
어떤 대회였나?
플레이리스트에 있는 곡들과 비슷한 느낌의 곡들을 계속해서 듣고 싶은 적이 있으셨나요?
이번 대회에서는 플레이리스트에 수록된 곡과 태그의 절반 또는 전부가 숨겨져 있을 때, 주어지지 않은 곡들과 태그를 예측하는 것을 목표로 합니다.
만약 플레이리스트에 들어있는 곡들의 절반을 보여주고, 나머지 숨겨진 절반을 예측할 수 있는 모델을 만든다면, 플레이리스트에 들어있는 곡이 전부 주어졌을 때 이 모델이 해당 플레이리스트와 어울리는 곡들을 추천해 줄 것이라고 기대할 수 있을 것입니다.
즉 playlist의 곡, 태그를 숨겼을 때 과연 어떤 곡과 태그가 원래 있었을지 예측하는 모델을 만드는 것이 목표였다.
대회 기간
대회 기간은 2020.04.27 ~ 2020.07.26 이었다.
하지만 나랑 팀원들이 인턴을 하던 중이라 본격적인 시작은 7월부터였다. 약 한달 정도 했다.
어떤 데이터가 있었나?
- 플레이리스트 메타데이터
- 플레이리스트 제목
- 플레이리스트에 수록된 곡
- 플레이리스트에 달려있는 태그 목록
- 플레이리스트 좋아요 수
- 플레이리스트가 최종 수정된 시각
- 곡 메타데이터
- 곡 제목
- 앨범 제목
- 아티스트명
- 장르
- 발매일
- 곡에 대한 Mel-spectrogram
