Arbiter: Bridging the Static and Dynamic Divide in Vulnerability Discovery on Binary Programs
analysis :: paper

Background
Mitigation
- 보안 취약점을 완화하거나 방지하기 위한 기술이나 접근 방법
- 악의적인 공격으로부터 시스템을 보호하고 취약점을 악용하는 공격의 영향을 최소화하기 위해 사용
- 미티게이션 기술
- ASLR(Address Space Layout Randomization): 메모리 주소의 무작위화를 통해 공격자가 취약점을 악용하기 어렵게 함
- DEP(Data Execution Prevention): 데이터 섹션에서의 코드 실행을 방지하여 악성 코드 실행 막음
- Stack Canary: 스택 버퍼 오버플로우와 같은 공격을 탐지하기 위해 스택에 보안 값 추가
- Control Flow Integrity(CFI): 프로그램의 제어 흐름을 검증하여 악의적인 변경 탐지
- Code Signing: 실행 파일의 무결성 확인하여 변조 방지
- Sandbox: 실행 환경을 격리하여 악성코드의 영향 제한
- 정적 분석 도구: 코드를 검사하여 잠재적인 취약점 탐지/수정하는 데 도움
Vulnerability class
- 비슷한 특성과 취약성을 가진 취약점들을 그룹화한 것
- 특정 유형의 보안 취약점을 식별하고 분류하는 데 사용됨
- 각 취약점 클래스는 공통된 취약점 원인, 공격 경로, 영향 등을 공유하는 취약점들의 집합
Dynamic coverage problem
- 동적 커버리지 문제: 동적 분석 기법에서 발생하는 문제
- 동적 분석은 프로그램을 실행하고 그 실행 중에 발생하는 동작을 관찰하거나 분석하여 버그 탐지하는 기법
- 동적 커버리지는 프로그램 실행 중에 얼마나 많은 코드가 실행되었는지를 측정하는 지표
- 동적 커버리지 문제는 모든 가능한 실행 경로를 탐색하는 것이 어렵다는 점에서 발생.
- 프로그램은 복잡한 제어 흐름과 다양한 입력 조합에 따라 실행 경로를 가질 수 있음
- 이러한 실행 경로 중, 어떤 경로는 특정한 조건이나 입력에 의해 활성화되어야만 실행될 수 있음 - 따라서, 동적 분석은 일부 실행 경로만을 탐색하게 되고, 이로 인해 일부 깊은 버그나 복잡한 제약 조건을 필요로 하는 버그를 놓치는 경우 발생
Exhaust execution path
- exhaust execution path = exhaustive path exploration : 가능한 모든 실행 경로 탐색하기
- 프로그램의 모든 조건문과 반복문 고려.
- 모든 조건문의 참/거짓 분기와 반복문의 모든 반복 횟수 고려하여 실행 경로 생성 및 탐색
- 시간과 자원 소모 큼
OCaml Compiler
- OCaml은 정적으로 타입이 검사되는 다중 패러다임 프로그래밍 언어. 함수형 프로그래밍과 명령형 프로그래밍을 결합한 언어
- OCaml 컴파일러는 OCaml 프로그래밍 언어를 소스코드에서 기계어로 변환하는 도구
Integer operation에서 발생할 수 있는 문제
- arithmetic overflow: 산술 연산 수행하는 동안, 정수 범위 초과하여 값 계산하는 경우
- 부호 있는 32비트 정수의 최댓값인 2,147,483,647에 1을 더하면 오버플로우 발생 → 최솟값인 -2,147,483,648로 돌아감 → 계산결과가 예상과 다름 - non-value preserving width conversions(값을 보존하지 않는 너비 변환): 정수 타입 간의 변환 중에 발생하는 문제. 더 큰 크기를 갖는 타입에서 더 작은 크기를 갖는 타입으로 값이 변환될 때 발생함. 이때, 원래의 값에 대한 정보 손실 가능
- 32비트 정수를 16비트 정수로 변환할 때, 32비트 정수의 상위 비트가 잘려나가고, 하위 16비트만 남음 - dangerous signed/unsigned conversions(위험한 부호/무부호 변환): 부호 있는 정수와 무부호 정수 간의 변환 중에 발생하는 문제. 부호 있는 정수를 무부호 정수로 변환할 때, 부호 비트의 의미가 변경되어 의도하지 않은 결과 초래 가능.
- 음수로 표현되는 부호 있는 정수를 무부호 정수로 변환하면, 음수의 표현이 없어지고 양수로 해석될 수 있음 → 예기치 않은 동작 발생 원인이 됨
Integer Overflow
- 정수형 변수는 부호화(양/음수)와 크기(비트 수)에 따라 다르게 동작함. 만약 오버플로우가 발생한 정수가 부호화된 변수로 사용되고, 할당 함수에 전달되기 전에 부호 확장이 발생하면 문제 발생
- 부호 확장은 해당 정수의 최상위 비트를 사용하여 음수로 확장하는 것을 의미
- 이로 인해 정수의 값이 매우 커지게 되고, 할당 함수는 그 크기에 맞게 메모리를 할당하려 하지만 실패하게 됨
- 이는, 할당 함수가 음수 값에 대한 처리를 제대로 하지 못하거나, 할당할 수 있는 메모리 크기의 한계에 도달했을 때 발생할 수 있음
- 이런 상황에서는, 오버플로우가 발생한 정수의 부호를 확인하고, 부호 확장 없이 할당 함수에 전달하는 등의 조치를 취해, 할당 함수의 실패와 프로세스 종료 방지
Assertion Errors
- 프로그램에서 발생하는 오류 유형 중 하나
- assertion: 프로그램이 실행될 때 특정 조건이 참이어야 한다는 것을 명시적으로 나타낸 것. 디버깅 및 코드 검증에 유용하며, 프로그램의 일부가 정상적으로 동작하는지 확인하는 데에 사용됨
- assertion error는 프로그램이 assertion을 검사하는 동안 조건이 거짓인 경우 발생. 즉, 프로그램이 예상대로 동작하지 않는다는 것 나타냄
- 예)
- assertion으로 "x는 양수여야 한다"라는 조건을 검사하는데, 실행 중에 x가 음수인 경우 assertion error 발생. ⇒ 프로그램이 예상과 다른 상태에 있다는 의미이며, 오류 메시지와 함께 프로그램 실행 중단 가능
0-day 취약점
- 해당 취약점이 발견됐을 때부터 제조사나 소프트웨어 개발자가 아직 공식적인 패치나 보안 조치를 제공하지 않은 상태의 취약점
- 취약점이 발견된 날짜를 기준으로 0일 이라는 용어로 표현
Harness
- 테스트나 실험을 위해 특정한 환경을 설정하고 실행하는 데 사용되는 코드나 도구
- 보통, 테스트 대상이 되는 코드를 호출하고, 필요한 입력을 제공하며, 테스트 결과를 측정하고 분석하는 역할
- 동적 분석에서의 harness: 프로그램을 실행하고 프로그램의 동작을 모니터링하며, 입력 데이터를 주입하고 실행 결과를 기록하고 분석하는 데 사용됨. 테스트 시나리오를 구현/테스트 데이터 생성/프로그램의 실행을 제어하기 위해 사용됨
Source & Sink
- source : 프로그램 안에서 데이터의 시작점
- sink : 데이터의 종착점
- 예)
- 웹 애플리케이션에서 사용자로부터 입력을 받는 경우: 사용자가 웹 페이지의 폼에 정보를 입력하면, 이 입력 데이터는 source가 되고; 이 데이터가 데이터베이스에 저장되거나 외부로 전송되는 과정에서 sink가 됨 - source~sink를 추적하여 보안 취약점 발견/데이터 비정상적 흐름 분석 가능
Symbolic reasoning
- 심볼릭 추론 : 심볼에 대한 논리적인 연산을 수행하여 추론 진행
- 심볼: 데이터나 개체를 식별하기 위해 사용되는 이름이나 표시(변수, 상수, 함수, 클래스, 모듈 등의 식별자)
- 예)
```Python x = 10 # 변수 x는 값 10을 저장하는 심볼입니다. def square(n): return n ** 2 # square 함수는 입력값을 제곱하여 반환하는 심볼입니다. ``` - x와 square는 프로그램에서 사용되는 심볼(변수와 함수 식별하기 위해 사용됨)
Control flow vs. Data flow
- Control flow
- 프로그램의 실행 흐름. 코드의 실행 순서와 논리적인 분기 관리하는 역할
- 코드의 실행 경로 결정하는 역할
- 예) if문이나 반복문 같은 제어 구조를 사용해 특정 조건에 따라 다른 코드 블록을 실행하거나 반복 실행하는 것이 제어 흐름의 예 - Data flow
- 프로그램에서 데이터의 이동과 변환 나타냄
- 변수, 파라미터, 함수 호출 등을 통해 데이터가 전달되고 가공되는 과정 추적
- 프로그램의 데이터 의존성(종속성)과 관련돼있고, 데이터의 흐름을 분석하여 변수의 사용과 변경 추적 가능
- 예) 한 변수의 값을 다른 변수에 할당하거나 함수의 인자로 전달하는 것이 데이터 흐름의 예
White-box Static Vulnerability Analysis
- 화이트박스 정적 취약점 분석
- 소프트웨어의 취약점을 찾기 위해 소스코드나 바이너리 코드 분석하는 방법
- 소스코드나 바이너리 코드의 내부 구조와 동작 확인해 취약점 식별
Black-box static vulnerability analysis
- 소프트웨어 내부 구조에 대한 접근 권한 없는 경우; 소스코드나 바이너리 코드에 대한 접근이 제한되어 있어서, 외부에서 소프트웨어를 실행하고 입력값과 출력값을 분석하여 취약점 탐지
- 소프트웨어 동작 테스트하고 예상치 못한 동작이나 취약점을 찾아내는데 중점
Fuzzing campaign
- 소프트웨어의 취약점을 발견하기 위해 대규모로 자동화된 테스트 수행하는 과정
- 취약점 탐지를 자동화하고 더 넓은 범위의 취약점을 발견하기 위해 사용
Pattern-matching solution
- 특정 패턴이나 구조를 차는 데 사용되는 알고리즘/기술
- 주어진 입력 데이터나 코드에서 특정한 패턴을 찾아내기 위해 정규식, 문자열 매칭 알고리즘, 구조적 분석 등의 기술 사용
- 예) INDIO
Path-sensitive data-flow anaylsis
- 경로 감지 데이터 플로우 분석: 소프트웨어의 실행 경로와 데이터의 흐름을 함께 고려하여 정적 분석 수행하는 기술
- 소프트웨어의 다양한 실행 경로에서 데이터의 흐름을 추적하고, 이를 기반으로 프로그램의 동작을 분석하고 예측
- 변수, 파라미터, 상수 등의 데이터 요소가 프로그램 내에서 어떻게 전달되고 사용되는지 추적
- 데이터의 흐름을 분석하여 변수의 값이 어떻게 변하는지, 데이터의 오염이 발생하는지, 데이터의 의존성이 어떻게 형성되는지 파악 가능
Vulnerability property
- 취약점 특성
- 코드 접근성(Code Reachability): 취약점이 발생하는 코드 영역의 접근 가능성. 정적 분석에서는 코드의 흐름과 제어 흐름을 분석하여 취약점 위치 결정하는 데 사용
- 데이터 의존성(Data Dependency): 취약점과 관련된 데이터 의존성. 데이터 의존성을 이용해 정적 분석에서 취약점 탐지하거나, 동적 분석에서 취약한 데이터 흐름 추적 가능
- 문맥 종속성(Context Dependency): 취약점이 발생하는 문맥에 종속적인 특성. 예-특정 함수 호출이나 특정 조건문의 참/거짓 여부에 따라 취약점 발생 가능
- 시간 종속성(Time Dependency): 취약점이 특성 시간에만 발생할 수 있는 특성. 동적 분석에서는 특정 시간 동안의 실행을 모니터링하여 취약점 탐지
- 동적 환경 의존성(Dynamic Environment Dependency): 실행 환경에 따라 취약점 발생할 수 있는 특성. 예-특정 운영 체제, 하드웨어, 라이브러리 버전 등에 따라 취약점 발생 가능
데이터 흐름에 민감한 취약점
- 입력 데이터가 프로그램 내에서 어떻게 처리되는지에 따라 발생
- 취약점 노출: 사용자로부터 입력 받은 데이터가 쿼리문에 직접 포함되는 경우, 악의적인 사용자가 SQL 삽입 공격을 수행하여 데이터베이스를 조작
- 민감한 정보 누출: 사용자로부터 입력 받은 비밀번호가 프로그램 내에서 로그 파일에 기록되는 경우, 로그 파일에 저장된 비밀번호가 노출
- 잘못된 데이터 처리: 사용자로부터 입력 받은 데이터가 프로그램 내에서 올바른 검증 과정을 거치지 않고 사용되는 경우, 예외 상황이 발생하여 프로그램의 안정성이 저하
Shadow Memory
- 원래의 메모리 영역에 대응하는 '그림자' 메모리를 생성하여, 원래의 메모리 영역에 대한 추가적인 정보를 저장하고 추적하는 방법
- 주로 메모리 디버깅, 메모리 누수 감지, 메모리 사용의 안전성 검사 등에 사용
- 작동원리
1. 프로그램이 메모리를 할당하거나 해제할 때마다, 이에 대응하는 shadow memory도 함께 업데이트됨
2. shadow memory는 원래의 메모리 주소에 대응하는 주소에 메모리 상태 정보(예-메모리가 할당되었는지 아닌지, 메모리에 값이 쓰여졌는지 아닌지 등)를 저장
3. 프로그램이 메모리에 접근할 때마다, shadow memory를 확인하여 해당 메모리 접근이 유효한지 아닌지 판단: 만약 shadow memory에 따라 유효하지 않은 접근이라면, 오류 보고
Atomic operation
- 어떠한 작업이 중간에 중단되지 않고 한번에 완전히 수행되거나, 아예 수행되지 않는 상태(즉, 중간 상태가 없음)
- 한 쓰레드가 해당 연산을 수행하는 동안 다른 쓰레드는 대기하게 되고, 연산이 완료된 후에 다음 스레드가 연산을 수행하게 됨
- 특징
- 불분할: 한번에 완전히 실행되거나, 아예 실행되지 않음. 이는 작업이 시작되면 중단되거나 중간에 멈추는 일이 없음을 의미
- 독립성: 다른 연산의 영향을 받지 않음. 즉, atomic operation이 수행되는 동안 다른 연산이 그 결과에 영향 줄 수 없음 - 멀티스레드 환경에서 공유 자원에 대한 동시 접근을 제어하는 데에 중요함(멀티스레드 프로그래밍에서 동기화 메커니즘 구현하는 데에 사용됨)
- 예) 두개의 스레드가 동시에 같은 메모리 위치를 수정하려고 할때, atomic operation을 사용하면 이런 동시 수정 상황(경쟁 상태)을 피할 수 있음
- 대표적 atmoic operation: compare-and-swap, fetch-and-add, laod-link/store-conditional ...
