Ferry: State-Aware Symbolic Execution for Exploring State-Dependent Program Paths
analysis :: paper

Background
Statement와 state의 차이
program statement는 프로그램의 실행 가능한 코드 라인(코드 자체)을 말한다. 예를 들어, 조건문, 반복문, 함수 호출 등이 프로그램 문장에 해당한다. 프로그램 문장은 특정 작업을 수행하거나 특정 동작을 나타내는 역할을 한다.
program state는 프로그램이 실행되는 동안의 전반적인 상태를 나타낸다. 프로그램 상태는 변수의 값, 메모리 상태, 함수 호출 스택 등을 포함한다. 프로그램이 실행되면서, 상태는 변경될 수 있고, 이에 따라 프로그램의 동작이 달라질 수 있다.
- 프로그램 상태의 변화는 statement의 실행 결과에 영향을 줄 수 있음
Data box
프로그램 내에서 특정 데이터 또는 변수가 포함되는 범위나 영역을 나타낸다.
데이터의 유효 범위를 나타내며, 해당 데이터가 접근 가능한 지역을 제한하는 역할을 한다.
SDVO 명령어
State-Describing Variable Operation instruction
상태를 설명하는 변수를 조작하는 명령어
프로그램 내의 상태 설명 변수
상태 설명 변수는 특정 동작이나 이벤트의 발생 횟수를 나타내는 상태를 저장하는 데 사용된다.
예
isRunning변수: 프로그램이 현재 실행 중인지 여부를 나타내는 상태를 저장함currStep변수: 프로그램의 현재 진행 단계를 나타내는 상태를 저장함
프로그램 분석에서의 상태 종속적이란?
프로그램 내에서 발생하는 다양한 상태가 서로 종속적인 관계를 가지고 있는 것을 의미한다. 이는 한 상태가 다른 상태에 영향을 주거나, 상태 간에 의존성이 존재하는 상황을 말한다.
프로그램 분석에서 상태 종속성을 확인하는 방법은 다양하다. 주로, 코드의 의존성 그래프를 분석하거나, 실행 흐름을 추적하여, 상태 간의 종속성을 확인한다.
명시적 데이터 종속성
프로그램에서 변수 또는 데이터 간의 직접적인 종속성을 말한다. 데이터 종속성은 한 데이터의 값이 다른 데이터의 값에 의존하는 관계를 나타내며, 명시적 데이터 종속성은 이러한 종속성이 프로그램 코드에서 명시적으로 표현되어 있는 경우를 말한다.
예
class Rectangle {
int width;
int height;
int calculateArea() {
return width * height;
}
}위 예제에서 calculateArea 메서드는 width와 height 멤버 변수에 종속되어 있으며, 이를 통해 사각형의 넓이를 계산한다.
프로그램 분석에서 guard
조건문 또는 제어 흐름에 따른 분기를 통제하는 개념을 의미한다.
guard는 일반적으로 조건식을 포함하고 있으며, 해당 조건식의 참/거짓 여부에 따라 특정 코드 블록이 실행되거나 건너뛰게 된다.
예
int number = 10;
if (number > 0) {
// 조건식(number > 0)이 참일 때 실행되는 코드 블록
printf("Number is positive.");
} else {
// 조건식(number > 0)이 거짓일 때 실행되는 코드 블록
printf("Number is non-positive.");
}위 예제에서 if 문의 조건식인 number > 0은 guard 역할을 합니다. 이 조건식의 결과에 따라 프로그램의 제어 흐름이 결정되며, number의 값이 양수인 경우 첫 번째 코드 블록이 실행되고, 그렇지 않은 경우 두 번째 코드 블록이 실행됩니다.
Guard vs Path constraint/condition/predicate
- guard: 조건문에서 사용되는 조건식
- path constraint: 프로그램의 특정 경로에 대한 제약 조건(e.g., x>y, x<=y)
- path condition: 특정 경로에서의 조건식(e.g., x>y, x<=y)
- path predicate: 특정 경로에서의 조건을 나타내는 논리식(e.g., x>y&&x>y)
Input partitioning
- 소프트웨어 테스트에서 사용되는 전략 중 하나
- 테스트 케이스를 여러 그룹이나 파티션으로 나누는 것을 말한다.
- 입력 파티셔닝은 테스트 케이스를 다양한 관점에서 분할하여 효율적으로 테스트를 수행하고 검증하는 데 도움이 된다.
- 이를 통해 테스트 커버리지를 높일 수 있고, 테스트의 효율성을 개선할 수 있다.
- 일반적으로 입력 파티셔닝은 입력 값의 특성에 따라 파티션을 나눈다.
- 범주형 변수의 경우, 각각의 가능한 값을 가지는 파티션으로 나눌 수 있고, 숫자형 변수의 경우, 값의 범위나 구간에 따라 파티션을 나눌 수 있다.
Unicorn 엔진
- 가상화된 실행 환경에서 프로세스나 코드를 실행하는 데 사용되는 CPU 에뮬레이션 엔진
- 주로 바이너리 분석, 디버깅, 보안 연구 등에 활용됨
- 다양한 아키텍처와 플랫폼 지원
- 실제 CPU 동작을 에뮬레이션하여 프로세스나 코드를 실행할 수 있어서, 이를 통해 다양한 운영체제나 프로그램을 가상 환경에서 실행하고 분석할 수 있음
Abstract
심볼릭 실행과 퍼즈 테스트는 경로 탐색 방법을 통해 프로그램 분석에 효과적인 접근법이다. 최신 심볼릭 실행과 퍼징 기술은 조건문을 충족시키기 위한 유효한 프로그램 입력을 생성할 수 있다. 그러나 이러한 기술들은 실제 프로그램에서 구현된 유한 상태 기계 모델을 탐색하는 능력이 매우 제한적이다. 이는 실제 프로그램의 상태에 따라 분기되는 상태 종속적인 분기들(state-dependent branches)이 현재 프로그램 입력이 아닌 프로그램 실행에 의존하기 때문이다.
본 논문은 실제 프로그램에서 상태 종속적인 분기를 철저히 탐색하기 위한 첫번째 시도이다. 우리는 프로그램 상태를 인지하는 심볼릭 실행 기술을 소개한다. 이 기술은 심볼릭 실행 엔진이 상태 종속적인 분기를 효율적으로 탐색할 수 있도록 안내한다. 이 논문에서 보여주듯이, 상태 종속적인 분기는 많은 중요한 프로그램에서 흔히 발견되며, 이러한 프로그램은 응용 로직을 충족하기 위해 상태 기계를 구현한다. 상태 종속적인 분기가 있는 임의의 프로그램을 심볼릭 실행하는 것은 어렵다. 왜냐하면, 상태 기계 구현에 대한 통일된 specification이 부족하기 때문이다. 이 어려운 문제에 직면하여, 본 논문은 중요한 프로그램 클래스에서 현재 프로그램 상태와 이전 입력 사이에 널리 존재하는 데이터 의존성을 인지한다. 이러한 프로그램에 대한 통찰력은 우리가 이 작업에 성공적인 첫걸음을 내딛을 수 있도록 도움을 준다. 우리는 프로그램 상태를 자동으로 인식하고, 상태 종속적인 분기를 탐색하기 위해 효율적으로 심볼릭 실행 엔진을 안내하는 도구인 Ferry를 설계하고 구현했다. Ferry를 13개의 다양한 실제 프로그램과 포괄적인 데이터셋인 Google FuzzBench에 적용한 결과, Ferry는 최신 심볼릭 실행 엔진 두개보다 더 높은 블록 및 분기 커버리지를 달성하며, jhead에서 3개의 0-day 취약점을 발견하는 데 성공했다. 추가적인 조사 결과, Ferry는 기존의 심볼릭 실행기와 퍼저보다 더 어려운 코드를 탐색할 수 있음을 보여준다. 또한, Ferry는 수집된 15개의 상태 종속적인 취약점과 6개의 주요 프로그램 테스트 스위트를 통해 기존의 심볼릭 실행기와 퍼징 접근법보다 더 많은 프로그램 상태 종속적인 취약점에 도달할 수 있음을 보여준다. 마지막으로, Ferry를 LAVA-M 데이터셋에서 테스트하여 그 강점과 한계를 이해한다.
1 Introduction
심볼릭 실행과 퍼징
심볼릭 실행과 퍼즈 테스팅(퍼징)은 효율적인 프로그램 경로 탐색 방법을 통해 동적 분석과 소프트웨어 테스트에 효과적인 접근법으로 잘 알려져 있다. 초기 연구에서는 무작위로 생성된 프로그램 입력에 의존했지만, 최신 기술은 조건문을 충족시키고 후속 분기에 도달하여 높은 코드 커버리지를 달성하기 위해, 유효한 프로그램 입력을 생성하는 방법에 초점을 맞추고 있다.
이전 연구의 측정 가능한 성과에도 불구하고, 기존의 접근법과 도구는 프로그램에 의해 구현된 유한 상태 기계 모델에서 프로그램 상태에 따라 다른 분기를 탐색하는 능력이 매우 제한적이다.
그림 1에 대한 예시
이 문제를 그림 1에 나와있는 실제 예시를 통해 설명한다.
이 예시는 비디오 입력을 구문 분석하기 위해 상태 기계를 구현한 것이다.
-
최신 기술 접근법
루프의 각 반복의 입력으로부터box_type의 값이 무조건적으로 로드되기 때문에, line 6의 분기를 효과적으로 탐색할 수 있다. -
stateful progrma logic을 이용한 접근법
그러나, 상태 기반 프로그램 로직(stateful program logic)을 용이하게 하기 위해,
실제 프로그램은 특정 변수를 사용하여 프로그램의 내부 상태를 저장하고, 조건문은 현재 프로그램 입력이 아닌, 내부 상태에 따라 다를 수 있다.
예를 들어, 그림 1의 line 9는 프로그램 변수인 saved_size에 의존한다.
이 프로그램이 실행될 때,
saved_size는 현재 반복에서 처리되는 프로그램 입력에 따라 결정되지 않는다(box_type이 "tx3g"이고, line 7의 분기가 선택된 경우),
대신 이전 반복에서 수정되어야 한다(box_type이 "trak"일 때, 20번째 줄의 분기를 선택한다).
본 논문에서는 saved_size를 상태 설명 변수(state-describing variable)로 부르고, 이처럼 변수에 의존하는 데이터 종속적 조건문에 의해 보호되는 분기를 상태 종속적 분기(state-dependent branches) 라고 한다.
그림 1-motivation 예제

위 예시에서, saved_size = -1;인 디폴트 상태에서는 버그가 없다. 따라서, line 11의 분기는 항상 선택된다.
특정한 입력 시퀀스 집합만이 프로그램 상태를 변경하고, line 16에서 정수 오버플로우 취약점을 트리거할 수 있다. 이 시퀀스는 두개의 입력으로 구성되며, 각각의 입력은 개념적으로 데이터 박스이다.
- 데이터 박스
각 데이터 박스는 필요한 메타데이터인box_size와box_type을 포함하며, 선택적으로 페이로드 데이터도 포함할 수 있다. 프로그램은 루프를 구현하고, 데이터 박스는 루프의 다른 반복에서 순차적으로 처리된다. 첫번째 "trak" 데이터 박스는saved_size를 해당 박스의 크기로 설정하여 프로그램 상태를 변경한다(양수 값). "tx3g" 박스를 처리하는 다음 반복에서, 크기가 0보다 크므로(line 13이 선택됨), 공격자는 신중하게 저장된box_size값을 사용하여 취약점을 트리거할 수 있다.
이렇게 상태에 민감한 프로그램 로직은 최신기술의 (암묵적인) 가정을 깨뜨린다.
즉, 프로그램은 각 입력의 각 부분을 독립적으로 처리하고,
이전 입력에 의해 발생하는 상태 변경이, 이후 입력의 처리 방식에 미치는 영향은 무시할 수 있다는 것이다.
반면에, 우리는 많은 real-world 프로그램이 응용 프로그램 로직을 충족하기 위해, 상태 기계의 맥락에서 상태에 따라 다른 분기를 구현한다는 것을 관찰했다.
기존의 심볼릭 실행기는 상태에 따라 다른 분기를 효율적으로 탐색하지 못하고, 그림 1과 같은 경우에서, 취약점을 찾을 수 없었다(섹션 2에서 논의한 내용과 같음).
우리의 방법이 어떻게 예시에서 취약점을 찾는지는 섹션 4에서 설명한다.
우리는 상태에 따라 다른 분기가 많은, 중요한 real-world 프로그램에서 이러한 상태 의존적인 분기가 흔하게 나타나는 것을 발견했다.
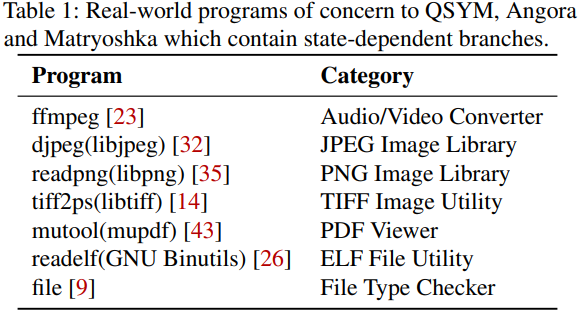
이전 연구들에 관련된 다양한 범주의 7개 주요 프로그램을 수동으로 검토한 결과(표 1), 모두 수십~수백개의 상태 의존적인 분기를 포함하는 복잡한 상태 기계를 구현하고 있음을 보여준다.
