[HTTP] Stateless & Connectionless
HTTP와 Stateless / Connectionless
HTTP는 Stateless하다 / Connectionless 하다는 말을 종종 듣게 됩니다.
실제로 HTTP는 Stateless 하지만, 완전히 Connectionless하지는 않습니다.
처음에는 Connectionless하게 설계되었지만 현재는 반대 개념인 Persistenet Connection에 가깝습니다.
두 특성은 모두 클라이언트 - 서버 간 이루어지는 요청-응답이 서로 독립적으로 이루어지도록 하기 위해 사용되는 특성으로, 무엇이 Stateless이고 Connectionless인지 자세히 알아보겠습니다.
Layer 4: Connectionless
Connectionless란
HTTP는 Layer 4에서 TCP 프로토콜을 사용해 데이터를 전송합니다.
이 때 서버와 클라이언트가 연결을 맺는 과정은 다음과 같습니다.
- 서버에서 특정 포트, 특정 클라이언트(ip)에 대해 연결 요청을 받을 수 있도록 설정합니다.(
listen()) - 클라이언트가 해당 포트로 연결 요쳥을 보냅니다(
conntect()). - 연결이 제대로 수립되었는지 확인하기 위해 클라이언트 -> 서버, 서버 -> 클라이언트, 클라이언트 -> 서버 순서로 연결 확인용 패킷을 총 세번 보내는 3-way handshake 과정을 거쳐 최종적으로 연결이 맺어지게 됩니다.
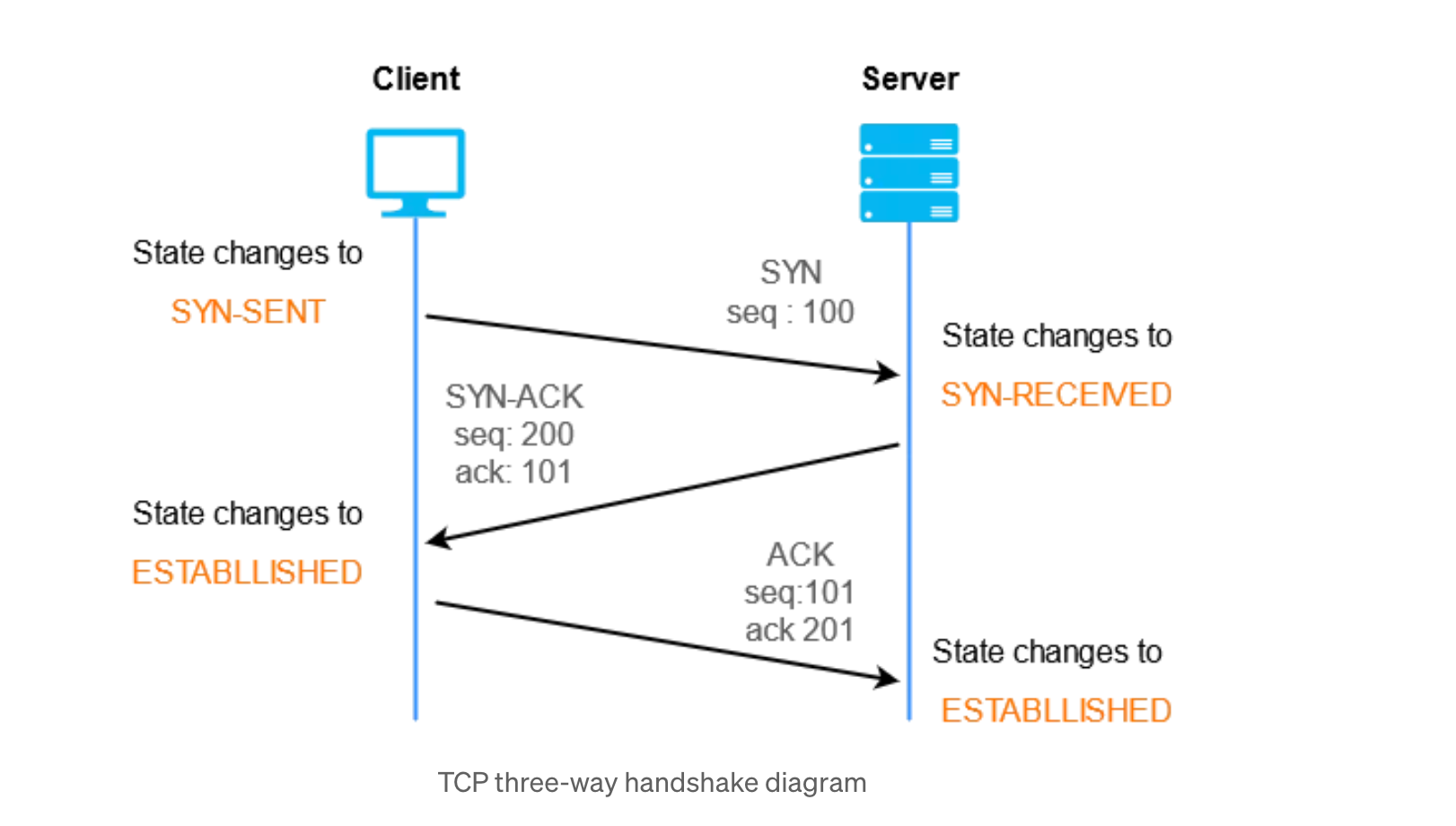
이후 보안 인증이 필요하다면 더 복잡한 TLS 핸드셰이크 과정을 거칩니다.