Code Lifting
- 원본 코드의 의미를 유지하면서 저수준 언어에서 고수준 언어로 코드를 '올리는' 과정
- 보통 리버스 엔지니어링, 즉 소프트웨어를 분석하여 그 구조와 기능을 이해하는 과정에서 많이 사용됨
- 변환된 코드는 사람이 이해하기 쉽고, 분석과 디버깅 편함
- 예) 어셈블리어로 작성된 코드를 C나 Python 같은 고수준 언어로 변환하는 것이 '코드 리프팅'에 해당.
Underlying code lifting mechanism
- 코드 리프팅 메커니즘의 기본 구조나 원리
Predicate
- 취약점을 나타내는 프로그램 상태의 컨디션(조건) 및 주장(assertion)
Statistics-guided symbolic execution
- 통계 분석을 사용하여 프로그램 predicate를 구성 → 경로 구성(path constructon) 알고리즘을 사용하여 취약성을 담당할 가장 가능성 있는 실행 경로를 선택 → 순위를 매김
- 의심스러운 실행 경로 및 관련 predicate 심볼릭 실행 모듈에 추론을 제공
- 이 모듈은 프루닝된 검색 공간에서 Statistics-guided 경로 탐색을 수행하여 취약한 경로의 존재를 검증
Constraint in Program analysis
- 속성, 동작 또는 상태에 대한 제한이나 규칙
- 타입 제약 조건 : 변수나 표현식 유형 제한
- 정수형 변수에 대한 제약 조건은 해당 변수가 정수값을 가지도록 제한
- 메모리 제약 조건 : 메모리 할당, 해제, 접근 등을 제한
- 포인터 변수가 유효한 메모리를 가리키도록 하는 제약 조건
- 제어 흐름 제약 조건 : 프로그램 제어 흐름에 대한 제한
- 조건문의 분기 조건이 항상 참/거짓이 되도록하는 제약 조건
- 데이터 의존성 제약 조건 : 변수나 연산 간의 데이터 의존성 제한
- 변수 A의 값이 변수 B의 값에 의존한다는 제약 조건
Constraint Solver
- 제약 해결기. 제약 조건을 만족시키는 문제를 효율적으로 해결하는 알고리즘/도구
- 주어진 제약 조건에 따라 변수들의 값을 결정하고, 제약을 만족시키는 해를 찾는 과정 수행
- 제약 해결기는 수학적 기법, 그래프 이론, 인공지능 등 다양한 알고리즘/기술 활용함
Aliasing
- 프로그래밍에서 동일한 메모리 위치를 가리키는 여러 개의 이름 또는 포인터를 가리키는 개념
- 한 메모리 위치에 여러 개의 이름이나 포인터가 연결되어 있는 상태
- 예)
- 변수 A와 변수 B가 동일한 메모리 위치를 가리키고 있다;
- A와 B는 별칭 관계
- 이 경우 A를 통해 값을 변경하면 B를 통해서도 동일한 값이 변경되는 것이기 때문에, 별칭 문제 발생 가능
- 이는 예기치 않은 동작이나 오류를 초래할 수 있으며, 프로그램의 예측 가능성 감소
Under-Constrained Symbolic Execution(UCSE)
- arbiter가 cite한 논문: Under-Constrained Symbolic Execution: Correctness Checking for Real Code_usenix'15
- 취약점 분석 및 테스트 도구인 symbolic execution의 한 형태
- symbolic execution과 차이
- symbolic execution: 프로그램의 입력을 심볼릭 값으로 대체하여 실행 경로 분석하는 기법. 일반적으로 모든 가능한 실행 경로 탐색하여 취약점 발견. but, 경로 폭발 문제로, 프로그램 내의 깊은 코드 도달 못할 수도 있음
- UCSE : 일부 제약 조건을 의도적으로 제거하거나 완화시켜 분석할 실행 경로의 수를 줄이는 방식. 일반적인 심볼릭 실행이 너무 복잡하거나 시간이 오래 걸리는 경우 유용함. ⇒ 특정 기능을 실행하는 데에 중점을 둬서 특정 코드 세그먼트 철저히 확인할 수 있도록 함 - UCSE : 프로그램 내에서 임의의 함수를 직접 실행해서 main부터 이 함수까지의 비용이 많이 드는 path prefix를 생략함
- path prefix: 프로그램 (주로 main함수)의 진입점에서 도구가 확인하고자 하는 특정 함수로의 실행 경로 - ![[Pasted image 20240109095752.png]]
- 바이너리 코드에서는 변수의 크기 정보를 알 수 없는데(바이너리 코드가 고수준 프로그래밍 언어에서 컴파일되어 저수준 언어인 기계어로 변환되는 과정에서 많은 추상화와 정보가 손실되기 때문), UCSE가 작동하는 방법
- conservative approach(보수적인 접근): UCSE는 변수 및 포인터에 대해 가능한 모든 값 범위를 고려해 실행함. 이는 변수의 최소/최대 크기를 예상할 수 없을 때 사용.
- heuristics-based approach(휴리스틱 기반 접근): UCSE는 휴리스틱을 사용해 변수의 크기를 추정하고, 포인터와 변수를 제한하는 추가적인 제약 조건 적용. 휴리스틱은 코드 패턴, 기본 데이터 타입의 크기, 함수 호출 관계 등을 기반으로 함. 실용적인 결과 제공
Under-Constrained pointer
- 사용자에 의해 지정된 전제 조건을 갖지 않는 포인터 인자 지칭
- 프로그램에서 포인터 변수가 실제로 어떤 객체를 가리키는지에 대한 정보가 부족한 상태. 이는 포인터가 어떤 메모리 영역을 가리키는지에 대한 제약이 없는 상태 의미
- 예1) what is UC pointer
```c void foo(int* ptr) { // ptr과 관련된 작업 수행 } int main() { int* p = malloc(sizeof(int)); foo(p); return 0; } ``` - 함수 foo는 포인터 인자 ptr을 받지만, ptr의 입력값에 대한 사전 조사나 제약 조건 명시 X - 이는, ptr이 under-constrained pointer이고, 함수에서 처리하는 합법적인 입력 값 집합이 과도하게 추정될 수 있음을 의미함 - main 함수는 malloc을 사용하여 포인터 p를 할당하고 foo에 인자로 전달 - foo 함수는 ptr의 입력값에 대한 사전 조건 명시 안해서, ptr에 대한 합법적인 입력 값 집합이 과도하게 추정될 수 있으며, 이는 aliasing 관계 분석에 영향 줄 수 있음 - UC 포인터는 실제 실행 시에는 어떤 객체를 가리키는지 알 수 없기 때문에, 분석의 정확도와 완전성에 영향 줄 수 있음
- 전제 조건들이 완전히 특정되지 않은 UC 포인터들인 경우, 함수에 의해 처리되는 정당한 입력값들의 세트가 over-approximation(과잉 근사화)될 수 있음
- 이러한 과잉 근사화는 더 넓은 범위의 잠재적 메모리 위치들이 고려되도록 해서, 잠재적으로 프로그램 내의 aliasing 관계의 분석에 영향을 미칠 수 있음
- 따라서, UCSE 논문에서는 aliasing에 대한 UC 포인터의 영향에 대해 논의하지 않음 - 예2) 제약 조건이 있는 포인터의 예
```c void manipulateData(int* ptr1, int* ptr2) { *ptr1 = 10; *ptr2 = 20; } int main() { int* p1 = malloc(sizeof(int)); int* p2 = malloc(sizeof(int)); manipulateData(p1, p2); return 0; } ``` - manipulateData 함수는 두개의 포인터 인자 ptr1과 ptr2를 받아서, 그들이 가리키는 값 수정함 - main함수에서는 malloc 사용해 p1과 p2라는 두개의 포인터를 할당하고, manipulate함수에 인자로 전달 - 이 경우, p1과 p2 포인터는 제약 조건이 있는 포인터임 - malloc을 사용하여 각각 다른 메모리 위치에 할당되기 때문에, 포인터들이 서로 다른 메모리 위치를 가리킨다는 것 알 수 있음
CWE
- Common Weakness Enumeration. 보안 약점 리스트
- CWE Doc
CWE-131: Incorrect Calculation of Buffer Size
- CWE-131 Doc
- 버퍼 할당 시, 사용할 크기를 정확하게 계산하지 못하여 버퍼 오버플로우 발생
- 메모리 할당과 관련하여 잘못된 계산이 사용되는 경우 소프트웨어는 예상보다 작거나 큰 버퍼를 생성함. 할당된 버퍼가 예상보다 작으면 범위를 벗어난 읽기 또는 쓰기(CWE-119)가 발생하여 충돌이 발생하거나 임의 코드 실행이 허용되거나 민감한 데이터가 노출될 수 있음
- 예) 소켓에서 들어오는 패킷을 읽고 하나 이상의 헤더를 추출하는 코드
```C DataPacket *packet; int numHeaders; PacketHeader *headers; sock=AcceptSocketConnection(); ReadPacket(packet, sock); numHeaders =packet→headers; if (numHeaders > 100) { ExitError("too many headers!"); } headers = malloc(numHeaders * sizeof(PacketHeader); // 이 부분 ParsePacketHeaders(packet, headers); ``` - 코드는 패킷에 너무 많은 헤더가 포함되어있지 않은지 확인하기 위해 검사 수행 - 그러나, numHeaders는 부호있는 int로 정의되어서, 음수가 될 수도 있음 - **수신 패킷이 -3과 같은 값을 지정하면 malloc 계산은 음수를 생성함**(각 헤더가 최대 100바이트인 경우, -300) - 이 결과, malloc()에 제공되면 먼저 size_t 유형으로 변환 (∵ void \*malloc(size_t size)) - **이 변환에서, 4,294,966,996(40억)과 같은 큰 값이 생성되어 malloc()이 실패하거나, 매우 많은 양의 메모리 할당될 수 있음** - 따라서, 공격자가 적절한 음수를 사용하면 매우 작은 양수를 사용하도록 malloc()을 속일 수 있으며, 이는 예상보다 훨씬 작은 버퍼를 할당하여 잠재적으로 버퍼 오버플로우로 이어질 수 있음
Allocation Site Overflow
- allocation site: 메모리 할당이 발생하는 위치. 프로그램에서 동적 할당을 사용할 때, 메모리 블록이 할당되는 위치 또는 메모리 할당 함수가 호출되는 지점
- 보통 동적 메모리 할당은 프로그램 실행 중에 필요한 메모리 공간을 동적으로 할당하기 위해 사용됨.
- 이때 메모리 할당함수(malloc, calloc, new 등)를 호출하여 메모리 블록 할당 → 이 호출된 메모리 할당 함수가 allocation site가 됨
- 할당된 메모리 블록의 크기를 제대로 계산하거나, 해제할 때 이런 allocation site에 대한 정보를 참조할 수 있음 - CWE-131: 버퍼 크기를 잘못 계산/추정했을 때 발생하는 취약점.
- allocation site overflow: 동적 메모리 할당 함수를 사용하여 버퍼를 할당할 때 발생할 수 있는 오버플로우 상황을 말함.
CWE-252: Unchecked Return Value
- CWE-252 Doc
- 메서드나 함수의 반환 값을 확인하지 않으므로 예상치 못한 상태 및 조건을 감지하는 것 방지
- 프로그래머들이 종종 하는 두가지 가정 (1) 이 함수 호출은 절대 실패하지 않을 것이다, (2) 이 함수 호출이 실패하더라도 상관 없을 것이다. 그러나, 만약 공격자가 함수를 강제로 실패하게 하거나 예상치 못한 값을 반환하게 한다면, 이후의 프로그램 로직은 프로그래머가 가정한 상태와 다를 수 있음.
- 예1) 프로그램이 권한을 낮추기 위해 함수를 호출하지만, 반환 코드를 확인하여 권한이 성공적으로 낮아졌는지 확인하지 않는다면, 프로그램은 여전히 더 높은 권한으로 작동함
- 예2)
```C char buf[10], cp_buf[10]; fgets(buf, 10, stdin); strcpy(cp_buf, buf); ``` - 프로그래머는 fgets()가 반환될 때, buf에 길이 9 이하의 null-terminated한 문자열이 포함될거라 예상하지만, I/O 오류가 발생하면, fgets()는 buf를 null로 종료하지 않음. - I/O 오류: File/Read/Write/Format Errors - 앞 3개는 권한이나 파일 손상된 경우 - Format Errors: 입력 데이터의 형식이 예상과 다른 경우. fgets()는 개행 문자를 포함하여 지정한 최대 길이만큼의 문자열을 읽어들이는데, 이를 초과하는 문자열이 입력된 경우, 형식 오류가 발생할 수 있음 - 또한, 문자를 읽기 전에 파일 끝에 도달하면 fgets()는 buf에 아무것도 쓰지 않고 반환함 - 이 두 상황 모두에서, **fgets()는 NULL을 반환하여 비정상적인 일이 발생했다는 신호를 보내지만, 이 코드에서는 경고 감지 못함** - **buf에 null 종결자가 없으면 strcpy()에 대한 후속 호출에서 버퍼 오버플로우 발생 가능**
CWE-134: Use of Externally-Controlled Format String
- CWE-134 Doc
- 포맷 스트링을 인자로 받아들이는 함수를 사용하지만 포맷 스트링은 외부 source에서 비롯됨
- 공격자가 외부에서 제어되는 포맷 스트링을 수정할 수 있으면 버퍼 오버플로우, DoS, 데이터 표현 문제 발생 가능
- 예) 인자로 제공된 문자열 출력하는 코드
```C #include <stdio.h> void printWrapper(char *string) { printf(string); } int main(int argc, char **argv) { char buf[5012]; memcpy(buf, argv[1], 5012); printWrapper(argv[1]); return (0); } ``` - printWrapper()함수에서 printf()를 호출하기 때문에 악용될 수 있음
CWE-1349: Uncontrolled Format String
- 일종의 코드 주입 취약점
- 원래 무해하다고 생각했던 포맷 스트링은 프로그램을 충돌시키거나 코드 실행하는 데 사용될 수 있음
- printf()와 같이 포맷을 수행하는 특정 C 함수에서 포맷 스트링 파라미터로 확인되지 않은 사용자 입력을 사용하는 것에서 비롯됨
- 공격자는 %s, %x 포맷 토큰을 사용해 콜 스택 또는 메모리의 다른 위치에서 데이터 출력할 수 있음.