상태 의존적인 분기의 존재는 기존 접근 방식의 경로 탐색 효율을 두가지 측면에서 저하시킨다.
- 내부 프로그램 상태에 대한 적은 지식으로, 기존 방법은 프로그램 상태를 다양하게 탐색하는 원하는 프로그램 입력을 생성할 수 없으므로 상태 의존적인 분기의 탐색이 매우 제한적이 된다.
- 프로그램 statement(구문)는 다른 프로그램 상태에서 다양한 동작을 할 수 있다(e.g., 그림 1의 line 16은 기본적으로 버그가 없고, 프로그램 상태가 변경될 때만 취약함). 이는 단순히 statement에 도달하는 것만으로는 충분하지 않으며, 대신 다른 프로그램 상태에서 완전히 조사되어야 한다. 이는 기존 도구의 상태 탐색 능력을 평가하기 위한 새로운 지표가 필요함을 요구한다.
본 논문에서, 우리는 프로그램 소스코드와 입력 시퀀스에 대한 사전 지식이 필요하지 않은 최초의 프로그램 상태 인식(symbolic execution) 프레임워크인 Ferry를 제안한다.
Ferry는 컴파일된 바이너리 파일에서 작동한다. 이는 자동으로 상태 설명 변수(state-describing variable)를 인식하고, 이를 사용하여 Symbolic Execution을 유도하고, 상태 의존적인 분기를 탐색한다.
또한, Ferry의 효율성을 더욱 개선하기 위해, 여러가지 최적화 기법을 제안한다. 우리는 Ferry를 널리 사용되는 Symbolic Execution 엔진인 angr와 KLEE, 그리고 인기있는 퍼저인 AFL, Angora, QSYM과 비교하여 13개의 실제 프로그램에 대해 실험을 수행한다. 이 프로그램은 표 1에 나열된 7개 프로그램과 Google FuzzBench를 포함한다.
표 1
우리의 실험 결과, 추론된 상태 설명 변수(state-describing variable)를 사용하는 Ferry는 이 두 Symbolic Execution 엔진보다 평균적으로 38%, 42% 더 많은 기본 블록과 42%, 47% 더 많은 분기를 탐색할 수 있고, 세개의 퍼저보다 18%, 21%, 8% 더 많은 기본 블록과 22%, 21%, 8% 더 많은 분기를 탐색할 수 있다.
실험 도중, Ferry는 jhead에서 세개의 0-day 취약점을 성공적으로 찾아냈다.
더 나아가, Ferry가 더 많은 프로그램 상태를 탐색할 수 있음을 입증하기 위해, River라는 테스트 스위트를 구축했다. 이 테스트 스위트는 6개 프로그램과 160개의 삽입된 취약점으로 구성되어있다. 삽입된 취약점은 서로 다른 상태 깊이에 분포되어 있다. 즉, 취약점까지의 경로에 참여하는 상태 의존적인 분기의 최소 개수이다.
이 테스트 스위트는 상기한 Symbolic Execution 엔진과 퍼저를 평가하는 데 사용된다. 동일한 시간 제한 내에서 Ferry는 모든 160개의 취약점을 찾아내는 반면, 다른 도구들은 얕은 깊이의 삽입된 취약점 중 최대 41%만을 보고한다.
우리는 이 테스트 스위트가 Ferry의 효과성을 명확하게 보여주며, 실제 프로그램의 깊은 로직(e.g., 상태 의존적인 분기)을 탐색하기 위한 미래의 연구 능력을 평하기 위한 의미 있는 기준을 제공한다고 믿는다.
Contribution
- 우리는 심볼릭 실행에 대한 연구 방향 중 하나인 프로그램 상태 인식(program-state-aware) 심볼릭 실행을 소개한다. 이는 심볼릭 실행에서 미처 연구되지 않은 문제를 중점적으로 다루는 새로운 연구 방향성이다.
- 우리는 state-dependent 분기를 가진 실제 프로그램이 직면하는, 복잡한 심볼릭 실행 도전 과제에 대한 새로운 통찰력을 제공한다. 우리는 심볼릭 실행 엔진 Ferry를 구현하기 위해 새로운 알고리즘과 휴리스틱을 제안한다.
- 우리는 Ferry를 실제 프로그램에 적용할 때 발생하는 실용적인 도전과제를 인식하고, Ferry의 효율성과 확장성을 더욱 개선하기 위한 최적화 기법을 제안한다.
- 우리는 Ferry를 평가하여, 실제 프로그램에서 "깊은" 보안 관련 취약점을 찾는 데 있어서, 최신 접근 방법과 도구들보다 훨씬 효과적이고 효율적임을 보여준다.
2 Problem Statement and Analysis
Insight 1: 심볼릭 실행 엔진의 주요 장애물은, 프로그램의 내부 상태를 무시하는 것으로, 이로 인해 state-dependent 분기를 비효율적으로 탐색한다.
최신 심볼릭 실행 엔진들은 논리적인 프로그램 상태와 심볼릭 상태의 차이로 인해 state-dependent 분기(e.g., 그림 1의 line 9)를 효율적으로 탐색할 수 없다(다른 심볼릭 실행 연구에서 논의된 실행 경로, 경로 제약조건 및 모든 변수와 심볼릭 표현 사이의 매핑 포함).
그림 1에서의 중복 탐색으로 인한 경로 폭발
그림 1의 예시는 세가지 다른 논리적인 프로그램 상태를 가지고 있으며, 이는 box_type과 saved_size의 다른 값 조합으로 설명된다.
(1) 음수 크기 값을 가진 "tx3g"
(2) 음수가 아닌 크기 값을 가진 "tx3g"
(3) 모든 크기 값을 가진 "trak"
그러나, 주어진 예시는 무한한 수의 심볼릭 상태를 가지고 있다.
예를 들어, 실행 경로가 각 반복마다 "tx3g" 분기를 계속 선택한다면, 각 반복마다 새로운 심볼릭 상태로 전환되며, 각 반복마다 입력에 대한 추가적인 경로 제약조건을 도입한다(즉, 새로운 "tx3g" 데이터 박스를 추가). 이는 무한히 많은 다른 심볼릭 상태를 생성할 수 있으며, 실제로는 동일한 프로그램 상태를 반복적으로 탐색하고 있다. 이러한 중복 탐색은 의미가 없으며, 경로 폭발로 이어질 수 있다.
기존 심볼릭 실행기들의 상태 의존적 면에서의 한계
기존의 심볼릭 실행기들은 이러한 상태 의존적 의미를 인식하지 못한다. 그들은 다른 박스 유형의 가능한 조합을 모두 열거하거나, 엔진이 예상한 순서대로 프로그램을 탐색하는 것만 할 수 있다.
그림 1은 state-dependent 분기의 단순한 예시만을 보여준다.
현대의 많은 프로그램은 수천개 이상의 state-dependent 분기를 가지며, 이러한 분기들은 중첩될 수 있다. 정확하게 지정된 상태 기계는 복잡한 응용 프로그램 로직을 포함한 프로그램 작성 시, 개발자가 실수를 범하지 않도록 도와준다. 그러나, 위에서 설명한 것과 같이, state-dependent 분기는 분석가와 연구자들이 그 안에 있는 버그와 취약점을 찾는 것을 방해한다.
2.1 Challenges to Conduct Program-state-aware Symbolic Execution
Challenge 1: Program state inference(프로그램 상태 추론)
전통적인 심볼릭 실행 엔진과 프로그램 상태를 인식하는 심볼릭 실행 간의 격차를 좁히기 위해 가장 중요한 문제는, 주어진 프로그램 내부 상태를 어떻게 추론할 것인가이다.
운영체제의 상태와 달리(섹션 7.3에서 논의된 것 처럼), 프로그램의 상태는 일반적으로 구현에 결합되어 있으며, 명시적인 specification이 없다.
프로그램은 일반적으로 특정 변수, 즉 상태 설명 변수(state-describing variable)들을 사용하여 자신의 상태를 추적한다. 상태 설명 변수(state-describing variable)들을 식별함으로써 우리는 프로그램의 상태를 추론할 수 있다.
그러나, 상태 설명 변수(state-describing variable)를 인식하는 것은 그 자체로 어려운 일이다. 상태 설명 변수(state-describing variable)와 관련없는 변수 사이에는 거의 의미적이거나 구조적인 차이가 없기 때문이다.
예를 들어, 현실 세계의 프로그램은 임의의 유형과 임의의 이름을 가진 변수로 상태를 기억할 수 있다. 상태 설명 변수(state-describing variable)를 식별하는 것은 프로그램 상태를 인식하는 심볼릭 실행의 효과에 큰 영향을 미친다.
상태 설명 변수를 누락/일반 변수를 상태 설명 변수로 간주한 경우
- 만약 일부 상태 설명 변수(state-describing variable)를 누락한다면, 우리의 심볼릭 실행은 다른 상태를 동일한 상태로 처리하여 상태의 일부를 누락할 수 있다.
- 반면에, 상태와 관련없는 변수를 상태 설명 변수(state-describing variable)로 처리하면, 동일한 프로그램 상태가 여러번 실행되어 심볼릭 실행의 탐색 공간이 폭발할 수 있다.
Challenge 2: Runtime program state recognition(프로그램 실행 중 상태 인식)
주어진 프로그램의 상태 설명 변수(state-describing variable)를 식별할 수 있다 해도, 심볼릭 실행 엔진이 현재 상태를 인식하는 것은 쉽지 않다.
특히, 현실 세계의 프로그램은 현재 상태를 기억하기 위한 specific한 열거형 변수를 사용하지 않을 수 있다.
예를 들어, 그림 1의 코드 스니펫은 saved_size ≤ 0인 정상 상태와 saved_size > 0인 취약한 상태, 이렇게 두개의 상태를 가지고 있다고 할 수 있다.
결과적으로, 현재 프로그램 상태를 인식하는 것은 어렵고, 주어진 프로그램이 탐색된 상태에서 실행되는지 여부를 결정하는 것도 어렵다.
2.2 Characteristics of Real-world Programs with State-dependent Branches
위에서 언급한 도전 과제에 대응하기 위해, 우리는 상태에 따라 분기되는 현실 세계의 프로그램들을 조사하여, 그 특성을 이해하기 위한 조사를 수행한다.
구체적으로, 우리는 AFL에 의해 분석되고, 독립적인 106개의 프로그램에서 시작한다(다른 54개의 프로그램(e.g., Mozila Firefox, Internet Explorer 처럼 여러 라이브러리를 사용하거나, 오픈 소스가 아닌 프로그램)은 제외한다).
수동 조사 결과, 106개 중 91개(86%) 프로그램에는 적어도 하나의 state-dependent 분기문이 포함되어 있음을 확인했다. state-dependent 분기문을 포함하는 프로그램은 네트워크 데이터 전송부터 멀티미디어 데이터 처리까지 소프트웨어 시스템의 다양한 측면에서 필수적인 구성 요소로 널리 사용된다.
더 중요한 것은 이러한 프로그램들 중 많은 것들이 대규모 프로젝트와 시스템의 구성 요소이다. 예를 들어, Chromiun 프로젝트는 libpng와 libtiff를 포함한 state-dependent 분기문을 가진 여러 라이브러리로 구동된다. 우리는 이들의 특성(characteristics)을 다음과 같이 결론 짓는다.
- C1: 이 프로그램들은 하나의 입력 소스로부터 입력 시퀀스를 받는다. 전역 설정 파일, 환경 변수 또는 command-line 인자와 같은 구성 옵션 외에도, 각 프로그램은 파일이나 소켓과 같은 하나의 외부 입력 소스로부터 입력 시퀀스를 받는다. 또한, 이러한 프로그램들은 command-line 응용 프로그램이나 라이브러리이므로, 신호나 UI 이벤트와 같은 비동기 입력은 받지 않는다.
- C2: 이 프로그램들은 입력을 순차적으로 처리한다. 이 프로그램들은 전체 입력 시퀀스를 한번에 처리하는 대신, (입력 시퀀스에서) 한번에 하나의 입력을 처리한다. 우리의 motivation 예제는 파일에서 데이터를 계속 읽기 위한 입력 처리 루프를 포함하는 전형적인 예이다. 루프의 현재 반복에서 처리되는 입력을 current input(현재 입력)이라고 하고, 이전 반복에서 처리된 입력들을 earlier inputs(이전 입력)이라고 한다.
- C3: 이 프로그램들은 하나 이상의 상태 설명 변수(state-describing variable)로 프로그램 상태를 유지한다. 프로그램 상태는 상태 설명 변수(state-describing variable)들의 값과 이들의 입력들 간의 데이터 종속성이 있으면, 이전 입력으로부터 영향을 받는다. 이러한 변수들은 특정 조건문에 대해 선택된 분기에 영향을 주어 프로그램 동작을 더욱 변경시킨다.
