Apache Hadoop
1.[Hadoop] Hadoop 기본, NameNode 장애 대비책

DataNode 에 데이터 블록이 어디에 저장되어있는지, 복제본이 어떠한지 관리데이터 블록을 저장하는 노드NameNode에 질의하여 파일을 요청NameNode가 응답하면 블록 검색을 위해 어떤 DataNode에 접근해야하는지를 알 수 있음DataNode에 접근하여 데이
2.[Hadoop] SafeMode 확인, 진입, 해제
https://wikidocs.net/25321 세이프 모드 상태의 확인, 진입, 해제 커맨드는 다음과 같습니다. 세이프 모드 상태 확인 $ hdfs dfsadmin -safemode get Safe mode is OFF 세이프 모드 진입 $ hdfs dfsadm
3.[Hadoop] CLI 명령어 기본
대부분 일반 linux cli 명령어와 공통되는 부분이 많음hadoop fs -ls파일, 디렉토리 목록 나열hadoop fs -mkdir {디렉토리명}디렉토리 생성hadoop fs -rm {파일명}파일 삭제hadoop fs -copyFromLocal {local파일명}
4.[Hadoop] Mapreduce 기본
MapReduce 하둡이 제공하는 빌트인 도구 데이터를 클러스터에 분배하는 작업 수행 데이터를 파티션으로 나누어 클러스터에서 병렬로 처리할 수 있도록 함 Mapper 는 관심있는 데이터를 뽑아 데이터를 추출하고 구조화 Reducer 는 mapper 에서 변경, 추출
5.[Hive] Hive 의 특징
친숙한 SQL 문법을 사용대화형 프롬프트로 쿼리문 사용 가능Hive QL 을 통해 일반적인 RDB처럼 SQL문을 통해 데이터 조회클러스터에 적재된 빅데이터에 작업 가능복잡하게 MapReduce를 직접 하는 대신 SQL 로 쉽게 사용실시간성 쿼리에 유용큰 데이터셋 전체에
6.[Hadoop] Sqoop 개요
SQL + Hadoop 합쳐 만든 이름데이터세트를 HDFS 로 가져오거나 내보내기.ex) MySQL, PostGres 와 같은 데이터베이스에 가져와 MapReduce를 수행, HDFS 로 적재sqoop import --connect jdbc:mysql://localho
7.[Hadoop] Hadoop 상태 체크 (report)
hdfs dfsadmin -report -livelive한 data node 포함 hadoop 상태 reporthdfs dfsadmin -report -deaddead한 data node report
8.[HBase] HBase 개요
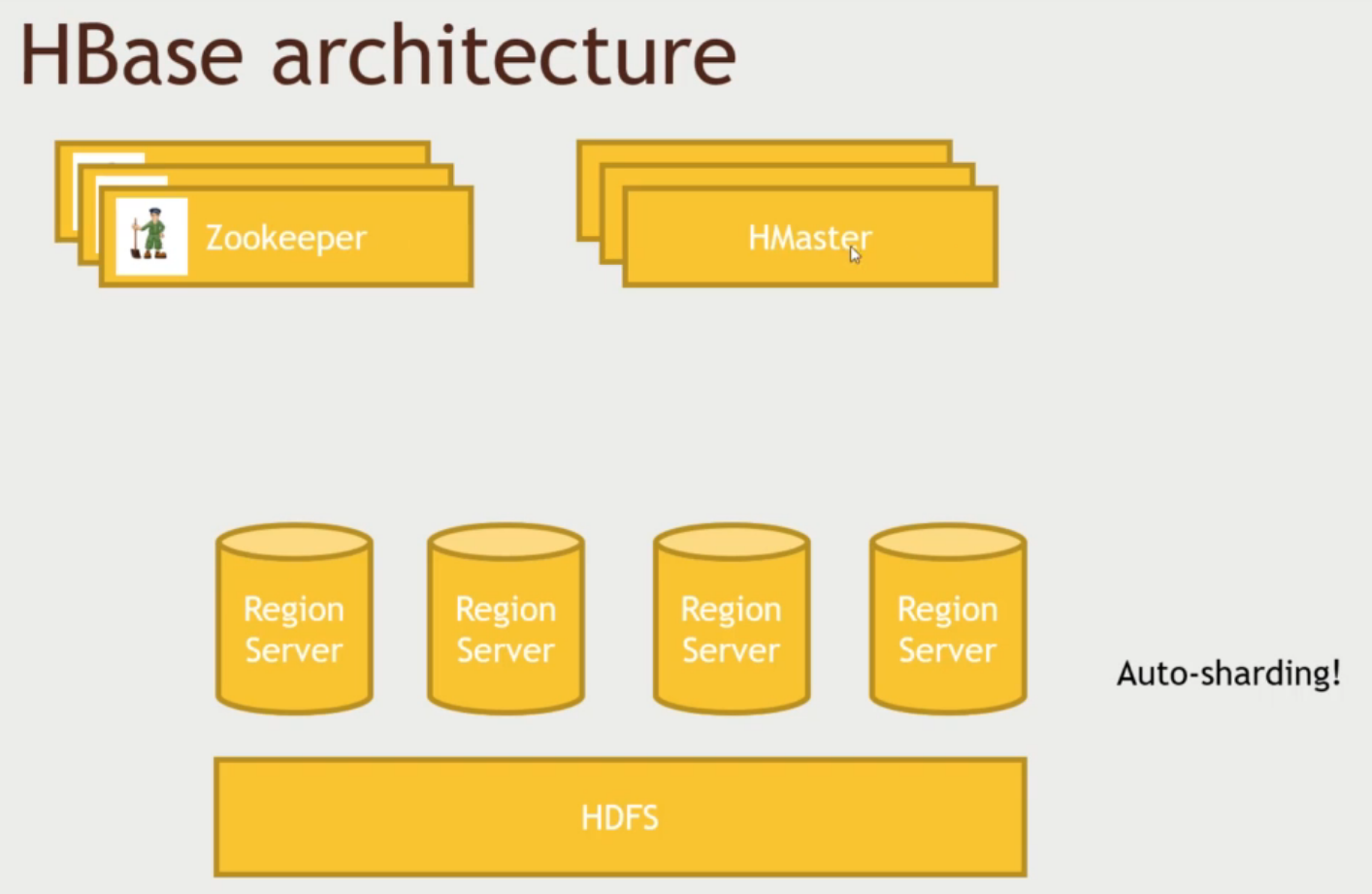
HDFS 위에 구축된 비관계형 DB (Non-relational)수평적으로 확장성을 가짐 (scalable)HDFS 기반으로 분할 저장된 데이터를 SQL로 빠르게 조회 가능HDFS 에 저장된 데이터를 HBase 를 활용해 대규모로 외부로 내보낼 수 있음SQL 미지원,
9.[Hadoop] Hadoop 서비스 포트 정리
Hadoop 서비스 포트 정리
10.[Hadoop] Hadoop 클러스터에서 노드 제거
hdfs-site.xml 의 dfs.hosts.exclude 에 파일명을 지정한다.해당 파일에는 클러스터에서 제거할 노드 IP를 기재한다.Hadoop Namenode 를 재시작한다.이미 dfs.hosts.exclude 를 설정한 경우 재시작 없이 refresh 할 수