참고) 곡에 대한 Mel-spectrogram 데이터는 용량이 방대합니다 (~240GB). 베이스라인 코드에서와 같이, 해당 데이터를 사용하지 않고도 문제를 해결하는 방법론이 있으니, 컴퓨터의 용량과 컴퓨팅 파워가 충분할 때 사용하세요.
위 경고 문구를 쉽게 넘겨선 안됐다......
주어진 데이터는 세가지로 나뉜다.
플레이리스트에 대한 메타데이터, 곡에 대한 메타데이터, 곡의 오디오 데이터이다.
Mel-spectogram은 곡의 음파를 짧은 시간마다 잘라서 푸리에 변환 후 이어붙여서 음원의 2D 표현을 얻고, 인간의 귀로 잘 구별할 수 없는 부분을 잘라내고 압축해서 완성된다고 한다.
이를 2차원 array 어레이 형태로, npy파일로 제공받았다.
어떤 방식으로 채점하나?
어떻게 모델을 구성했나?
아래 예시 모델과 비슷하게 만들어보려고 했다.

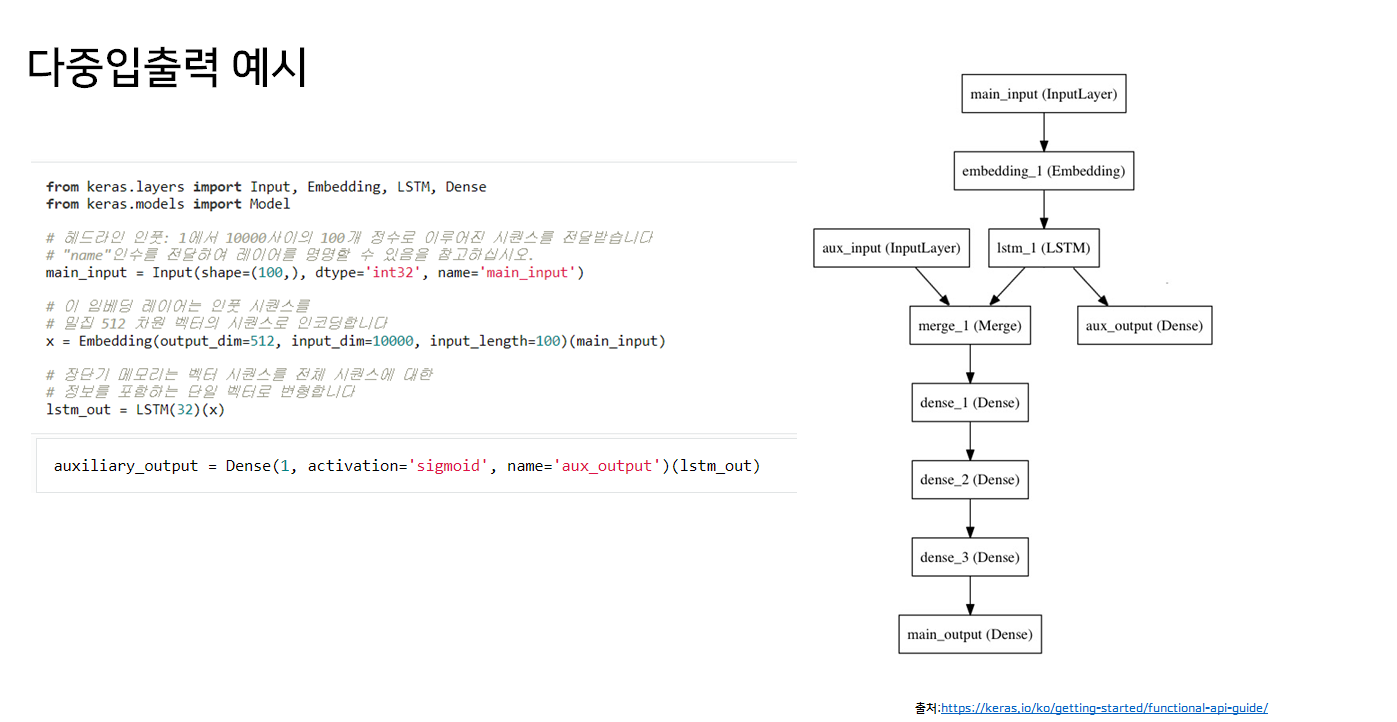
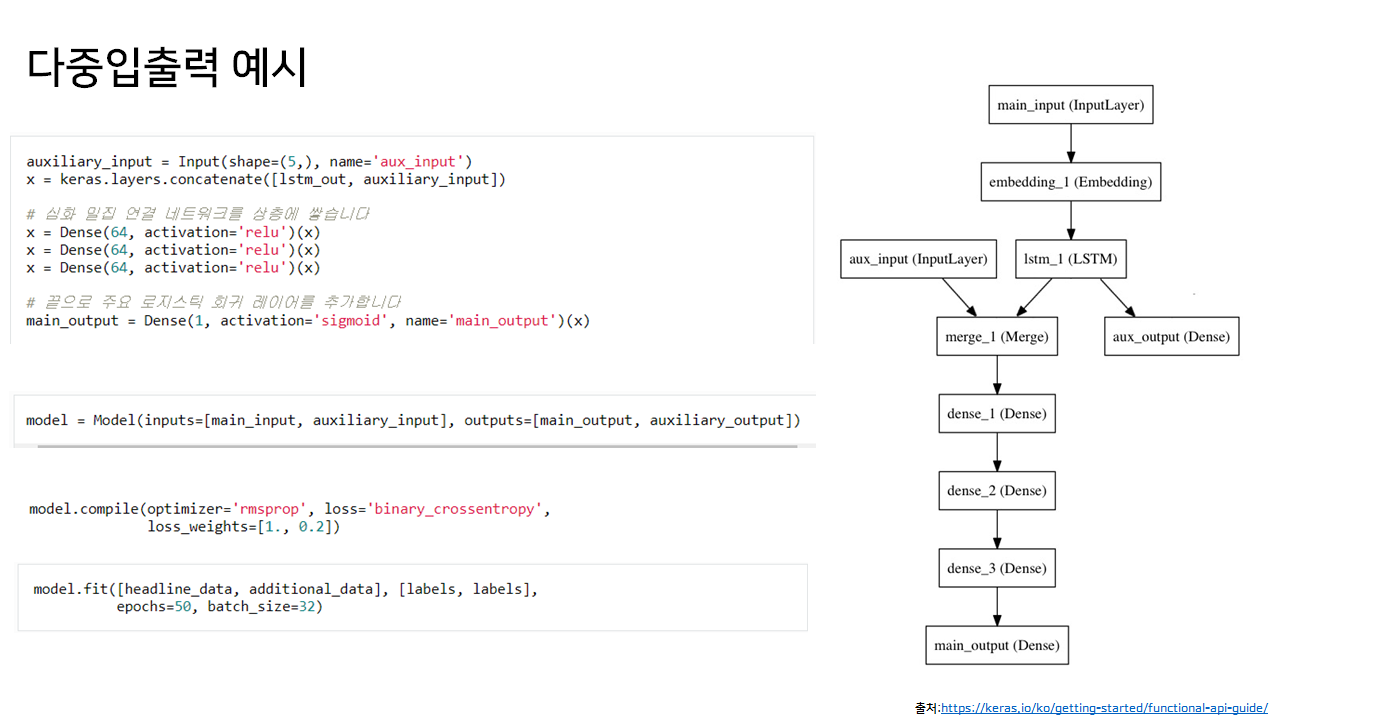
뉴스 헤드라인과 게시시간을 다중 인풋으로 넣고 얼마나 많은 리트윗 횟수와 좋아요 횟수를 얻을 지 예측하는 모델이다.
main input은 뉴스 헤드라인을 각 정수가 단어 하나를 인코딩하는 정수 시퀀스의 형태로 전달받는다. 정수는 1에서 10,000사이의 값이며 (10,000 단어의 어휘목록), 시퀀스의 길이는 100 단어이다.
