requests, BeautifulSoup로 crawling 하기
import requests #1
from bs4 import BeautifulSoup #2#1 requests : 웹 페이지를 가져오는 라이브러리
#2 BeautifulSoup : 웹 페이지를 추출할 수 있도록 분석하는 라이브러리
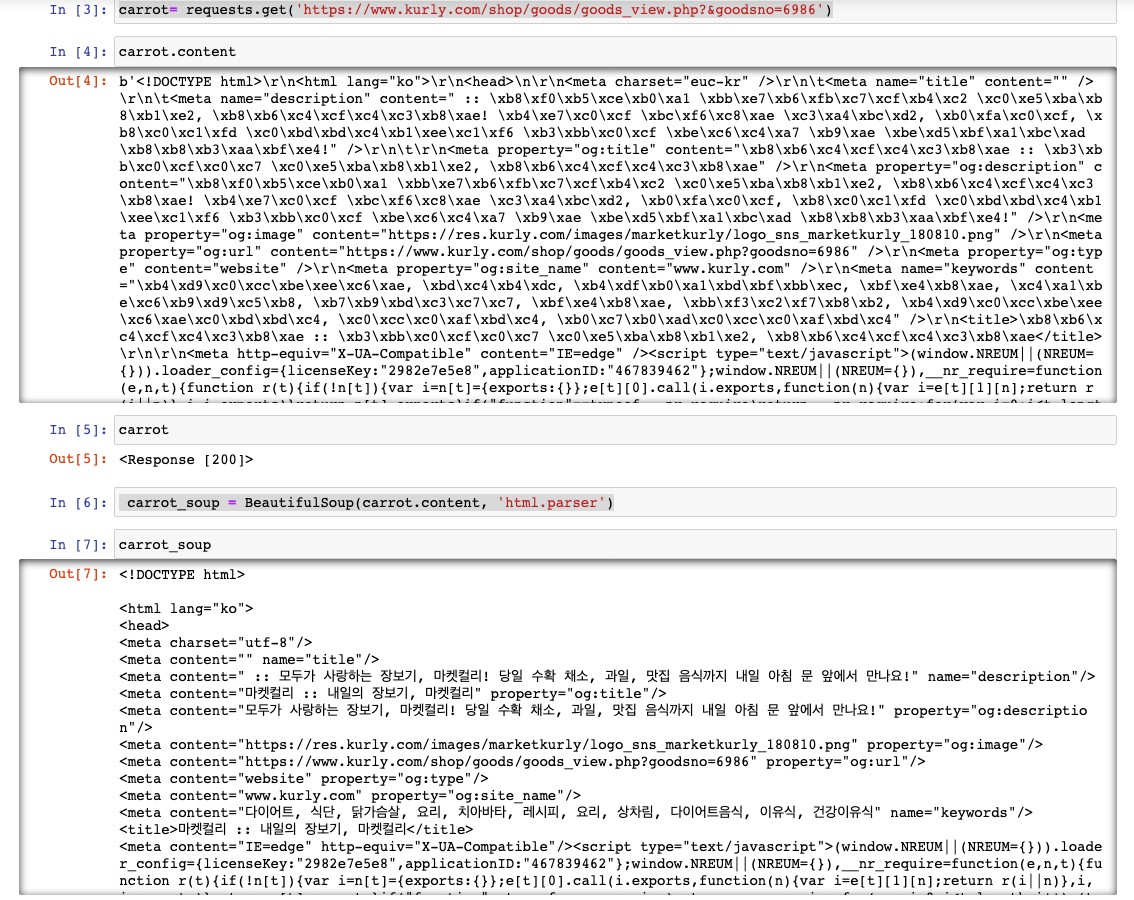
carrot= requests.get('https://www.kurly.com/shop/goods/goods_view.php?&goodsno=6986') #3
carrot.content #4#3 get이라는 method를 사용해 다음 주소를 통해 서버에 접속해 html 파일을 받을 수 있고, 그 파일은 carrot이라는 객체에 담긴다.
#4 carrot에 담긴 html 코드를 볼 수 있다. 그냥 carrot이라고 입력하면? 200 이 출력되는데, 해당 사이트에서 파일을 성공적으로 가져왔다는 의미다. (주피터 노트북에서는 변수명만 써도 값이 출력된다.)
In [4]: carrot
Out[4]:<Response [200]> carrot_soup = BeautifulSoup(carrot.content, 'html.parser') #5
carrot_soup #6#5 BeautifulSoup은 html 파일을 파싱(파일을 분석하는 것)해주는 라이브러리다.
형식 : BeautifulSoup(분석할 html 파일 내용, html을 분석해주는 프로그램(parser))
분석한 것을 carrot_soup 객체 안에 넣었다.
#6 파싱한 html 파일
mydata = carrot_soup.find('title') #7
data = carrot_soup.find('strong', class_='name') #8
data = carrot_soup.find('span', attrs={'class':'dc_price'}) #9
data = carrot_soup.find('span', 'dc_price') #10#7~#9 html태그 이용해 원하는 정보를 추출하는 방법.
#7 태그명으로 찾기
#8 태그명과 태그의 요소로 찾는 방법. 파이썬에서 class는 예약어이기 때문에 class_로 작성해야 한다.
#9 여러개의 요소를 이용해 찾고 싶을때는 json형식으로 객체에 담아 작성해야 한다.
#10 클래스의 경우에는 굳이 클래스를 명시하지 않고 두 번째 인자로 담을 수 있다.

You're not a computer, you're a tiny stone in a beautiful mosaic