- 또한, %n 포맷 토큰 사용하여 임의의 위치에 임의의 데이터를 기록할 수 있으며, 이 토큰은 printf() 및 유사한 기능을 명령하여 포맷된 바이트 수를 스택에 저장된 주소에 기록함```C int count; printf("Hello, world!%n", &count); printf("The number of characters printed so far is: %d\n", count); ``` - *%n*은 "Hello, world!" 문자열 출력하기 전까지 출력된 문자의 수(13)를 *count*변수에 저장 - 두번째 printf문에서 count 변수의 값 출력하면 "The number of characters printed so far is: 13" 출력됨 - 탐지
- root cause를 x86 컴파일 실행 파일에서 쉽게 감지 가능
- printf- family 함수를 잘못 사용할 경우, 함수에 전달된 인자의 개수를 세는 것만으로도 감지 가능- 인자 부족(argument deficiency)
- x86으로 컴파일된 바이너리 파일에서의 감지
- 호출자가 스택에 push한 인자를 호출하나 이후, 스택 포인터를 조정해서 제거하는 호출 규약 덕분에 가능함. 따라서, stack correction을 간단히 검사하면, printf 계열 함수에 전달된 인자 개수 알 수 있음
- 예)```C #include <stdio.h> int main() { char* name = "John"; printf("Hello, %s!\n", name); return 0; } ``` - x86 아키텍처에서 위 코드를 컴파일하고 실행하면, printf 함수를 호출할 때 스택에 인자가 push되고 호출한 이후에, 스택 포인터가 조정됨. - 이때, stack correction 값을 검사하면 전달된 인자의 개수를 알 수 있음 - stack correction 값=8: 인자 1개; 12: 인자 2개 - Stack Correction(스택 보정) - 함수 호출 시, 스택 포인터(SP)를 조정하여 스택에 push한 인자들을 제거하는 과정. 스택 보정은 호출된 함수가 실행을 마치고 반환될 때, 스택 상태를 이전 호출 상태로 되돌리기 위해 필요한 작업임 - **호출 규약(call convention)**에 따라 수행됨. 호출 규약은 함수 호출 시, 인자 전달/반환값 처리/스택 관리 등의 규칙을 정의한 규약 - 대표적인 호출 규약 : cdecl 규약- 호출된 함수에서 스택에 푸시한 인자들을 호출 이후에 호출자가 제거하는 스택 보정 필요함 - 스택 보정 값 : 스택 포인터를 조정하는데 필요한 바이트 수
CWE-337: Predictable Seed in Pseudo-Random Number Generator(PRNG)
- CWE-337 Doc
- PRNG는 프로세스 ID 또는 시스템 시간과 같은 에측 가능한 시드에서 초기화됨
- 예측 가능한 시드를 사용하면 공격자가 PRNG에 의해 생성될 난수를 예측하기 위해 테스트해야 하는 가능한 시드 수가 크게 줄어 공격에 소요되는 시간 줄어듦
- 예) 시스템 시계의 현재 값으로 시드된 통계적 PRNG를 사용하여 난수 생성하는 코드
```C srand(time()); int randNum = rand(); ``` - 공격자는 PRNG에 사용되는 시드 예측하여, 생성된 난수 스트림도 예측 가능 - srand(): rand함수의 시드값 초기화해주는 기능 - rand()함수는 srand()함수에 의존적임 - srand의 s는 seed라는 뜻. seed 값에 따라 rand값이 바뀌게되며, stdlib.h 헤더파일에 존재함
CVE vs. CWE
- CVE : 취약점을 식별하고, 추적하기 위한 일련의 식별자. 고유한 식별 번홀르 할당하여 개별적인 취약점 식별
- CWE : 일반적인 약점 패턴 분류하고, 기술하는 데 사용되는 체계. 취약점 인식과 방지를 위한 참조 지침 제공
Context Sensitivity
- 특정 코드 또는 데이터의 실행 상황을 고려하여 분석하는 정도
- 예)
```python x = 10 y = 5 z = x + y ``` - z 변수는 x와 y 변수의 합으로 계산됨 - 컨텍스트 민감성이 낮은 분석: x와 y 변수의 값에 관계없이 z는 항상 15로 간주 - 분석이 실행되는 동안 변수의 값에 대한 상세한 정보 고려하지 않고, 단순히 코드의 구조 확인 - 컨텍스트 민감성 높은 분석: x와 y 변수의 값에 따라 z의 값이 달라질 수 있다는 것 인지 - 더 정확한 분석결과, but 분석의 복잡성과 처리 속도 증가 초래
Topological order
- 방향성 그래프에서 각 노드가 다른 노드에 의존하는 관계를 나타내는 경우, 그래프들의 노드들을 선형적으로 정렬하는 방법
- 이 그래프에서 topological order를 계산하면, 각 블록을 순서대로 방문할 수 있는 순서 결정됨
Abstract state
- 프로그램 실행 중 특정 지점에서의 실행 상태를 나타냄
- 변수의 추상화된 값, 제약 조건의 심볼릭 표현, 실행 경로 등 정보 포함
- 예)
```python x = 5 y = 10 if x > y: z = x + y else: z = x - y ``` - 위 코드에서 abstract state를 사용하여 실행 상태를 표현할 수 있음 - abstract state는 변수의 추상화된 값을 포함하므로, x, y, z를 아래와 같이 표현할 수 있음 ```python x: [x > 5, x <= 5] y: [y > 10, y <= 10] z: [x + y, x - y] ``` - 위 abstract state에서 x, y 변수의 추상화된 값은 각각 x>5와 y>10임 - 이는 x가 5보다 크고, y가 10보다 크다는 제약 조건 나타냄. z 변수의 abstract state는 조건문에 따라 x+y 또는 x-y로 구체화됨
AFL
- honggfuzz, libfuzzer와 함께 소프트웨어 퍼징을 위한 대표적인 grey-box fuzzer
NVD Database
- National Vulnerability Database(NVD)
- 국가 취약점 데이터 베이스
- NIST에 의해 관리되는 미국 정부 보안 취약점 저장소
- 소프트웨어 결함, 잘못된 설정, 제품명, 영향도 등의 보안 체크리스트 참고 데이터 보유
CSound
- 오디오 프로그래밍을 위한 도메인별 컴퓨터 프로그래밍 언어
- C로 작성됨
- 특별히 형식이 지정된 두개의 텍스트 파일을 입력으로 받음
ABSTRACT
취약점의 발견의 맥락에서 그 효과에도 불구하고, 최근 바이너리 프로그램 분석 접근 방식은 정확성과 확장성의 절충안으로부터 제한되고 있다. 본 논문에서, 저자는 정적/동적 취약점 탐지 기술을 돕는 취약점 속성 셋을 식별하여, 정적분석의 정확성과 동적 분석의 확장성을 향상시키고자 한다. 정적/동적 기술을 조심스럽게 합치면서, 저자는 큰 스케일에서의 real world 프로그램에서 이러한 속성을 보여주는 취약성을 탐지한다.
저자는 바이너리 코드 분석에서 몇가지 발전을 만들며 기술을 구현했고, arbiter라는 프로토타입을 만들었다. 저자는 네가지 common vulnerability classes에서 큰 스케일의 평가로 저자의 접근방식의 효과성을 증명한다: CWE-131(버퍼 사이즈의 부정확한 계산), CWE-252(check되지 않은 반환 값), CWE-134(uncontrol된 포맷 스트링), CWE-337(난수 생성기의 예상가능한 seed). 저자는 우분투 저장소의 76516개 이상의 x86-64 바이너리들에서 이 접근방식을 평가했고, 컴파일 과정에서 프로그램에 삽입되는 결함을 포함하여 새로운 취약점을 발견했다.
1 Introduction
- fuzzing 기술이 나오면서 정적 분석에 대해 엄청난 기술 발전이 있었음.
- 그러나, deep bug를 찾아낼 수 없다는 단점이 있음
- deep bug는 실행 가능한 경로 내 깊이 묻혀있거나, 동적 커버리지 문제 때문에 동적 기술에 어려움을 겪을 수 있는 복잡한 제약 조건이 필요함 - 동적 기술
- DSE(Dynamic Symbolic Execution)은 바이너리 코드의 작은 구역에서 exhaust execution path로 사용되고, 속성 위반을 찾아냄
- DSE는 정확하지만, 리얼월드 바이너리에서 낮은 범용성으로 동적 커버리지 문제가 있음 - 정적 기술을 사용하면 동적 커버리지 문제를 피할 수 있지만, 바이너리 코드에 대한 정적 분석 기술은 false positive가 많아 precision이 낮아서, 인간의 도움을 받아야 한다.
- 그래서, 낮은 false positive, 높은 precision, 높은 scalability를 가지며, 완전히 자동화되고, 많은 프로그램에 적용되는 강력한 툴이 필요하다
- fuzzer는 타겟 프로그램을 실행해야하기 때문에, 각 기법들은 커널 모듈이나 언어 런타임과 같은 개별 프로그램 클래스의 분석에 특화되어 있음
- 정적 분석도 이 개념과 비슷하단 걸 깨달은 저자는, 특정 취약점 유형에 대해 정적 분석을 조정함으로써 정적 분석 수행함
- 저자는 이를 활용해서, false positive에 대해 확장 가능한 정적 탐지(부정확함)와 정확한 동적 필터링(확장성 낮음)을 유지할 수 있는 취약점 속성을 식별함 - ARBITER 장점
- 정수 오버플로우나 권한 상승 버그 같은 복잡한 발생처럼 복잡한 취약점에 대해서도 높은 정확도를 보이면서, 많은 양의 바이너리 코드를 분석할 수 있음
- 새로운 취약점 클래스를 추가할 때, 몇 줄의 코드만으로 사양을 작성해서 다양한 취약점 클래스를 식별하고 분석할 수 있음
- 네가지 경우의 예시 보여줌
- CWE-131, CWE-252, CWE-337, CWE-134 - 하이브리드 분석을 위해
- 바이너리 수준의 분석 기술을 개선하고 새로운 조합 도입
- 이러한 개선과 조합은 정확성과 성능 사이의 설정 가능한 균형을 위해 정적/동적 기법을 사용하는 adaptive false positive 필터링 단계에서 잘 보여줌 - 리얼월드에서 잘 돌아가는지?
- synthetic한 Juliet 데이터셋에서 실험 진행에서, ARBITER는 이전 분석들에서 안전하다고 잘못 판단된 190개 취약점을 식별하고 수동으로 확인했다. - 간략한 evaluation 내용
- 76516개 바이너리 프로그램: x86-64 우분투 18.04 software repository
- 366개 프로그램에서 436개 CWE-131 알람
- 126개 프로그램에서 159개 CWE-159 알람
- 119개 프로그램에서 158개 CWE-134 알람
- 370개 프로그램에서 337개 CWE-337 알람 - 이런 결과는 ARBITER가 리얼월드 소프트웨어에서 제로데이 취약점을 포함하여 버그를 감지할 수 있고, 리얼월드까지 아우를 수 있다는 것 보여줌
- exploitable한 취약점(CVE-2018-18311)을 펄 런타임과 OCaml 컴파일러로 컴파일된 모든 32비트 프로그램에 영향을 주는 힙 에러에서 발견해서 제보했다.(Appendix)
Contribution
- 정적/동적 분석의 효과적인 조합을 위한 취약점 속성의 구체적인 set 식별
- ARBITER 개발
- ARBITER는 소스코드에 대한 어떠한 요구사항도 없이 잘 돌아가며, 시스템을 구축하고, 정적/동적 기술의 개선함.
- ARBITER에서 새로운 취약점 클래스의 사양을 만드는 건 어렵지 않음 - large scale의 evaluation 진행.