이를 embedding 레이어와 lstm레이어를 통과해 feature를 표현하는 하나의 벡터로 만든다.(1)
auxiliary_output은 좋아요 횟수로, lstm레이어의 아웃풋이다.(sigmoid)
(1)과 aux input인 게시시간을 concatenate하여 dense층에 통과하여 main output인 리트윗 횟수가 나온다.(sigmoid)
본 대회에서 우리팀은 아래와 같은 모델을 구상했었다.

해당 플레이리스트의 멜스펙토그램 데이터와 태그데이터를 multi input으로 받아서 음원은 cnn으로 feature 추출하고 태그는 word2vec이용해서 임베딩해서 merge한 것을 오토인코더 부류의 모델을 통과해서 음원, 태그를 multi output으로 하는 모델이었다.
느낌적인 느낌으로는 될 것 같았지만 실제로 상세하게 어떻게 구현할 지 막막했다,,
진행 과정에서의 난관들
오디오 데이터와 텍스트 데이터를 CNN과 LSTM으로 feature를 추출한 값을 merge한 것이 오토인코더 모델로 들어가면 아웃풋도 이 merge된 인풋을 복원하게 될 것이다.
우선 음원과 태그는 concatenate된 것이기에 구분점을 기준으로 나누면 음원부분과 태그부분은 나누어 질 것이다.
문제 1
문제는 복원된 음원 feature와 태그feature가 실제 어떤 음원을 가리키는 것인지, 어떤 태그를 가리키는 것인지 어떻게 찾는 지였다.
아니면 CNN과 LSTM을 사용하지 않고 원본 데이터를 concatenate해서 input으로 넣고 오토인코더를 통해 복원하는 모델을 만들면 위와 같은 문제는 발생하지 않는다. 하지만 너무 음원데이터의 차원이 커서 그냥 넣기에는 무리였다.
그래서 우리는 음원데이터를 PCA를 이용해 차원축소한 것과 태그를 Word2Vec으로 임베딩한 값을 인풋으로 하는 오토인코더 모델을 만들어 보기로 했다.
문제 2
하지만 의문점은 남아있었다. 오토인코더는 어떤 데이터가 들어가면 그 데이터를 복원하는 것이다.
그런데 우리의 목적은 원본 플레이리스트가 100개의 곡, 10개의 태그로 이루어져 있었다면 50개의 곡, 5개의 태그를 받고 100개의 곡 10개의 태그를 아웃풋으로 하는 모델을 만들어야했다.
오토인코더 모델로 위와 같이 인풋과 아웃풋의 형태가 다르게 가능한가?하는 의문이 들었다.
이 의문은
원래 플레이리스트의 모든 곡, 모든 태그를 인풋으로하는 오토인코더 모델을 training해서 latent space를 잘 학습하고 이 latent space를 이용해서 곡과 태그를 임베딩하고 이를 이용해 유사도를 구해 추천하는 방향으로 간다는 것으로 이해하였다.
그래서 일단은 팀원이 4명이었기에 2명은 음원 부분을 2명은 태그부분을 맡아서 후에 둘을 합쳐서 모델 완성을 하기로 했다.
나는 오디오 데이터 파트를 맡았다.
우선 곡들의 오디오 데이터를 플레이리스트 단위로 묶는 것부터 시작했다.
문제 3
여기서 또 문제가 발생한다. 음원데이터는 총 240기가로 매우 컸다.
한 컴퓨터에 모든 데이터를 저장할 수 없었고, 다운받는데에도 많은 시간이 걸렸기에 랩실의 컴퓨터 여러대로 데이터를 다운받고 네트워크 공유폴더를 이용해 한데 합쳤다. 이러는데에만 최소 일주일이 걸렸다.
그리고 이들을 플레이리스트 단위로 묶어주는 코드를 작성했다. 그런데 문제점은 한 곡이 여러 플레이리스트에 들어가는 경우가 있어 이를 간과하고 코드를 짰다가 다시 되돌리느라 애먹었다. 그리고 데이터의 중복이 생겨서 데이터양이 더 증가했다.
또한 모든 데이터를 PCA 해줘야 했는데, 이 시간도 매우 오래걸렸다.
결국 교수님의 은혜로 서버를 빌리게 된다. (7.17 즈음)
하지만 서버로 데이터를 옮기고 PCA하고 플레이리스트 단위로 합치는 시간이 4~5일 걸리게 된다. 대회 마감기간이 다가와서는 모델을 끝까지 완성치 못하고 음원 부분은 포기하고 태그 데이터쪽으로 넘어갔다.
