
오늘은 개념을 배우면서 조금 아리송하군...하다가 과제를 하면서 눈물을 한 바가지 흘렸지만 나름대로 배운 게 있는 것 같아서 + 오랜만에 정말 좋은 페어분을 만나서 즐거웠던 하루였다.
과제 할 때는 진짜 에러 해결이 안 돼서 힘들었는데, 해결되고 나니... 짜릿하다.
이게 바로...개발...중독...? 🤭
(지나가세요 힘들어서 그래요..ㅎㅎ...)
😵💫GraphQL 소개
GraphQL...너는 12월 1일을 망치러 온 나의 구원자....(?)
❓ what is GraphQL?
GraphQL은 페이스북에서 만든 쿼리 언어이다.
오픈 소스이고, 2016년에 처음으로 등장해 현재까지 높은 비율의 만족도 비율 보이고 있다고 한다.
Graph + Query Language의 줄임말이고
쿼리 언어 중에서도 Server API를 통해 정보를 주고 받기 위해 사용하는 쿼리 언어를 뜻한다.
즉, API를 위한 쿼리 언어이다.
이것 저것 검색해보니 SQL이라는 Structed Query Language가 일반적으로 DB에서 데이터를 가지고 올 때 사용되는 쿼리 언어인 것 같았다.
SQL은 데이터베이스 시스템에 저장된 데이터를 효율적으로 가져오는 것이 목적이고, GraphQL은 클라이언트가 데이터를 서버로부터 효율적으로 가져오는 게 목적이라고 한다. (DB도 일종의 DB 서버일 수도 있지만)
목적이 다르다보니 SQL 문장은 주로 백엔드에서 작성하고 호출하는 반면, GQL 문장은 주로 클라이언트 시스템에서 작성하고 호출한다고 한다. 카카오 기술 블로그 참고
📉 based on Graph
그래프는 여러 개의 점들이 서로 복잡하게 연결되어 있는 관계를 표현한 자료구조이다.
그래프는 정점(vertex 혹은 node)과 간선(edge)을 가지며, 각 노드 간 간선을 통해 특정 순서에 따라 그래프를 재귀적으로 탐색할 수도 있다.
GraphQL에서는 모든 데이터가 그래프 형태로 연결되어 있다고 전제하는데, 여기서 그래프에는 계층이 있든 없든 일대일 관계든 모두 포함될 수 있다.
예를 들어 트리 구조는 계층을 가진 그래프인데 이 역시 노드와 노드를 연결하는 간선으로 구성되어 있다.
단지 그 그래프를 누구의 입장에서 정렬하느냐(클라이언트가 어떤 데이터를 필요로 하느냐)에 따라 트리 구조를 이룰 수도 있고, 아닐 수도 있는 것이다.
GraphQL은 클라이언트 요청에 따라 유연하게 트리구조의 JSON 데이터를 응답으로 전송할 수 있다.
= GraphQL은 REST API방식의 고정된 자원이 아닌 유연하게 자원을 가져올 수 있다는 점이 엄청난 장점이다 !
GraphQL 특징
- GraphQL은 HTTP를 통해 API 서버로 요청을 보내고 응답을 받는다.
- 응답을 받을 때 데이터 결과를 JSON 형식으로 받는다.
- GraphQL은 서버 개발자가 작성한 각 필드에 대응하는 resolver 함수로 각 필드의 데이터를 조회할 수 있다.
- GraphQL은 GraphQL 라이브러리가 조회 대상 schema가 유효한지 검사한다.
