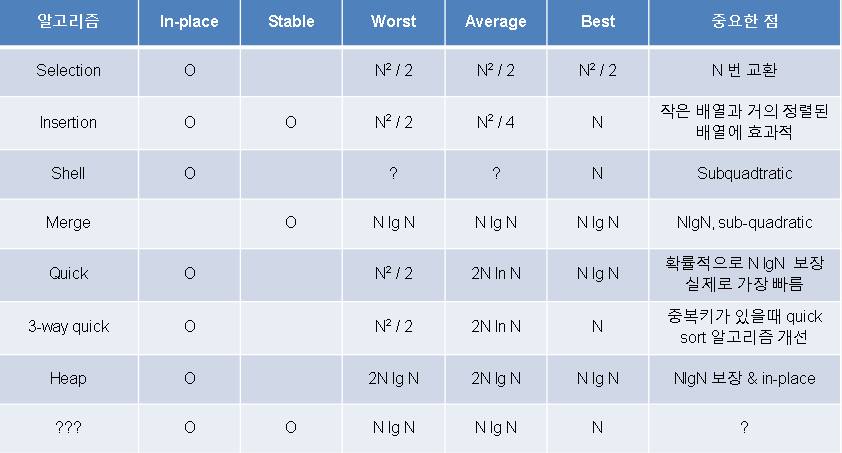
정렬알고리즘
- Stable 정렬: 중복된 키 값의 순서가 유지되는 것
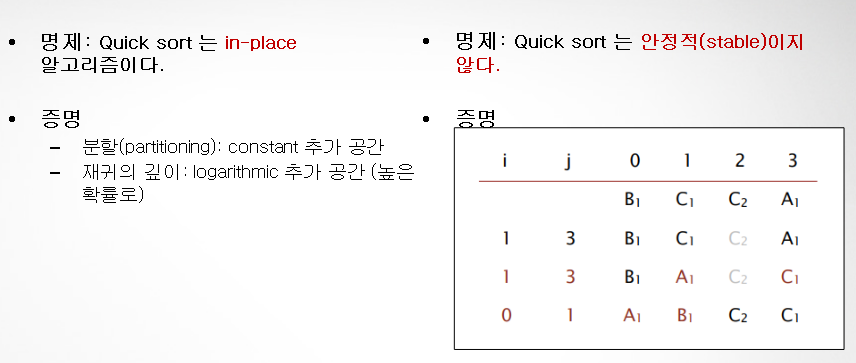
- In-Place: 추가로 사용하는 메모리가 n(원소)에 비해 少
- Amortized: 분할
- Implementation: 구현

- merge sort에 비해 quick sort는 중복된 keys의 영향을 많이 받음
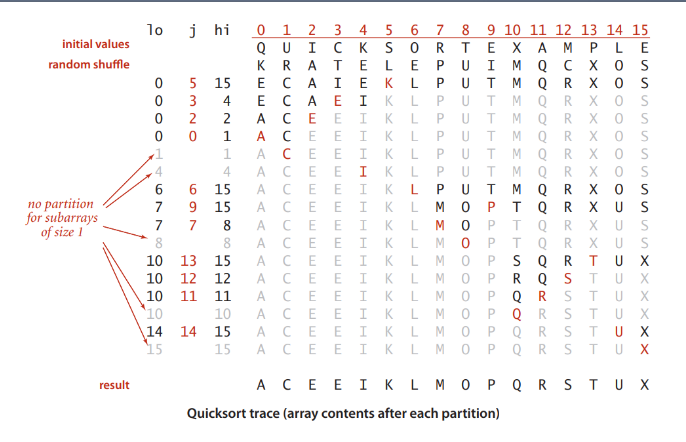
1. Quick-Sort
동작방식 (구름 코드구현 동시 확인)
출처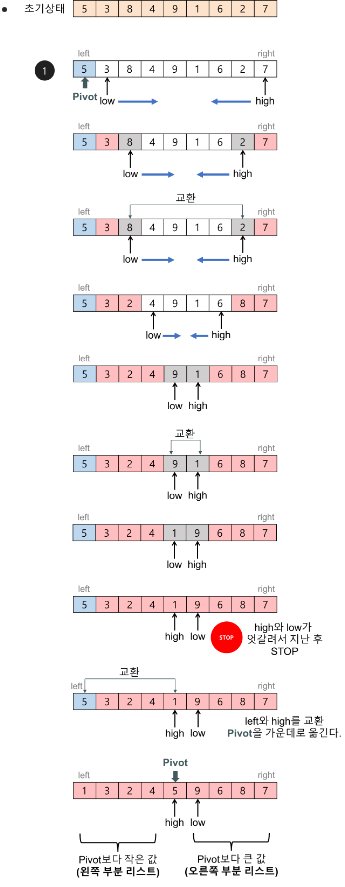
