회원 정보가 담긴 테이블에서 서울에 거주하는 20대 회원들의 정보를 검색하는 상황을 가정해보자. 데이터베이스는 유저 테이블의 1번 로우부터 전체 데이터를 확인해(full scan) 조건에 알맞은 데이터를 식별한 후 결과를 보여줄 것이다. 당연히 이 연산은 회원수가 증가할 수록 부담스러운 연산이 될 것이고, 전체 서비스의 성능에도 영향을 미칠 것이다. 이러한 상황의 개선책으로 검색 연산의 속도를 단축하기 위해 사용하는 자료구조 혹은 기능이 인덱스다.인덱스의 특징을 파악해 적절히 활용하면 검색 연산의 성능을 향상시킬 수 있다. 이 글에서는 인덱스의 자료구조를 통해 작동 원리를 설명하고 인덱스를 효율적으로 사용하는 방법을 소개한다.
인덱스 소개
인덱스란 데이터베이스의 읽기 작업을 향상하기 위한 자료구조다. 책에 있는 색인이 특정 키워드가 어느 페이지에 위치하는지 알려주는 것 처럼 인덱스를 이용하면 특정 데이터가 테이블 중 어디에 위치하는지 빠르게 찾을 수 있다.

User 테이블에서 name과 age 컬럼을 기준으로 인덱싱을 했다.
SELECT * FROM user
WHERE name > '박' and
age > 20 and
address = 'Busan';이 SQL문의 작동 순서
1. 첫번째 인덱싱 기준인 name으로 기준에 맞는 데이터를 선별한다. (13 -> 10개의 row)
2. 두번째 인덱싱 기준인 age로 1번에서 선별된 데이터를 대상으로 한번 더 필터링을 한다. (10 -> 4개의 row)
3. address는 인덱싱 기준이 아니므로, 포인터를 통해 테이블에서 직접 레코드를 읽어야 한다.(4 -> 2개의 row)
인덱스를 활용하려면 어떻게 테이블을 사용할 계획인지를 먼저 파악하고 인덱스를 설정하는 것이 좋다. 만약 age와 address를 기준으로 검색한다면, 인덱싱을 활용하지 못하고 full scan을 하게된다. 인덱스는 name을 기준으로 먼저 정렬이 되어있고, 그 다음에 age로 정렬되어 있기 때문이다. 인덱스 설정에는 컬럼의 순서를 어떻게 정하느냐도 중요하다.
인덱스는 쓰기 연산에서 성능을 향상시키지만, 이외 쓰기 연산(update, delete, insert)에서는 성능 저하가 일어나기 쉽다.
- Insert: 레코드의 생성으로 인덱스가 재정렬된다.
- Update: 업데이트는 일단 데이터를 검색한 뒤 값의 변경이 일어나기 때문에 검색에서는 인덱싱의 덕을 볼 수 있지만, 데이터를 업데이트하면 Insert와 마찬가지로 인덱스가 재정렬되어야 한다.
- Delete: Delete연산으로 테이블에서는 레코드가 즉시 삭제되지만 인덱스에서는 삭제되었음을 알지만 인덱스 상에서 제거되지는 않아 메모리가 낭비된다.
인덱스의 자료구조
DBMS마다 다양한 인덱스 자료구조를 제공하고 심지어 사용자가 커스터마이징 할 수도 있다. 그 중에서 OracleDB, MySQL, Postgresql등 많은 DBMS에서 공통적으로 제공하는 B Tree 인덱스를 소개한다.
