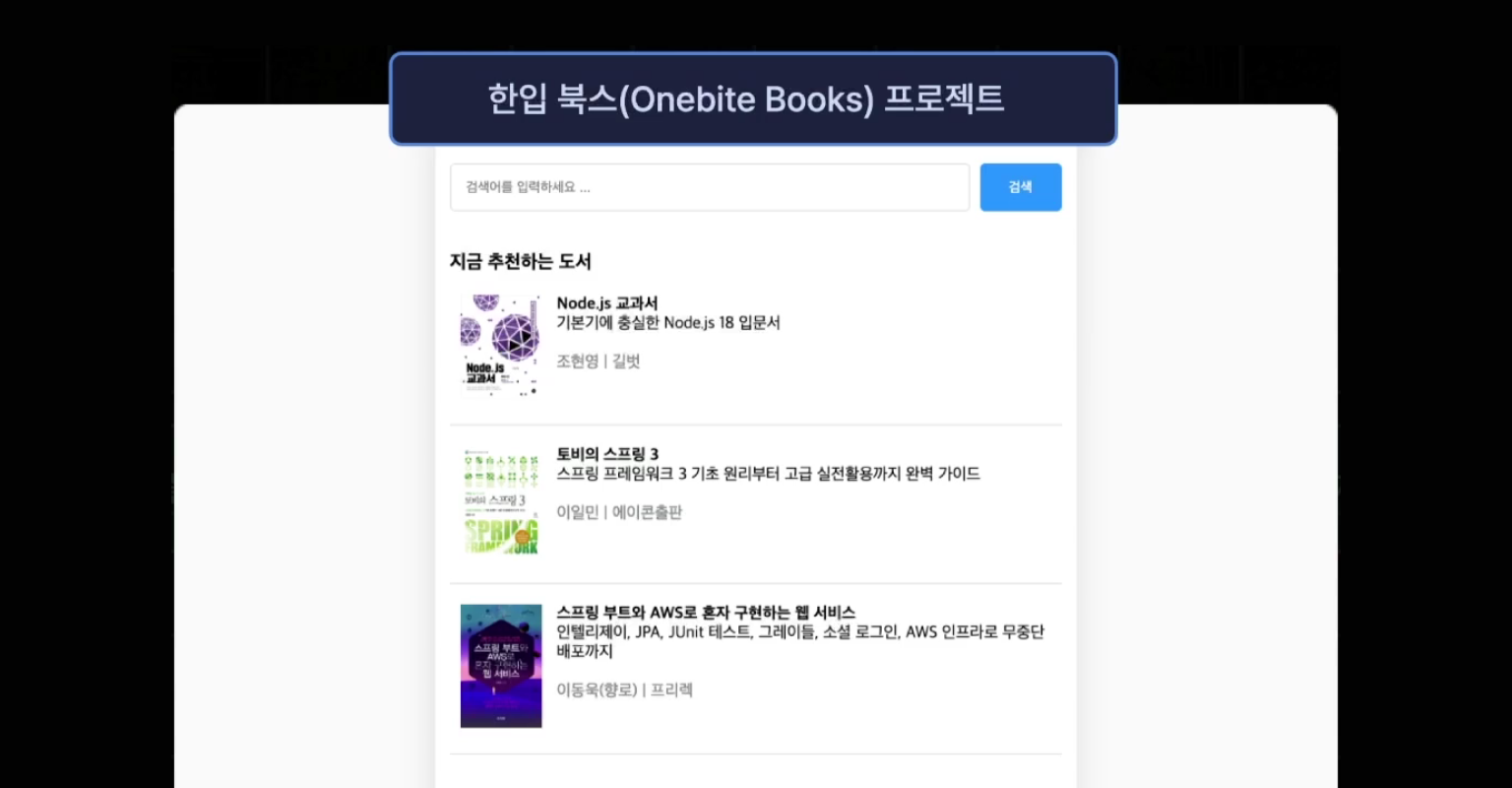
1. 실습 프로젝트 구성
1) Index
- 인덱스 페이지(
/) - 등록되어 있는 모든 도서의 리스트를 볼 수 있다.
2) Search
- 검색 페이지(
/search) - 제목, 저자별로 검색 결과를 볼 수 있다.
3) Book
- 상세 페이지(
/book/{book_id}) - 특정 도서의 상세 정보를 확인할 수 있다.
2. 불필요한 코드 제거
- 홈 컴포넌트의 import문 전부 삭제
- 홈 컴포넌트의 return문 내부 전부 삭제
- globals.css 코드 전부 삭제
- home.module.css는 현재 실습에 필요하지 않으므로 제거
index.tsx의 기본 HTML 코드 중에 폰트 클래스를 적용해 둔 부분이 낯설었습니다.
왜 이런 형태인지는 나중에 알아보도록 하겠습니다.
const geistSans = localFont({
src: "./fonts/GeistVF.woff",
variable: "--font-geist-sans",
weight: "100 900",
});
const geistMono = localFont({
src: "./fonts/GeistMonoVF.woff",
variable: "--font-geist-mono",
weight: "100 900",
});<div className={`${styles.page} ${geistSans.variable} ${geistMono.variable></div>3. search 페이지 생성
1) 정적 경로 페이지 생성
- search.tsx를 만들어도 되고, pages/search/index.tsx를 만들어도 됩니다.