- 4가지 버그 클래스에 대해 76516 바이너리들 분석
2 Related Work and Motivations
- Table 1 : 이전 모든 연구들은 이 연구의 목표인, 자동화/광범위/일반적인 솔루션을 모두 포함하지 않음
- ![[Pasted image 20240109210339.png|450]]
2.1 Vulnerability Discovery Techniques
White-box Static Vulnerability Analysis
- 정적 분석과 바이너리 파일에 초점을 맞춘 솔루션을 구별하는 근본적인 문제가 있어서, ARBITER와 더 관련된 접근법에 대해서만 논의
- 그래프 기반 취약점 발견 접근법
- Joern, Chucky, CodeQL
- 프로그램 소스코드에 대한 그래프 표현으로 패턴을 표현하는 많은 쿼리에 의존
- 목표: 코드의 잠재적으로 취약한 부분에 대해서만 인간이 작업할 범위 줄이는 것
- 한계: 완전 자동화하지도 않았고, 정확하지도 않음 - 에러의 같은 유형 찾도록 설계된 접근법(like ARBITER)
- Vanguard
- 정적 코드 분석과 taint 분석을 조합해서 누락된 security-sensitive check를 식별함
- 한계: 필요한 소스코드에서 사용자 입력으로 부터 직접적으로 영향 받는 operation 검사에 초점을 맞춰서, failed dropped privilege 취약점을 탐지하지 못함
Dynamic Analysis on Binaries
- 테스트 케이스 생성을 fuzzer에서 구동하기 위한 정적 분석 및 DSE의 사용에 관해서 많은 문헌이 있음
- 퍼징과 DSE 조합한 접근법
- SmartFuzz
- 퍼징과 DSE 조합 → x86 리눅스 프로그램에서 정수 버그를 식별하기 위함
- 정수 연산에서 assertion error를 추가로 식별하기 위한 constraint solver 사용 → DSE를 사용해 새로운 테스트 케이스를 생성하기 위함
- arithmetic overflow, non-value preserving width conversions, dangerous signed/unsigned conversions
- 한계
- 프로그램 진입점부터 수행되는 symbolic-supported fuzzy exploration 때문에 다른 동적 기술들처럼, scalability 부족함
- 정수 버그만 찾을 수 있음 - DSE나 taint 분석 적용한 접근법
- Statsym: statistics-guided DSE 사용
- DIODE: 메모리 및 DSE를 할당하는 코드 위치를 식별하기 위해, 테인트 분석을 사용하여, 이러한 할당의 정수 인수가 오버플로우에 취약한지 확인 - 이러한 접근법은 ARBITER가 찾은 취약점 찾을 수 있지만, 타겟 프로그램에서 취약한 포인트를 실험하는 테스트 케이스가 필요하고, 막대한 퍼징 캠페인까지 필요할 수 있음
Binary Static Analysis enhanced by DSE
- 결과를 검증하고 false positive를 줄이기 위해 정적 분석과 DSE를 합치는 건 옛날에도 있어왔음
- INDIO
- 패턴 매칭 솔루션 사용
- 잠재적인 취약점들의 코드 위치를 식별하고, 순위 매김
- DSE를 path 프루닝과 함께 사용해 취약점 검증
- 한계: DSE를 수행할 때 항상 프로그램의 진입점부터 시작해야해서 scalability 매우 낮음 - IntScope
- path-sensitive data-flow 분석 사용
- 정수 오버플로우 식별
- tatin 분석 후 DSE 사용
- 오버플로우 제약 조건이 만족되는지 검증 - 정적분석과 DSE 합치는 것과 많은 false positive를 발생시키는 정수 오버플로우를 감지하는 능력은 이러한 접근 방법을 ARBITER와 비슷하게 만듦
- 한계: 이러한 기술들은 구체적인 버그 클래스에 맞춰져있음
- ARBITER한테 정수 오버플로우는 하나의 예시에 불과함(ARBITER는 이거 포함 더 많이 탐지할 수 있음)
2.2 Binary Analysis: Static vs. Dynamic
- 동적 분석
- 코드 커버리지 낮음(동적 커버리지 문제 때문에) → 버그 많이 놓침
- 하네스와 적용을 위해 인간의 노력이 필요함 - 정적 분석
- 높은 코드 커버리지 달성
- 높은 false positive - ARBITER
- 바이너리 코드에서 low-cost 취약점 탐지
3 Vulnerability-Targeted Static Analysis
- key insight
- 정적/동적 분석 모두에서 활용할 수 있는 특성을 가진 취약점 신중히 선택해서 취약점 탐지 접근 방식을 적절히 구성하여, 두 패러다임을 결합하고, 높은 정확도와, 확장 가능성 유지할 수 있음
- 이를 위해, 정적 분석에 적합한 취약점 특성을 식별 - 아래 세가지 특성을 식별함
(P1) Data-flow sensitive vulnerabilities
- 데이터 흐름에 민감한 취약점
- input source와 취약점 위치 간의 데이터 흐름 분석하여 발견할 수 있는 취약점
- tainted user input에 대한 적절한 검증이 부족해서 발생
- 데이터 흐름에 민감한 취약점 포함
- 데이터 흐름에 민감한 취약점의 범위는 taint-style 취약점보다 엄격하고, 일반적으로 정적 기법으로 접근할 수 있지만 정확도가 낮음
- 추가적인 동적 검증을 통해 데이터 흐름 정확성 높일 수 있음 - 예) 사용자로부터 입력받은 데이터가 새로운 데이터베이스 쿼리의 일부로 사용되는 경우, 해당 데이터가 쿼리 인자로 전달되는지 여부 확인해 취약점 탐지 가능
(P2) Easily identifiable sources or sinks
- 쉽게 식별 가능한 source 및 sink
- 많은 취약점 클래스의 source와 sink를 식별하기 위해 전체 바이너리에 대한 정확한 aliasing 정보가 필요함
- 많은 비용, 낮은 확장성
- 예) source가 "/tmp/secret" 파일에서 읽은 모든 데이터로 정의된 경우, 모든 입력 source를 식별하기 위해서는 파일을 열거나 파일 관련 함수와 시스템 콜의 파라미터를 올바르게 분석하고, 파일 포인터, 파일 디스크립터 및 관련 데이터 구조의 propagation을 정확하게 추적해야함 - 일부 취약점은 CFG와 같이 계산적으로 저렴하고 확장 가능한 분석이 생성하는 아티팩터를 조사하여 식별할 수 있는 source 또는 sink를 가지고 있음
- sink 예) 라이브러리 함수 malloc()을 호출하는 모든 호출 지점 → CFG 분석 결과로 쉽게 sink 식별 가능 - 프로그램을 source부터 sink까지 슬라이싱
- 이 속성은 정적 분석의 문맥에서 고려되지만, 동적 기법으로도 슬라이스 처리할 수 있음
- 이를 통해 DSE와 같은 동적 기법을 사용해 슬라이싱 과정에서 발생하는 대략적인 추정치 추론하고, 이런 추정치를 수정해 전체 시스템 정확도를 향상시킬 수 있음
- 동적 슬라이싱은 실제 데이터 흐름을 추적해서 정확한 의존성 그래프 생성할 수 있음
(P3) Control-flow-determined aliasing
- 데이터 흐름을 추적할 때, 대부분의 경우 aliasing 정보를 복구해야 하는데, 비용 많이 드는 전체 바이너리 분석 필요로 함
- 제어 흐름 결정 aliasing
- case: 많은 취약점들이 포함하는 데이터 흐름들이 포인터 역참조를 전혀 갖고있지 않거나, 포인터 역참조가 있다하더라도 항상 제어 흐름에 의해 결정되는 하나의 객체(스택 포인터를 통해 액세스되는 로컬 변수)로 해결될 수 있음 - 정적 분석 측면
- 이 속성은 ARBITER가 잘못된 aliasing 정보에 의해 발생하는 부정확성에 대해 걱정할 필요 없이 CFG에서 앞뒤로 적응적으로 이동할 수 있게 함 - 동적 분석 측면
- 동적 상태의 초기화 부재로 인해 발생하는 aliasing 문제를 단순하게 함
Choosing the right techniques
-
정적 기법: 데이터 흐름 복구, 프로그램 슬라이싱 사용
-
동적 기법: 취약성 특성에 따라 선택됨
-
속성들
- P1
- ARBITER가 지원할 수 있는 취약성 범위 정의
- 데이터 흐름에서 복잡한 value 관계를 추론할 수 있는 DSE 사용
- P2
- 작은 프로그램 슬라이스를 실행하여 확장성 높이기 위한 사전 조건 정의
- 이는, 동적 분석에 필요한 상태 정보가 부족한 프로그램 슬라이스 문제를 발생할 수 있음
- P3
- P2의 문제를, P3가 aliasing 문제의 대부분을 무시할 수 있는 능력으로 인해 DSE 기법인 UCSE 적용함
- P3 없으면, ARBITER는 정적 분석 중에 aliasing을 계산하거나 보수적인 aliasing으로 인해 높은 false positive 수용해야했을 것임 -
Property-Compliant(PC) 취약점: 정적/동적-심볼릭 문맥에서 이런 특성을 따르는 취약점
- ARBITER는 이런 취약점 추론 가능 -
PC 취약점을 포함하는 CWE 항목
- Table 3
- ![[Pasted image 20240109222151.png]]
아래 부터는 배경지식 섹션 참고하는 게 나음
3.1 CWE-131: Allocation Site Overflows
- 정수 오버플로우는 할당 사이트에서 발생하는 심각한 취약점 클래스
- 공격자에게 강력한 primitive 제공 - 발생
- 프로그램이 데이터를 저장해야 할 양보다 작은 크기의 메모리 블록을 할당할 때 발생
- 데이터가 이 메모리로 복사될 때, out-of-bound 메모리 접근이 발생하며, 이때 공격자가 코드 실행을 위해 악용할 수 있음
Occurrence
- 주로 malloc, realloc, calloc과 같은 일반적인 libc 함수를 사용해 메모리를 할당하는데 사용되는 custom wrapper 함수에서 발생함
- 이 래퍼 함수는 일반적으로 할당할 바이트 수를 나타내는 인자를 필요로 함
- 요청된 바이트 수를 할당하는 함수를 호출하기 전에, 해당 숫자는 애플리케이션 특정 메타데이터를 수용하기 위해 증가됨
- 요청된 크기가 매우 큰 경우, 이 증가는 정수 오버플로우 일으켜서 너무 작은 할당 요청하게 됨
Static sources and sinks
- CWE에 대한 sink: 할당 함수들(malloc, callloc, realloc)
- source: 각 할당 함수들 차례대로 식별된 sink들 호출하는 래퍼 함수에 대한 인자들
Static data flow
- 간단한 데이터 흐름 사양
- source에서 sink로 가는 모든 흐름을 정적으로 복구하고, 그 다음 심볼릭 추론 수행
Dynamic symbolic constraints
- 이 제약 조건은 래퍼함수에서 할당 크기 계산이 오버플로우하지 않도록 보장
- 수학적/절차적 표현 가능
- ARBITER의 절차적 방식의 제약 조건
- uint : e → uint : 부호 없는 정수 값으로서의 expression 평가
- 산술 수식 e가 메모리 할당 함수 f와 그것의 개별 항 {e1,··· , en}에 인자로 전달됨
- 취약점은 ∃ei ∈ {e1, ···, en}|uint(ei) > uint(e)인 경우에 존재 - 이 제약 조건은 할당 위치를 포함하는 함수가 필요한 메모리 블록의 길이를 감소시키지 않는다는 가정에 기반
- 대규모 평가에서는 이러한 가정이 항상 성립하는 건 아니라는 걸 발견함
- 그래서 취약점의 false positive detection 발생
- 저자는 논의 중임
3.2 CWE-252: Unchecked Return Values
- 프로그램이 오류를 제대로 처리하지 않으면 취약점 발생함
- DoS, 권한 상승 같은 다양한 공격 가능
- 일반적인 공격 경로는 프로그램의 초기화 단계 이후에 권한을 낮추기 위해, 권한을 낮추려는 프로그램의 취약점임
- 권한 감소(setuid)의 반환 값이 확인되지 않으면 프로그램이 취약해질 수 있음
Occurrence
- 개발자가 반환 값 확인을 생략할 때 발생할 수 있는 취약점
- 주로 setuid와 같은 함수 뿐 아니라, mmap, open, close 등과 같이 자주 사용되는 기능에서도 발생
Static sources and sinks
- source: source list를 만들고, 보안 상의 의미가 분명한 시스템 호출에 초점(이 list는 확장 가능)
- access, chdir, chown, chroot, mmap, prctl, setgid, setsid, setpgid, setreuid, setregid, setresuid, setresgid, setrlimit, stat - sink: 시스템 호출의 (분석 중인 바이너리에서) 해당 libc API를 호출하는 함수의 반환 블록 사용
Static data flow
- 데이터 흐름 사양: 발신자의 반환 값이 시스템 호출 리턴 값에 의존하지 않은 경우를 포함하여 source로부터 API 리턴 값의 모든 흐름을 캡쳐해야함
- 반환 값이 폐기된 경우(이 취약점의 공통 원인)를 캡처하기 위함
Dynamic symbolic constraints
- 선택한 API의 반환 값은 오류인 경우에 -1, 성공한 경우에 다른 값임
- 제약 조건
- ARBITER의 심볼릭 추론 능력을 통해 이 애플리케이션에 강력한 취약점 제약 조건 생성함
- 만약 함수의 끝에서 DSE가 API 호출의 반환 값이 성공/실패 상태를 식별하면, 해당 값에 대한 검사가 없었고, 확인되지 않은 return value 취약점이 존재함
3.3 CWE-134: Uncontrolled Format String