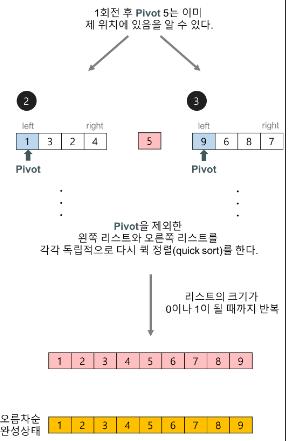
 ↳ 가지치기를 잘하자! 어디가 Pivot인지 파악(왼쪽 리스트 먼저!)
↳ 가지치기를 잘하자! 어디가 Pivot인지 파악(왼쪽 리스트 먼저!)
성능 = 비교횟수 (!= 교환횟수)
- 경험적으로, 삽입 & 병합 정렬보다 뛰어나다
- Worst case 매우 드뭄
- merge sort보다 빠름(비교는 더 많이 해도, 교환은 적음)
- 다음과 같은 경우 Quadratic
- 이미 정렬된 or 역정렬된
- 중복키 多 (밑에서 자세히! 3-way quick sort)
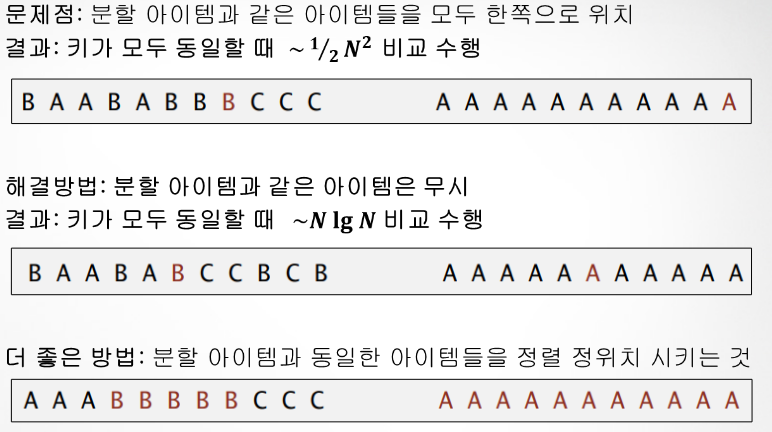
- 정렬의 목적은 동일한 키들을 묶는 것!
