함수들로 작성된 코드는 각 부분이 유사한 일반성을 가진 코드가 됩니다.
리액트 프로젝트의 경우, 프리젠터 계층에 속한 함수들을 도메인 계층에서 가장 상위 계층에 속한 함수들로 작성한다면, 코드의 논리 흐름을 파악하기가 쉬워질 것입니다. 예를 들어, 제품의 가격을 변경하는 UI를 제공하는 프리젠터에서 객체의 특정 값을 변경시키는 코드를 읽게 되는 일은 발생하지 않을 것입니다.

예시 코드
다음의 코드들은, 결제 방법에 대한 데이터를 서버로부터 가져와, 결제 방법을 선택할 수 있는 라디오 버튼을 렌더링하는 기능을, 어니언 아키텍처를 적용해 작성한 것입니다. (’잘 알려진 UI 패턴을 사용하여 리액트 애플리케이션 모듈화하기’에 공개된 코드를 참고해 일부 변형시켰습니다.)
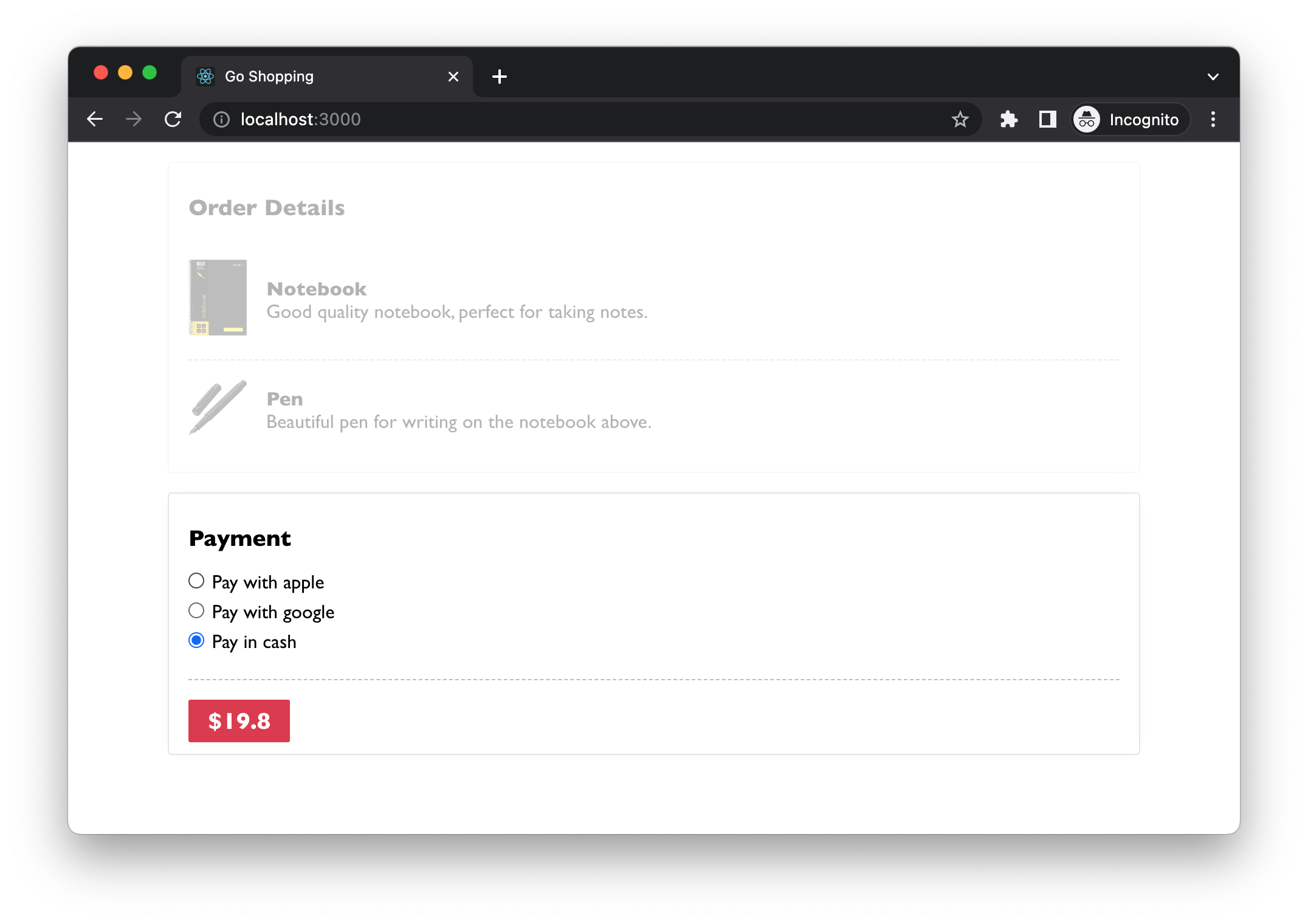 출처: 잘 알려진 UI 패턴을 사용하여 리액트 애플리케이션 모듈화하기
출처: 잘 알려진 UI 패턴을 사용하여 리액트 애플리케이션 모듈화하기
컨테이너 계층
컨테이너 계층은 3개의 계층으로 이루어져 있고, 각 계층은 하나의 비순수 함수로 이루어져 있으며, 각 함수는 작은 규모의 명확한 하나의 기능을 수행합니다.