- printf()와 같은 포맷팅 함수는 런타임에서 포맷 스트링을 기반으로 인자의 개수 결정
- 이 포맷 스트링은 (문자 그대로 출력되는) 일반 문자와 포맷 지정자(format directives)를 포함
- 포맷 지정자: 출력/복사/수정할 인자를 지정 - 공격자가 포맷 지정자를 제어할 수 있으면, 이 기능 사용해서 메모리 값 노출시키거나, 덮어쓰기 가능
- 예)
```C int secret = 42; printf(user_input); ``` - user_input은 사용자가 제어할 수 있는 문자열임. 사용자가 포맷 지정자를 포함한 악의적인 문자열 입력하면, 다음과 같은 문제 발생 가능 - 메모리 노출: 사용자가 `%s`나 `%x`와 같은 포맷 지정자를 사용하여 스택이나 임의의 메모리 위치에서 값을 읽을 수 있 - 메모리 손상: 사용자가 `%n`과 같은 포맷 지정자를 사용하여 메모리 주소에 값을 쓸 수 있고, 이를 통해 중요한 프로그램 변수를 수정하거나 메모리 영역을 덮어쓸 수 있음 - 서비스 거부: 사용자가 특정 포맷 지정자나 큰 너비/정밀도 값을 사용하여 프로그램이 과도한 리소스를 소모하거나 충돌을 일으킬 수 있음
Occurrence
- 포맷 스트링 취약점은 포맷 스트링이 상수가 아닐 때 발생할 수 있음
- lazy 프로그래밍 관행(pritnf("%s", name);이 아닌, printf(name);사용)이나 동적으로 포맷 스트링을 구성할 때 충분한 필터링이 없는 경우 발생
- 전자는 종종 덜 사용되는 경로(특히 error logging)에서 발생
Static sources and sinks
- sink: 포맷 스트링 취약점에 영향을 받는 libc 함수 집합
- printf, fprintf, asprintf, dprintf, sprintf, snprintf, vasprintf, vfprintf, vsprintf, vsnprintf - source: 식별된 sink를 호출하는 래퍼 함수의 인자
Static data flow
- 간단한 데이터 흐름 사양
- source에서 sink로 가는 모든 흐름을 정적으로 복구하고, 그 다음 심볼릭 추론 수행
Dynamic symbolic constraints
- 이 취약점에 대한 동적 심볼릭 제약: sink에서 사용되는 포맷 스트링이 상수인지 아닌지 검사
- 이 포맷 스트링이 상수가 아니면 잠재적 버그로 플래그 지정
3.4 CWE-337: Predictable Seed in PRNG
- PRNG의 보안성은 seed의 예측 불가능성에 의존
- PRNG 알고리즘은 초기상태인 시드값을 기반으로 계산해 난수 생성
- 만약 공격자가 예측한 시드로 생성된 난수 값이 보안 작업에 사용되면, 보안 침해 가능
Occurrence
- 현재 일반적인 관행은 PRNG의 시드로 current time 사용
- 이는 랜덤 시드를 예측 가능하게함 - 프로세스 ID를 시드로 사용하는 것도 이와 유사한 일반적인 anti-pattern과 관련 있음
- 이 ID들은 예측 가능하게 되고 있음
Static data flow
- 간단한 데이터 흐름 사양
- source에서 sink로 가는 모든 흐름을 정적으로 복구하고, 그 다음 심볼릭 추론 수행
- 이전의 취약점 클래스는 상수 값을 음수로 사용했지만, 여기서는 양수로 취급함
Dynamic symbolic constraints
- DSE를 이용해 데이터 흐름 분석 결과를 확인하고 source와 sink 간 데이터 흐름을 설ㄹ정함
- 추가적으로 적용해야 하는 제약 조건은 없음
4 ARBITER Analysis Framework
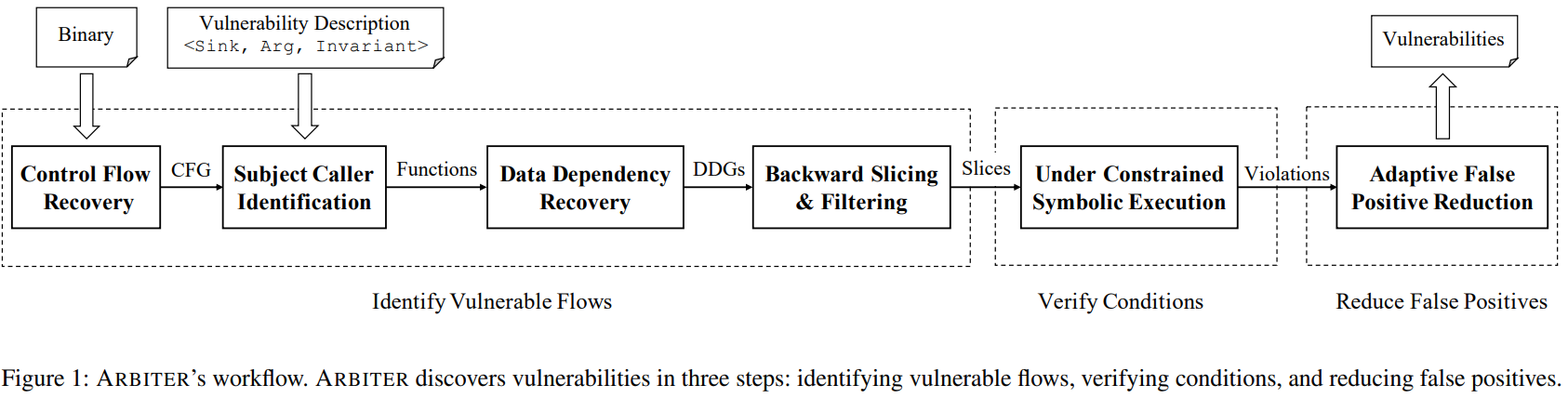
- 섹션 3의 속성들은 ARBITER에 정적/동적 접근 방식의 효과적인 결합을 가능케 함
- ARBITER는 높은 수준에서 확장가능한 정적 분석기술과 정밀한 DSE 기술 결합
- 정적 분석은 분석 중인 프로그램에서 PC 취약점 후보의 슈퍼셋을 식별하게 함
- 동적 분석은 정확성과 확장성 사이에서 조절 가능한 false positive 필터 역할 - 하지만, 바이너리 코드에서의 사용을 위해 몇가지 혁신적인 분석 개선 필요
Input: The Binary
- 순수하게 동적분석(퍼징)과는 달리, 인풋 바이너리 파일은 실행 가능하지 않아도 됨
Input: Vulnerability Description
- PC 취약점은 정적 분석을 통해 감지할 수 있는 특정 속성을 가지고 있음
- 이러한 속성들은 Vulnerability Description(VD)로 ARBITER에 제공됨
- VD: 섹션 3의 정적 및 심볼릭 아티팩트 설명을 프로그래밍적으로 표현한 것
- 예) CWE-131에 대한 섹션 3.1과 CWE-252에 대한 섹션 3.2)
- 다른 PC 취약점 클래스는 VD 생성해서 추가 가능
Identifying vulnerable flows
- 바이너리 코드에서 VD를 만족시킬 수 있는 흐름을 식별하기 위해 여러 기법을 결합해 사용
- 프로세스
1. ARBITER는 복구된 제어 흐름 그래프에서 VD 주체 검색
2. 계산된 데이터 종속성 그래프(DDG)를 쿼리해서 제공된 VD와 일치하는 주체 간의 데이터 흐름 식별
3. ARBITER는 이런 흐름을 나타내는 경로 계산하고, 다음 단계로 넘김
Verifying vulnerable conditions
- ARBITER는 제공된 경로를 실행하고 source와 sink 사이의 심볼릭 데이터 관계를 복구하기 위해 UCSE 사용해 취약 조건 검증
- 이 심볼릭 데이터 관계가 제공된 VD에서 설명하는 제약 조건을 만족하면, 해당 경로가 다음 단계로 넘어감
Reducing context-based false positives
- trade-off로 인한 문제 발생 : 확장성 보장을 위해 정적 분석의 문맥 민감성 제한
- 취약점 후보에 대해 검출된 데이터 흐름에는 문맥 민감도가 더 높은 상태로 존재할 수 있는 누락된 제약 조건일 수 있음 → false positive 발생
- As a result, the data flow detected for a Vulnerability Candidate might be missing constraints that would be present with a higher context sensitivity, resulting in a false positive detection.
- 이해하기로는, 검출된 데이터 흐름에서 문맥 민감성을 제한하고, sink에서 문맥 민감성을 높게해서 완화시킨다는거 같은데.. 맞나? - ARBITER의 문제 완화 방식: 검출된 sink에서 더 높은 컨텍스트 민감도로 슬라이스 계산, 이를 심볼화하여 누락된 제약 조건 식별
- 이 단계에서 컨텍스트 민감도 증가시켜서, ARBITER는 scalability 대신 정확성을 우선시함 - ARBITER가 기존의 취약점 후보를 무효화할 어떠한 제약도 식별할 수 없는 경우, 그 후보는 alert로 분석자에게 보고됨
5 Identifying Vulnerable Flows
- ARBITER는 CFG와 VD를 입력으로 하여 VD에 명시된 취약점 source/sink에 대한 DDG(Data Dependecy Graph)를 구축하고 쿼리함
- 이렇게 생성된 후보 취약점 데이터 플로우는 ARBITER의 동저 분석 컴포넌트에 의해 검증됨
5.1 Precise Static Data Flow Tracking
- SymDFT: 새로운 정적 데이터 흐름 추적 기술
- 정밀성과 확장성을 중점으로 PC 취약점 추론
- 그래프 기반/테인트 기반 정적 분석 사용 → 소스코드와 바이너리코드에서 테인트 스타일의 취약점 찾음
- PC 취약점은 유사한데, 이 취약점들에 대한 추론은 데이터 흐름 추적 동안에 더 많은 정밀도 요구됨
- 설계 결정 사항
- context-sensitivity & path-sensitivity: 일반적으로 함수의 시작점으로 설정되는 임의의 시작점을 기준으로 컨텍스트 민감성과 경로 민감성 방식 수행해서, 기본 블록을 정적으로 에뮬레이션
- 모델링: 레지스터, 메모리(전역 영역, 스택 및 힙을 포함하는 flat 메모리 모델), syscall, 파일 디스크립터롭터의 접근 및 접근에 대한 모델링 수행해서 프로그램 동작 추적 → 파일 및 네트워크 소켓에 대한 접근 포착 가능
- symbolic domain: 심볼릭 도메인을 사용해서 추론 과정 중, 알 수 없는 변수와 심볼릭 표현식 추적함 → 모델링된 데이터의 높은 정밀성 달성
Traversal policy
- 함수 레벨에서 SymDFT는 함수 내분의 기본 블록들을 topological order에 따라 순회함
- 모든 이전 블록들이 방문된 후, 다음 블록을 방문하도록 보장 - 호출자에게 호출이 발생하면, SymDFT는 호출자 함수를 분석하고, 반환된 abstract state를 사용해서 반환된 사이트에서 분석 진행
Branching policy
- SymDFT
- forced execution과 blanket execution 기반으로 분기 정책 통합
- 각 분기 지점에서 abstract state를 분기시키고, 분기의 실행 가능성과 관계없이 모든 분기 따라감.
- 에뮬레이션 진행 중에 심볼릭한 경로 조건식(심볼릭 제약 조건) 수집하지만, 이 조건식의 만족 가능성은 평가 X
- 정확도는 낮을 수 있지만, 섹션 6에서 ARBITER는 이 정확도 복원함
State merging policy
- 동일한 바이너리 주소에 있는 abstract state들은 즉시 병합됨
- 각 상태들은 병합 레이블 할당 받음
- 구체적인 심볼릭 표현들은 병합 레이블을 조건으로 하는 if-then-else 식의 형태로 병합됨
- if-then-else 표현식 사용하면 abstract state를 효과적으로 표현할 수 있고, 후속 분기 작업에 유용한 정보 제공 - 상태 병합은 상태 공간의 크기를 줄이고 복잡성 감소시키는 데에 유용 → 분석 효율성 향상+메모리 사용량 감소
Termination
- 프로그램 분석에서 분석이 종료되는 시점
- SymDFT의 분석 종료: 공격적인 종료 전략
- soundness와 정확성 저하, 확장성 향상 목적
1. 함수 호출 깊이(call depth) 제한
- 분석 중에 함수 호출의 깊이가 2 이상인 경우, 호출된 함수를 분석하는 대신 추상적인 리턴 값 생성
2. 반복문 횟수 제한
- 각 반복문 최대 3번 방문
- 반복문 종료 보장 및 무한 루프 방지 - 정확성 저하, but 대규모 코드베이스에서 분석 확장성 향상
5.2 Building DDGs and Extracting Flows
- ARBITER 작동 방법
1. CFG에서 source와 sink 식별하고 관련 함수 인식함
2. 각 source 또는 sink가 포함된 함수에 대해 DDG 구축 - ARBITER가 구축한 DDG에는 호출자(caller) 포함 안됨 (섹션7)
- source와 sink 모두 알고 있는 경우
- DDG에서 모든 취약한 데이터 흐름을 식별하는 법 : source나 sink에서 출발해서 subgraph(하위그래프)를 생성하면 됨 - sink만 알고 있는 경우(VD에서 sink만 설명)
- ARBITER는 sink가 발견된 각 함수(및 호출된 함수)에 대해 별도의 DDG 구축(모든 잠재적인 입력 source를 포함하는 전체 프로그램 DDG 구축 X) - ⇒ DDG 생성 및 취약한 흐름 식별 확장성 향상(정확성 저하-검증단계에서 보정 가능)
6 Verifying Vulnerable Flows
- 정적 분석을 통해 수집된 후보 취약점 데이터 흐름이 반드시 취약한건 아님
- (1) un-satisfiable한 경우
- (2) 흐름이 유효하더라도, 경로 예측(path predicate)이 취약점을 트리거할 수 없게하는 경우 - ARBITER는 UCSE를 사용해 각 후보 데이터 흐름을 검증하고, 위 두가지 경우(충족할 수 없거나, 취약하지 않은 흐름)에 대해 제거
6.1 Under-Constrained Symbolic Execution
- ARBITER는 대상 바이너리 파일의 진입점에서 시작해, 취약점 sink에 도달하는 실행 가능 경로를 도출하기 어려움
- CFG가 불완전하거나, 동적 커버리지 문제 때문
- 대신, 후보 데이터 흐름에 해당하는 바이너리 프로그램 슬라이스는 일반적으로 프로그램 상태 초기화에 필요한 코드 포함 X - source 기반 분석에서는 미완성된 프로그램 상태에서 DSE를 수행하기 위해 UCSE가 유용한 접근임
- UCSE: 데이터 구조 초기화나 환경 모델링 없이 임의의 함수에 대해 심볼릭 실행 허용
- 미완성된 상태에서 사용할 수 없는 값들(누락된 매개변수, 호출된 함수의 알 수 없는 리턴 값)은 UC 변수로 간주
- UC 변수가 포인터로 사용되면
- UCSE는 해당 변수를 동일한 크기를 갖는 새롭게 할당된 메모리 영역을 가리키는 포인터로 초기화함
- 변수가 포인터로 사용되지 않으면
- UC 변수는 해당 변수에 대해 심볼릭 제약 조건을 더 강하게 가함 - ARBITER는 UCSE로 바이너리 코드 지원하기 위해서 UCSE를 확장함
- UCSE는 aliasing 문제에 취약
- 기본적으로 UC 포인터가 기존 객체를 가리키지 않는다고 가정하기 때문
- 즉, 바이너리 파일에서는 메모리에 할당된 영역을 가리키지 않는다고 가정하는 것
- UC 포인터는 실제로 어떤 객체를 가리키는지 알 수 없어서, 해당 포인터를 통해 접근하는 메모리 영역에 대한 정보를 알 수 없게 됨. 그래서 UCSE는 잘못된 가정을 할 수 있고, 잘못된 실행 경로 탐색 - 하지만, 다행히도 PC 취약점에서는 제어 흐름에 의해 감지되지 않는 aliasing 관계가 존재하지 않는다고 명시하고 있어서, UCSE의 aliasing 문제 우회 가능