- n(key)는 작지만, 배열의 크기가 매우 큰 경우 활용
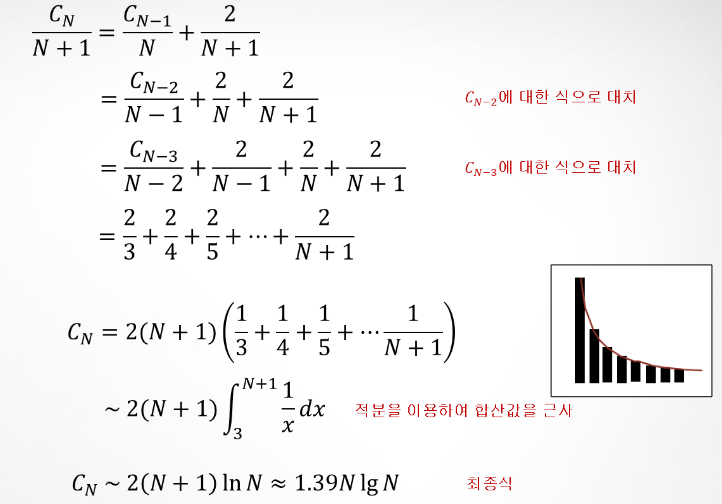
- 수학적 증명

개선방안: 응용(실용적 코드구현 동시 확인)
- 10개 이하의 아이템을 가진 작은 배열에 대해서는 insertion sort 사용
- Pivot = 중간값
↳ 샘플의 중간값을 통해 실제 중간 값을 추정
↳ 무작위로 선택한 3개의 아이템 중 중간값 선택
↳ ~ 12/7 N ln N compares (약간 줄어듦)
↳ ~ 12/35 N ln N exchanges (약간 늘어남)3. 중복키가 많을 때 ⇨ 3-way Partitioning (Demo check)
↳ 피벗값과 중복되는 값을 좌/우 영역에서 제외시킴으로서 시간복잡도를 개선
Dutch national flag 문제
- 관련 수학적 명제


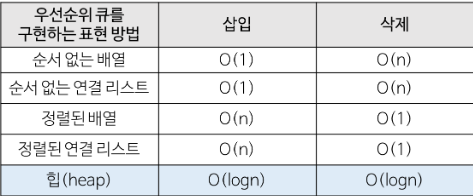
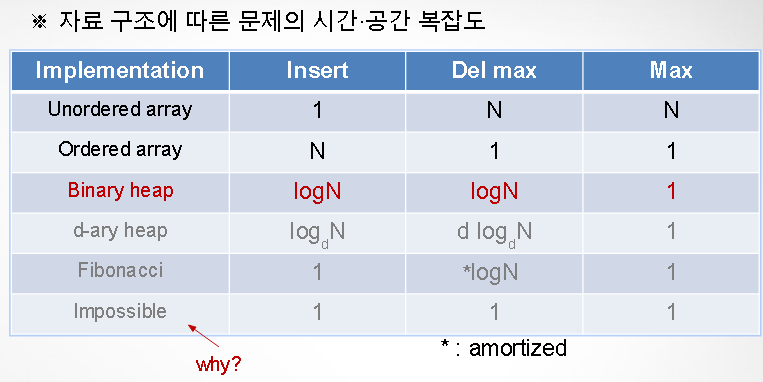
2. PRIORITY QUEUES 中 Binary Heap
Priority queue: 가장 큰(작은) 아이템을 삭제

Binary Heap 특성
- 이진트리 : n(자식노드) == 0 or 2
- 완전 이진트리 : 마지막 레벨 外 n(자식노드) == 2
↳ N개의 노드 ⇨ 높이 = log N
- 중복 키 허용
- 최대, 최소 빠르게 찾을 수 있게끔!
1. 최대 힙(max heap)
key(부모 노드) >= key(자식 노드)
2. 최소 힙(min heap)
key(부모 노드) <= key(자식 노드)
**자식노드간의 비교는 X- 키의 불변성
- Underflow: 비어있는 PQ에 대해 delete 연산 요청 시 예외 처리
- Overflow: 사이즈를 미리 지정하지 않도록 생성자 정의 (resizing array 이용)
- 매 연산 당
log N amortized time 소요

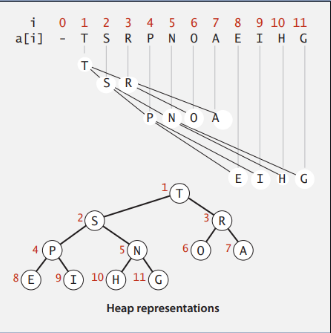
Binary Heap 배열 표현 (구름 코드 & Demo)
구름에서는 Max heap(루트노드가 가장 큼)! Min heap 도 구현해보기!