In-scope Programs
대상 프로그램의 범위를 명시적으로 정의하기 위해, 내부 상태를 가진 모든 프로그램을 효율적으로 분석하려는 대신,
이 논문에서는 대상 프로그램의 범위를, 위에서 언급한 세가지 특성을 가진 real-world 프로그램으로 명확하게 정의한다.
Problem Statement
위에서 언급한 특성을 가진 프로그램에 대해, 그림 1에 나타난 것과 같은 상태에 따라 분기되는 분기문을 효율적으로 탐색하기 위해 섹션 2.1에서 식별된 도전 과제를 어떻게 해결할 것인지에 대한 문제를 제기한다.
2.3 Model of Ferry
Definition of Program States
프로그램 내의 상태는 다음과 같이 특징화될 수 있다.
(1) 상태는 상태 설명 변수(state-describing variable)들의 집합에 의해 정의된다.
(2) 두 상태가 다르면, 적어도 하나의 상태 설명 변수(state-describing variable)는 다른 값을 가지고 있다.
(3) 프로그램은 다른 상태에서 다른 동작을 수행한다(i.e., 다른 분기 방향을 선택함).
상태 설명 변수(state-describing variable)들을 자동으로 식별하는 것은 어려운 과제이다. 이 도전 과제에 대한 해결책은 분석 대상 프로그램의 특성에 기반한다:
섹션 2.2에서 언급한 대로, 각 프로그램은 하나의 외부 데이터 소스를 가지며, 이는 이전의 입력이 특정 state-decribing 변수의 값에 영향을 미칠 수 있는 방식으로 프로그램의 실행을 결정하며, 이는 현재 입력이 처리될 때, 일부 조건문에 대해 선택한 분기를 추가로 결정한다.
실행 중에, 프로그램 상태는 입력 시퀀스 처리 중에 변경된다. 이 논문에서는 상태 변화(state-changing) 이벤트를 세 가지 범주로 나눈다.
(1) 새로운 상태 설명 변수(state-describing variable)가 초기화된다.
(2) 특정 상태 설명 변수(state-describing variable)의 값이 변경된다. 이는 다른 값을 할당하거나 심볼릭 표현의 데이터 제약 조건이 변경된 것을 의미한다.
(3) 상태 설명 변수(state-describing variable)가 해제(release)된다.
특히, 입력 시퀀스가 실행 중인 프로그램 상태에 미치는 영향은 다음과 같이 정의할 수 있다.
1. 입력 시퀀스의 일부를 메모리 셀로 로드하는 각 명령을 입력 로딩 명령(input loading instruction) 으로 정의한다. (e.g., 그림 1의 read_box_size()와 read_box_type())
2. 상태 설명 변수(state-describing variable)의 값을 초기화하거나 해제하거나 수정하는 각 명령을 상태 설명 변수(state-describing variable) 동작(SDVO) 명령이라고 부른다. 위의 정의에 따라, SDVO 명령을 실행하면, 상태 전이가 발생한다.
3. SDVO 명령과 입력 로딩 명령 사이의 데이터 의존성을 다음과 같이 정의한다.
- 상태 설명 변수(state-describing variable)와 입력 로딩 명령 사이에 데이터 의존성이 존재할 때, 해당 SDVO 명령은 입력 로딩 명령에 대해 데이터 의존적이라고 한다.
- 실제로 이러한 종속성을 동적 오염 추적으로 확인한다.
분석된 프로그램의 본질적인 특성은 SDVO 명령과 입력 로딩 명령 사이에 데이터 의존성이 많이 존재한다는 것이다.
Ferry는 이러한 특성을 활용하여 상태 설명 변수(state-describing variable)를 식별한다.
Distinguishing Characteristics of State-describing Variables(상태 설명 변수의 차별적인 특성)
상태 설명 변수는 다음 두가지 특성을 갖고 있다
1. 상태 설명 변수(state-describing variable)는 명시적/암시적으로 입력 데이터에 데이터 의존적이다.
2. 상태 설명 변수(state-describing variable)는 적어도 하나의 조건문에서 확인된다.
Remark(비고)
우리의 접근법은 섹션 2.2에서 확인된 세가지 특성을 직접적으로 활용하지만, 우리의 기술은 위에서 언급한 특성을 가진 모든 프로그램에 잠재적으로 적용 가능하다.
즉,
- 중요한 상태 설명 변수(state-describing variable)의 하위 집합에 대해, 그들의 SDVO 명령은 적어도 하나의 입력 로딩 명령에 데이터 의존적이다.
- 상태 설명 변수들의 상이한 콘텐츠들(i.e., value) 로, 프로그램은 서로 다른 분기들을 선택함으로써 동작을 변경할 수 있다.
3 Design
3.1 Overview of Ferry
Ferry는 그림 2에서 보여지는 것처럼, 세단계로 작동한다
그림 2
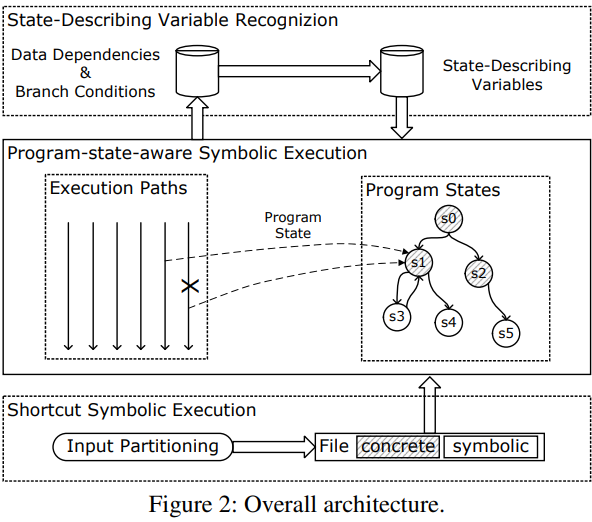
- 프로그램의 상태 설명 변수와 입력 간에 데이터 의존성이 존재한다는 인사이트를 기반으로, Ferry는 주어진 프로그램의 실행을 모니터하고, 상태 설명 변수를 식별한다.
- Ferry는 런타임 프로그램 상태를 인식하고, 심볼릭 실행을 사용하여 다양한 프로그램 상태를 탐색한다. 또한, 우리는 실제 프로그램의 복잡성이 Ferry의 효과에 영향을 줄 수 있다는 것을 발견했다.
- 두번째 단계에서의 발견을 바탕으로, 우리의 세번째 단계에서는 inactive한 state-describing 변수의 상태 감소(state-reduction)과 shortcut(단축) 심볼릭 실행이라는 두가지 최적화 기법을 도입하여 효율성을 더욱 향상 시킨다.
3.2 State-describing Variable Recognition
섹션 2.3에서는 상태 설명 변수에서 2개의 차별적인 특성을 확인한다.
즉, 상태 설명 변수들은 입력에 데이터 의존적이며(이후 단락에서는 InputDetermined로 표기됨), 상태 설명 변수들은 적어도 하나의 조건문에서 확인된다(BranchRelated로 표기됨). 이러한 특성을 가진 변수는 StateDescribing으로 표시된다.
- InputDetermined: 입력에 데이터 의존적인 상태 설명 변수
- BranchRelated: 조건문에서 확인된 상태 설명 변수
- StateDescribing: InputDetermined하고, BranchRelated한 변수
변수의 이러한 특성이 전역적으로 인식된다는 것이 중요하다.
즉, 변수가 한 실행 경로에서 InputDetermined로 표시되고, 다른 경로에서 BranchRelated로 표시된 경우, 우리는 그것을 StateDescribing으로 표시할 수 있다.
이 섹션에서는 분석된 프로그램의 본질적인 특성을 기반으로 한, 상태 설명 변수 자동 인식 메커니즘을 제시한다.
상태 설명 변수 자동 인식 메커니즘 - 1. InputDetermined 변수 식별
먼저, 우리는 외부 입력 소스에서 동적 오염 분석을 적용하여 InputDetermined 변수를 인식한다.
우리의 목표는 입력 시퀀스에 의존하는 상태 설명 변수를 찾는 것이다.
우리는 모든 입력을 "tainted"로 태그하고(그림 1의 비디오 파일의 경우, box_size와 box_type), 프로그램 내에서 그들의 전파를 추적한다.
전통적인 오염 분석과는 달리, 우리의 접근법은 구체적인 입력 대신 심볼릭 입력의 전파를 추적한다. 구체적으로, 우리는 오염 정보를 심볼릭 입력에 대한 특정 유형의 데이터 제약 조건으로 기록하여, 심볼릭 실행을 수행하면서, 오염 태그가 자연스럽게 전파되도록 한다.
변수는 Tainted 심볼릭 표현식을 받으면, InputDetermined로 표시된다.
주어진 예시에서는 box_size, box_type, saved_size가 InputDetermined로 표시된다.
상태 설명 변수 자동 인식 메커니즘 - 2. control dependency로 변수 식별
명시적 데이터 종속성 외에도, 그림 3에서 나타낸 제어 종속성(control dependency)을 통해 상태 설명 변수를 식별하는 데 도움이 될 수 있다.
그러나, 동적 오염 분석은 일반적으로 제어 종속성을 다루지 않는다. 실제로, 이러한 종속성을 고려하는 건 양날의 검이다. 커버리지를 높이는 장점이 있지만, 관련 없는 많은 변수(false positive)들이 잘못 도입될 수도 있다. 따라서, 우리의 분석은 오직 첫번째 레벨의 제어 종속성만 고려한다.
즉, 입력에 명시적으로 데이터 종속적인 다른 변수에 제어 종속적인 변수만이 tainted된다.
예를 들어, 그림 3에서는 state_var가 taint 되는데, 이는 명시적으로 입력들(inputs)에 의존하는 input에 control dependent하기 때문이다.
반면, tmp_var는 더이상 taint 되지 않는데, 이는 tmp_var의 조건식(guard condition)이 입력들(inputs)에 control dependent한 state_var를 검사하기 때문이다.
직접적으로 input에 의존하지 않아서 그런가?
(guard condition은 조건문에서 사용되는 조건식)
그림 3-제어 의존성 예제

섹션 2.3에서 밝힌 대로, 프로그램은 서로 다른 상태에서 서로 다른 분기 방향을 가진다. 따라서, 프로그램의 각 조건문에 대해 해당 조건을 확인할 때, 액세스하는 모든 변수를 기록하고, BranchRelated로 태그한다.
조건문에서 사용되는 InputDetermined 변수는 동시에 BranchRelated이므로 StateDescribing으로 표시한다.
예를 들어, 그림 1의 saved_size는 line 9의 조건문에 의해 액세스되므로, StateDescribing이다.
Identifying Invalid State-describing Variables > 최적화 기법
섹션 2.3에서 언급한 대로, 변수는 생존 기간(liveness duration)이 있으며, 상태 설명 변수가 해제될 때, 상태 전이가 발생한다.
예를 들어, 그림 4에서 opcode는 상태 설명 변수이다.
opcode가 스택의 로컬 변수라면, 함수가 반환되면, 함수의 로컬 스택은 무효화된다.
그림 4-만료된 상태 설명 변수 'opcode'의 제거
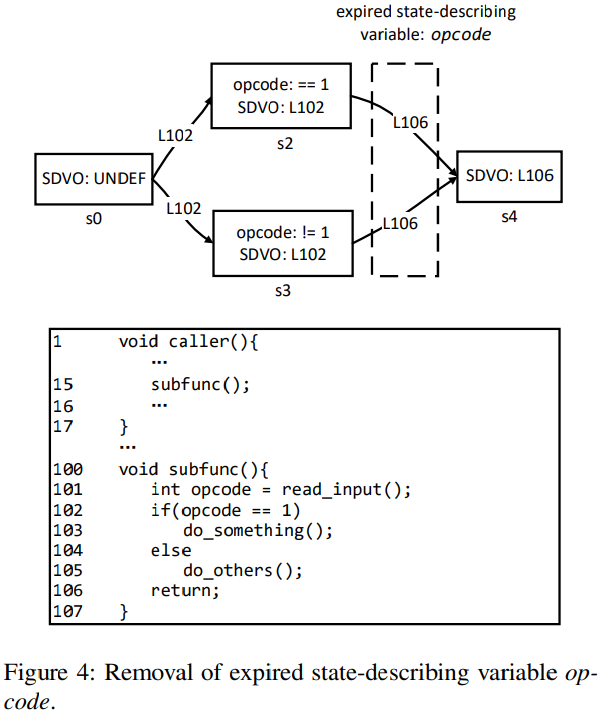
이와 같은 만료된 변수를 가진 프로그램 상태를 잘못 식별하는 것을 피하기 위해, Ferry는 두가지 최적화 기법을 도입한다.
1. free(해제)된 객체가 상태 설명 변수를 포함하면, free() 함수 호출은 SDVO 명령어로 간주된다.
2. 함수 호출이 반환되면, 상태 설명 변수를 조사하고, 반환된 함수의 스택 프레임 내에 있는 상태 설명 변수들을 폐기한다. 또한, 변수 중 하나라도 폐기된 경우, 반환 명령어를 SDVO 명령어로 간주하고, 새로운 상태가 도입되었는지 확인한다.