- 그러나, 스트립된 바이너리에서는 타입 정보를 사용할 수 없어서 아래 두가지 문제 발생
Shadow memory allocation
- UCSE는 타입 정보 부족으로 인해, 할당할 메모리 영역의 크기를 알지 못함
- in ARBITER
- UCSE는 UC 포인터에 대해 할당된 메모리 영역의 크기를 결정하지 않음
- 대신, 각 UC 포인터가 스택, 힙, 다른 섀도우 메모리 영역과 완전히 분리된 섀도우 메모리 영역을 가리킨다고 가정하면, UC 포인터에서 파생된 모든 포인터는 동일한 섀도우 메모리 영역에만 액세스할 수 있음
Adding neccessary constraints
- UCSE
- 소스 코드에서 변수의 크기에 대한 정보를 활용하여 포인터 제한
- 포인터 접근이 변수의 범위 벗어나는 경우의 위배 사항을 찾는 데 의존 - 그러나, 바이너리 코드에서는 이러한 정보가 없으니까, 포인터와 변수를 제한하는 게 어렵고, UC 포인터나 변수로 인해 발생하는 특정 메모리 접근은 스택이나 전역 영역의 중요한 데이터 구조를 손상시킬 수 있음
- 예) 완전히 constrained된 포인터, stored return address 등
- 이는, 실행 중에 존재하지 않는 unsound symbolic state로 이어짐 - 따라서, UCSE는 변수와 포인터에 대해 적극적으로 제약 조건을 추가하여, 스택이나 전역 영역의 중요한 데이터가 덮어쓰이지 않도록 함
- 이 방식으로 UCSE는 스택 버퍼 오버플로우 같은 취약점 찾을 수는 없어도, 이런 취약점은 PC 밖의 문제여서, UCSE의 범위를 벗어남
6.2 Collecting Data Flow Constraints
- ARBITER는 각 sink에서 시작해 CFG를 따라가며 프로그램 슬라이스 생성 → 각 후보 취약점 데이터 흐름에 대해 프로그램 슬라이스에서 UCSE 실행
- sink에서는 source와 sink 사이의 data dependency를 심볼릭 표현식으로 추출하고, 경로 조건식 수집
- 경로 조건식으로 VD 위반 여부 판단
- 만약, VD에 해당하는 제약 조건이 충족 가능하면, ARBITER는 잠재적인 VD 위반 alert
7 Adaptive False Positive Reduction
- 원인 : ARBITER는 함수 내에서 작동하기 때문에, 해당 함수의 흐름과 데이터 흐름에 영향을 미치는 문맥 관련 정보가 없음
- 문제 : UCSE 단계에서 후보 취약점 데이터 흐름에 대한 만족성 필터링을 하더라도, 문맥의 부족으로 인해 많은 false positive 발생
- 해결 : 작은 문맥에서 취약점이 감지되면 분석할 문맥을 증가시켜서 false positive 필터링함
- 적용
- ARBITER는 현재 함수의 모든 호출 위치를 재귀적으로 식별하고, 호출 프레임의 문맥에서 분석 진행
- 이때, 재귀적으로 호출자별로 문맥 확장하고, 미리 정의된 recursion limit까지 계속 확장
- recursion limit은 분석가가 report의 수와 시간 제약을 통해 설정할 수 있음
- 문맥 확장은 기하급수적 시간 증가 야기하니까 recursion limit 적당히 설정 - 결과 : 각 문맥 확장 단계가 약 factor 0f two의 경고를 줄인다는 것 보여줌(섹션 8.1). 세가지 reduction 단계는 false positie 충분히 줄여서 수동으로 검증할 수 있게 함
8 Evaluation
- evaluation 수행 환경: Kubernetes cluster of Intel Xeon CPUs at 2.30GHz, with one core and 4GB of RAM(각 바이너리 분석 전용)
- ARBITER prototype: angr 위에 구현
- 세가지 추가 실험셋
1. coreutils Linux 바이너리 파일에 대한 성능 평가
- ARBITER 기술의 다른 부분들의 computational 비용 측정(부록C)
2. Juliet 프로그램 분석 테스트 suite와 다른 Linux 프로그램 비교
- ARBITER를 최신 기술과 비교
3. Ubuntu 18.04 소프트웨어 저장소에서 대규모 평가
- 총 76516개 바이너리 파일에서 CWE-131, CWE-252, CWE-337, CWE-134 및 취약저머 클래스 탐지 능력 평가
8.1 Effectiveness Evaluation
- 실제 코드에서 버그 찾는 능력 측정하기
- 수행 환경: x86-64 Ubuntu Linux 18.04 저장소의 모든 user space 바이너리
- Ubuntu Linux 18.04 저장소
- 1852152개 ELF 파일 중
- 제외 파일 : ARBITER가 작동하지 않는 커널 모듈 1708122개, 다른 ELF 파일의 디버그 심볼 포함한 64101개 심볼 전용 ELF 파일, angr 프레임워크에서 처리 못하는 2829개 파일 - 최종 데이터 셋 크기 : 76516개 파일
- 각 바이너리를 ARBITER가 구현한 VD인 CWE-131, CWE-252, CWE-134, CWE-337과 비교
- Adaptive False Positive Reduction 단계에서 recursion limit 3으로 설정
- 결과: 1095개 alert 발생
- 수동 분석: 636개 true positive, 400개 false positive
- false positive: (1) Description false positive: VD 자체의 부정확성으로 발생, (2) Vulnerability false positive: 분석의 부정확성으로 발생
- 410개 false positive 중, 72개 DFP, 338개 VFP
- 나머지 경고는 복잡해서 분류 못함 - Appendix A
Case Studies
- OCaml 관련 사례
- ARBITER의 CWE-131 alert를 분류하는 과정에서 버그가 거의 동일한 함수에 대한 26개의 report 발견
- 소스 코드 확인 결과, 모두 OCaml로 작성됐고, 해당 함수들의 OCaml 소스 코드에는 버그 없었음
- 이 26개 alert은 OCaml 컴파일러에 의해 컴파일 과정에서 도입된 버그였음
- 이 버그는 영향을 받은 OCaml 컴파일러로 컴파일된 모든 32비트 OCaml 프로그램에 영향을 미침
- OCaml 개발자들에게 말했고, 현재 조사 중임 - 저자는 프로그램을 crash시키는 out-of-bound 힙 액세스와 정수 오버플로우를 유발하는 Proof of Conecpt(PoC) 개발
8.1.1 CWE-131: Overflows at Allocation Sites
- 데이터셋의 366개 바이너리 파일의 444개 함수에서 436개의 CWE-131 alert 발생
- 수동 정적 분석 결과
- 194개 true positive
- 184개 vulnerability false positive
- 11개 description false positive
- 코드 복잡성과 코드 베이스 이해 부족으로 34개 바이너리 파일에서 47개 alert 분류 못함
Description False Positives
- 10개 바이너리 파일에서 11개 alert 보고
- 이 결과는 CWE-131 VD에서 사용한 predicate가 항상 버그의 존재를 의미한다는 건 아니라는 뜻
- VD 목표: 할당 호출 시, 인자의 정수 오버플로우 취약점 모델링 하기
- 그러나, VD에서의 predicate는 정수 오버플로우에 대한 특정 표시가 아닌 일반적인 패턴을 기반으로 함
- 이 패턴은 크기 변수가 할당 래퍼에 인자로 전달되고, 계산 중에 오버플로우가 발생하여 더 작은 변수가 할당자에 전달되는 상황을 설명함
- 그러나, 우분 데이터셋의 150077458개 함수 중 11개 함수에서는 이 패턴 성립 X
- 이 경우, 래퍼 함수에서 수행되는 계산이 할당 크기를 합법적으로 줄이고, 정수 오버플로우 겪지 않음
Vulnerability False Positives
- CWE-131 alert에서 VFP를 일으키는 주요 원인
- unrealistic execution requirments: 일부 감지를 트기러하는 것은 콜백을 불합리한 횟수로 실행해야함
- 예) 전역 카운터가 매우 커져야 하는 감지는 해당 전역 카운터를 증가시키는 함수가 수억번 실행되어야해서, 실제로 트리거 불가 → 실제 상황에서 발생 안 할 가능성 높음
- unrealistic data requirments: 몇가지 alert은 264바이트의 문자열이 제공될 때, 정수 오버플로우를 겪을 함수들에 대해 생성됨
- 그러나, 이러한 크기의 데이터를 생성하거나 전송하는 것은 현실적으로 불가능해서 버그는 트리거 불가
- ARBITER는 24개의 바이너리 파일에서 24개의 함수에 대해 alert 발생 시킴 ⇒ 264-1 바이트 길이의 문자열이 메모리에 실제로 저장될 수 있다고 가정했기 때문
- dead code: 의미없는 코드에서 발생한 detection은 실제로는 트리거될 수 없는 취약점으로 판단
- 해당 코드를 실행할 수 없거나, 접근할 수 없기 때문에, 실제적인 버그가 아니라고 판단되어, vulnerability false positive로 분류
- insufficient analysis context: in some cases, 콜 스택에서 더 높은 호출자 함수가 취약점을 실제로 트리거할 수 없게 만드는 제약 조건을 도입하지만, ARBITER는 그러한 제약 조건을 추론할 수 있을 만큼 충분히 높은 호출자 수준으로 분석하지 않음
- 예) alttab 바이너리는 LibPNG를 사용해 PNG를 로드하는데, 이미지 크기로 인해 4바이트 정수 오버플로우 발생함
- PNG 사양에서는 PNG의 높이와 너비가 최대 232까지 허용되지만, LibPNG는 이를 216로 제한해서 버그가 트리거 될 수 없게 함
- signedness side-effects: 오버플로우된 정수가 할당 함수에 사용되기 전에 부호 확장되는 상황에서, 확장된 값이 커지게 되고, 할당에 실패하여 프로세스 종료됨
8.1.2 CWE-252: Unchecked Return Values
- 이 취약점에 대해서는 ARBITER가 sink부터 시작해서 함수의 끝에 도달하려고 하는 경로를 심볼릭하게 실행함
- 그 다음, FP 축소 단계에서, outermost 호출자부터 sink까지의 경로를 실행하고, 해당 호출자의 끝까지 계속 실행함
- 다른 취약점들에서는 ARBITER가 호출자에서 sink까지만 탐색함 ← CWE-252에서는 이렇게 안하면, 확인되지 않은 반환 값이 나중에 발신자 함수에 의해 확인될 수 있음
Description False Positives
- 필터링된 159 report 목록 중, VD를 생성하는 동안 가정을 위반하는 53개 report 발견
- 이유1 - Atomic operation confusion
- case1: cmov
- two detection에서 조건부 이동 명령인 cmov를 사용하여 주체(subject)의 반환 값을 기본 값으로 덮어쓰기 수행
- ARBITER는 주체의 반환 값에 대해 두가지 제약 조건 중 하나를 만족하는 단일 상태가 있으면 버그로 report함
- 그러나, 이 경우, cmov 명령이 새로운 상태를 생성하는게 아니고 주체의 반환 값에 대한 제약 조건을 추가하는 거라서, 저자의 분석은 이러한 사레를 버그로 잘못 분류함
- case2: setz
- 다른 두가지 false positive는 setz에 의해 발생
- 문제 해결: 코드 변환 메커니즘(code lifting mechanism) 수정해서 단일 cmov/setz 명령을 두개의 분기로 분할
- 이유2 - Unsupported error values
- subject의 반환 값이 SIZE_MAX 또는 UINT_MAX 일 수 있다고 가정하고, 오류를 각 64비트 또는 32비트 값으로 반환함.
- 따라서, VD는 반환되는 값이 SIZE_MAX 또는 UINT_MAX인지 확인함
- mmap을 제외한 모든 sink VD는 오류 시, UINT_MAX를 반환하고, mmap은 오류 시, SIZE_MAX 반환
- mmap의 경우, UINT_MAX와 0 모두 성공적인 반환 값으로 간주
- 따라서, 논문의 분석은 이러한 경우를 true positive로 잘못 label
- mmap의 반환값을 UINT_MAX와 비교해서 잘못 보고된 52개의 사례 발견
Vulnerability False Positives
- false positive는 보통 ARBITER의 분석 엔진의 제한에 의해 발생
Duplicate sinks
- sink가 여러 개 있을 때, ARBITER는 각각의 sink의 반환 값을 대상으로 심볼릭 표현 생성
- 그러나, sink와 생성된 심볼릭 표현 사이의 dependency는 유지되지 않음 - 그래서, 이러한 sink 중 하나의 반환 값이 에러를 확인하고, 다른 반환 값은 확인하지 않을 때, 확인되지 않은 반환 값에 적용된 제약 조건이 충족됨
- ARBITER는 실제로는 두번째 sink와 연결된 alert를 첫번재 sink의 alert 위치로 잘못 분류함.
- 근데, 두번째 sink와 연결된 alert를 올바르게 식별함
- 이런 alert 8개 발견
Unsupported API functions
- 일부 함수들이 오류 코드를 반환할 때, 프로그램은 현재 스레드의 errno 변수의 주소를 얻기 위해 함수 __errno_location 호출
- 프로그램은 반환된 주소를 역참조하여 오류 코드 가져옴.