이렇게 연결이 맺어지고 나면 비로소 클라이언트에서 서버로 요청을 보낼 수 있게 됩니다.
Connectionless는 네트워크 계층에서 연결을 유지하지 않고, 각 패킷이 독립적으로 전송되는 것을 의미합니다.
TCP는 기본적으로 연결을 유지하는 프로토콜이며, HTTP는 TCP를 기반으로 하고 있으므로 엄밀히 말해 Connectionless가 아닙니다.
다만 HTTP 1.0에서는 매번 요청할 때마다 연결을 끊고 재연결하는 방식이 사용되었기 때문에 비슷한 동작을 했습니다.
HTTP가 Connectionless하다는 것은 이처럼 매 요청마다 연결을 끊었다가 재연결 하는 프로세스를 의미합니다.
이와 달리 연결을 유지하는, 즉 Persistent Conenction을 사용하는 프로토콜로는 FTP, Telnet 등이 있습니다.
이들은 한번 맺은 연결로 여러 번 요청 - 응답을 보내도록 설계되었습니다.
Connectionless의 단점
매 요청바다 연결을 끊었다가 재연결하도록 했기 때문에 각각의 요청-응답을 다른 요청-응답과 분리할 수 있었지만,
Connectionless한 HTTP 1.0에서는 매 요청마다 TCP의 3 Way Handshake 과정을 다시 거쳐야 했습니다. 이로 인해 요청 사이에 지연(latency) 이 생깁니다.
또 TLS 핸드셰이크 과정도 새로 거쳐야 합니다. TLS는 서버-클라이언트 간 보안 인증을 거치는 단계로, TCP 핸드셰이크보다 더 많은 단계를 거치며 암호화 관련된 연산 작업도 들어갑니다. 이로 이해 매 요청마다 CPU를 소모하게 됩니다.
이러한 문제로 인해 HTTP 1.0 시절 연결을 유지하도록 하는 Keep-alive 라는 비공식 확장이 사용되기 시작했습니다.
클라이언트와 서버가 모두 Persistent connection을 지원한다면 :
- 헤더에
Connection: keep-alive를 추가해 연결을 유지하고, - 이후
Connection: close로 바꾸어 연결을 끊을 수 있었습니다.
HTTP 1.1 부터는 Persistent connection이 디폴트 동작이 되었습니다. Connection: close를 추가하면 Connectionless하게 작동하도록 바꿀 수 있습니다.
따라서 현재의 HTTP는 Connectionless보다는 Persistent Connection에 가깝습니다.
하지만 이는 성능상의 문제이고, 요청-응답 쌍은 여전히 독립적으로 취급됩니다. HTTP의 또 다른 특성인 Stateless는 여전히 유효하기 때문입니다.
Layer 7: stateless
HTTP 프로토콜은 어플리케이션 레이어인 Layer 7에서 사용됩니다.
여기서의 Stateless는 애플리케이션 레벨에서 서버가 클라이언트의 상태 정보를 저장하지 않는다는 의미입니다.