Payment는 가장 상위의 함수로서 결제 방법에 대한 데이터를 가져와, 결제 방법을 렌더링하는 함수로 전달합니다.usePaymentMethods는 서버로부터 가져온 결제 방법에 대한 데이터를 로컬 상태에 저장합니다.fetchPaymentMethods는 서버로부터 결제 방법에 대한 데이터를 가져와 그 데이터를 리턴합니다.
// 계층 1
export const Payment = () => {
const { paymentMethods } = usePaymentMethods();
return <PaymentMethodOptions methods={paymentMethods} />;
};
// 계층 2
const usePaymentMethods = () => {
const [paymentMethods, setPaymentMethods] = useState<PaymentMethods>(
createPaymentMethods()
);
useEffect(() => {
fetchPaymentMethods().then((methods) => setPaymentMethods(methods));
}, []);
return { paymentMethods };
};
// 계층 3
const fetchPaymentMethods = async () => {
const response = await fetch("<https://online-ordering.com/api/payment-methods>");
const remoteMethods: RemotePaymentMethod[] = await response.json();
return createPaymentMethods(remoteMethods);
};프리젠터 계층
프리젠터 계층은 2개의 계층으로 이루어져있고 각 계층은 하나의 순수 함수로 이루어져 있습니다.
PaymentMethodOptions은 결제 방법들에 대한 데이터를 입력받아 각 결제 방법을 렌더링합니다.MethodOption은 하나의 결제 방법에 대한 데이터를 입력받아 라디오 버튼으로 렌더링합니다.
// 계층 4
const PaymentMethodOptions = ({ methods }: { methods: PaymentMethods }) => {
const map = mapPaymentMethods(methods);
const options = map((method) => {
const read = readPaymentMethod(method);
return <MethodOption key={read("provider")} method={method} />;
});
return <div>{options}</div>;
};
// 계층 5
const MethodOption = ({ method }: { method: PaymentMethod }) => {
const read = readPaymentMethod(method);
return (
<label>
<input
type="radio"
name="payment"
value={read("provider")}
defaultChecked={read("isDefaultMethod")}
/>
<span>{read("label")}</span>
</label>
);
};도메인 계층
도메인 계층은 1개의 계층으로 이루어져 있고, 3개의 순수 함수로 이루어져 있습니다.
createPaymentMethods는 서버로부터 가져온 결제 방법 데이터(RemotePaymentMethods)를 적절한 형태(PaymentMethods)로 변형합니다.mapPaymentMethods은 결제 방법 데이터(PaymentMethods)를 순회할 수 있는 기능을 제공하는 함수입니다.readPaymentMethod은 하나의 결제 방법 데이터(PaymentMethods)에서 특정 정보를 읽어오는 함수입니다.
mapPaymentMethods와 readPaymentMethod을 작성한 이유는 무엇일까요? 자바스크립트 배열과 객체의 기본 메쏘드를 이용한 것 뿐인데 말입니다. 그 두 함수를 작성한 이유는, 그렇게 하면 데이터의 형태를 상위 계층에 숨길 수 있기 때문입니다. 상위 계층에서 데이터 형태를 알고 값을 읽어오는 경우에는 데이터 형태가 변경된 경우에 그것이 끼치는 영향이 아주 크기 때문입니다. 예를 들어, PaymentMethod를 어떤 이유로 객체에서 Map으로 변경한다면 더 이상 배열의 기본 메쏘드를 사용할 수 없기 때문에, method.key의 형태의 코드를 모두 method.get(key)의 형태로 변경해야만 합니다.