잘 이해가 안되네
3.3 Program-state-aware Symbolic Execution
이제 인식된 상태 설명 변수를 사용하여, 심볼릭 실행을 유도하는 방법을 설명한다.
Challenge 2에서 소개된 대로, 주어진 프로그램이 탐색된 프로그램 상태에서 실행되었는지 여부를 결정하는 것은 어렵다. 이러한 도전에 대처하기 위해, 우리의 해결책은 이 인사이트에 기반한다.
이게 무슨 말이지?
Insight 2: 프로그램의 상태 전이는 상태 설명 변수에 대한 제약 조건에 의존한다.
심볼릭 실행 엔진은 모든 실행 경로에 대해 심볼릭 입력에 대한 제약 조건을 기록하고, 동일한 제약 조건을 만족하는 모든 입력은 반드시 동일한 실행 경로를 따를 것이다. 또한, 프로그램 상태 정보는 Ferry에 의해 상태 설명 변수로 캡처된다. 따라서, 두 실행이 모든 상태 설명 변수에 대해 동일한 제약 조건을 갖고 있다면, 그들은 동일한 상태 전이를 따를 것이다.
섹션 2.3에서 언급한 대로, 특정 SDVO 명령어가 실행되면, 상태 전이가 발생한다. real-world 프로그램에서는 다음과 같은 경우에 명령이 SDVO 명령으로 간주된다:
- 초기화: 새로운 상태 설명 변수가 초기화된다.
- 데이터 제약 조건 변경: 상태 설명 변수에 대한 제약 조건이 할당에 의해 변경되거나 특정 분기 방향을 취하기 위해 업데이트된다.
- 변수 해제: 상태 설명 변수의 해제는 해당 변수의 생존 기간이 끝나면 발생한다.
상태 설명 변수 외에도, Ferry는 최신 상태 전이가 발생한 위치(i.e., 마지막으로 만난 SDVO 명령어의 주소)를 기록한다. 두 실행 경로는 상태 전이 위치나 상태 설명 변수(state-describing variable)에 대한 제약 조건이 다르다면, 서로 다른 프로그램 상태를 탐색하는 것으로 간주된다.
그런 다음, 상태 전이가 발생하면, Ferry는 현재 상태를 탐색된 record와 비교한다.
탐색되지 않은 새로운 상태가 관찰되면, 해당 상태의 SDVO 명령 주소와 상태 설명 변수의 제약 조건을 기록한다.
그렇지 않으면, Ferry는 심볼릭 실행을 롤백하여, 다른 프로그램 상태를 탐색한다.
symbolic execution을 롤백한다는 것은, symbolic execution 도중에 발생한 상태를 이전 상태로 되돌리는 것을 말한다.
4 Algorithm of Program-state-aware Symbolic Execution
프로그램 상태를 인식하는 심볼릭 실행의 알고리즘은 알고리즘 1에 나타내어 있다.
알고리즘 1-프로그램 상태 인식 심볼릭 실행

우리는 심볼릭 실행기(executor)의 상태를 (l,Π,∆)로 유지한다.
- 코드 위치
l: 현재 실행 중인 명령어의 주소를 기록한다 - 경로 술어(predicate) 집합
Π: path constraint를 저장한다 - 심볼릭 저장 사전
∆: 런타임 변수를 concrete한 값이나 심볼릭 표현과 매핑한다 - 상태 변수
s: 최근 실행 경로의 프로그램 상태를 저장한다 - 전역 상태 저장소
Ω: 탐색된 프로그램 상태(가장 최근의 SDVO 명령어와 상태s의 주소 포함)를 기록한다
섹션 3.2에서 설명한대로, 프로그램 상태 s는 세가지 변수 집합을 추적한다: BranchRelated, InputDetermined, StateDescribing
기본적으로 Ferry는 너비 우선 탐색 전략을 적용한다.
pickNext() 함수는 처리할 다음 실행 경로를 반환한다. 각 실행 경로에 대해 (l,s,Π,∆)를 유지한 상태에서, SDVO 명령이 충족되면(when an SDVO instruction is met), 프로그램 상태 s를 업데이트한다.
특히, 상태 설명 변수는 할당(assignment)이나 조건문이 발생할 때, 초기화되거나 변경될 수 있으며, 함수 반환 시 해제될 수 있다.
updateState(s,v,e) 함수는 원래 상태 s, 할당된 변수 v, 새로운 값(또는 제약 조건) e를 받고, 업데이트된 상태를 반환한다.
또한, 조건문을 만나면, SMT 솔버를 활용해서 해당 후속 상태의 만족 가능성을 확인한다. 마지막으로, 탐색되지 않은 상태의 실행 경로만 향후 처리를 위해 작업 목록 W에 추가한다.
그림 5는 그림 1의 심볼릭 실행을 그려냈다.
그림 5-우리의 프로그램 상태 인식 심볼릭 실행을 그려낸 예시
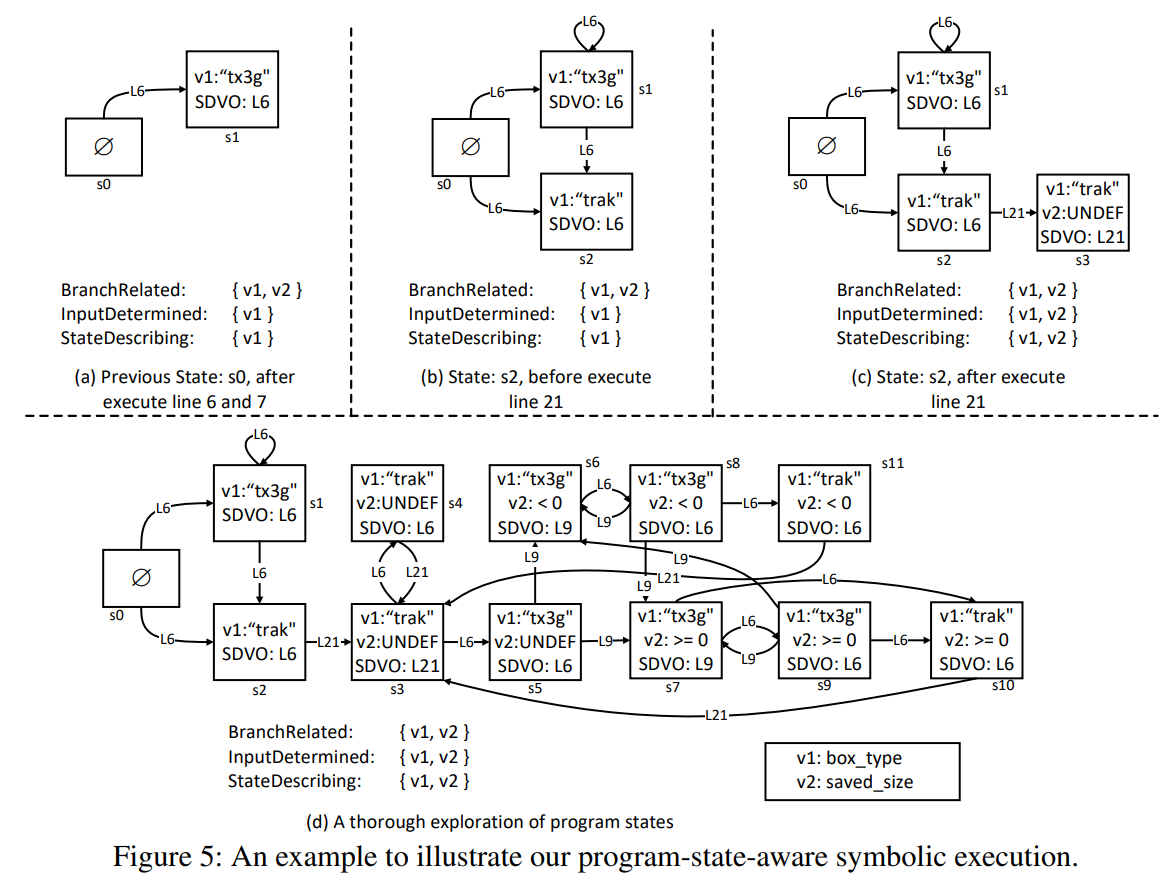
우리 실행에서 첫번째 상태 설명 변수는 변수 box_type으로, line 4에서 입력으로부터 load된다(InputDetermined).
line 6에서 스위치 명령어가 이 변수에 접근하고(BranchRelated), 상태 설명 메모리 recognition은 이를 StateDecribing으로 표시한다.
따라서, line 6는 SDVO 명령어이며, 이들의 서로 다른 분기를 탐색함으로써 두개의 새로운 상태(s1과 s2)가 기록된다. 상태 s1이 먼저 탐색되면, line 6의 두번째 실행은 s1을 탐색된 상태로 판단하여 다시 탐색하지 않을 수 있다.
saved_size도 상태 설명 변수이다. line 9의 조건문이 변수 saved_size에 접근한다.
그러나, 입력 시퀀스의 콘텐츠가 그 안으로 흘러들어가기 전(line 21)까지는, 이를 StateDescribing인지 판단할 수 없다. 따라서, line 9의 첫번째 실행은 새로운 프로그램 상태를 도입하지 않는다.
나중에 실행 경로가 line 21에 도달하면, saved_size가 StateDescribing으로 인식되어, 새로운 상태 s3를 도입한다. 그런 다음, line 6의 추가 실행은 새로운 상태 설명 변수(state-describing variable)가 도입되었기 때문에, "tx3g" 분기로 진입할 수 있다.
이 메모리 위치에 대한 제약 조건은 line 9의 두번째 실행에서 추가로 업데이트된다. 따라서, 두개의 새로운 상태(s6, s7)이 도입된다.
뭔 소리지...
5 Optimizations for Complex Real-world Programs
우리는 real-world 프로그램의 복잡성이 Ferry의 효과에 두가지 주요 영향을 미칠수 있다는 것을 알아냈다.
1. 실제 프로그램은 수백~수천개의 상태 설명 변수를 가질 수 있으며, 이는 상태 설명 변수 추적에 큰 오버헤드를 초래할 수 있다.
2. 실제 프로그램은 "깊은" 취약점에 도달하는 실행 경로에서 여러개의 state-dependent 분기를 가질 수 있으며, 이에 따라 Ferry는 이전의 state-dependent 분기를 탐색하는 동안 멈춰버리고, 이후의 분기를 탐색하지 못할 수도 있다.
이러한 실질적인 문제를 해결하기 위해, 우리는 두가지 최적화 기법을 제안한다.
1. State-reduction of Inactive State-describing Variables: 거의 액세스(접근)되지 않는 상태 설명 변수의 불필요한 추적을 줄인다.
2. Shortcut Symbolkic Execution(SSE): Ferry가 "깊은" 상태를 탐색할 수 있도록 한다.
이 두가지 최적화 기법은 모든 프로그램에 필수적으로 적용되지는 않지만, 섹션 4에서 제안된 기본 분석에는 영향을 주지 않는다는 점에서 가치가 있다.
5.1 State-reduction of Inactive State-describing Variables
이미 탐색된 프로그램 상태를 탐색하지 않기 위해, Ferry는 각 상태 설명 변수의 범위(i.e., 모든 가능한 값의 집합)를 탐색 기록과 지속적으로 비교해야 하므로, 성능 오버헤드가 발생한다. 이 문제를 완화하기 위해, 우리는 "비활성 상태 설명 변수의 상태 감소"라는 최적화 기법을 제안한다. 이 기법은 추적해야 하는 상태 설명 변수의 수를 줄여준다.
모든 상태 설명 변수를 추적하는 대신, 우리는 일정한 수의 임계값을 설정하고, 최근에 액세스된 변수(i.e., 새로운 값이 할당되거나 조건문에서 확인된 변수)에만 초점을 맞춘다.
우리의 조사 결과, 상태 설명 변수는 다양한 빈도로 액세스된다.
표 1에 나열된 7개의 프로그램의 실행을 모니터링하고, 다양한 상태 설명 변수의 액세스 빈도에 초점을 맞춘다.
이러한 프로그램에서 사용되는 모든 상태 설명 변수 중 72%는 다섯 번 미만으로 검사되며, 상위 4%의 변수는 모든 변수 액세스의 85%이상을 차지한다.
이 관찰은 우리의 motivation 예제(그림 1)를 뒷받침한다. 비대칭적인(skewed) 분포는 프로그램에서 많은 상태 설명 변수의 값이 오랜 기간 동안 변경되지 않을 것을 나타낸다. 실행 경로가 상태 설명 변수에 액세스하지 않으면, 해당 변수의 값은 변경되지 않고, 상태 전이를 발생시킬 수 없다.
추적할 변수의 수(threshold) 설정
추적되는 변수의 수는 신중하게 선택되어야 한다.
적은 수를 추적하면, 상태 설명 변수를 잘못 무시해서, 서로 다른 상태를 동일한 것으로 인식하게 되어, 경로가 잘못 제거될 수 있다.