힙 정렬된 완전 이진트리
- 인덱스 1부터
- 인덱스로 트리 탐색
- 루트값 a[1]이 가장 큼
- 111이 불가능한 이유?
- 링크 정보 불필요 (1부터 연결됨)
- 응용: Heap sort with In-place (Demo 확인)
- 무작위 완전 이진트리
- bottom - up, index가 큰 값(밑)부터 sink
↳ Max Heap 생성- 배열을 내림차순으로 정렬
↳ del_max & Heap화 (sink)
- 수학적 접근


Event Driven 시뮬레이션 방식
(구름: Ball & Collision System)
N 개의 움직이는 입자의 행동을 탄성충돌법칙에 따라 시뮬레이션

Symbol Table 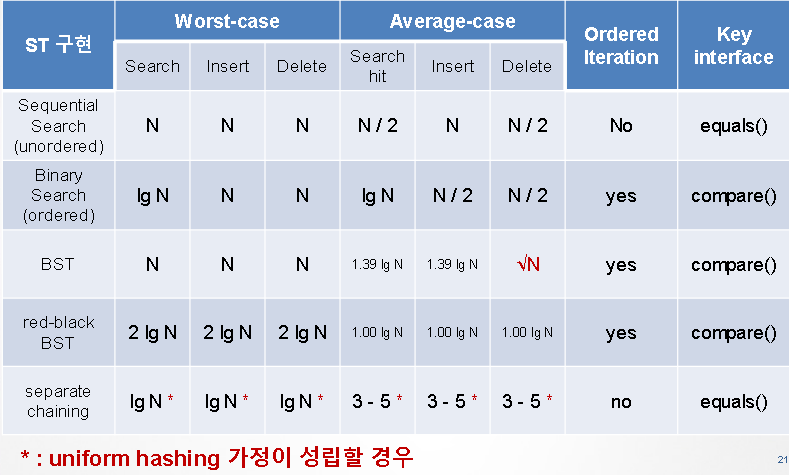
- Key, Value : generic type
↳ 데이터 타입을 컴파일 시에 미리 지정