/search라는 요청이 들어왔을 때 pages에 search 파일이 없다면 동일한 이름의 폴더를 찾아가서 index 파일을 렌더링하기 때문입니다.- 또한
/search/setting이라는 경로를 만들고 싶다면 search 파일에 index 파일 외에 setting 파일을 생성하면 됩니다. - 이 setting도 하위 폴더로 동일하게 생성하는 것이 가능합니다.
- 이렇듯 Next.js에서는 중첩 경로 라우팅이 매우 편리하게 이루어집니다.
- 이제 검색어(쿼리 스트링)를 사용하는 방법을 알아봅니다:
2) useRouter: 쿼리 스트링 사용
localhost:3000/search?q=next- 쿼리 스트링을 사용하는 컴포넌트라고 해서 폴더 구조를 바꾸어야 하는 것은 아닙니다.
- 쿼리 스트링이 컴포넌트 구조에 영향을 주지는 않기 때문입니다.
- 다만 이 쿼리 스트링을 해당 컴포넌트에서 읽어오기 위해서는
useRouter라는 훅을 사용해야 합니다. - 이때
useRouter를next/navigation에서 가져오지 않도록 주의합니다. - 이는 App Router에서 사용되는 도구이기 때문에 버전이 부적절합니다.
- 지금은 Page Router에서 사용하므로
next/router에서 가져오도록 합니다. useRouter는 라우터 객체를 반환하는 함수입니다.
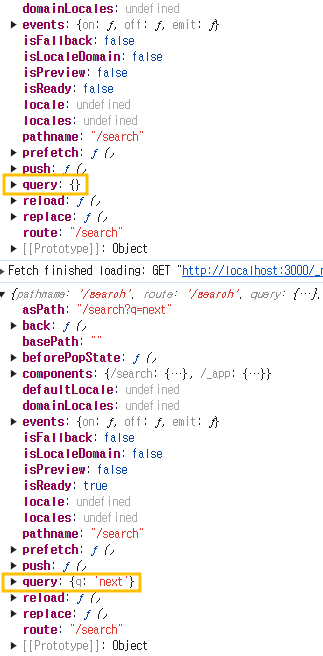
3) 라우터 객체 확인
localhost:3000/search?q=nextconst router = useRouter();
console.log(router);- 임의의 쿼리스트링(
next)을 추가한 후 콘솔로 라우터를 출력해보았습니다. - 이상하게도 라우터 객체가 두 번 출력된 것을 확인할 수 있습니다.
- 넥스트가 쿼리 스트링을 인식하는 과정 중에 컴포넌트를 한번 더 렌더링하기 때문입니다.
- 따라서 첫 번째 출력에서는 쿼리 스트링을 인식하지 못했다가 두 번째에 인식합니다.
4. book 페이지 생성
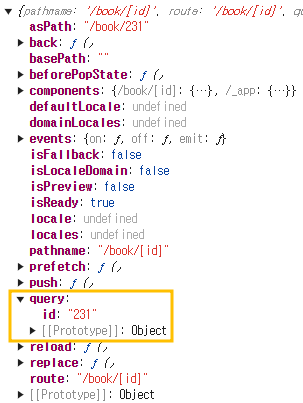
1) [id]: 동적 경로 페이지 생성
http://localhost:3000/book/231- /book/1, /book/2, /book/100, ...
- 이 페이지에서는 도서의 아이디, 즉 URL Parameter를 사용합니다.
- 이러한 동적 경로가 요구되는 페이지를 생성하기 위해서는 pages/book/[id].tsx를 생성하면 됩니다.
- 위 페이지에 접속한 후 콘솔로 라우터 객체를 확인해봅니다.
- URL Parameter 또한 쿼리 스트링처럼
query키에 값이 저장되어 있습니다. [id].tsx, 즉 파라미터 키를id로 지정했기 때문에id: 231이라고 출력됩니다.
2) [...id]: Catch All Segment
그런데 만약 URL 파라미터가 두 개 이상이라면 어떨까요?
http://localhost:3000/book/231/1255/166/72- 이런 경우에는 404 에러 페이지를 만나게 됩니다.
- 이렇게 복수의 파라미터에 모두 대응 가능한 페이지를 만드는 방법이 있습니다.
- 그것은 book/[id].tsx가 아니라 book/[...id].tsx 파일을 생성하는 것입니다.
...는 모든 경로를 잡아채겠다는 의미에서 Catch All Segment라고 칭합니다.- 참고로 segment는 '구간'을 의미합니다.
- 이제는 아무리 많은 아이디를 전달하더라도 페이지가 정상적으로 렌더링됩니다.
- 이때는 id를 출력해보면 라우터 객체에 아이디들이 배열로 저장됩니다.
3) [[...id]]: Optioanl Catch All Segment
http://localhost:3000/book- Catch All Segment로 대응할 수 없는 경우가 있습니다.
- 위 경로처럼 book 뒤에 아무런 파라미터가 없는 경우입니다.
- 이럴 때에는 book 폴더 내에 index.tsx를 생성해야 한다고 생각될 것입니다.
- 하지만 더 나아가 [...id].tsx를 더욱 범용적으로 바꿀 수 있는 방법이 있습니다.
- book/[[...id]].tsx를 생성하면 파라미터가 없는 경우와 여러 개의 파라미터가 들어가는 경우 등 모든 상황에 대응할 수 있습니다.
[[...]]는 Optional Catch All Segment라고 칭합니다.
5. 404 페이지 생성
export default function Page() {
return <>
<p>존재하지 않는 페이지입니다.</p>
</>
}- pages/404.tsx를 생성합니다.
- 존재하지 않는 페이지를 요청한 경우 자동적으로 렌더링됩니다.

Junior Frontend Developer