많은 수를 추적하면, 추적해야할 변수의 수를 증가시켜 경로 탐색 대신 제약 조건 해결에 시간을 낭비하게 된다.
우리는 표 1에 있는 7개의 프로그램에 대해 실험을 진행하고, 추적되는 변수의 수가 실행 경로 수에 어떤 영향을 미치는지 알아보려고 한다.
우리는 하나의 상태 설명 변수를 추적하는 임계값에서 시작해서, 대부분의 프로그램에서 30분 이내에 탐색 경로가 소진되는 것을 발견했다.
반면, 다섯 개 이상의 상태 설명 변수로의 제한은 상태 간의 비교 수를 제한하는 데 거의 영향을 미치지 않았다.
?다섯개 이상의 상태 설명 변수를 제한하면, 너무 적은 수를 추적하는 거 아닌가?
마지막으로, 세개의 변수를 추적하는 것이 상태 간의 비교 수를 줄이고 싶은 프로그램 상태에 도달하는 데 도움이 되므로, 이를 실험의 기본 설정으로 채택한다.
5.2 Shortcut Symbolic Execution with Input Partitioning
실제 프로그램에서 "깊은" 상태로의 실행 경로는 많은 state-dependent 분기는 guard에 의해 보호된다.
경로 폭발과 마찬가지로, state-dependent 분기의 수가 증가하면, 프로그램 상태의 수도 급격하게 증가한다.
다행히, 우리는 이러한 모든 분기를 정복하려는 대신에, 독립적인 그룹으로 나눌 수 있으며, 이를 별도로 처리할 수 있다는 사실을 발견했다.
실제 프로그램에서 개발자들은 입력 시퀀스 전체를 한 함수에서 처리하지 않고, 입력 시퀀스의 다른 부분을 서로 다른 함수 그룹에서 처리한다.
예를 들어, 우리의 motivation 예제(그림 1)에서 입력 처리(input-handling) 루프는 각 데이터 박스의 box_type과 box_size만을 파싱한다.
이 코드에서 파싱은 데이터 박스의
box_type과box_size값을 읽어오는 과정을 말한다.read_box_type()과read_box_size()함수를 통해 데이터 입력에서 해당 값을 일거와 변수에 저장한다.
반면, payload 데이터는 line 18에서 구성된 버퍼 buf에서 읽혀지고, 다른 함수에서 처리되도록 남겨진다.
따라서, 이러한 함수들에서의 state-dependent 분기는 입력 시퀀스의 다른 부분에도 의존하며, state-dependent 분기가 속한 함수들이 처리하는 입력 시퀀스의 부분에 따라 이런 분기들을 그룹화할 수 있다. 이 관찰을 기반으로, 우리의 아이디어는 구체적인 프로그램 입력을 선택적으로 제공함으로써 state-dependent 분기의 초기 단계 그룹을 우회하는 것이다.
shortcut 심볼릭 실행이 활성화되면, 수동으로 제공된 시드 파일이 필요하다. 주어진 입력 시드로, 우리의 shortcut 심볼릭 실행은 다음과 같이 진행된다.
1. SSE는 심볼릭 에뮬레이션을 통해, state-dependent 분기의 서로 다른 그룹에서 처리되는, 서로 다른 입력 부분의 경계를 자동으로 인식한다.
2. 그 다음, 추론된 경계를 사용하여 SSE는 특정 입력 파티션을 선택적으로 심볼릭하게 만들어서, 상태를 인식하는(state-aware) 방식으로 해당 state-dependent 분기 그룹을 심볼릭하게 실행한다.
SSE는 상태를 인식하는 심볼릭 실행 과정에서 실시간으로 진행된다는 점에 주목할 가치가 있다.
즉, SSE를 사용하는 Ferry는 먼저 주어진 시드 파일 내용으로 입력 데이터를 제약하고, 심볼릭 실행(i.e., 심볼릭 에뮬레이션)을 적용한다. 이 과정에서, Ferry는 입력 파티션의 경계를 자동으로 인식한다.
3. 그 다음, 해당 입력 부분에 대한 제약 조건을 동적으로 제거하여, state-dependent 분기의 특정 그룹을 탐색하려고 한다.
- Ferry with SSE는 주어진 시드 파일 내용으로 입력 데이터를 제약한다.
- 그 후, 심볼릭 실행(즉, 심볼릭 에뮬레이션)을 수행한다.
- 이 과정에서, Ferry는 입력 파티션의 경계를 자동으로 인식한다.
- SSE는 추론된 경계를 사용해서, 특정 입력 파티션을 선택적으로 심볼릭하게 만든다.
- 그 후, state-aware 방식으로, 해당 state-dependent 분기 그룹을 심볼릭하게 실행한다.
- 그 다음, 해당 입력 부분에 대한, 제약 조건을 동적으로 제거해서, state-dependenet 분기의 특정 그룹을 탐색한다.
Input Partitioning
여기서 중요한 문제는, 서로 다른 state-dependent 분기 그룹으로부터 처리되는 부분을 나누는 입력 시퀀스의 경계를 자동으로 결정하는 방법이다.
예를 들어, earlier 분기 그룹 A와 later 분기 그룹 B가 입력 시퀀스의 두개의 인접한 부분을 처리한다고 가정해보자.
두 그룹 사이의 경계를 찾을 때, A 그룹을 호스팅하는 함수 f와 B 그룹을 호스팅하는 함수 g 사이의 특정한 관계를 활용한다.
특히, 우리는 조사한 91개 프로그램 중 73개(80.22%)에서 함수 f가 명시적으로 함수 g를 위한 버퍼를 생성하고, 자신의 버퍼에서 (미처리된) 데이터를 새로운 버퍼로 복사(또는 이동)한다는 것을 관찰했다.
이에 따라, 우리는 먼저 I/O 함수(e.g., fread())를 모니터링하고, 대상 배열을 초기 입력 버퍼로 표시한다.
그런 다음, 분석된 프로그램에서 한 버퍼에서 다른 버퍼로 데이터를 복사하거나, 이동하는 작업(e.g., memcpy(), memmove())을 인식한다. 새로운 버퍼로 이동된 입력 부분은 다른 가드 그룹에 의해 처리될 것으로 예상되며, 우리는 이를 다른 부분 사이의 경계로 설정한다.
그림 6은 우리의 방법론이 motivation 예제에서 어떻게 작동하는지를 보여준다.
그 다음, later state-dependent 분기 그룹은 새로운 버퍼를 입력 소스로 사용한다. 우리는 payload 앞에 경계를 설정한다.
Shortcut Symbolic Execution
위에서 설명한 바와 같이, 입력 파티션의 중요한 특성은 독립적인 분기 그룹에 의해 처리된다는 것이다.
만약 우리가 선행하는 N-1 파티션에 구체적인(concrete) 값을 사용한다면, 해당 초기 단계의 분기 그룹은 분기된 경로(i.e., shortcut) 없이 실행될 것이다.
더 중요한 점은, 프로그램의 다음 동작이 결정론적이라는 것이다: N번째 파티션을 버퍼로 읽고, 특정한 분기 그룹을 사용하여 처리한다. 따라서, 우리가 N번째 파티션을 즉석으로 심볼릭하게 하면, 해당하는 분기 그룹을 대상으로 타겟팅하고, 탐색할 수 있다.
서로 다른 파티션을 심볼로 변환하는 순서를 결정할 때, 우리는 제공된 파일 내용을 최대한 활용해서, 경로 폭발 없이, 가능한 한 깊은 프로그램 로직을 탐색한다.
따라서, 우리는 역순으로 입력 파티션을 심볼로 변환(symbolize)한다. 즉, 우리는 먼저 마지막 파티션을 심볼로 변환한다.
실행 경로가 다 소진되면, 이전의 한 개의 파티션을 추가로 symbolize하고 이 과정을 반복한다.
6 Evaluation
이 섹션에서는 Ferry의 효과를 평가한다. 우리의 평가는 다음과 같이 진행된다.
다른 도구들보다 높은 코드 커버리지 달성하는지
- 먼저, 13개 실제 프로그램과 포괄적인 테스트 스위트인 Google FuzzBench를 사용하여 Ferry가 다른 도구들보다 코드 커버리지에서 우월한 성과를 보이는지 평가한다.
우리의 평가 결과, Ferry는 두가지 널리 사용되는 심볼릭 실행 엔진인 KLEE와 angr보다 38%, 42% 더 많은 기본 블록과 42%, 47% 더 많은 분기를 커버한다.
동일한 입력 시드를 사용할 경우, SSE를 사용한 Ferry는 AFL, Angora, QSYM이라는 세가지 인기있는 퍼저보다 블록과 분기 커버리지에서 우수한 성능을 발휘한다. 더욱이, 15%의 기본 블록은 어떤 퍼저에서도 도달하지 못한 상태이다.
결과를 더 자세히 조사한 결과, Ferry는 추론된 상태 설명 변수들과 비교하여 더 깊은 프로그램 로직을 탐색할 수 있기 때문에, 더 높은 코드 커버리지를 달성한다.
깊은 프로그램 로직 탐지하는지
- 코드 커버리지를 높이는 것 외에도, 이 논문은 프로그램 상태에 따라 "깊은" 프로그램 로직을 탐색하는 데 초점을 맞추고 있다. 우리는 섹션 2.2에서 상태에 따른 분기의 보편성을 제시했다.
이 섹션에서는 CVE 데이터베이스에서 프로그램 상태에 의존하는 취약점을 수집하고, Ferry와 다른 도구들이 이를 재현할 수 있는지를 평가하여 깊은 프로그램 로직을 탐색하는 중요성을 더 자세히 밝힌다.
우리는 또한, River라는 테스트 스위트를 구성하여 도구가 state-dependent 분기를 어느정도까지 탐색할 수 있는지 평가한다. River는 160개의 수동으로 삽입된 취약점을 포함한 6개의 프로그램으로 구성되어 있고, 이 취약점은 특정한 프로그램 상태에서만 트리거 될 수 있다.
심볼릭 실행기 두개와 퍼저 세개와 비교했을 때, Ferry는 실제 세계의 취약점을 40% 이상 더 많이 찾아냈고, 수동으로 삽입된 취약점도 2.4배 더 많이 찾아낸다.
상태와 관련없는 취약점 탐지 성능 측정
- Ferry의 성능 기준을 이해하기 위해, 우리는 상태와 관련없는 취약점들로 이루어진 다른 포괄적인 데이터 세트인 LAVA-M을 사용한다.
최악의 경우, Ferry는 BFS 전략을 사용하는 angr와 비슷한 성능을 보이지만, 일부 중복된 경로를 탐색하지 않는다. 더 나아가, Ferry의 한계에 대해서는 섹션 6.7에서 더 자세히 논의한다.
Implementation
Ferry는 5070줄의 파이썬 코드로 구성된 angr 프레임워크 위에 구축됐다.
우리는 SMT 쿼리를 해결하고, 프로그램 상태를 비교하기 위해 Z3을 사용한다.
SMT 쿼리를 해결한다: 주어진 논리식이 참인지 거짓인지 결정한다
Z3: SMT 솔버
shortcut 심볼릭 실행에서 구체적인 파일 내용의 에뮬레이션을 가속화하기 위해 Unicorn 엔진을 사용한다.
Vulnerability Detection
심볼릭 실행에서, (1) 취약점 전달(vulnerability-carrying) 분기에 도달하도록 실행을 구동하는 문제과 (2) (심볼릭 실행을 통해 해당 보안 취약점에 도달한 후) 취약점을 트리거/악용하는 문제은 별개의 문제이다.
(2)번 문제는, 심볼릭 실행 분야에서 잘 다루어지지 않았기 때문에, 이 연구는 해당 문제를 범위에서 제외해야한다.
소프트웨어 퍼징과 함께 잘 작동하는 sanitizer는 (2)번 문제를 해결하는 데 사용될 수 없다는 점에 유의해야 한다.
심볼릭 실행 엔진과 sanitizer의 네이티브한 조합은 sanitizer가 입력 데이터에 대한 추가 검사(i.e., 조건문)를 도입하기 때문에 심각한 경로 폭발을 유발한다.
Experiment Setup
실험환경
모든 평가는 Ubuntu 16.04 server, with a single 3.9GHz Intel i5-8600K CPU and 64GB of RAM에서 진행되었다.
Ferry와 대부분의 비교 도구는 싱글 스레드로 작동하고, QSYM은 퍼징 프로세스와 심볼릭 실행 프로세스를 가지고 있다. 모든 도구에게는 6시간의 동일한 타임아웃이 적용되었다.
실험은 세번 반복되고, 평균 결과로 보고한다.
기본적으로, 우리의 프로그램 state-aware 심볼릭 실행 기술을 BFS 탐색 전략을 기반으로 InputDetermined와 BranchRelated 변수를 인식한다. 우리의 평가에서는 BFS와 DFS를 포함한 다양한 탐색 전략에서 우리의 접근 방식을 다른 심볼릭 실행 도구와 비교한다.
KLEE의 경우, 독특한 무작위 경로 전략을 추가로 평가한다.
Ferry with SSE와 퍼저에는 입력 시드가 필요하며, 우리의 시드 파일은 AFL 테스트케이스와 FuzzBench에서 수집했다.