↳ 키끼리 comparable, Immutable as possible- BST에서 히바드 삭제 시 높이가 log N에서 루트 N으로 증가
↳ 삽입, 탐색(평균)도 루트 N으로 증가!- LLRB가 tree 밸런스가 좋으므로 BST에 비해 빠름
- 해시 테이블 → 상수 check
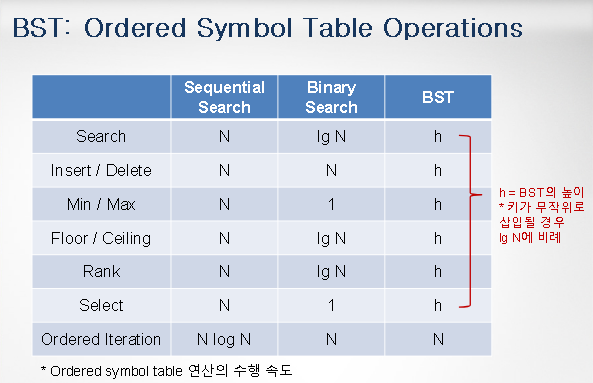
Binary Search Tree
binary search table 기본개념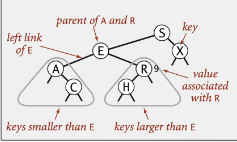
대칭 정렬 + 이진트리 (최대 2개 서브트리)
- BST & QuickSort → 배열에 중복되는 값이 없는 경우 1:1 대응 관계
↳ BST에 N개 키 무작위 추가 → 삽입, 탐색위한 비교횟수 ~2 ln N
↳ 트리의 평균 높이는 ~ 4.311 ln N↳ 올림-내림, 상한-하한에 활용
