사전지식
베이즈 정리
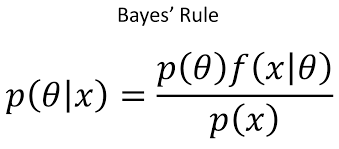
: 추정하려는 분포의 파라미터
: 우리가 가지고 있는 데이터
: 사후확률, 관측치 x가 주어졌을때 theta(=수식을 구성하는 parameters)를 가지는 확률
: 사전확률, 관측치 x를 통해 특정하고자 하는 함수이다. 대부분 분포를 알 수 없는 경우가 많기에 특정 분포를 가진다고 가정하여 진행
: likelihood, 특정 파라미터를 가지는 분포로부터 해당 데이터가 나올 확률, posterior과 likelihood는 서로 뒤집어 놓은 형태임.
결국 베이즈정리는 사후확률(posterior) = 사전확률(prior) * likelihood / 상수로 전개됌
이 글에서 앞부분 참조
MLE
MLE란 관측치로부터 분포를 추정하는 방법으로, 가능도를 가장 크게하는 파라미터를 찾고 이로 분포를 근사하는 것이다.
아래와 같은 상황이라면 주황색 분포로부터 샘플이 추출됐을 가능성이 클 것이다.
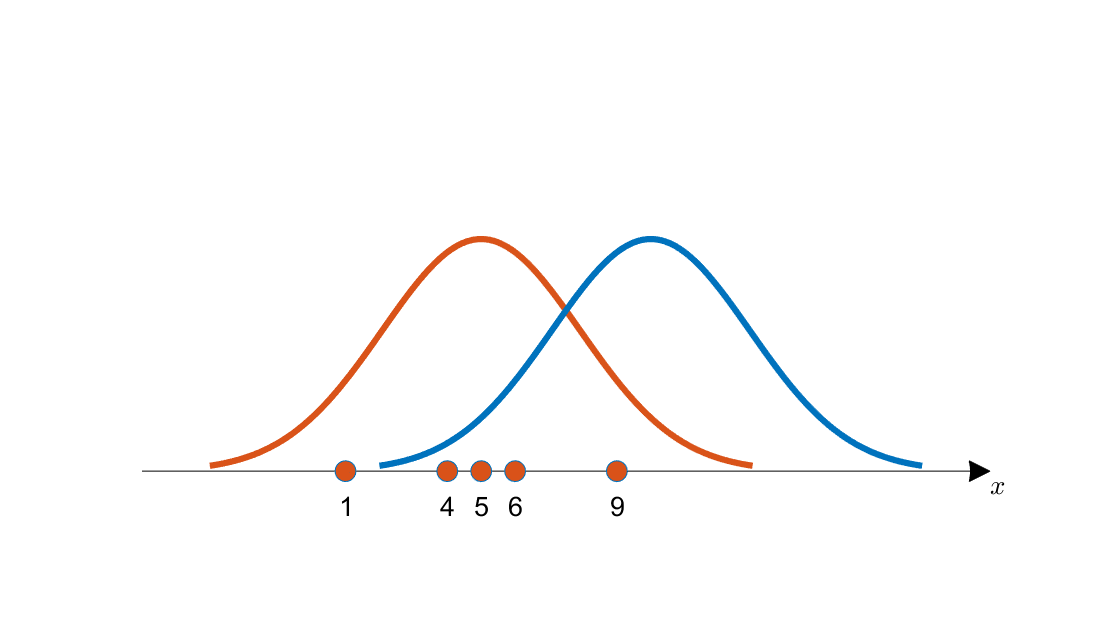
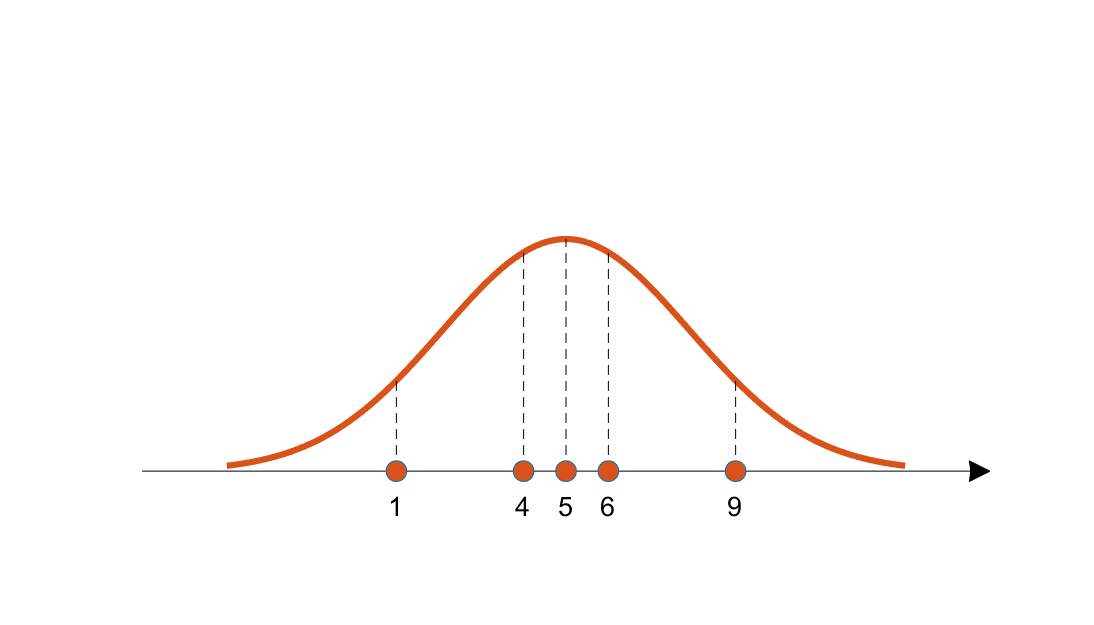
그렇기에 likelihood, 를 (x : 관측치, :분포의 파라미터) 최대화하는 를 찾는다.
더 자세히는 각 데이터가 특정 파라미터의 분포로부터 나왔을 확률을 모두 곱한 우도함수 (아래 수식)