AFL의 성능 권장 사항을 따라, FuzzBench의 큰 시드는 제외하고(이는 Angora의 오염 분석을 압도할 수 있음), 시드의 수를 제한한다. 위의 구성을 모든 실험에 적용한다.
6.1 Code Coverage
Benchmarks
Ferry의 코드 커버리지를 평가하기 위해, 두가지 종류의 프로그램을 수집한다.
구체적으로, Google의 포괄적인 데이터셋인 FuzzBench를 사용하여 Ferry와 다른 도구들의 경로 탐색 능력을 평가한다.
FuzzBench는 끊임없이 변화하는 벤치마크이다.
작성 시점에서 49개의 프로그램이 포함되어있었다. 우리는 FuzzBench의 20개 프로그램을 성공적으로 분석했다.
나머지 프로그램의 분석에 실패한 이유는 두가지가 있다.
25개 프로그램 실패 이유
1. FuzzBench는 Google OSS-Fuzz에 의해 퍼징되도록 설계되어있다. 또한, Google이 AFL 기반 도구에 대한 어댑터만 제공하기 때문에, 우리가 평가한 대부분의 도구들은 공식적으로 지원되지 않는다. non-AFL 도구들이 25개 프로그램을 분석하지 못한 이유는 다음과 같다.
- 컴파일러 및 linker 오류: libFuzzer를 기반으로 한 Google OSS-Fuzz는 커스텀된 타겟 프로그램을 필요로 한다. 구체적으로, 프로그램은 LLVMFuzzerTestOneInput()과 LLVMFuzzerInitialize()와 같은 libFuzzer에서 제공하는 인터페이스를 override해야 하는데, 이는 다른 퍼저 및 심볼릭 실행 도구에서 지원되지 않아, 빌드 실패를 야기한다. 우리는 이러한 인터페이스에 대한 wrapper를 제공하여 프로그램을 수정하고, 빌드 스크립트를 수정하여, 다른 도구에 적응시키기 위해 최선을 다 했지만, 그 중 15개 프로그램은 여전히 실행하지 못했다.
- 환경 모델링 한계: 25개 프로그램 중 10개에서는 LLVMFuzzerInitialize()에서 복잡한 로직을 구현하여, 우리의 환경 모델에서 처리할 수 없는 경우가 있었다. 그 중 curl 드라이버는 HTTP 요청을 구성하기 위해, 추가적인 HTTP 2.0 라이브러리를 도입하고, construction progress는 심볼릭 실행기(executor)에서 경로 폭발을 일으킬 수 있다. 나머지 프로그램들은 mkstemp()와 같은 모델링되지 않은 함수를 사용하여 동적으로 임시 파일을 생성하거나, 심볼릭 실행기 중, 어느 하나에서 지원되지 않는 다중 스레드 기능에 의존한다.
4개 프로그램 실패 이유
2. 4개의 프로그램은 FuzzBench가 upstream 코드베이스의 변경을 따르지 않아, 빌드에 실패한다. 예를 들어, FuzzBench에서 필요한 stb 내 파일은 이미 최신 버전에서 제거되었고, FuzzBench는 관련 스크립트를 업데이트하지 않는다. 또한, 200만 줄 이상의 코드를 가진 13개의 실제 프로그램을 수집했다. 이 프로그램들은 보안 연구자들에게 관심을 받으며, 이미지, 비디오/오디오, pdf, 바이너리 등 다양한 범주의 처리를 커버한다. libjpeg와 libtiff 같은 많은 프로그램들은 Chromium, Android, iOS 등 중요한 실제 프로젝트의 구성 요소로 사용된다.
0-day Vulneratbilites
흥미로운 점은, 우리의 평가 중에 Ferry가 libstagefright에서 보고되지 않은 null-dereference 버그 두개를 발견했다. 분석해본 결과, 이 버그들이 Google에 의해 내부적으로 수정되었음을 발견했다.
게다가, Ferry가 생성한 입력을, sanitizer로 인스트루먼트된 프로그램에 주입함으로써, Ferry는 jhead에서 3개의 0-day 취약점을 발견했다. 구체적으로, Ferry는 성공적으로 4개의 힙 버퍼 오버플로우 취약점을 발견했으며, 그 중 3개는 0-day이고, 하나는 보고되었지만, 아직 수정되지 않았다.
Responsible Disclosure
우리는 jhead 작성자에게 3개의 0-day 취약점을 보고했다.
구체적으로, 우리는 작성자의 홈페이지에서 이메일 주소를 수집한 다음, 취약한 커밋, 코드 위치, PoC exploit을 포함하여 취약점에 대한 모든 세부 정보를 공유했다. 최종적으로, 이러한 취약점은 최신 버전에서 모두 수정되었다.
표 2에서 다른 도구들의 블록 커버리지와 분기 커버리지를 보여준다.
표 2-Ferry with/without SSE, KLEE/angr, AFL/Angora/QSYM의 코드 커버리지
서로 다른 탐색 기술을 가진 심볼릭 executor에 대해, 각 프로그램의 best 결과를 나타냄.
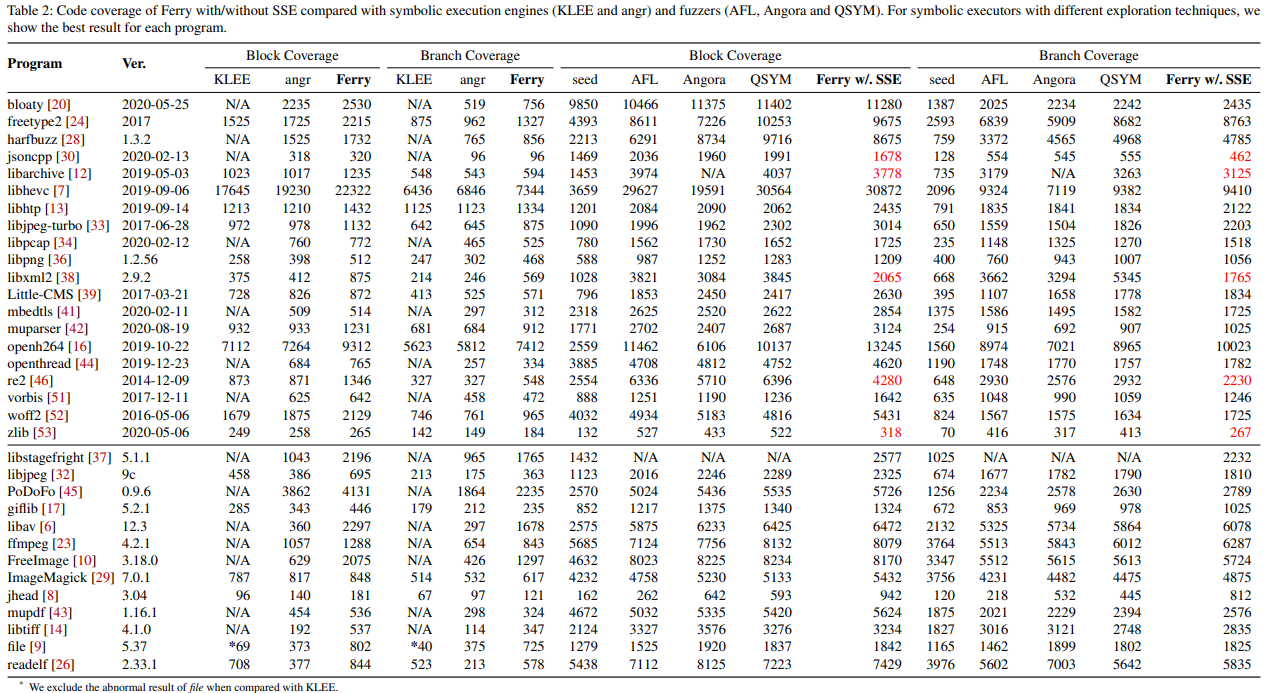
FuzzBench의 7개 프로그램에서는 KLEE를 명시적으로 "지원되지 않음"으로 표시하고 있음을 주목해야 한다.
또한, KLEE가 PoDoFo, libav, ffmpeg, FreeImage, mupdf, libtiff를 분석하는 데 실패한 것을 발견했는데, 그 이유는 분석된 프로그램을 LLVM IR로 컴파일하는 것을 요구하고, LLVM IR 상에서 심볼릭 실행을 수행하지만, 컴파일 중 생성된 LLVM 내부의 모든 함수를 지원하지 못해, 심볼릭 실행 시작 시에 충돌이 발생하기 때문이다.
게다가, libstagefright를 분석할 수 있는 것은 Ferry와 angr 뿐이다. 우리는 이를 분석해보았고, 오직 그들만이 libstagefright의 build dependency인 Android bionic 라이브러리를 올바르게 모델링했음을 발견했다.
우리는 시드 파일이 필수 요구 사항인지를 기준으로, 평가 도구를 두 그룹으로 나눈다.
구체적으로, Ferry with SSE와 퍼저만이 시드 파일을 필요로 하고, Ferry without SSE와 다른 심볼릭 실행기는 필요로 하지 않는다.
공정한 비교를 위해, 우리는 각 그룹의 코드 커버리지를 비교한다.
첫번째 그룹 간 비교(Ferry without SSE, KLEE, angr)
첫번째 그룹에서는 Ferry와 다른 두개의 심볼릭 실행기를 비교한다. 우리는 angr와 KLEE의 다양한 탐색 전략에 따른 최상의 결과만을 보여한다.
KLEE는 file을 분석할 때, 매우 낮은 커버리지를 달성한다. 수동으로 확인한 결과, 이는 KLEE의 파일 시스템 모델링으로 인해 파일 형식을 인식하기 위한 signature list를 로드하는 것이 불가능하다는 사실 때문이다.
우리는 이상적인 평가를 위해, KLEE와의 비교에서 abnormal(이상) 데이터를 제외한다.
Ferry without SSE는 KLEE와 angr보다 각각 기본 블록에서 38%, 42% 더 많은 커버리지와, 분기에서 42%, 47% 더 많은 커버리지를 제공한다.
두번째 그룹 간 비교(Ferry with SSE, AFL, Angora, QSYM)
두번째 그룹에서는, Ferry with SSE와 세가지 유명한 퍼저를 비교하며, 시드 파일에 의해 도입된 기본 코드 커버리지도 함께 제시한다.
우리는 Ferry with SSE가 jsoncpp, libarchive, libxml2, re2, zlib에서 성능이 좋지 않음을 발견했다.
한편, AFL을 기반으로 한 하이브리드 퍼저인 QSYM도 원본 AFL과 비교해봤을 때, 개선이 없음을 보여준다. 우리의 조사 결과, jsoncpp, libxml2, re2의 문자열 매칭 로직(e.g., re2의 정규식 처리)과 libarchive, zlib의 압축 로직은 복잡한 경로 제약 조건을 생성하여, Ferry에서 솔버를 차단하고, 상태 폭발을 초래하기 때문에, 이런 결과가 나타났다.
우리는 더 나아가, 섹션 6.7에서 Ferry의 한계에 대해 논의한다.
동일한 시드 파일을 사용할 경우, Ferry는 대부분의 벤치마크에서 더 나은 분기 커버리지를 보여준다.
위에서 언급한 다섯개의 프로그램을 제외하고, Ferry는 AFL/Angora/QSYM 보다 각각 기본 블록에서 18%, 21%, 8% 더 많은 커버리지와, 분기에서 22%, 21%, 8% 더 많은 커버리지를 제공한다.
더욱이, Ferry의 블록 커버리지 분포는 다른 것들과 크게 다르다. 구체적으로, Ferry에 의해 커버된 블록 중 15%는 어떤 퍼저에서도 도달하지 못한 블록이다. 우리는 이러한 결과가 Ferry가 어렵게 접근할 수 있는 코드를 커버하는 능력을 나타낸다고 믿는다.
우리의 수동 검사는 더 나아가, Ferry가 다른 프로그램들이 접근하지 못하는 더 깊은 로직에 도달할 수 있는 것을 보여준다.
예를 들어, ffmpeg를 분석할 때, Ferry만이 기본 비디오 디코더의 코드를 탐색할 수 있으며, angr는 반복적으로 방문한 상태를 탐색하는 데에서 멈추게 된다(즉, angr는 동일한 명령을 수백 번 반복하며, 이 명령의 모든 실행은 Ferry가 인식하는 동일한 유효한 상태에 있다).
6.2 Reproducibility of Program-state-dependent Vulnerabilities
본 섹션에서는 Ferry가 이전 연구보다 더 많은 프로그램 state-dependent 취약점을 찾을 수 있는지 평가한다.
Vulnerability Collection
프로그램 state-dependent 취약점은 적어도 하나의 state-dependent 분기를 통해, 해당 취약점에 도달하는 경로로 간주된다. 우리는 세 단계로 프로그램 state-dependent 취약점을 수집한다.
검색 범위를 줄이기 위해, 각 프로그램의 버전을 확인한다. 우리는 CVE 데이터베이스에서 가장 많이 보고된 취약점을 가진 버전으로 설정한다. 그 후, 취약점에 대한 정보를 수집한다. 이 정보에는 코드 위치와 해당 취약점을 유발하는 입력 시퀀스가 포함된다. 구체적으로, 우리는 세가지 방법으로 취약점 세부 정보를 수집한다.
