PL/SQL 프로그래밍
- PL/SQL 프로시저 형식
DECLARE
변수이름1 데이터형식;
변수이름2 데이터형식;
BEGIN
/* 이 부분에 프로그래밍 */
END;1. IF...ELSE...
- 조건에 따라 분기한다, 한 문장 이상의 처리되어야 할 때는 BEGIN...END와 함께 묶어줘야만 하며
- 습관적으로 실행할 문장이 한 문장이라도 BEGIN... END로 묶어주는것이 좋음
1. 형식
IF <부울 표현식> THEN
사용할 명령들1...
ELSE
사용할 명령들2...
END IF
2. 활용
-- 화면 출력을 허용함(접속을 끊기 전에는 1회만 수행하면 됨
SET SERVEROUTPUT ON;
DECLARE
var1 NUMBER(5); -- 변수 선언
BEGIN
var1 := 101; -- 변수에 값 대입
IF var1 = 100 THEN -- 만약 var1이 100이라면
DBMS_OUTPUT.PUT_LINE('100입니다');
ELSE
DBMS_OUTPUT.PUT_LINE('100이 아닙니다');
END IF;
END;
3. 간단 실습
DECLARE
hireDate DATE; --입사일
curDate DATE; -- 오늘
wDays NUMBER(5); --근무한 일수
BEGIN
SELECT hire_date INTO hireDate -- hire_date 열의 결과를 hireDate에 대입
FROM HR.employees
WHERE employee_id = 200;
curDate := CURRENT_DATE(); --현재 날짜
wDays := curDate - hireDate; -- 날짜의 차이(일 단위)
IF (wDays/356) >= 5 THEN -- 5년이 지났다면
DBMS_OUTPUT.PUT_LINE('입사한지' || wDays ||
'일이 지났습니다. 축하합니다!');
ELSE
DBMS_OUTPUT.PUT_LINE('입사한지' || wDays ||
'일밖에 안되었네요. 열심히 일하세요.');
END IF;
END;2. CASE
- IF 구문은 2중 분기라는 용어를 종종 사용함, 즉 참이 아니면 거짓 두가지만 있기 때문임
1. 형식
CASE
WHEN <부울 표현식> THEN
사용할 명령들1...
WHEN <부울 표현식> THEN
사용할 명령들2...
WHEN <부울 표현식> THEN
사용할 명령들3...
ELSE
사용할 명령들4...
END CASE2. 활용(비교)
-- IF...ELSIF...ELSE
DECLARE
pNumber NUMBER(3); -- 정수
credit CHAR(1); -- 학점
BEGIN
pNumber := 77;
IF pNumber >= 90 THEN
credit := 'A';
ELSIF pNumber >= 80 THEN
credit := 'B';
ELSIF pNumber >= 70 THEN
credit := 'C';
ELSIF pNumber >= 60 THEN
credit := 'D';
ELSE
credit := 'F';
END IF;
DBMS_OUTPUT.PUT_LINE('취득점수==>' || pNumber || ',학점==>' || credit);
END;
-- CASE
DECLARE
pNumber NUMBER(3); -- 정수
credit CHAR(1); -- 학점
BEGIN
pNumber := 77;
CASE
WHEN pNumber >= 90 THEN
credit := 'A';
WHEN pNumber >= 80 THEN
credit := 'B';
WHEN pNumber >= 70 THEN
credit := 'C';
WHEN pNumber >= 60 THEN
credit := 'D';
ELSE
credit := 'F';
END CASE;
DBMS_OUTPUT.PUT_LINE('취득점수==>' || pNumber || ',학점==>' || credit);
END;3. 실습
- CASE문을 활용하는 SQL문 작성
-- sqlDB의 구매 테이블(buyTBL)에 구매핵(price*amount)이 1500원 이상인 고객은 '최우수고객'