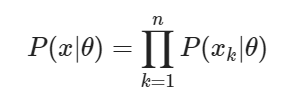
계산의 용이성을 위해 log를 씌운 로그우도함수(아래수식)를 최대화하는 를 찾는다.
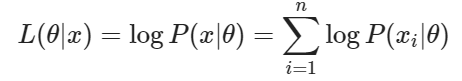
더욱 자세한 내용은 https://angeloyeo.github.io/2020/07/17/MLE.html 참고
MLE와 딥러닝
신경망은 가중치값에 따라 결과값이 바뀌는 하나의 확률분포라고 말할 수 있다.
딥러닝은 최적의 가중치를 찾는 과정이고, 이는 곧 likelihood를 최대화하는 방향으로 최적의 가중치를 찾는 MLE 과정이라고 말할 수 있음.
그러나 딥러닝은 경사하강법으로 구현되어 있기에 -를 붙여 negative log-likelihood로 만들어 최대화가 아닌 최소화 문제로 만들어서 최적화를 한다.
MAP(Maximum A Posterior)
posterior = likelihood * prior (분모는 상수로 생략)
위의 수식에서
MLE는 최대 likelihood를 가지는 파라미터 추정
MAP는 최대 posterior를 가지는 파라미터 추정
MLE는 관측치에 영향을 많이 받는다. 예를 들어 우연히 동전이 계속 앞면만 나왔다면 앞면만 존재하는 분포로 예측할 것이다.
즉 MLE는 관측치에만 의존하기에 이상치에 민감하다. 반면 MAP를 한다면 사전확률까지 고려해 이러한 한계를 극복할 수 있다.
더 알아볼 자료

잘 봤습니다. 좋은 글 감사합니다.