16.3. Matrix Factorization
- Matrix Factorization(이하 MF)은 Simon Funk가 제안했습니다. 블로그글
- MF는 Netflix contest에서 유명해집니다. 우승팀의 솔루션은 여러 모델을 앙상블한 것이었는데, 주요 역할을 한것이 MF였습니다. 우승팀의 솔루션 리포트는 여기에서 확인할 수 있습니다.
16.3.1. The Matrix Factorization Model
- MF는 협업필터링의 하위 모델입니다. 유저-아이템 상호작용 행렬을 두개의 lower rank 행렬의 곱으로 분해하여 유저-아이템간 상호작용을 포착합니다.
은 유저 m명과 아이템 n개를 가지는 rating 행렬을 의미합니다.
은 유저-아이템 행렬을 분해하여 만든 유저잠재행렬을 의미합니다. k는 잠재행렬의 차원으로, 하이퍼파라미터입니다.
은 유저-아이템 행렬을 분해하여 만든 사용자잠재행렬을 의미합니다. k는 잠재행렬의 차원으로, 하이퍼파라미터입니다.
를 유저잠재행렬 의 u번째 행
를 아이템잠재행렬의 i번째 행이라고 할때
는 아이템 i가 가진 특성(ex. 장르, 언어)를 의미할 수 있고,
는 유저 u의 선호를 의미할 수 있습니다. 그러나 완전히 명확하게 해석될 수는 없습니다.
예측된 평점은 아래의 수식으로 나타낼 수 있습니다.
그러나 유저마다 평균적으로 평점을 적게 줄수도, 많이 줄수도 있습니다. 아이템도 마찬가지로 편향이 존재합니다. 따라서 유저와 아이템의 편향을 더해주면 아래와 같은 식이 완성됩니다.
위의 식을 학습할 때 mean squared error를 사용합니다. 이를 수식으로 나타내면 다음과 같습니다.
는 규제를 얼마나 할 것인지 regularization rate를 나타냅니다. 뒤에 따라오는 규제항은 파라미터의 크기가 커지는 것에 대한 페널티를 주어 파라미터의 과적합을 막기 위한 것입니다. 위의 목적함수로 Gradient Descent를 하여 파라미터를 학습하게됩니다.
지금까지의 과정을 하나의 그림으로 나타내면 아래와 같습니다.
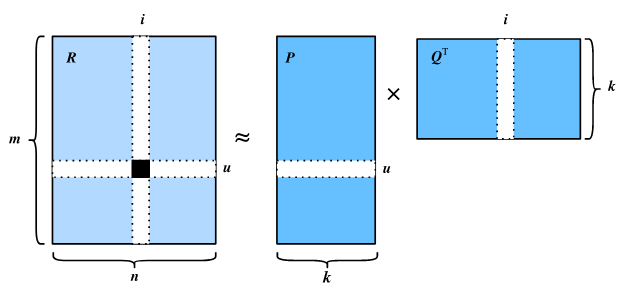
유저-아이템 행렬을 유저잠재행렬과 아이템 잠재행렬로 분해한 것을 볼 수 있습니다.
16.3.2. Model Implementation
다음부터는 MF모델 구현 코드를 살펴보겠습니다. 아래의 코드는 mxnet으로 구현된 D2L코드를 참고하여 pytorch로 구현한 것입니다.
전체코드는 여기에서 확인할 수 있습니다.
from torch import nn
class MF(nn.Module):
def __init__(self, num_factors, num_users, num_items, **kwargs):
super(MF, self).__init__(**kwargs)
self.P = nn.Embedding(num_users, num_factors)
self.Q = nn.Embedding(num_items, num_factors)
self.user_bias = nn.Embedding(num_users, 1)
self.item_bias = nn.Embedding(num_items, 1)
def forward(self, user_id, item_id):
P_u = self.P(user_id)
Q_i = self.Q(item_id)
b_u = self.user_bias(user_id)
b_i = self.item_bias(item_id)
outputs = (P_u * Q_i).sum(axis=1) + np.squeeze(b_u) + np.squeeze(b_i)
return outputs.flatten()Embedding layer를 이용해 num factors 크기의 차원을 갖는 latent matrix로 만듭니다.
Embedding layer의 원리는 다음과 같습니다.
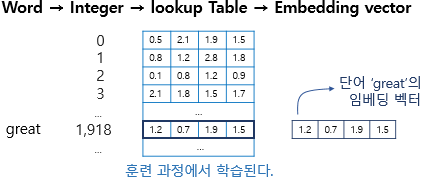
출처
( 가질수있는 id개수 x 매핑할차원수 ) 크기를 갖는 행렬을 만들고 이를 학습하는 것입니다.