-- 1000원 이상인 고객은 '우수고객', 1원 이상인 고객인 '일반고객'으로 출력
-- 또 전혀 실적없는 고객은 '유령고객'이라고 출력하자
SELECT * FROM userTBL;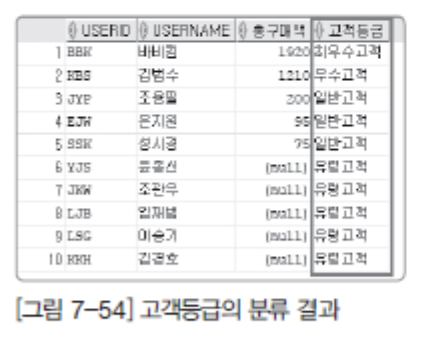
-- local-sqlDB의 워크시트에서 작업
-- 먼저 buyTBL에서 구매액(price*amount)을 사용자 아이디(userID)별로 그룹화
-- 구매액이 높은 순으로 정렬
SELECT userID, SUM(price*amount) AS "총구매액"
FROM buyTBL
GROUP BY userID
ORDER BY SUM(price*amount) DESC;
-- 사용자 이름이 빠졌으므로, userTBL과 조인해서 사용자 이름도 출력
SELECT B.userID,U. userName, SUM(B.price*B.amount) AS "총구매액"
FROM buyTBL B
RIGHT OUTER JOIN userTBL U
ON B.userID = U.userID
GROUP BY B.userID, U.userName
ORDER BY SUM(price*amount) DESC NULLS LAST;
-- 그런데, buyTBL에서 구매한 고객의 명단만 나왔을 뿐
-- 구매하지 않은 고객의 명단은 나오지 않았다
-- 오른쪽 테이블(userTBL)의 내용이 없더라도 나오도록하기 위해 RIGHT OUTER JOIN으로 변경
-- 또한 정렬할 때 NULL 값을 뒤쪽으로 보내려면 정렬할 때 NULLS LAST문을 붙여준다
SELECT B.userID,U. userName, SUM(B.price*B.amount) AS "총구매액"
FROM buyTBL B
INNER JOIN userTBL U
ON B.userID = U.userID
GROUP BY B.userID, U.userName
ORDER BY SUM(price*amount) DESC;
-- 결과를 보면 name은 제대로 나왔으나, 구매한 기록이 없는 고객은 userID부분이 null로 나왔다
-- 이유는 SELECT절에서 B.userID를 출력하기 때문이다
-- buyTBL에는 윤종신, 김경호 등이 구매한 적이 없으므로 아예 해당 아이디가 없다
-- userID의 기준을 buyTBL에서 userTBL로 변경
SELECT U.userID,U.userName, SUM(B.price*B.amount) AS "총구매액"
FROM buyTBL B
RIGHT OUTER JOIN userTBL U
ON B.userID = U.userID
GROUP BY U.userID, U.userName
ORDER BY SUM(price*amount) DESC NULLS LAST;
-- 이제는 총구매액에 따른 고객 분류를 처음에 제시했던 대로 CASE문만 따로 고려해보자
-- (다음은 실행하지 말자.)
CASE
WHEN (SUM(price*amount) >= 1500) THEN '최우수고객'
WHEN (SUM(price*amount) >= 1000) THEN '우수고객'
WHEN (SUM(price*amount) >= 1) THEN '일반고객'
END
-- 작성한 CASE 구문을 SELECT에 추가한다, 최종 쿼리 완성
SELECT U.userID,U.userName, SUM(B.price*B.amount) AS "총구매액",
CASE
WHEN (SUM(B.price * B.amount) >= 1500) THEN '최우수고객'
WHEN (SUM(B.price * B.amount) >= 1000) THEN '우수고객'
WHEN (SUM(B.price * B.amount) >= 1) THEN '일반고객'
ELSE '유령고객'
END AS "고객등급"
FROM buyTBL B
RIGHT OUTER JOIN userTBL U
ON B.userID = U.userID
GROUP BY U.userID, U.userName
ORDER BY SUM(price*amount) DESC NULLS LAST;
아직까지는 코린이!