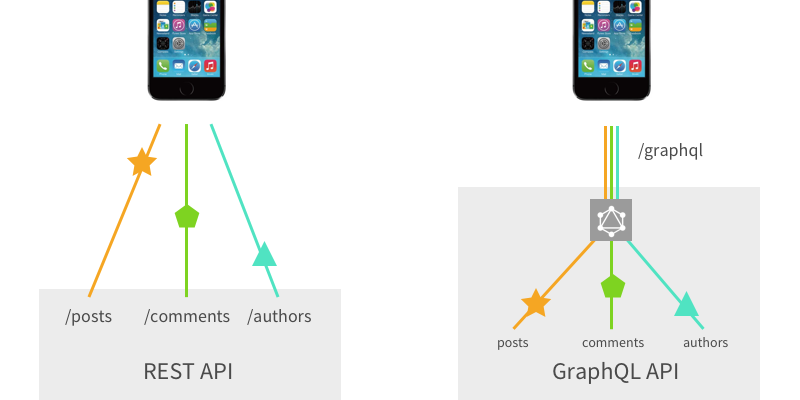
🔥 GraphQL vs. REST API
REST API가 그렇게 그렇게 좋다고 하더니~~ 왜 갑자기 멱살을 잡느냐...한다면 여느 기술들이 다 그렇듯 REST API에도 한계가 존재하기 때문이다.
REST API의 한계 😥
- Overfetch : 필요 없는 데이터까지 제공함.
- Underfetch : endpoint가 필요한 정보를 충분히 제공하지 못함.
REST API에서는 각각의 자원에 따라 엔드 포인트를 구분하기 때문에여러가지 정보가 필요할 때, 여러 개의 엔트포인트에 요청을 보내야함.- 클라이언트 구조 변경 시 엔드포인트 변경 또는 데이터 수정 필요
: REST API에서는 자원의 크기와 형태를 서버에서 결정하므로 클라이언트가 직접 데이터 형태를 결정할 수 없음.
만약 클라에서 필요한 데이터 내용이 변할 경우 다른 endpoint 통해 변경된 데이터 가져오거나 수정해야 함.
REST API와 GraphQL의 차이점은 아래와 같다.
GraphQL과 REST API 차이
- REST API는 Resource에 대한 형태 정의와 데이터 요청 방법이 연결되어 있지만, GraphQL에서는 Resource에 대한 형태 정의와 데이터 요청이 완전히 분리되어 있음.
- REST API는 Resource의 크기와 형태를 서버에서 결정하지만, GraphQL에서는 Resource에 대한 정보만 정의하고, 필요한 크기와 형태는 클라이언트 단에서 요청 시 결정.
- REST API는 URI가 Resource를 나타내고 Method가 작업의 유형을 나타내지만, GraphQL에서는 GraphQL Schema가 Resource를 나타내고 Query, Mutation 타입이 작업의 유형을 나타낸다.
- REST API는 여러 Resource에 접근하고자 할 때 여러 번의 요청이 필요하지만, GraphQL에서는 한번의 요청에서 여러 Resource에 접근할 수 있음.
- REST API에서 각 요청은 해당 엔드포인트에 정의된 핸들링 함수를 호출하여 작업을 처리하지만, GraphQL에서는 요청 받은 각 필드에 대한 resolver를 호출하여 작업을 처리함.
GraphQL의 장단점
장점
- 하나의 endpoint 요청
: •/graphql이라는 하나의 endpoint 로 요청을 받고 그 요청에 따라 query , mutation을 resolver 함수로 전달해서 요청에 응답함. 모든 클라이언트 요청은POST메소드를 사용.
- No under & overfetching 🚫
- 강력한 playground
: graphql 서버를 실행하면 playground라는 GUI를 이용해 resolver 와 schema 를 한 눈에 보고 테스트 해 볼 수 있음. (POSTMAN 과 비슷)
- 클라이언트 구조 변경에도 지장이 없음
: 클라이언트 구조가 바뀌어도 필요한 데이터를 결정하고 받는 주체가 클라이언트이기 때문에 서버에 지장이 없다. 클라이언트에서는 무슨 데이터가 필요한 지에 대해서만 요구사항을 쿼리로 작성하면 된다.
단점
- REST API에 친숙한 개발자의 경우 GraphQL 학습시간 필요.
