RNN
수식으로 나타내면 아래와 같다.
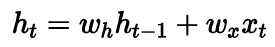
이를 좀 더 직관적으로 살펴보자.
를 위한 weight, hidden을 위한 weight가 존재
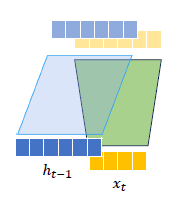
각각을 더하여 activation fuction을 거치면 완성
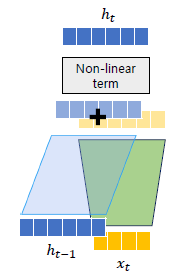
이 는 다음 단계의 로 들어가고 앞에서와 같은 과정을 거치게된다.
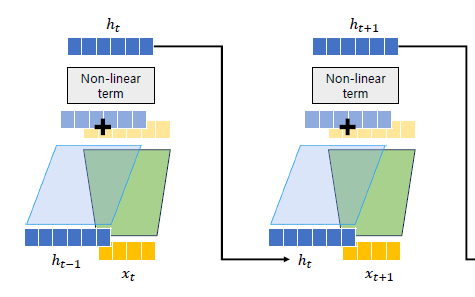
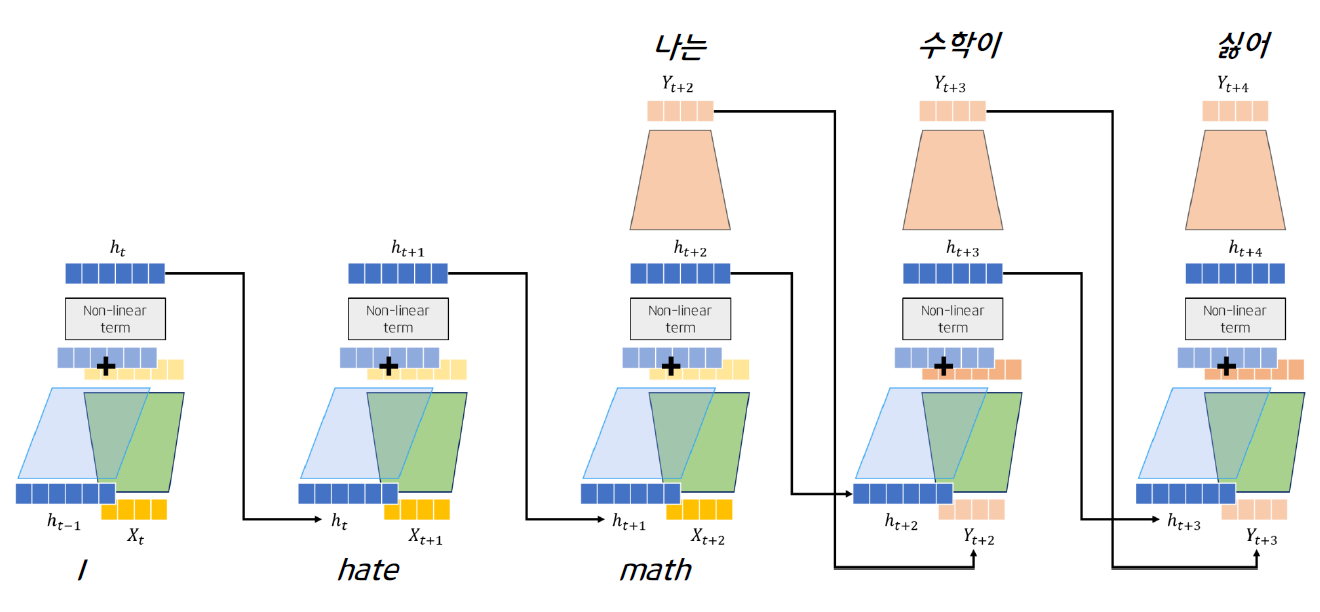
예시
many to many 구조의 RNN을 살펴보자.
영어 -> 한국어 변환을 한다고 가정해보자.
영어문장의 마지막 단어의 hidden과 y가 다음으로 전해져 계속 문장을 생성해간다.
Vanishing Gradient
RNN은 반복적인 activation function을 거치면서 문장이 길어질 시 gradient가 소멸되는 문제가 발생한다.