1. CVE 데이터베이스의 각 취약점의 reference 링크를 따라간다.
2. 많은 취약점의 PoC exploit을 제공하는 Exploit Database에서 search한다.
3. 취약점을 수정하는 패치를 찾아서, 그로부터 배운다.
마지막으로, 우리는 프로그램 상태에 의존하지 않는 취약점을 수동으로 필터링한다.
표 3에 나타난 대로, 우리는 최종적으로 CVE 데이터베이스에서 15개의 취약점을 수집한다.
표 3-다양한 툴의 취약점 reproducibility
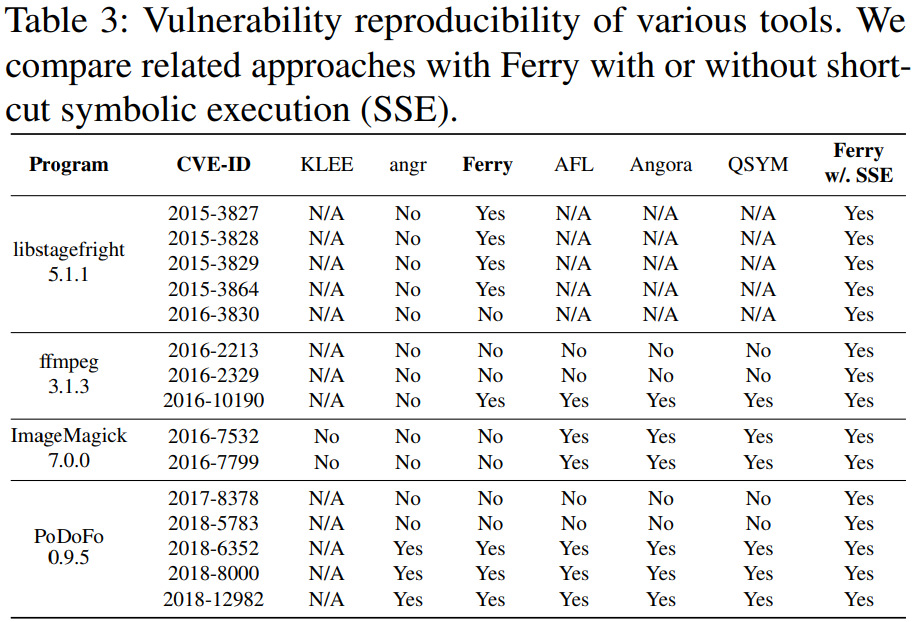
위에서 언급한대로, 심볼릭 실행기는 취약점을 자동으로 트리거할 수 없다. 따라서, 우리는 수동으로 이러한 취약점을 필요한 트리거 조건으로 보호된 assert(0)로 대체해서 실행기가 해당 취약점에 도달하면, 즉시 알림을 받을 수 있도록 한다. 이러한 취약점은 힙과 스택 오버플로우, double-free, use-after-free, divided-by-zero, 초기화되지 않은 포인터 참조와 같은 다양한 취약점 유형을 포함한다.
결과는 표 3에 나와있다.
이 도구들의 성공적인 분석 중에서도, Ferry는 shortcut 심볼릭 실행을 활성화시키지 않고도, 15개의 취약점 중 8개를 재현할 수 있다. shortcut 심볼릭 실행이 활성화된 후, Ferry는 모든 취약점을 찾을 수 있다.
다른 도구들이 취약점을 찾지 못하는 이유는 다음과 같이 설명할 수 있다.
For symbolic executors
심볼릭 실행기에서의 주된 이유는 경로 폭발이다.
우리의 수동 검사에서 KLEE와 angr 모두 심각한 경로 폭발에 시달리는 것을 확인했다.
예를 들어, BFS 전략을 사용해서 libstagefright/ffmpeg/ImageMagick을 분석할 때, angr는 Ferry보다 6시간 동안 실행 경로를 10배 이상 분기한다.
For fuzzers
퍼저들이 취약점에 도달할 수 있는지 여부는 시드 파일에 의해 크게 영향을 받는다. 예를 들어, CVE-2016-2213는 특정 유형의 JPEG 2000 페이로드를 포함한 비디오 파일로만 트리거할 수 있기 때문에, 이 취약점에는 어떤 퍼저도 도달할 수 없다. 불행히도, 이런 rare한 페이로드는 어떤 AFL 테스트케이스나 FuzzBench 시드에도 포함되어 있지 않으며, 퍼저가 효율적으로 생성하기 어렵다.
반면, Ferry with SSE만이 초기 단계의 비디오 처리 로직에서 경로 폭발을 피하기 위해, 주어진 시드만 사용하고, 해당 입력 파티션을 심볼릭하게 만든 후, 성공적으로 취약점에 도달한다.
6.3 "Deep" Program State Exploration
우리는 동적 분석 도구의 state-dependent 분기를 탐색하는 능력을 평가하기 위해, 테스트 스위트인 River를 제안한다.
데이터셋 LAVA-M과는 다르게, River는 "깊은" 상태를 탐색하는 도구의 능력을 평가하기 위해 만들어졌으며, 이는 다른 사람들이 주로 관심을 가지는 블록 커버리지 기준과는 관련이 없다. River는 다음과 같은 특징을 가지고 있다.
1. 모든 삽입된 취약점은 프로그램 state-dependent하며, 특정한 입력 시퀀스에 의해서만 트리거될 수 있다.
2. 취약점은 다양한 state depth에 분포되어 있으며, 이는 취약점에 도달하기 위해 필요한 최소한의 state-dependent 분기 결정 횟수를 의미한다.
state depth가 더 깊은 취약점일수록 입력 시퀀스에 대한 제약 조건이 많아져, 도달하기 어렵다. 우리는 모든 삽입된 취약점을 수동으로 주석을 달고, state depth 정보를 기록했다.
River는 "깊은" 상태를 탐색하는 도구의 능력을 평가하기 위해 만들어졌기 때문에, 해당 지표는 state depth를 고려해야 한다. 따라서, 탐색된 전체 프로그램 상태의 수를 측정하는 대신, 가장 적합한 지표는 "깊은" 상태가 얼마나 많이 탐색되었는지를 측정하는 것이다.
이 아이디어를 구현하기 위해, 우리는 각 삽입된 취약점의 state depth를 주요 속성으로 두었다. 이렇게 함으로써, 해당 [취약점 ID, state depth] 쌍은 새로운 프로그램 상태가 탐색되었는지 여부 뿐만 아니라, 해당 상태가 "깊은" 상태인지 여부도 알려준다.
주목할 점은 [취약점 ID, state depth] 쌍의 지표가 시스템적으로 깊은 상태를 탐색하는 도구의 능력을 측정할 수 있는지는 reachable 깊은 상태의 대표적인 집합에 취약점이 삽입되었는지 여부에 크게 의존한다는 것이다.
Test Suite Construction
우리는 벤치마크를 두 단계로 구성했다.
1. 프로그램 state-aware 심볼릭 실행을 사용하여, 프로그램을 6시간 동안 분석하고, 각 상태 전이의 코드 위치(i.e., SDVO 주소)와 해당 상태에 도달하기 위한 경로 제약 조건과 같은 취약점 삽입에 필요한 정보를 기록했다.
2. 우리는 각 SDVO 이후에, 수동으로 취약점을 삽입했다.
인간 프로그램 분석가가 이해하기에 경로 조건이 너무 복잡한 SDVO는 건너뛰었다. 각 삽입된 취약점은 assert(0 && state_depth && vul_id) 호출이고, 해당 호출은 경로 제약 조건에 의해 guard(보호)되므로, 무조건적으로 악용될 수 있다.
vul_id는 고유하고, 상세한 취약점 정보를 얻기 위한 인덱스로 사용된다.
Program State Exploration Ability Evaluation
우리는 River를 사용하여 모든 심볼릭 실행기와 퍼저를 평가한다. 우리는 부록 A에서 자세한 취약점 재현 결과를 제시하고, 다른 도구들이 깊이에 따라 도달한 삽입된 버그의 분포를 그림 7에서 보여준다.
부록 A
River를 사용하여 두가지 심볼릭 실행기(KLEE와 angr)와 세가지 퍼저(AFL, Angora, QSYM)를 평가했다. 결과는 표 4에 나와있다.
표 4

Ferry는 벤치마크 구축 기술을 공유하기 때문에, 삽입된 모든 취약점을 찾을 수 있다는 것이 놀라운 사실은 아니다. 우리는 River에서 QSYM의 성능이 좋지 않다는 것을 발견해서, 수동 분석 결과, QSYM은 반복되는 기본 블록을 감지하고, 심볼릭 실행에서 제외시키려고 시도한다는 특정 최적화 때문에, 이러한 문제가 발생했다. 이로 인해, QSYM은 입력 처리 루프의 많은 분기를 무시하게 된다. 평가된 도구 중에서 KLEE가 가장 많은 취약점을 찾아내며(41%), 심볼릭 실행기는 탐색 기법(특히, BFS)과 제약 해결 능력 덕분에 퍼저보다 더 얕은 취약점을 찾는 데 도움이 됐다.
그림 7-깊이에 따른 각 툴로부터 도달되는 삽입된 버그의 누적 분포
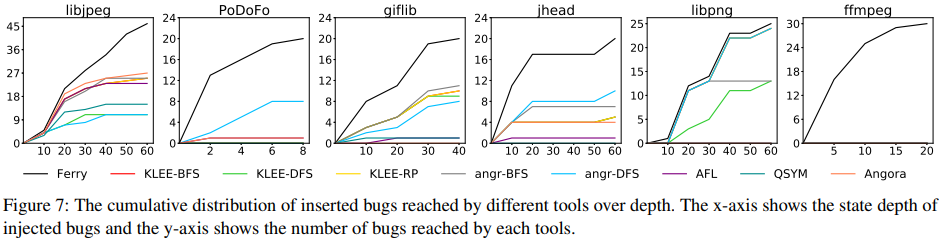
우리의 결과는 기존 심볼릭 실행기와 퍼저들이 얕은 깊이의 버그만을 찾을 수 있다는 것을 보여준다. 구체적으로, 깊이가 20보다 작을 때, 해당 도구들은 삽입된 버그 중 46%(110개 중 51개)를 찾을 수 있었다. 그러나, 깊이가 40보다 큰 17개 취약점 중에서는 angr(DFS)와 KLEE(RP)만이 각각 5개를 찾을 수 있었다.
6.4 Accuracy of Inferred SDVO instructions
우리의 지식으로는, 주어진 프로그램의 SDVO 명령어에 대한 ground truth가 없어서, SDVO 명령어 추론의 정확성을 철저하게 평가할 수 없다.
대신, 우리는 예시로 libjpeg의 SDVO 명령어를 확인했다. Ferry는 총 88개의 SDVO 명령어를 인식하여, 수동으로 라벨링된 명령어를 모두 커버했다.
10시간의 코드 검사 후, 우리는 49개의 SDVO 명령어를 발견했다. 우리의 추가적인 수동 분석으로, 나머지 39개의 인식된 명령어가 실제로 SDVO 명령어임을 확인했다. 이들은 프로그램의 깊은 로직에 위치하여, 다중 함수 호출과 변수 할당 후에 코드가 존재하기 때문에, 인간의 노력으로 입력 추적이 어려워서 코드 검사에서 누락된 것이다.
6.5 A Case Study
CVE-2016-3830 in libstagefright
CVE-2016-3830은 libstagefright의 취약점으로 보고되었었다. 평가된 모든 심볼릭 실행 엔진 중에서 shortcut 심볼릭 실행기능을 가진 Ferry만이 이 취약점을 자동으로 찾을 수 있었다. 우리의 수동 검사는 이 취약점을 밝혀내기 위한 어려움을 보여준다.
- 취약점은 AAC 포맷의 오디오 디코더에서 발생하고, 최소한 두개의 earlier 상태 머신으로 "protected(보호)"된다. 즉, 오디오 디코더를 초기화하고, 오디오 헤더와 트랙을 추출하는 첫번째 상태 머신과, 오디오 헤더를 사용하여 디코더를 구성하는 두번째 상태 머신이 있다. 취약점은 오디오 트랙을 디코딩하는 세번째 상태 머신에 존재한다. 우리의 실험 결과, angr는 첫번째 상태 머신에서 경로 폭발 문제가 발생하며, Ferry는 두번째 상태머신에서 심각한 경로 폭발 문제가 발생한다.
- 취약점은 세번째 상태 머신의 깊은 프로그램 상태에서만 악용될 수 있다. 구체적으로, 예상된 페이로드 크기인
adtsHeaderSize와aac_frame_length에 저장된 계산 결과 간의 불일치가 발생한 상태이다. 최첨단 심볼릭 실행 기술의 효율성을 측정하기 위해, 우리는 이 경우를 angr에 수동으로 세번재 상태 머신의 엔트리 포인트로 할당했다. 우리의 평가 결과, angr는 여전히 이 취약점을 찾지 못한다.