위의 사진에서 great이라는 단어의 id는 1918이고, 임베딩은 해당행의 (1.2, 0.7, 1.9, 1.5)입니다.
위의 수식의 유저/아이템 잠재행렬과 bias 모두 구현된 것을 볼 수 있습니다.
16.3.3. Evaluation Measures
RMSE를 사용합니다. 는 유저-아이템쌍의 개수, 즉 학습 데이터의 개수를 의미합니다.
(아래의 구현에서는 를 생략했습니다.)
class RMSELoss(torch.nn.Module):
def __init__(self):
super(RMSELoss, self).__init__()
def forward(self, x, y):
criterion = nn.MSELoss()
eps = 1e-6
loss = torch.sqrt(criterion(x, y) + eps)
return loss16.3.4. Training and Evaluating the Model
num_users, num_items, train_iter, test_iter = split_and_load_ml100k(
test_ratio=0.1, batch_size=512)
model = MF(30, num_users, num_items)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model.to(device)lr, num_epochs, wd = 0.002, 50, 1e-5
loss_func = RMSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr = lr, weight_decay=wd)
learnig rate, epoch수, weight decay값을 설정합니다.
loss와 weight decay를 사용하여 학습합니다. weight decay는 regularization과 같은 효과를 가집니다.
from tqdm import tqdm
import glob
train_epoch_loss = []
val_epoch_loss_lst = []
best_val_epoch_loss = int(1e9)
for epoch in tqdm(range(num_epochs)):
train_iter_loss = []
for i, values in enumerate(train_iter):
train_user = values[0].long().to(device)
train_item = values[1].long().to(device)
labels = values[2].to(device)
preds = model(train_user, train_item)
loss = loss_func(preds, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_iter_loss.append(loss.detach().item())
if i%50 == 0:
print(f'{epoch} epoch {i}th train iter loss: {loss.detach().item()}')
train_epoch_loss.append(np.mean(train_iter_loss))
print(f'{epoch} epoch ALL LOSS : ', np.mean(train_iter_loss))
with torch.no_grad():
model.eval()
val_epoch_loss = 0
for i, values in enumerate(test_iter):
test_user = values[0].long().to(device)
test_item = values[1].long().to(device)
labels = values[2].to(device)
preds = model(test_user, test_item)
loss = loss_func(preds, labels)
val_epoch_loss += loss.detach().item()
val_epoch_loss /= len(test_iter)
val_epoch_loss_lst.append(val_epoch_loss)
if val_epoch_loss < best_val_epoch_loss:
best_val_epoch_loss = val_epoch_loss
print(f'New best model loss: {best_val_epoch_loss}')
if not os.path.exists('model'):
os.mkdir('model')
if os.path.exists('model/best.pth'):
os.remove('model/best.pth')
torch.save(model.state_dict(), 'model/best.pth')
print('best model is saved!')
49 epoch ALL LOSS : 0.6171384588959291 # train last epoch loss
New best model loss: 2.040631353855133 # best val losstrain data로 predicted rating을 내고, GT와 비교하여 loss를 낸 후,
gradient descent하는 과정입니다. 각 에폭마다 validation loss를 잽니다.
최소의 val loss를 가지는 모델이 저장됩니다.
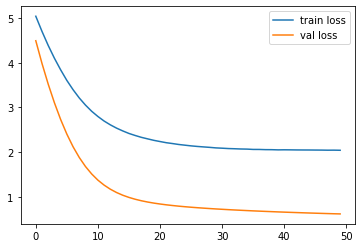
train loss, validation loss 모두 줄어드는 것을 볼 수 있습니다.
아래는 20번 유저가 20번 아이템에게 부여할 것이라고 예상되는 평점입니다.
scores = model(torch.tensor([20]).to(device), torch.tensor([20]).to(device))
scorestensor([2.4434], device='cuda:0', grad_fn=<AddBackward0>)16.3.5. Summary
- MF모델을 추천시스템에서 널리 쓰이는 모델이다. 유저가 아이템에 부여할 평점을 예측하는데에 쓰일 수 있다.
16.3.6. Exercises
- latent factor의 사이즈를 다르게 해봅시다. 어떤 영향을 줄까요?
- 다른 옵티마이저, 학습률, weight decay rate를 사용해봅시다.
- 다른 유저의 특정 영화에 대한 예측 평점을 살펴봅시다.