LSTM
gate 사용
RNN에 비해 vanishing gradient 문제 해결
GRU
LSTM에 비해 적은 파라미터
Seq2Seq
many to many 구조
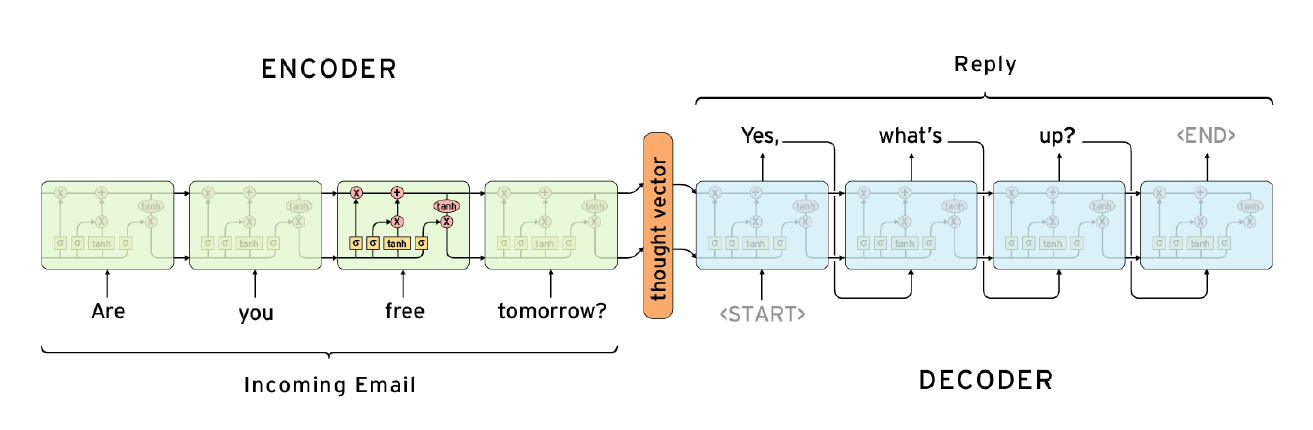
가운데 context vector에만 정보가 집중됌
인코더의 앞단의 정보가 소실될 수 있음
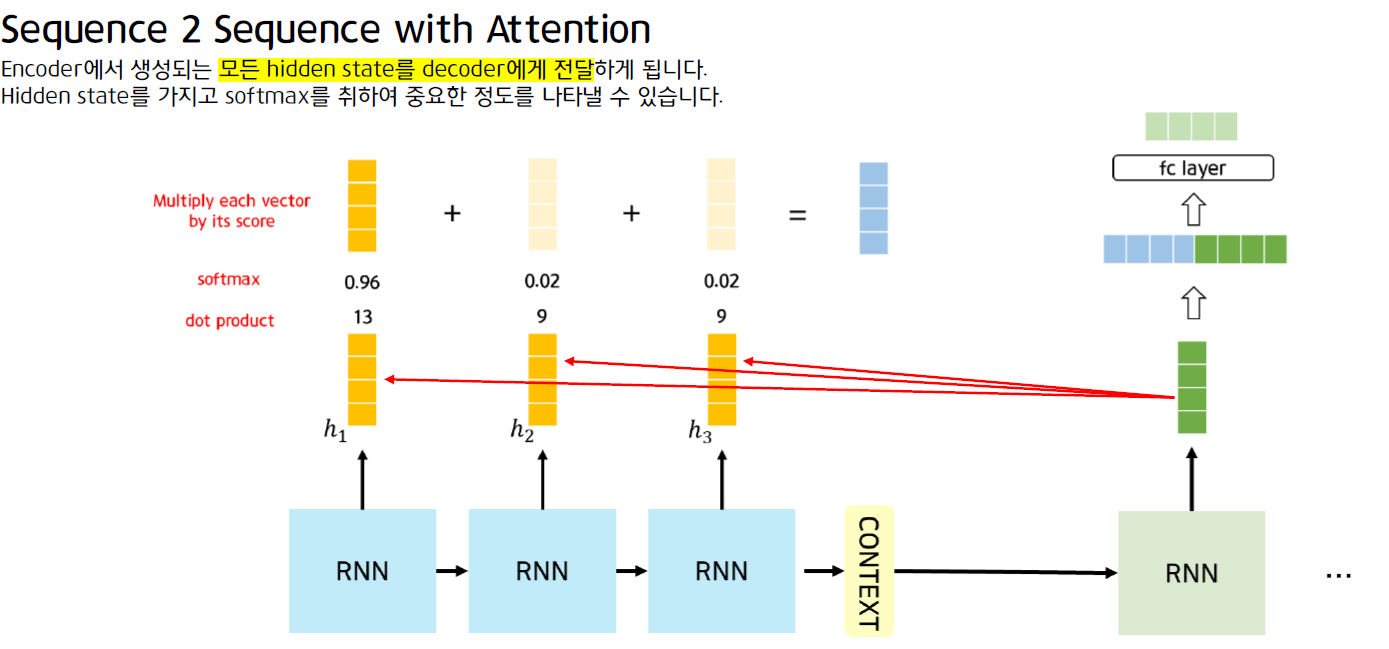
Seq2Seq + Attention
디코더의 hidden과 인코더의 모든 hidden간의 attention을 구해서 인코더의 어떤 hidden에 얼마나 집중할 지 score생성, 이를 적용한 결과를 디코더에 전달

중요한 것은 속력이 아니라 방향성, 공부하며 메모를 남기는 공간입니다.