6.6 Performance Baseline
이 섹션에서는 상태에 의존하지 않는 분기가 있는 코드 로직을 탐색할 때, Ferry의 성능 기준을 찾으려고 한다. 이를 위해 LAVA-M 데이터셋을 사용했는데, LAVA는 취약점을 입력 바이트가 "제어 흐름을 결정하지 않는" 위치에만 삽입하기 때문이다(i.e., 이러한 위치에 도달하는 경로에 관여하는 제어 흐름 문장은 입력 바이트와 독립적이다). 즉, 이러한 취약점을 향하는 실행 경로에는 state-dependent 분기가 없다. 우리는 이에 대한 자세한 결과를 부록 B에서 제시한다.
부록 B
결과는 최악의 경우에는 Ferry가 BFS 전략을 사용하는 angr와 거의 동일한 성능을 발휘하지만, 일부 중복된 경로를 탐색하지 않는 차이가 있다는 것을 보여준다.
6.7 Discussion
우리의 실험은 Ferry가 상태 의존적 분기를 탐색하기 위한 효과적은 심볼릭 실행 엔진을 제공하고, 심볼릭 실행을 위한 도전적인 문제인 상태 의존적 분기로 프로그램을 처리하는 방법을 해결하기 위한 첫 단계를 달성한다는 것을 보여준다. 이 섹션에서는 Ferry의 한계와 어떤 상황에서 Ferry가 실패할 수 있는지에 대해 논의한다.
State Explosion
표 2에서는 Ferry의 효율성이 특정 프로그램 로직(e.g., 문자열 검색, 압축 알고리즘)에서 제한된다는 것을 보여준다. 이러한 로직은 복잡한 경로 제약 조건을 생성하여 제약 조건 솔버를 압도할 수 있는 심볼릭 실행기에 대한 일반적인 도전과제이다. 또한, 이러한 프로그램 로직은 상태 폭발을 야기한다.
예를 들어, 압축 프로그램은 막대한 내부 상태 공간을 가지고 있으며, 입력 바이트의 변경은 다른 프로그램 상태를 유발하고, 이후의 모든 입력 처리 방식을 변경한다. 이러한 경우에 Ferry는 상태 폭발에 시달린다(이는 경로 폭발을 더욱 야기시킴).
상태 폭발을 완화하는 데 도움이 되는 최적화 기법들도 이 문제를 완전히 해결하지 못한다.
우리의 기술은 state-dependent 분기가 있는 프로그램에 체계적으로 접근하기 위한 첫번째 시도로서, 섹션 2.3에서 설명한 유사한 내재적 특성을 가진 프로그램에 대해 작동한다.
그러나, 현재로서는 범용적인 접근 방식은 아니다. 여전히 심볼릭 실행 엔진을 방해하는 주요 challenge는 임의의 프로그램에서 상태 설명 변수를 식별하는 방법이다. 이 문제는 Ferry에 대한 우리의 future work로 남겨둔다.
7 Related Work
이 섹션에서는 두가지 부류의 동적 분석 접근법에 대해 논의한다
1. 심볼릭 실행에 대한 다른 연구
2. 버그 찾기에서 심볼릭 실행 엔진의 대안으로 알려진 퍼징 테스트
우리는 실제 프로그램, 운영 체제, 네트워크 프로토콜의 상태 공간을 탐색하고, 이 논문과의 차이점을 설명하는 관련 연구에 대해 추가로 논의한다.
7.1 Symbolic Execution
Ferry는 state-dependent 프로그램의 분기를 체계적으로 처리하는 최초의 심볼릭 실행 엔진이다.
최초의 심볼릭 실행 엔진이 등장한 이래 수십개의 심볼릭 실행 엔진이 제안되면서, 수십년이 흘렀다. 이들이 높은 코드 커버리지를 달성하는 방식에 따라 세가지로 특정지을 수 있다.
Mixing concrete and symbolic execution
심볼릭 값의 일부를 구체적인 값으로 대체하면, 경로 폭발을 크게 완화시킬 수 있고, 성능이 향상된다.
예를 들어, S2E는 자동 bidirectional 심볼릭-concrete 상태 변환을 제안하여, 실행을 심볼릭 모드와 콘크리트 모드 간에 매끄럽고 정확하게 오갈 수 있다. 이 논문에서는 선행하는 콘크리트 실행과 후속하는 심볼릭 실행을 혼합한 shortcut 심볼릭 실행을 제안한다.
그러나, 기존의 콘클릭 테스팅이 무작위로 분기를 되돌리는 것과 달리, 우리의 핵심 문제는 입력 파티션의 경계를 자동으로 결정하고, 해당 state-dependent 분기 그룹을 탐색하는 방법이다. 이 문제는 우리의 독특한 관찰을 기반으로 해결된다.
Compositional execution
compositional 실행은 프로그램의 기본 단위(i.e., 메소드, procedure)를 별도로 분석하고, 단위의 입력-출력 변환을 인코딩하는 요약에 분석 결과를 저장한다.
이는 처음으로 Dart에 의해 제안되었으며, 구성 실행의 개선을 위해 여러 최적화가 제안되었다.
일반적으로 구성 실행의 기본 가정은 함수 간의 느슨할 결합이라는 것이며, 따라서 전체 프로그램이 아닌 elementary unit을 직접적으로 확인함으로써 확장성을 향상시킬 수 있다.
그러나, state-dependent 분기되는 프로그램의 경우, 각 기본 단위(elementary unit)의 동작은 실행 지점의 프로그램 상태에 따라 다를 수 있다.
Selective symbolic execution
선택적 심볼릭 실행(또는 가이드된 심볼릭 실행)은 실행 경로 선택에 휴리스틱 정책을 적용하여 곧 바로 올 새로운 코드를 커버할 가능성이 가장 높은 경로를 실행하려한다.
예를 들어, KLEE의 휴리스틱은 커버되지 않은 명령문까지의 최소 거리, 프로세스의 호출 스택, 최근에 새로운 코드를 커버했는지 여부의 조합이다.
Li는 하위 경로(subpath) 프로그램 스펙트럼을 사용하여, 완전한 경로 정보를 체계적으로 근사화하고, 심볼릭 실행을 덜 방문한 경로로 안내한다.
반면 Chopper는 사용자가 분석 중, 제외할 코드의 무흥미한 부분을 지정할 수 있도록 한다.
Ferry도 선택적 심볼릭 실행을 적용하며, 도달한 프로그램 상태는 다시 탐색되지 않아야 한다는 인사이트를 이용한다. 따라서, Ferry는 특정 경로를 우선시하는 대신 도달한 프로그램 상태를 탐색하는 중복 경로를 자동으로 제거한다.
7.2 Fuzzing
퍼징(퍼즈 테스트)은 프로그램에 잘못된, 예상치 못한, 무작위인 데이터를 입력으로 제공하고, 프로그램의 예상치 못한 동작을 모니터링하는 자동화된 테스트 기법이다. 변이 기반 퍼저들은 제공된 참조 입력(시드)을 수정하여 입력을 생성한다. 이들은 미탐색된 프로그램 동작이 프로그램 입력의 단순한 변이에 의해 트리거될 수 있다고 가정한다. 그러나, 이러한 가정은 많은 상태에 따라 분기가 있는 프로그램에서는 성립하지 않는다. 왜냐하면, 변형된 프로그램 입력은 일련의 상태 전이를 트리거하기가 어렵기 때문이다. 생성 기반 퍼저들은 일반적으로 제공된 입력 모델(또는 형식)에 기반하여 입력을 생성한다. 일반적으로 데이터 템플릿을 지정하는 데 인간의 노력이 필요하다. 더 안 좋은 점은, 프로그램의 상태를 추론하는 것이 어렵다는 것이다. 따라서, state-dependent 분기를 가진 프로그램의 입력 모델링은 시간이 많이 소요될 수 있다.
또한, guided된 퍼저들은 휴리스틱을 적용하여, 미탐색된 코드에 도달할 가능성이 있는 테스트 케이스를 선택한다.
예를 들어, AFL은 프로그램 instrumentation을 사용하여, 어떤 입력이 새로운 프로그램 분기를 탐색하는지 이해하고, 이러한 입력을 추가적인 변이를 위한 시드로 유지한다. 몇 가지 최적화 기법은 다양한 경로 제약 조건을 해결하여, 분기 커버리지를 증가시키는 새로운 휴리스틱을 추가한다.
또한, Driller는 선택적인 콘클릭 실행을 활용하여, 퍼징을 위한 시드를 생성한다. 이러한 도구들은 하나의 입력 검사를 처리할 수 있지만, 실제 세계의 상태 기계들은 보통 복잡한 검사들의 연속을 포함하고 있어서, 이들을 압도할 수 있다. 게다가, 이들은 새로운 경로를 탐색하는 데 초점을 맞추고 있으며, 우리 논문에서 논의하는 프로그램의 상태에 대해서는 알지 못한다. 결과적으로, 그들의 휴리스틱은 프로그램 상태를 효율적으로 탐색할 수 없도록 만들어진다.
7.3 Program and System State Exploration
Ferry를 제외한 몇 가지 관련 연구는 실제 세계의 프로그램, 운영체제, 네트워크 프로토콜에서 상태 공간을 탐색하려고 시도한다. 우리는 이 논문과의 차이점을 다음과 같이 설명한다.
IJON은 프로그램의 깊은 상태 공간을 탐색한다. 이는 인간 전문가가 퍼저에게 피드백을 제공하여 상태 기계를 탐색하는 데 도움을 준다.
반면, 우리의 연구는 상태 설명 변수를 자동으로 추론하고, 인간의 노력이 필요하지 않다. 우리의 연구에서 분석하는 실제 세계의 프로그램에는 수십, 수백개의 상태 설명 변수가 포함되어 있어서, 이는 인간 분석가들을 압도할 수 있다.
운영체제에서 상태 공간을 탐색하는 관점에서 상태 인식 커널 퍼징 기술은 커널 로직을 탐색하는 동안 운영체제의 상태를 모니터링한다. 본 논문에서 다루는 프로그램 상태와 달리, 운영체제 상태는 잘 정의된 메타데이터로 설명되며, 상태 전이는 잘 정의된 이벤트(e.g., syscall이 호출되거나, 인터럽트가 발생함)가 발생할 때 발생한다. 따라서, 상태 설명 변수를 식별하거나 런타임 상태를 인식하는 것은 상태 인식 커널 퍼징에서 주요한 도전과제가 아니다. 그러나, 이는 섹션 2.1에서 보여주는 프로그램 상태 인식 심볼릭 실행에서 주요한 도전 과제이다.
heartbleed와 같은 심각한 취약점이 발생한 이후로, 상태를 가지는 네트워크 프로토콜은 유망한 분석 대상의 또 다른 범주이다. 네트워크 프로토콜의 입력 시퀀스는 클라이언트와 서버 간의 개별 메시지로 나누어진다. 서버에서 메시지가 처리되면, 서버 상태를 명시적으로 보여주는 상태 코드와 함께 응답이 반환된다. 현재의 상태를 가지는 프로토콜 퍼징 작업은 이러한 네트워크 프로토콜에 대한 사전 지식(e.g., 메시지 구조, 상태 코드)을 활용하여 분석한다.
예를 들어, AFLNEet은 메시지 구조와 프로토콜별 정보를 사용하여, 개별 메시지를 추출하고, 상태 코드를 읽어 서버의 상태를 결정하며, 휴리스틱을 사용하여 메시지를 재정렬하여 프로토콜 상태를 탐색한다.
그리고 MACE는 사용자가 제공한 상태 기계 모델 추상화에 의존하며, 이 정보를 사용하여 콘클릭 실행을 유도한다.
반면, Ferry는 분석 대상 프로그램과 입력 구조에 대한 사전 지식이 없다고 가정한다. Ferry의 관점에서 상태 코드는 다른 상태 설명 변수와 다를 바가 없으며, 프로그램 상태를 설명하는 모든 변수를 자동으로 인식하려고 시도한다.
8 Conclusion
본 연구에서는 입력 데이터와 상태 설명 변수 간의 데이터 의존성이 존재하는 중요한 실제 프로그램 클래스에서 프로그램 상태를 인식하는 심볼릭 실행을 처음으로 시도했다. state-dependent 분기가 있는 실제 프로그램에 초점을 맞춘 새로운 심볼릭 실행 엔진인 Ferry를 제안한다. 우리는 Ferry를 두가지 포괄적인 테스트 스위트, 13개의 실제 프로그램, 15개 보고된 취약점에 적용하여 접근 방법의 효과를 입증한다. 실험 결과는 Ferry가 기존 접근 방법보다 뛰어난 성능을 보여준다. 우리의 평가는 또한, Ferry가 다른 기술보다 더 많은 코드(기본 블록)와 분기를 커버하며, 최첨단 심볼릭 실행기와 퍼저보다 2.4배 더 많은 프로그램 상태에 의존하는 취약점을 찾는 것을 보여준다. 우리의 연구는 일반적인 목적의 프로그램 상태 인식 심볼릭 실행을 달성하기 위한 후속 연구에 대한 성공적인 경험을 제공한다.