// 계층 6
const createPaymentMethods = (remoteMethods?: RemotePaymentMethods) => {
if (remoteMethods && remoteMethods.length > 0) {
const methods: PaymentMethod[] = remoteMethods.map(({ name }) => ({
provider: name,
label: `Pay with ${name}`,
isDefaultMethod: false,
}));
return [
...methods,
{ provider: "cash", label: "Pay in cash", isDefaultMethod: true },
];
} else {
return [];
}
};
const mapPaymentMethods =
(methods: PaymentMethods) =>
<T,>(callback: (method: PaymentMethod) => T) =>
methods.map(callback);
const readPaymentMethod =
(method: PaymentMethod) =>
<T extends keyof PaymentMethod>(name: T) =>
method[name];호출 그래프
위 코드에 대한 호출 그래프를 그리면 다음과 같습니다. 이 그래프를 통해 함수 호출의 방향이 순환하지 않고 위에서 아래로 흐른다는 것을 알 수 있습니다. 그래프에서 상위의 함수들의 변경은 하위의 함수들에 아무런 영향을 미칠 수 없습니다. 앞에서 말씀드렸듯이 어니언 아키텍처의 이러한 특성 때문에 유지보수성과 가독성 등이 좋아지고 결국 생산성 향상으로 이어집니다.

파일 구조
어니언 아키텍처를 리액트 프로젝트에 적용하는데 한 가지 어려운 점은 코드의 규모가 조금만 커져도 각 함수의 계층을 파악하기가 쉽지 않다는 점입니다. 이를 해결할 수 있는 한가지 방법은 동일한 파일에 있는 함수는 동일한 계층에 포함되어 있는 것으로, 동일한 폴더에 있는 함수는 동일한 계층에 포함된 것으로 간주하고, 하위 계층의 코드는 하위 폴더에 위치시키는 것입니다. 하지만 이 방법의 단점은 폴더의 깊이가 너무 깊어질 수 있다는 점입니다.
/
┗ container
┣ componentA
┗ componentB
┗ presenter
┗ componentC
┗ componentD
┗ domain이 단점을 해결하기 위해 폴더는 최대한 ‘평평하게’ 유지하되 계층의 위계에 대한 정보를 어딘가에 작성해 둘 수 있습니다. 하지만 코드의 규모가 커지만 계층의 위계에 대한 정보를 알고 있다고 하더라도 파악하기가 쉽지 않습니다.
/
┣ container
┃ ┣ componentA
┃ ┗ componentB
┣ domain
┗ presenter
┣ componentC
┗ componentD이 단점을 극복하기위해 파일과 폴더의 이름에 계층의 층위를 알 수 있도록 숫자를 포함시킬 수 있습니다. 하지만 어떤 경우에는 파일이나 폴더의 이름에 대한 제한 사항 때문에 그렇게 하지 못할 수도 있습니다. 그렇지 않다 하더라도 코드의 규모가 커질수록 ‘함수의 위계화’를 준수하지 않는 실수를 방지하기가 쉽지 않습니다.
/
┣ 1 container
┃ ┣ 1 componentA
┃ ┗ 2 componentB
┣ 2 presenter
┃ ┣ 1 componentC
┃ ┗ 2 componentD
┗ 3 domain따라서 파일 구조나 파일/폴더명에 대한 컨벤션만으로는 한계가 있습니다. 개발자가 실수하지 않도록 코드 작성 자체를 제한할 필요가 있습니다. 여기에서 제가 제안드리는 방법은 eslint를 사용하는 것입니다. 기존에는 이러한 용도로 사용하기 위한 것이 없지만, 특정 파일의 import를 제한하거나 특정 함수의 사용을 금지하는 eslint rule을 제작해 사용할 수 있습니다. 참고로 저는 eslint-plugin-stratified-design라는 eslint plugin을 만들어 사용하고 있습니다.
마치며
어니언 아키텍처는 특정한 계층이 반드시 포함되는 것을 요구하지 않고, 단지 두 가지 간단한 제한 사항—‘순수함수의 최대화’와 ‘함수의 위계화’—만을 준수한다면, 거의 ‘자동적으로’ 생산성 높은 코드가 작성될 수 있도록 합니다. 하지만 파일 규모가 조금만 커져도 함수의 계층을 파악하기 쉽지 않아 함수 위계화를 어길 가능성이 높아집니다. 이 문제를 해결하기 위해 eslint rule을 제작해 잘못된 함수 호출을 제한할 수 있습니다.
지금까지의 어니언 아키텍처에 관한 모든 내용(리액트와 관련된 부분은 제외)은 에릭 노먼드의 <쏙쏙 들어오는 함수형 코딩>을 참고한 것입니다. 이 글을 읽으시고 어니언 아키텍처에 대해 더 자세히 알고 싶으신 분은 그 책을 읽어보시기를 권해드립니다.

개발자로서 배울 점이 많은 글이었습니다. 감사합니다.