- 그런데, angr는 __errno_location을 시물레이션한 후에도, 레지스터 rax를 덮어쓰거나 초기화하지 않음
- 그래서 ARBITER는 sink의 (주소가 아닌) 반환 값이 역참조되고 있는 것으로 가정하며, CWE-252의 VD에 따라 역참조된 값도 확인해야함
- ARBITER는 해당 check 가 누락된 경우에 alert 발생시킴
- 이 alert 6개 발견
Ignoring error checking functions
- 이 VD는 다른 VD와 달리, FP reduction 단계에서 sink 이후의 호출자 함수로부터 경로를 심볼릭하게 탐색한 후, 호출자 함수의 끝까지 이어서 경로 탐색
- 이유: 다른 VD와 달리, 이 VD에서는 sink에서의 버그 존재 결정 불가 - 탐색 경로의 복잡성 증가로 인해, 각 FP reduction 단계에서 추가적인 타임아웃 발생
- 따라서, 저자는 sink가 호출된 이후의 어떤 함수로의 호출도 심볼릭하게 탐색하지 않는 기능을 기반으로 프레임워크의 feature 사용함
- 이는, 만약 sink의 반환 값이 하위 루틴에 인자로 전달되어 그 값을 확인하는 작업을 수행한다면, ARBITER가 이 check를 감지하지 못할 수 있다는 것 의미
- 왜냐하면, 하위 루틴 자체가 탐색되지 않기 때문 - 이런 하위 루틴이 sink의 반환 값을 확인하는 데 사용되는 case 1개 발견
8.1.3 CWE-337: Predictable Seed in PRNG
- 총 350개 바이너리 파일에서 372개 함수에 걸쳐, 377개 CWE-337 alert 보고
- 수동으로 선별(triaging)해서, 372개 true positive, 2개 description false positive, 4개 식별 못함
Description False Positives
- 2개는
srand호출에 사용되는 시드가 시간의 반환 값과 커널의 난수 생성기에서 읽은 값과 같이 결합되어(e.g., xor연산 사용) 생성돼서 발생 - 논문의 VD는 시간 외에 다른 것이 PRNG의 시드로 사용되는지 테스트 안해서, ARBITER는 시간 외 다른 경우는 필터링할 방법 없음
Vulnerability False Positives
- 식별되지 않음
- 일반적인 경우:
srand(time(NULL));
8.1.4 CWE-134: Uncontrolled Format String
- 119개 바이너리 파일에서 139개 함수에 걸쳐, 158개 CWE-134 alert 보고
- 수동으로 식별해서 포맷 스트링 제어하고, 포맷 스트링 취약점을 트리거할 수 있는 true positive report 중 12개 결정
- 그러나, 이러한 report 중에서 142개가 포맷 스트링 취약점으로 이어지지 않았음
- 따라서, 3단계의 FP reduction에도 불구하고, 불충분한 컨텍스트 정보로 인해 false positive임을 발견함
Description False Positives
- ARBITER에 의해 생성된 142개 false positive 중 3개는 VD를 생성하는 동안 가정 위반해서 발생
- case 1 for 1개:
- 논문 목표: 포맷 지정자가 일정한 문자열이 아닌 함수의 printf 계열의 호출을 찾는 것
- 그러나, VD는 sprintf 계열 함수를 사용해서 여러 개의 상수 문자열을 결합해서 문자열을 생성하는 상황을 플래그화 함 - case 2 for 2개:
- 포맷 지정자를 NULL로 설정했는데, 이 값은 상수 문자열로 간주되지 않아서 alert 발생함
Vulnerability False Positives
- 36개 오탐은 G_gettext와 __dcgettext와 유사한 함수들에 의해 발생함
- 이 함수들은텍스트 문자열을 사용자의 모국어로 번역함
- ARBITER는 이 지식이 부족해서, 이 함수들에 의해 반환되는 문자열이 constant하지 않다고 가정했음 - false positive의 대부분은 불충분한 문맥 정보로 인해 발생
- false positive 중 103개가 call stack 위로 4레벨(또는 그 이상)인 호출자가 상수 문자열을 인자로 하는 후속 함수를 호출한 후에 발생했음을 발견
- 논문에서 FP reduction 단계는 3레벨 호출자만 포함해서, 이 상수들을 감지 못하고, posiotive로 잘못 분류함
8.2 Comparative Evaluation
- AFL 비교 평가
- ARBITER의 기존 동적 분석 회피의 장점 입증 - 소스코드 액세스의 장점이 있지만 ARBITER의 심볼 실행 기능(CodeQL 및 Infer)이 부족한 정적 분석 기법과 ARBITER 비교
- ARBITER를 사용해 Juliet 정적 분석 테스트 세트 분석 + 새로운 버그 식별
8.2.1 ARBITER vs. Dynamic Analysis (AFL)
- 취약점 감지를 위해 사용한 접근법은 퍼징의 동적 접근법과 다르지만, 대중적인 퍼징의 비교 평가는 ARBITER가 퍼징에 비해 제공하는 강점을 입증 가능
- ARBITER가 보고한 15개 바이너리에서 25개 정수 오버플로우 취약점에 대한 PoC를 생성하고, AFL이 이러한 취약점을 찾을 수 있는지 평가
- AFL
- 데이터셋 및 평가 과정
- 취약점이 포함된 15개 바이너리 중 7개만 독립형 바이너리고, 나머지는 하네스가 필요한 공유 개체
- 이 7개 바이너리 중 2개는 GUI/Network와 같은 추가 수동 환경 구성 없이 실행 불가; 나머지 5개는 AFL에서 생성된 바이트를 관련 command line인자 또는 환경 입력으로 사용하여 퍼징하는 래퍼 사용 - 결과
- AFL을 바이너리 당 하나의 코어에서 24시간 동안 실행
- 두개에서 AFL은 ARBITER와 동일한 버그 발견
- 하나에서는, AFL은 ARBITER와 다른 취약점 클래스에서 다른 crash 버그 발견
- 나머지 두개에서는 AFL은 버그 발견 불가
- 데이터셋 및 평가 과정
- ARBITER
- ARBITER는 탐지를 위한 PoC를 생성하는 동안, 충돌을 유발하는 적절한 command line 인자/ 환경 변수를 이미 이해하고 있어서, 해당 command line 인자/환경 변수 값만 퍼징하도록 래퍼 수정 - ARBITER의 도움을 받아 식별한 인자/환경 변수를 명시적으로 제어하지 않고, 이 바이너리를 퍼징하려고 했을 때, AFL은 각 바이너리를 퍼징한 24시간 후에 충돌 유발 불가
- ARBITER는 AFL이 놓치고 있는 버그 발견하고, 수동으로 식별할 필요 없이 진행함을 보여줌
8.2.2 ARBITER vs CodeQL
- CodeQL : LGTM 플랫폼에서 이용 가능한 소스 코드 분석 엔진
- ARBITER로 식별한 오류 중 CodeQLl이 얼마나 탐지할 수 있는지 평가
- ARBITER의 두가지 구현과 가장 유사한 CodeQL 쿼리
1. 반환 값에 대한 일관성 없는 연산
2. 제어되지 않는 할당 크기에서의 오버플로우 - CodeQL은 소스 코드 수준에서 의미론적 도메인만 분석 수행(이러한 쿼리는 ARBITER의 심볼릭 도메인과 근본적으로 다름)
- LGTM에서 CWE-252 ARBITER alert이 포함된 11개 프로그램과 CWE-131 ARBITER alert이 포함된 54개 프로그램 찾음
- LGTM은 이러한 프로그램에서 일관성 없는 반환 값 연산 탐지 불가
- 할당크기 오버플로우에 대해서는 실제로 하나의 true positive 발생
- 그러나, LGTM은 수동으로 확인한 false positive로 판단한 6개의 alert과 효과적으로 식별할 수 없는 3개의 alert 발생시킴 - CodeQL과 같은 소스 코드 수준의 분석 도구조차 놓치는 버그를 ARBITER가 식별할 수 있음
8.2.3 ARBITER vs Infer
- Infer: Java, C, Objective C를 위한 OCaml로 작성된 정적 프로그램 분석기.
- Infer는 null 포인터 역참조(null pointer dereference), 메모리 누수(memory leak), 코딩 규칙(coding conventions), 사용 불가능한 API 등과 같은 버그 클래스를 분석하기 위해 분리 논리(separation logic)와 이중-유추( bi-abduction) 사용
- 2017년, Infer는 무시된 반환 값(bug class of ignored return values)에 대한 지원을 제거
- 그래도 여전히 Java, C, Objective-C 프로그램에서 정수 오버플로우를 감지 기능을 지원 - PoC 작성해서 정수 오버플로우의 일부에 대해 Infer 평가
- 4개의 타겟은 Infer가 지원하지 않는 빌드 시스템이어서, 해당 소스 코드 파일에서 도구를 수동으로 실행
- 이 타겟들에 대해 정수 오버플로우 감지 불가 - Infer는 분리 논리 분석 능력이 sink를 트리거로 하는 취약점에 대해서는 덜 강력하고, 얕은 정수 오버플로우 취약점만 감지할 수 있다고 생각함
- 정적 분석, 심볼릭 실행의 조합인 ARBITER가 짱이다
8.2.4 ARBITER on Juliet
- Juliet Test Suite (v1.3): 합성적으로 생성된 데이터 셋
- 테스트 사례에 대한 ARBITER의 정수 오버플로우 VD 평가
- v1.3은 여러 CWE 유형에 대한 C/C++로 작성된 많은 테스트 케이스 포함 - C++에 새로운 sink 추가해서 이를 확장해서, CWE-131 VD인 CWEs, CWE-680 (정수 오버플로우로 인한 버퍼 오버플로우), CWE-190 (정수 오버플로우)를 적용
- 15680개 테스트 케이스 중 4536개가 Juliet 문서에 명시된 의도적 버그 가지고 있음
Description False Negatives
- 몇가지 테스트 케이스(for CWE-680)는 산술 연산에서 안전하게 사용할 수 없는 너무 큰 상수 값을 변수에 초기화해서 정수 오버플로우 발생시킴
- 그러나, ARBITER의 정수 오버플로우 VD는 상수 값 source에 대해 추론하지 않음
- 따라서, 실제로 Juliet이 버그로 간주하는 52개의 테스트 케이스를 negative로 잘못 분류함
Signedness adaptation
- ARBITER에서 오버플로우를 추론할 때, sink 함수의 타입 시그니처(e.g., malloc은 부호 없는 정수 사용)를 기반으로 데이터의 부호 결정
- 그러나, 이전의 모든 sink 함수는 부호 없는 정수 사용했으며, Juliet은 몇가지 부호 있는 sink 함수 제공
- Juliet의 부호 없는 오버플로우 테스트 케이스
- 부호 없는 인수를 받는 sink 함수인 printUnsignedLine 사용
- 기본적으로 비교가 부호 없는 비교이기 때문에, 정수 오버플로우 실험과 동일한 제약 조건 사용
- 부호 있는 테스트 케이스
- sink 함수인 printIntLine, printHexCharLine 및 printLongLongLine을 사용
- 부호 있는 비교를 위해 제약 조건 수정
Unexpected positives
- 결과에서, Juliet 테스트 제품군에서 "안전하다"고 분류된 몇몇 테스트 케이스들이 개발자도 모르게 취약하다는 것 발견
- 예) 32비트 부호 없는 정수에 대해 제곱 연산을 수행하는 결함이 있는 테스트 케이스는 listing1 참고
- ![[Pasted image 20240110221839.png]]
- 코드는 이 정수의 절대값을 계산하여, 그 값이 오버플로우 없이 제곱 연산을 수행할 수 있을 만큼 충분히 작은 것을 보장하려하고, 이를 상한 값(upper bound)과 비교함
- 이때, 절대값은 부호 있는 정수를 사용하여 abs 함수 사용하여 계산됨
- 이는 부호 없는 데이터 타입을 부호 있는 타입으로 변환하는 것으로 인해, 큰 값이 체크를 통과하고, 이후 오버플로우로 이어질 수 있음
- 예) data의 값이 UINT_MAX(0xFFFFFFFF)인 경우, abs 함수는 값 1을 반환해, 크기 체크 통과하지만, 곱셈의 결과는 값 0xFFFFFFFE00000001이 되어 32비트 정수 오버플로우 발생 - ARBITER는 Juliet 테스트 suite 내에서 이와 같은 잘못된 테스트 케이스 190개 발견
- 이들이 실제로 버그 유발 시키는지 확인하기 위해 각각의 PoC 작성해서, 개발자들에게 전달(회신 아직 못받음)
- 그래서 이 190개 테스트 케이스를 ground truth로 간주
ARBITER’s results
- Adaptive False Positive 필터링 사용하여 0(추가 필터링 없음), 1, 2로 조정한 ARBITER 실행
- FP 필터링 0단계: ARBITER는 2411개 TP, 2890개 FP 보고
- 1단계: FP 2121개, TP 2197개(여러 경로의 심볼릭 추적 시간 초과로 인한 것으로 추정)
- 2단계: TP 3234개(UCSE의 추적 가능성을 높이는 추가적인 심볼릭 제약 조건 때문), FP 1015개 - ARBITER는 precision 0.77, recall 0.57 달성(Figure 2)
- ![[Pasted image 20240110222547.png]]
Literature comparison
- Juliet 데이터셋 기반으로한 다양한 도구들은 다양한 접근 방식 사용
- 대부분의 도구들은 소스코드를 필요로 함
- Yang이 제안한 기법:
- 취약성 패턴을 인식하는 머신러닝 모델 사용하여 감지
- precision 1.00, recall 0.995
- Juliet 테스트 suite에서 훈련된 동일한 모델을 실제 세계의 NVD 데이터베이스에서 취약점 감지하는 데 사용했을 때: precision 0.0036, recall 0.539 - ARBITER가 Juliet 테스트 케이스에서 감지한 오류 테스트 케이스를 다른 도구들은 감지 못함
- 소스코드 기반 기술의 경우, 이는 ARBITER가 바이너리 레벨에서 동작하여 abs 함수의 예외적인 동작을 모델링하지 못했기 때문일거라 예상
- 머신러닝 기술의 경우, Juliet의 stated ground truth를 기반으로 훈련되어 정확하지 않을 것이라 추정
9 Limitations and Discussion
- 취약점 유형에 대한 한계와 여러가지 분석상의 한계
CWE coverage
- ARBITER의 효율성은 섹션 3에서 말한대로, PC 취약점으로 분류될 수 있는 CWE 유형으로 제한됨
- PC 요구사항의 일부 한계: ARBITER가 사용하는 정적 분석, 특히 분석 대상을 신속하게 찾고 제한된 분석 맥락을 지원하기 위한 기반에서 비롯.