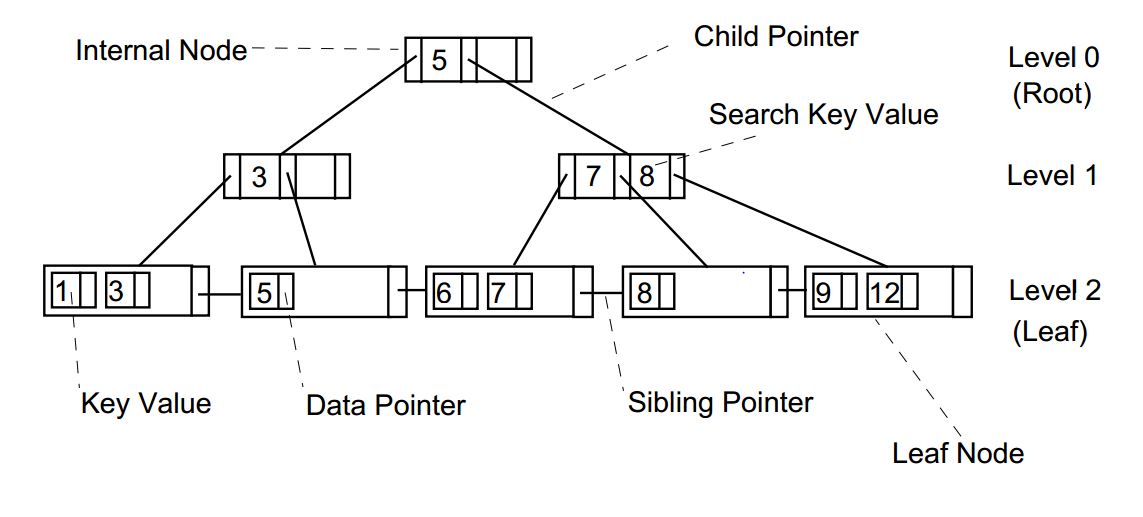
B tree는 리프노드와 비리프노드(Non-leaf)로 구성되는데, 리프 노드부터 루트 노드 까지의 길이는 모든 리프가 동일하다는 특징을 가지고 있다. 즉, 모든 리프 노드의 레벨은 동일하다. 검색 대상과 관계없이 검색 연산을 할 때 시간복잡도는 O(logN)으로 Full scan을 하는 경우의 시간복잡도 O(n)보다 훨씬 효율적이다. 또한 리프 노드 간에는 링크드 리스트로 연결되어 있어 여러 값을 스캔할 때 유리하다.
효율적인 인덱싱 방법
테이블
- 테이블은 읽기 연산이 많은 테이블에 적합하다. UPDATE, INSERT, DELETE 쿼리는 인덱스를 재배치하기 때문에 오버헤드가 발생한다. 쓰기 연산이 적고 읽기 연산이 많은 테이블일수록 효율적이다.
- 데이터가 충분히 많지 않다면 인덱싱을 활용하는 것이 오버헤드가 될 수 있다. 옵티마이저가 비효율적이라고 판단해 인덱스를 자체적으로 활용하지 않기도 한다.
컬럼
- 인덱스를 설정하지 않은 컬럼을 기준으로 하는 검색 쿼리는 인덱스를 사용하지 않는 것과 같다.
- 멀티 인덱싱을 사용할 경우 기준 컬럼의 순서를 정하는 것에 신중해야 한다. (name, age) 순으로 인덱싱을 했을 경우 age만으로 검색 쿼리를 날리면 역시 인덱스를 사용하지 않는 것과 같다.
- 카디널리티(Cardinality)가 높은 컬럼일수록 인덱싱에 적합하다. 카디널리티는 높다는 것은 중복되는 데이터의 수가 낮다는 뜻이다. Boolean은 값이 TRUE, FALSE 2개 뿐이라 카디널리티가 낮다고 할 수 있다. 데이터 타입이 Boolean인 컬럼을 기준으로 인덱싱을 한다면 모든 값이 TRUE OR FALSE라 인덱싱의 효율이 떨어진다. 이름, 아이디, 주소같은 데이터가 높은 카디널리티를 갖는다.
- 선택도(Selectivity)가 낮은 컬럼일수록 인덱싱에 적합하다. 선택도가 높다는 것은 해당 데이터가 전체 테이블에서 얼마나 희소한지를 의미한다. 수치화 하면 (같은 값을 가진 데이터) / (전체 데이터) 로 표현한다. 여러개의 컬럼을 조합하면 선택도를 낮출 수 있다.
- 따라서 컬럼을 설정할 때 어떻게 사용할지 먼저 생각한 뒤 컬럼과 인덱싱 순서를 설정해야 한다.
기타
- 인덱스의 크기가 지나치게 커지지 않도록 유의해야 한다. 이 또한 메모리자원을 소모하기 때문이다.