- 캐싱이 REST보다 훨씬 복잡함.
: HTTP에선 각 메소드에 따라 캐싱이 구현되어 있지만 GraphQL에선POST메소드만을 이용해 요청을 보내기 때문에 각 메소드에 따른 캐싱을 지원받을 수 없다.
그래서 이를 보안하기 위해 Apollo 엔진의 캐싱과 영속 쿼리 등이 등장함. - 고정된 요청과 응답만 필요할 경우에는 Query 로 인해 요청의 크기가 RESTful API 의 경우보다 더 커짐.
👩🏫 GraphQL 구조
🔑 GraphQL keywords
🟢 서버로부터 데이터를 조회(Read)하는 경우
: REST API에서는 GET요청이었다면 GraphQL에서는 Query 이용해 원하는 데이터 요청할 수 있음.
🟢 Create, Delete와 같이 저장된 데이터를 수정하는 경우
: Mutation을 이용.
🟢 Subscription(구독)
: 특정 이벤트가 발생하면 서버가 대응하는 데이터를 실시간으로 클라이언트에게 전송해준다.
이 개념을 이용하면 실시간 업데이트를 구현할 수도 있음.
(전통적인 Client, Server 모델을 따르는 Query, Mutation과 달리 발행/구독 (sub/pub) 모델을 따르는데, 클라이언트가 어떤 이벤트를 구독하면 클라이언트는 서버와 WebSocket을 기반으로 지속적 연결을 형성하고 유지하게 됨. 그 후 특정 이벤트가 발생하면 서버는 대응하는 데이터를 클라이언트에 푸쉬해줌.)
❓quey
field
//hero 필드의 name을 쿼리
{
hero {
name
}
}
//쿼리 실행 결과
{
"data": {
"hero": {
"name": "R2-D2"
}
}
}
필드 중첩 가능
//히어로 이름과 히어로 친구 이름을 함께 쿼리
{
hero {
name
# 이런 식으로 GraphQL 내에서 주석 작성
friends {
name
}
}
}
//응답
{
"data": {
"hero": {
"name": "R2-D2",
"friends": [
{
"name": "Luke Skywalker"
},
{
"name": "Han Solo"
},
{
"name": "Leia Organa"
}
]
}
}
}
//friends 필드는 배열을 반환한다.
//GraphQL쿼리가 관련 객체 및 필드를 순회할 수 있기 때문에
//클라이언트가 하나의 요청을 보냄으로써 관련 데이터를 가지고 올 수 있음.
//(REST API에서는 각각의 endpoint로 요청 보내야함)Arguments (전달인자)
필드에 인수 전달하는 부분을 추가하면 쿼리 필드 및 중첩된 객체들에 전달해 원하는 데이터만 받아올 수 있음.
//id가 1000인 human의 name과 height를 쿼리
{
human(id: "1000") {
name
height
}
}
//쿼리 결과
{
"data": {
"human": {
"name": "Luke Skywalker",
"height": 1.72
}
}
}
//id가 1000인 human의 이름과 키를 쿼리해올 수 있음.Aliases (별명)
필드 이름 중복해 사용할 수 없지만 필드 이름을 중복으로 사용해야 할 때 별명을 붙여서 쿼리할 수 있음.
응답시에는 별명으로 응답이 온다.
//이렇게 중복해 쿼리할 수 없음 🚫
{
hero(episode: EMPIRE) {
name
}
hero(episode: JEDI) {
name
}
}
//앞에 알아볼 수 있는 별명을 붙여주면 중복해서도 가능
{
empireHero: hero(episode: EMPIRE) {
name
}
jediHero: hero(episode: JEDI) {
name
}
}
//쿼리 결과
{
"data": {
"empireHero": {
"name": "Luke Skywalker"
},
"jediHero": {
"name": "R2-D2"
}
}
}Operation name
실제로 코드를 작성할 땐 모호하지 않은 코드를 작성하는 것이 중요하므로 쿼리에 이름을 붙여주는 게 중요
오퍼레이션 타입인 query, mutaion, subscription, describes 등에 맞춰서 오퍼레이션 네임을 작성해주는 것이 가독성에 좋다.