- 다른 것들은 ARBITER가 alert을 확인하기 위해 심볼릭 실행을 사용함으로써 부과됨 - ARBITER의 요구사항을 충족시키지 못하는 예시 CWE로는 CWE-362(race-condition)
- P2 위반 : sink(스레드 간에 공유되는 변수)를 식별하는 어려움
- P3 위반 : 스레드 컨텍스트를 통해 변수 접근에 대한 추론 필요함
- P1 위반 : 실행 순서가 데이터 흐름 분석 결과에 미치는 영향
Static analysis limitations
- 정적 분석은 VD 주체를 찾을 수 있어야 함
- 인라인 함수, 정적으로 링크된 프로그램 또는 스트립된 프로그램은 이 작업을 어렵게 하지만 불가능하진 않음
- 분석은 일정 수준으로 제어 흐름과 데이터 흐름 복구해야함
- 크고 복잡한 프로그램은 이 작업에 매우 많은 시간 소요 → 확장성에 영향
- ARBITER는 aliasing 문제가 잇는 전통적인 정적 분석 문제로 인해 문제 발생 가능
- false positive rate 증가 발생
Dynamic analysis limitations
- ARBITER의 동적 component는 UCSE를 사용해 프로그램 슬라이스 실행해야함
- 심볼릭 실행의 한계가 있음
- 이러한 슬라이스가 너무 큰 경우, 동적 실행은 state explosion 겪어서, 이 단계에서 속도 저하나 실패 발생 가능
- 논문의 DSE 단계의 UC 특성(nature)로 인해, ARBITER는 테스트하는 프로그램 슬라이스에 대한 범위 부족과 관련된 제약으로 false positive 발생 가능
Take-away
- ARBITER는 기술적 한계가 있어도, 실제 소프트웨어의 대규모 분석에서 실행 가능한 결과 얻을 수 있음
- 76516개 바이너리 파일을 완전히 동적 분석으로 분석하는 건 현실적으로 불가능
- 지금까지 확장가능하고 정확한 정적 분석 기술 개발 안됨
VD Implemenation
- VD를 구현하기 위한 첫 과제는 대상 취약점 유형을 이해하는 것
- 분석가는 대상 취약점의 컴포넌트들(e.g., source 및 sink, 데이터 플로우 속성)을 ARBITER에서의 VD에 해당하는 속성들과 매칭해야함
- 이런 매칭 작업 후, ARBITER는 API를 사용해 VD를 상대적으로 쉽게 구현할 수 있음
- 그러나, VD 구현 후, 몇가지 예외적 상황 발생 가능
- 평가 도중 섹션 8.1.1에서 설명한 비현실적인 데이터 요구 사항의 경우와 섹션 8.1.4에서 설명한 gettext 함수 패밀리의 경우와 같이 일부 false positive를 초래하는 문제 발견하여 수정함
- 새로운 예외적 상황은 새로운 VD 구현할때마다 발생
- 이런 상황 식별되면, 수정은 간단함 - VD의 구체적 구현은 Appendix B
Applying ARBITER
- false positive rate은 거의 50%.
- 유사한 확장성을 가진 바이너리 application과 비교했을 때 개선되었지만, 개발자들은 40% 미만을 원함
- 따라서, ARBITER 결과는 대상 application을 수동으로 검토하여 취약점 조건을 유발할 수 있는지 확인하는 것과 결합하는게 가장 좋음
- 거짓 양성을 제거할 수 있는 정적 분석 보고서를 검증하는 것을 목표로 하는 기존 동적 접근 방식과 결합하여 사용될 수 있음
10 Conclusion
- ARBITER라는 새로운 프레임워크를 제안
- 정적 분석 기법과 동적 분석 기법의 강점을 결합하여 프로그램의 어떤 깊이에서도 복잡한 보안 취약점을 식별하는 데 사용
- ARBITER를 사용하여 우분투 패키지 저장소의 상당한 부분에서 VD(보안 결함)를 확인하고 보고할 수 있음
- 소프트웨어 개발 생명주기에서 사용되며 보안 연구자들이 VD를 분석하고 검증하여 소프트웨어를 보호하는 데 활용될 것으로 기대
Appendix
A - ARBITER에 의해 발견된 취약성에 대한 공개
- 저자가 공개한 취약점 목록
- CVE-2018-18311: Integer overflow in Perl before 5.26.3
- Integer overflow in Python-PIL
- Integer overflow in LibTIRPC
- Unchecked setuid in CSound
- Unchecked setuid in ping and ping6 in Inetutils
B - Specializing ARBITER
- ARBITER는 특정 취약점 클래스의 인스턴스를 쉽게 감지할 수 있도록 설계된 일반적인 분석 프레임워크로 구현해서, 분석가들은 source, sink 및 동적 제약조건을 지정하는 짧은 취약점 설명(VD) 구현하면 됨
- ARBITER는 angr 바이너리 분석 엔진 위에, 약 2000줄의 파이썬으로 구현
- angr를 ARBITER에 필요한 개선 사항을 구현하기 위해 약 140줄 코드 수정 - VD를 위한 세가지 기능 구현(평가를 위해 선택한 CWE-252 — “Unchecked Return Value”, CWE-337 — “Predictable Seed in Pseudo-Random Number Generator”, and CWE-134 — “Controlled Format String”)
-specify_sources(binary): 프로그램 위치들의 세트(e.g., 함수명 또는 주소) 및 변수 사양들(e.g., 리턴 값, 함수에 대한 특정 인수) 반환해야함. 이 위치들은 ARBITER의 정적 분석에서 잠재적으로 취약한 흐름들 찾기 위한 source로 사용됨
-specify_sinks(binary): source들과 유사하게, 잠재적인 취약한 흐름들 찾기 위한 sink로서 사용될 변수들의 집합 지정
-apply_constraint(state, sources, sink): 잠재적으로 취약한 흐름을 감지하고 상징적으로 분석할 때 이 함수 이용해서 심볼릭 취약점 조건에 대한 흐름 확인 - CWE-131: Incorrect Calculation of Buffer Size
```python def specify_sources(binary): return {} # defaults to function arguments def specify_sinks(binary): return { "malloc": 0 } # first argument to malloc def apply_constraint(state, sources, sink): for source in sources: if source.length < sink.length: #equalize bit length of source and sink source = source.zero_extend(sink.length-source.length) state.solver.add(sink < source) ``` - CWE-252: Unchecked Return Value
```python def specify_sources(binary): # specify return values (index 0 in arbiter) of security-relevant system calls return { 'access': 0, 'chdir': 0, 'chown': 0, 'chroot': 0, 'mmap': 0, 'prctl': 0, 'setrlimit': 0, 'stat': 0, 'setuid': 0, 'setgid': 0, 'setsid': 0, 'setpgid': 0, 'setreuid': 0, 'setregid': 0, 'setresuid': 0, 'setresgid': 0 } def specify_sinks(binary): # arbiter shorthand for the return value of the _caller_ of these functions return [ 'access', 'chdir', 'chown', 'chroot', 'mmap', 'prctl', 'setrlimit', 'stat', 'setuid', 'setgid', 'setsid', 'setpgid', 'setreuid', 'setregid', 'setresuid', 'setresgid' ] def apply_constraint(state, sources, sink): if state.satisfiable( extra_constraints=[sources[0] == -1]): # target function allows both negative and positive values (indicating absence of checks) state.solver.add(sources[0] == 0) else: # reject the state by making it unsatisfiable state.solver.add(False) ``` - CWE-134: Controlled Format String
```python def specify_sources(binary): return {} # defaults to function arguments def specify_sinks(binary): # the format argument of string formatters return { 'printf': 0, 'fprintf':1, 'dprtinf': 1, 'sprintf': 1, 'vasprintf': 1, 'snprintf': 2, 'fprintf_chk': 2, 'dprintf_chk': 2, 'sprintf_chk': 3, 'vasprintf_chk': 2, 'asprintf_chk': 2, 'snprintf_chk': 4 } def apply_constraint(state, sources, sink): # check for the format string in the ELF addr = state.solver.eval(sink, cast_to=int) elf_address = \ state. project.loader.find_section_containing(addr) if elf_address is not None: state.solver.add(False) ``` - CWE-337: Predictable Seed in PRNG
```python def specify_sources(binary): # return value of time() return {"time": 0} def specify_sinks(binary): # first argument of srand() return {"srand": 0} def apply_constraint(state, sources, sink): # no constraints --- purely a data flow problem pass ```
C - Performance Evaluation
- 성능 평가를 위해 섹션 3.1에서 설명한 정수 오버플로우 탐지를 잘 테스트된 coreutils suite의 105개 바이너리 모두에 대해 실행
- 결과
- 27608개 함수 분석하고, 그 중 763개 source와 sink 찾는 데 884초 소요됨
- 데이터 플로우 복구 단계에서 763개 함수 중, 62개 함수에 대해 기본 angr 프레임워크에서 실패 경험
- 나머지 701개 경우, 1303개 allocator 호출 사이트로 데이터 플로우를 성공적으로 추출
- 이 중, 364개는 크기가 일정했고(데이터 의존성 없음), 939개는 567개 함수에 걸쳐 데이터 플로우 allocator 호출 사이트를 나타내는 경로 도출
- 총 4585초 소요
- UCSE로 각 경로를 심볼릭 실행해서, 구현 문제로 인한 45건의 실패, 251건의 타임아웃(플로우 당 기본값 10분 타임아웃), 133건의 satisfiable path(즉, 정적 분석의 over-approximation), 510건의 데이터 플로우 predicate 발생.
- 총 15705초 소요
- 이 510개의 predicate를 VD description과 비교하여 체크하는 것은 124개 후보 alert 발생
- 그러나, 2개의 caller의 레벨로 이들의 false positie 필터링 수행한 후, ARBITER는 124개 false positive 모두 성공적으로 제거
D - Detailed Evaluation Results
- CWE-131, CWE-134, CWE-252, CWE-337에 대해 바이너리, 함수, 식별된 sink, 결정된 데이터 흐름, 탐색 경로, 분석된 state, 발생한 alert 설명(Table 6)
- ![[Pasted image 20240111130605.png]]
E - Case studies
- ARBITER로 식별된 버그의 case study
Case Study: Integer Overflow in Perl
- ARBITER로 5.28 이전의 Perl 런타임 버전에 존재하는 취약점 발견
- 힙 오버플로우 발생 가능, 잠재적으로 임의 코드 실행 발생 가능
- Listing 2
- ![[Pasted image 20240111134014.png]]
- 코드 설명
- 사용자가 환경 변수의 값을 초기하하기로 결정하면 Perl_my_setenv 함수 호출
- 변수 nam과 val은 각각 환경 변수의 이름과 값임
- 이 함수에서 nam과 val 문자열의 길이를 저장하기 위해 두개의 32비트 정수 nlen과 vlen 사용
- 그 다음 이 정수들의 상수 2와 더한 합으로 힙에 버퍼 할당
- line 14에 추가된 이 산술이 정수 오버플로우로 이어질 수 있고, 그 결과 작은 버퍼가 할당될 수 있는 지점임
- line 15에서 함수 my_setenv_format은 새로 생성된 버퍼에 두 문자열을 개별적으로 복사하고, 그 결과 제어된 입력으로 힙 버퍼 오버플로우 발생
- 이 취약점은 CVE-2018-18311로 할당되어, 현재 수정됨
- 그러나 2001년에 도입됐는데, 18년까지 탐지되지 않은 상태였음
Case Study: Integer overflow Vulnerability in Pillow
- ARBITER는 python-pil 패키지에서 취약점 발견 → 유지보수 관리자에게 보고해서 수정됨
- ImagingMemorySetBlocksMax 함수에서 발생함
- Listing 3
- ![[Pasted image 20240111135818.png]]
- 정수 오버플로우 취약점은 line 5에서 32비트 부호화된 정수 blocks_max에 상수 곱한 후, realloc의 두번째 인자로 사용됨
- 64비트 환경에서 realloc의 두번째 인자는 64비트 값이지만, blocks_max는 32비트 값임
- blocks_max는 부호화된 정수이므로, 64비트 값으로 부호 확장됨. 이 상황에서 정수 오버플로우가 발생하는 유일한 방법은 부호 확장자가 64비트 값이 큰 경우이며, 이는 처음 blocks_max가 음의 값일 경우에만 발생
- 그러나, 이 ImagingMemorySetBlocksMax함수를 호출하는 코드를 보면, 이 취약점이 트리거될 수 없음을 알 수 있음(Listing 4)
- ![[Pasted image 20240111140142.png]]
- 코드 설명
- PyArg_ParseTuple은 args 개체에서 32비트 정수 값 추출하고, 그 결과를 blocks_max 변수에 저장하는 데 사용됨
- 이 값을 값 0과 바로 비교하고, 더 낮은 값으로 판명되면 올가 발생
- 따라서 64비트 환경에서는 이러한 취약점 트리거 불가
- 그러나, 32비트 환경에서 realloc하기 위한 두번째 인자는 32비트 값인데, 이것은 곱셈을 하는 동안 32비트 정수 공간을 감쌀 수 있는 양의 값을 생성하는 것을 가능케함
- 저자는 곱셈 후에 0의 값이 될 그런 양의 값을 찾을 수 있었음
- reallco의 설명에 따르면, 두번째 인자가 0일 때, 그건 calling free와 동일하다고 한다.
- 포인터가 null로 설정되지 않으면, 이건 UAF(Use-After-Free) 시나리오가 된다
- 이 취약점을 유지보수자들에게 보고해서, 병합된 패치도 제출함
- 그러나, 유지보수자들은 이 취약점을 트리거하기 위해서는 arbitary 파이썬 실행이 필요해서, 보안 위험으로 간주할 수 없다고 주장
Case Study: Unchecked RetVal in Csound
- 섹션 3.2의 예에 기술된 것 처럼, SETUID 기능을 갖는 바이너리에서 권한을 낮추는 일반적인 패턴은 프로세스를 시작한 사용자의 실제 사용자 ID를 얻기 위해 getuid를 호출하는 것 포함
- 그 후, 바로 setuid 호출해서 프로세스의 사용자 ID를 유효한 사용자 ID에서 실제 사용자 ID로 변경
- 그러나 소프트웨어가 setuid 권한을 성공적으로 드롭했는지 확인하지 않으면, 권한 상승 가능
- Csound에서 그런 동작 케이스 발견(Listing 5)
- ![[Pasted image 20240111141359.png]]
- 코드 설명
- setuid는 함수 set_rt_priority 안에서 호출되어 루트 권한 낮춤.
- 이 함수 set_rt_priority가 반환된 후, 프로그램은 로그 파일 생성하고 기록
- 이 경우, setuid에 오류 발생하면, 시스템에 남게되는 로그 파일을 root가 소유하게 돼서, 위험한 상황 발생
- setuid와 같은 중요한 API 함수의 반환값을 무시하면, 보안 취약점 발생해서, 컴파일러는 종종 이런 API 반환 값이 사용되지 않는 상황을 보고하기 위해 경고 생성
- 그러나, listing 5에서 ignore_value 매크로 사용해서 컴파일러에서 생성된 경고 억제함
- 이에 대한 패치 제출해서 수정됨