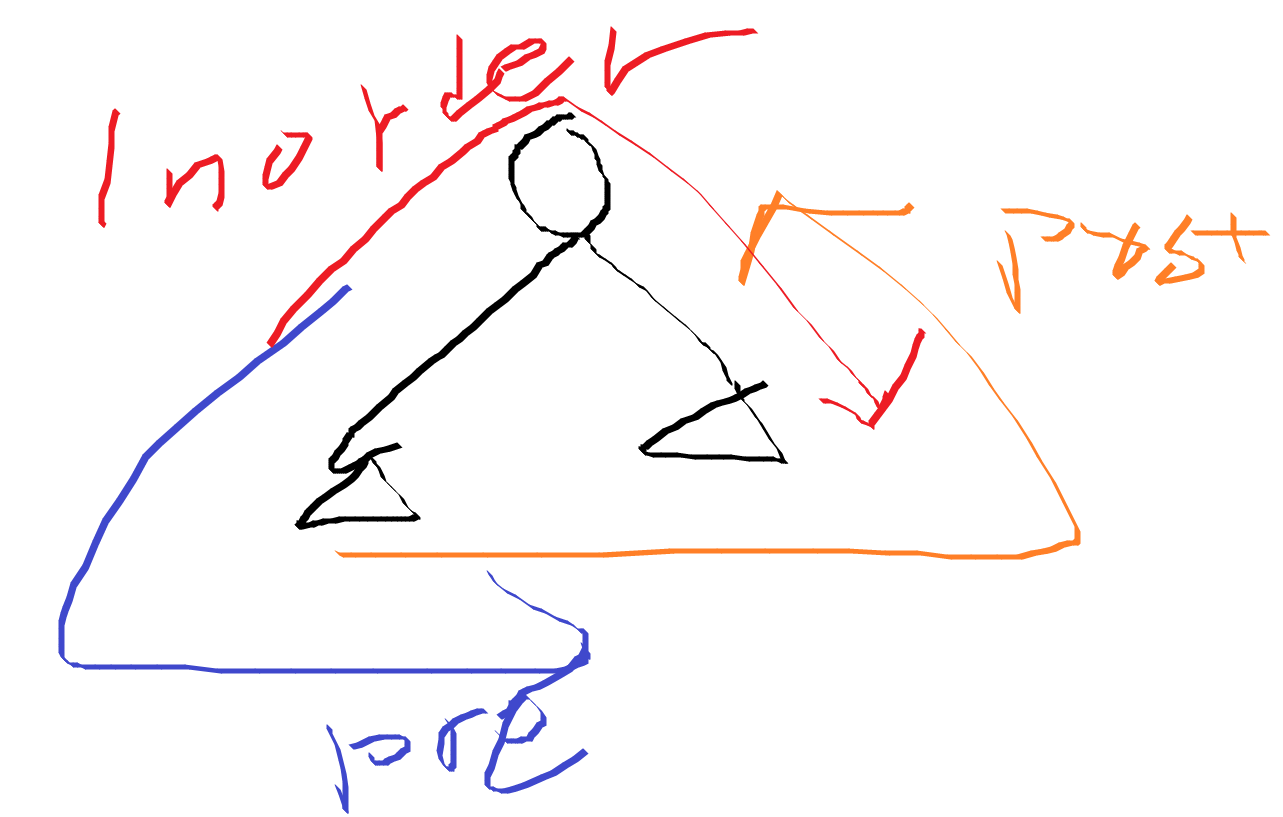
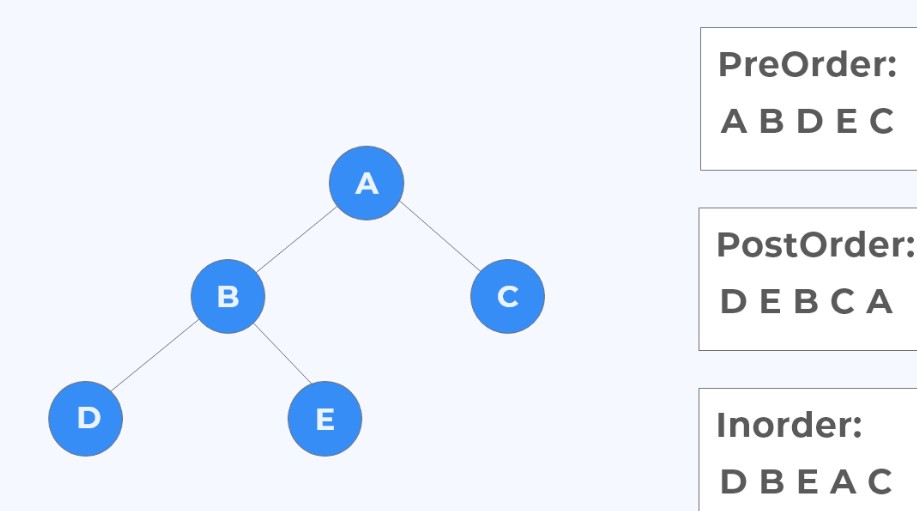
참고: inorder, preorder, postorder
BST의 삭제 알고리즘(min_del & Hibbard) → 구름실습
최소값 삭제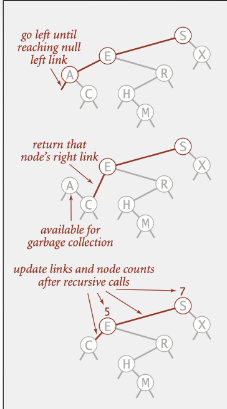
HIBBARD 삭제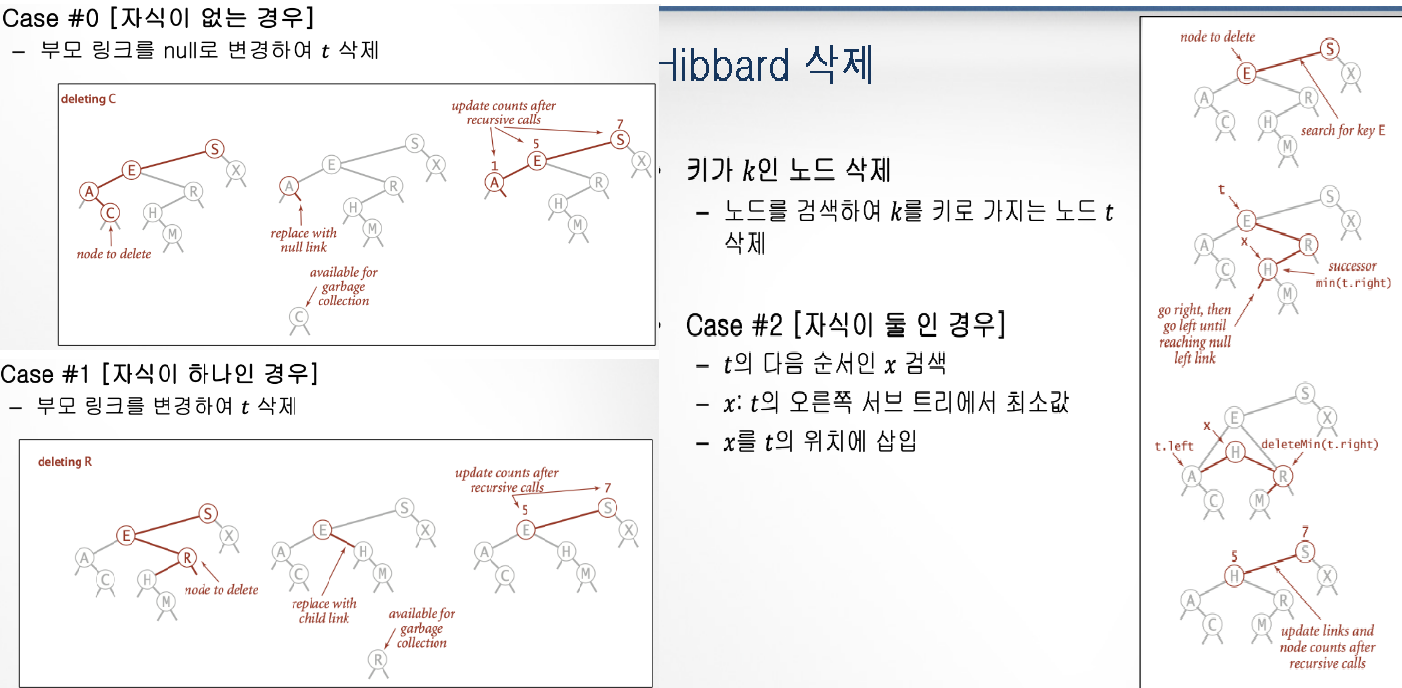
Balanced Search Tree_2-3 & RB BST
1. 2-3 Tree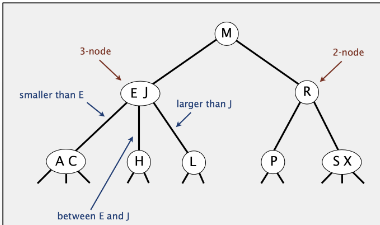
- 이진트리(대칭정렬, 이진) + PERFECT BALANCE(H=)
- 4 NODE 발생 시 → 매우 작은 수의 링크만 조정 → 효율성
