파이썬으로 공립도서관 신착도서 목록을 크롤링했다.
requests와 BeautifulSoup를 이용했고 repl에서 코딩했다
#requests
requests는 HTTP로 간단하게 요청을 보낼 수 있도록 도와주는 라이브러리다.
import requestsresult = requests.get(URL)
print(result.status_code)status_code를 통해 요청이 제대로 수행되었는지 알 수 있다. 200이 출력되면 제대로 된 것이고, 404나 5로 시작되는 3자리 숫자가 출력되면 bad request라는 의미다.
#BeautifulSoup
HTML과 XML파일에서 데이터를 가져올 수 있는 파이썬 스크린 스크래핑 라이브러리다.
가져온 데이터에서 find로 태그나 속성값을 입력해 원하는 결과를 출력할 수 있다.
from bs4 import BeautifulSoupsoup = BeautifulSoup(result.text, 'html.parser')print해보면 해당 페이지의 모든 데이터를 가져왔다는 것을 알 수 있다.
paging = soup.find("div", {"id": "board_paging"})
links = paging.find_all('a')find를 쓰면 해당 조건을 만족하는 가장 상위에 등장하는 태그를 출력하고, find_all은 조건을 만족하는 모든 태그를 출력한다.
vctrl = html.find('a')['vctrl']a태그에서 vctrl이라는 속성의 값을 출력한다.
#repl
https://repl.it/
코딩하는데 사용한 사이트다. requests와 BeautifulSoup 모두 packages에서 간단한 과정을 통해 설치해 사용할 수 있다는게 큰 장점이다. 편리하고 가볍고 어느 환경에서나 이용할 수 있다.
#csv
comma-separated values의 약자로 이름에서 알 수 있듯 쉼표로 구분한 데이터 형태다.
import csv
file = open("newbook.csv", mode="w")open함수를 통해 newbook이라는 csv파일을 연다. 해당 파일이 없다면 자동으로 생성된다. mode가 w라는건 쓰기모드 라는 의미다. 추출한 데이터를 보기좋게 정리된 데이터로 추출하는것이 목적이기 때문에 쓰기모드로 한다.
def save_to_file(books):
file = open("newbook.csv", mode="w")
writer = csv.writer(file)
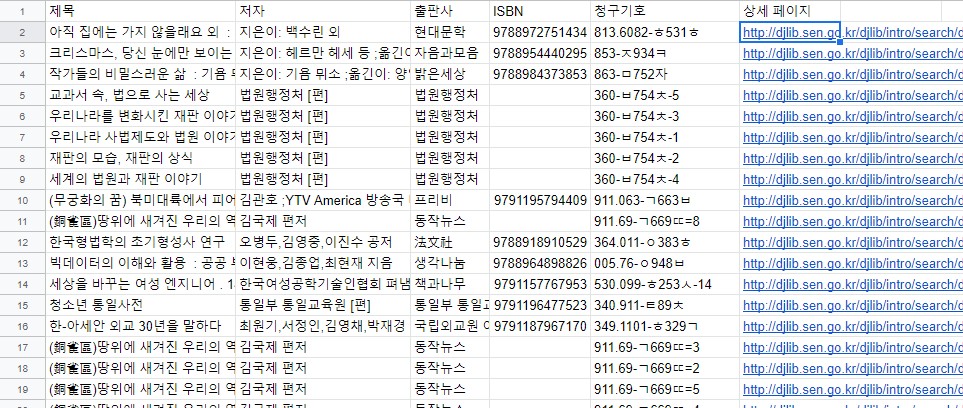
writer.writerow(['제목', '저자', '출판사', 'ISBN', '청구기호', '상세 페이지'])
for book in books:
writer.writerow(list(book.values()))
returnwriterow로 한 줄씩 추가할 수 있다. books는 딕셔너리 형태로 되어있어서, value값만 가져와 list형태로 만들어 한 줄씩 추가한다.
결과