또한 실제로 저장하지 않는다는 것이 아니라, 프로토콜이 그럴 것을 가정하고 설계되었음을 의미합니다.
FTP와 같은 Stateful한 프로토콜의 경우, 상태 유지가 프로토콜 명세의 일부입니다.
세션 상태, 현재 디렉토리, 전송 모드 등의 상태를 필수로 저장하도록 명세되어있고
프로토콜에서 사용되는 메서드 또한 이런 상태 정보를 가정하고 작성되어있습니다.
반면 HTTP는 서버가 클라이언트의 상태 정보를 저장하지 않는다고 가정하고 설계되어 있습니다.
Stateless한 프로토콜의 장점
그렇다면 HTTP는 왜 Stateless를 지향하는 걸까요?
1. 가시성
가시성이 향상됩니다. 모니터링 시스템이 요청의 전체 성격을 파악하기 위해 단일 요청 데이터 이상을 살펴볼 필요가 없기 때문입니다.
2. 신뢰성
신뢰성이 향상됩니다. 여러 요청에 걸쳐서 적용되는 상태가 없기 때문에 부분적인 실패로부터 복구 작업이 쉬워지기 때문입니다.
3. 확장성
확장성이 향상됩니다. 요청 간에 상태를 저장할 필요가 없어 서버가 빠르게 리소스를 해제할 수 있고, 요청 간 리소스 사용을 관리할 필요가 없어 구현이 더욱 단순해지기 때문입니다.
모든 방법이 그렇듯 단점도 있습니다.
1. 성능 저하
일련의 요청에서 반복적인 데이터를 증가시켜 네트워크 성능을 저하시킬 수 있습니다. 그 데이터를 서버에 남길 수 없기 때문입니다.
2. 클라이언트 의존성 증가
애플리케이션 상태를 클라이언트 측에 배치함으로써 서버의 일관된 애플리케이션 동작에 대한 제어가 줄어듭니다. 예를 들어 클라이언트가 올바로 구현되지 않으면 하나의 서버가 여러 버전의 클라이언트와 소통할 때 특정한 클라이언트에서만 오류가 발생할 수 있게 됩니다. 서버가 제대로 구현되어 있더라도 클라이언트에 따라 오류가 발생할 수 있어 서버의 제어권이 약해집니다.
애플리케이션 레벨에서 구현하는 stateful
그런데 실제로는 HTTP 프로토콜을 사용해 통신할 때 클라이언트의 상태를 저장하는 경우가 많습니다.
이는 프로토콜과 별개로 개발자가 애플리케이션 레벨에서 직접 구현하는 방식입니다.
예를 들어 Cookie 또는 세션을 사용한 인증 - 인가 프로세스가 있습니다.
Cookie는 HTTP의 헤더에 속해있기 때문에 HTTP가 상태 저장을 지원하는 것이라고 생각할 수 있지만 HTTP는 클라이언트에 데이터를 저장하는 메커니즘을 제공할 뿐, 프로토콜 레벨에서 이를 가정하고 동작하지 않기 때문에 여전히 Stateless 하다고 할 수 있습니다.
정리
HTTP는 각 요청-응답을 다른 요청-응답으로부터 독립적으로 취급하기 위해 Connectionless & Stateless를 추구했습니다.
성능상의 문제로 HTTP는 1.0 이후로 더 이상 Connectionless 하지 않지만 필요하다면 Connection: close 를 헤더에 추가해 Connectionless하게 동작하도록 할 수 있습니다.
이러한 차이는 성능상의 문제로 이로 인해 서로 다른 요청-응답이 영향을 미치지는 않습니다.
왜냐하면 HTTP는 클라이언트의 상태 정보를 서버에 저장하지 않는 것을 가정하고 설계된 Stateless한 프로토콜이기 때문입니다.
서버가 클라이언트의 정보를 저장하지 않기 때문에 이전의 요청-응답이 이후의 요청-응답에 영향을 미치도록 설계되지 않았습니다.
하지만 실제로는 개발자가 상태 저장 매커니즘을 직접 구현해 사용하는 경우가 많습니다.
이는 상태 관리를 프로토콜 레벨에서 하지 않고 프로그래머가 필요에 따라 직접 구현하도록 함으로써 단순성과 확장성을 가져가기 위한 설계라고 정리할 수 있을 것 같습니다.