- PB → ROOT ~ NULL 경로 ALL 同 → 삽입, 탐색의 LOG 보장!
2. red-black BSTs
- 2-3 tree를 BST로 표현 → 3-NODE 허용 X
↳ 내부링크(빨간색)을 통하여 3-NODE 표현- 2-3 와 LLRB(LEFT LEANING RED BLACK) BSK → 1:1 대응
- 대전제 : LEFT LEANING RED LINK + NO 2개 연속 RED
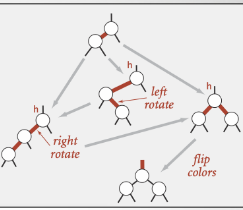
알고리즘_구름 실습
1. LEFT, RIGHT 로테이션, Flip 알고리즘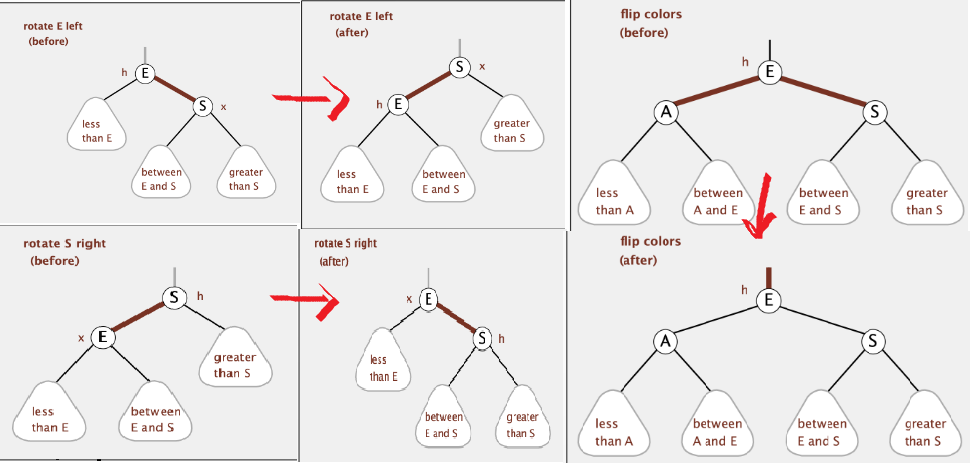
2. 삽입, 탐색 알고리즘
1. 대전제 : LEFT LEANING RED LINK + NO 2개 연속 RED
2. LEFT, RIGHT 로테이션, Flip 알고리즘