음원 사용x 모델

오디오 데이터를 사용하지 않은 모델은 플레이리스트 메타데이터에서
플레이리스트에 수록된 곡, 플레이리스트에 달려있는 태그 목록 을 사용해서 구성했다.
train data에서 특정횟수 이상 등장한 곡 list와 1회 이상 등장한 tag list를 추려내서 단어목록을 구성해 각 플레이리스트마다 one hot encoding했다.
그리고 원핫인코딩된 train set으로 auto encoder를 학습하고,
validation set(일부 곡과 태그를 감춘 데이터)를 원핫인코딩 후 학습된 모델에 넣어서 예측값을 얻었다.
예측값을 argsort해서 최종적으로 song 100개, tag 10개 예측을 한다.
정말 단순한 AE만 사용한 것이기에 VAE같은 것을 사용하면 어땠을까 싶기도 하다. 하지만 제공된 데이터 중 너무 일부만 사용한다는 점과 표현되는 vector가 너무 sparse해서 과연 성능이 얼마나 개선될 지 모르겠다.
부족했던 점은 무엇인가?
-
음원데이터에 함부로 덤볐다
음원 데이터를 플레이리스트 단위로 엮는 것만 해도 너무 시간이 오래 걸렸다. DB를 사용해서 했다면 더 적은 시간이 걸렸을 것 같다. 아니면 음원 데이터를 사용하지 않는 모델부터 구현해봤어야했다. -
이론적인 공부를 너무 소홀히 했다.
카카오에서 제공한 글 정도만 집중해서 보고 추천시스템 자체에 대한 공부가 적었다. 지금생각해보니 카카오에서 소개한 글에서 오토인코더를 사용한다고 설명해서 이를 그냥 무작정 구현해보려 한 것이었는데
Recommender System KR 커뮤니티를 알게 되었는데 여기서 이 대회와 RecSys 2018 대회가 유사하다는 것을 알게되었다. 이 대회의 우승작을 봤으면 정말 도움이 많이 되었을 것이라고 생각된다. -
딥러닝이면 다된다고 생각했다.
딥러닝에 뭐든 넣어보면 되지 않을까하는 생각으로 기본적으로 쌓아야 하는 지식을 재쳐두고 무조건 모델을 빨리 만들어서 돌려보자는 마음가짐으로 임했기 때문에 방향을 못잡고 헤맸던 것 같다. -
포럼에 있는 코드를 더 잘봤어야했다
포럼에 공유된 코드르 먼저 돌려보면서 대회의 분위기를 파악하고 다른 여러 시도들도 해봤어야 했다.
무엇이 성장되었나?
-
공유를 위해 주석을 다는 습관을 들일 수 있었다.
처음에는 팀원들끼리 각자 코드를 짠 다음에 공유가 잘 안된다거나 전에 일의 진행상황이 어떻게 되는지 정리가 잘 안되는 상황이 벌어졌었으나
이후에는 다른 팀원과 공유를 위해 주석을 다는 습관을 들일 수 있었다. -
또한 일의 진행상황을 계속 아이패드에 정리해놓고 팀원들에게 알려주는 습관을 들일 수 있었다. 정리의 중요성을 알았다고 해야할까.
-
앞으로 본 대회의 음원 데이터처럼 큰 데이터를 다룰 일이 생긴다면 좀 더 노련하게 대응할 수 있을 것 같다.
-
자료 서칭능력이 늘었다. 캐글 코리아, 텐서플로우 코리아, Recommender system KR 등 여러 커뮤니티와 다양한 키워드로 검색을 해서 자료를 잘 찾는 방법을 더욱 키웠다.
-
카카오 아레나에서 추천시스템 대회가 또 열리면 이번보다 잘할 자신이 생겼다.
우승팀은 어떻게 했나?
datartist
이 분은 진짜 대단한 것 같다. 저번에 세미나 때 추천받은 깃헙도 이 분꺼였다.
Task와 Data에 대한 정확한 이해 / 평가 Metric에 대한 정확한 이해 / 다양한 가설을 세우고 빠르게 검증 / 중간중간에 코드 점검 및 주석 달기 / Overfitting을 막기 위한 Validation set 생성 / 실시간 순위 확인 & 막판 스퍼트
hics
대회 포럼의 모델들 돌려보고 RecSys 우승작도 보고, 가설을 세우고 이를 반영해서 rescoring했다고 한다.
이후 행보는?
이렇게 또 후기글을 정리하다보니 승부욕이 불타오른다🔥🔥🔥
대회에서 상타고 싶다..!!!
RecSys논문 읽을 것이고, 전반적인 추천시스템 공부가 더 필요하다.
여기에 코드를 남겼다.