성능분석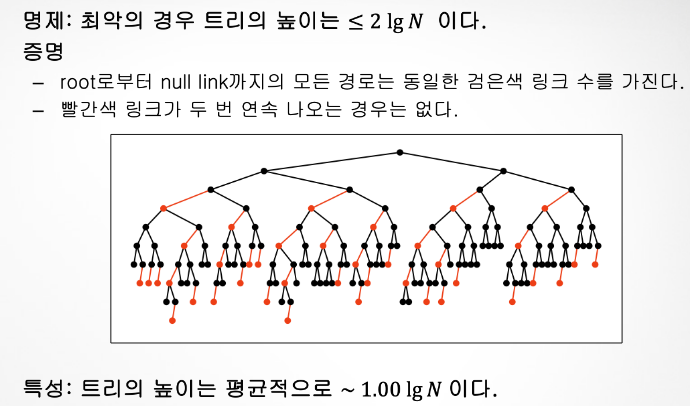
응용: RB BST 효과적 구현
Hash Table
해시테이블의 Uniform Hashing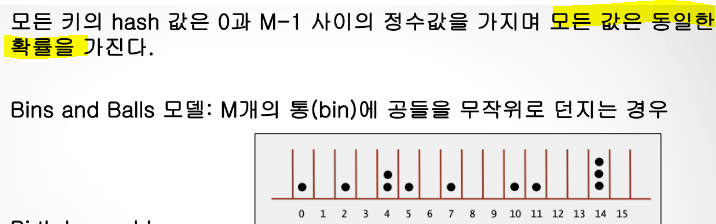

1. separate chaining 동작방식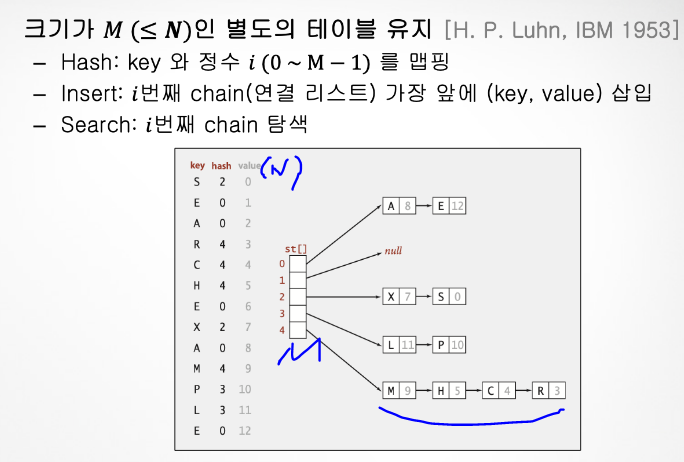
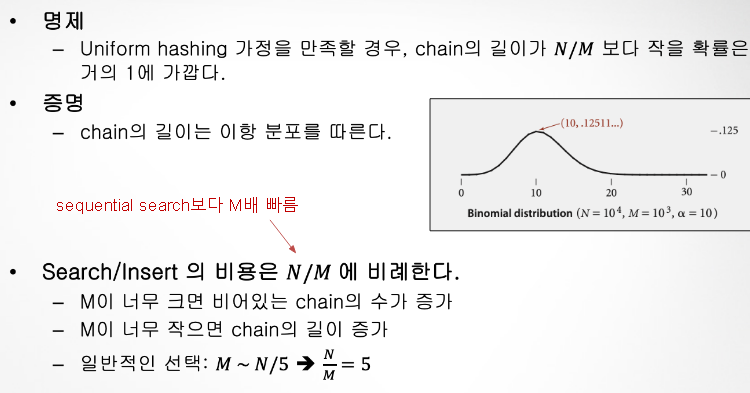
2. linear probing 동작방식
새로운 key가 충돌하는 경우, 다음 비어있는 슬롯을 찾아서 index 할당
↳ similar with 집합연관정도
1. HASH값으로 INDEX 접근
2. VALID = 1 ⇨ 오른쪽 비어있는 공간으로 MISS(마지막 인덱스이면 처음으로!)
- 배열 크기 M은 key-value 개수 N보다 커야함

c0d3_wh1t3