//여기서는 HeroNameAndFriends가 오퍼레이션 네임
query HeroNameAndFriends {
hero {
name
friends {
name
}
}
}
//결과
{
"data": {
"hero": {
"name": "R2-D2",
"friends": [
{
"name": "Luke Skywalker"
},
{
"name": "Han Solo"
},
{
"name": "Leia Organa"
}
]
}
}
}
Variables (변수)
실제 앱을 사용할 때는 고정된 인수를 받는 것보다는 동적으로 인수를 받아 쿼리하는 경우가 많고,
변수는 인수들을 동적으로 받고 싶을 때 사용한다.
query HeroNameAndFriends($episode: Episode) {
hero(episode: $episode) {
name
friends {
name
}
}
}오퍼레이션 네임 옆에 변수를 $변수 이름: 타입 형태 로 정의할 수 있다.
위의 예시처럼 $episode: Episode일 때, 뒤에 !가 붙는다면 episode는 반드시 Episode여야 한다는 뜻임.
(!는 옵셔널한 사항이다.)
✍️ mutation
GraphQL은 데이터를 가져오는 데 중점을 둔 언어이지만, 개발을 하다보면 데이터를 수정해야 하는 경우가 있기 때문에 mutation이라는 키워드도 존재한다.
mutation CreateReviewForEpisode($ep: Episode!, $review: ReviewInput!) {
createReview(episode: $ep, review: $review) {
stars
commentary
}🧩 스키마/타입(Schema/Type)
GraphQL 스키마의 가장 기본적인 구성 요소는
서비스에서 가져올 수 있는 객체의 종류, 그리고 포함하는 필드
를 나타내는 객체 유형.
- 오브젝트 타입 : Character
=> Character는GraphQL 객체 타입을 말함.
필드가 있는 타입임을 의미하고, 스키마에 있는 대부분의 타입은 객체 타입이다. - 필드 : name, appearsIn => name 과 appearIn 은 Character 타입의 필드로 GraphQL 쿼리의 Character 타입 어디서든 사용할 수 있는 필드임
- 스칼라 타입 : String, ID, Int 등
- 느낌표(!) : 필수 값을 의미(non-nullable)
- 대괄호([, ]) : 배열을 의미(array) => 배열에도 !가 붙을 수 있음.
type Character {
name: String!
appearsIn: [Episode!]!
}
//배열 뒤에 !가 붙어있어 null 값을 허용하지 않으므로 항상 0개 이상의 요소를 포함한 배열을 기대한다. 스키마 같은 경우는 오늘 과제에서도 직접 작성해볼 일이 없어서 아직 개념이 조금 모호한데
스터디원과 이야기해본 바 서버단에서 응답'할' 데이터의 틀 = 각각 항목과 필드에 어떤 값이 들어올 것인지 를 미리 설정하는 느낌인 것 같다.
🛠 Resolver
GraphQL에서는 데이터를 가져오는 구체적인 과정을 직접 구현해야 하는데 이와 같은 작업(e.g. 데이터베이스 쿼리, 원격 API 요청)을 Resolver가 담당하게 된다.
리졸버는 요청에 대한 응답을 결정해주는 함수로써 GraphQL의 여러 가지 타입 중 Query, Mutation, Subscription과 같은 타입의 실제 일하는 방식 즉 로직을 작성한다.
스키마를 정의하면 그 스키마 필드에 사용되는 함수의 실제 행동을 Resolver에서 정의한다. (이러한 함수들이 모여 있기 때문에 보통 Resolvers라 부름)
(스키마와 리졸버는 보통 서버단에서 작성하는듯 하다.)
const db = require("./../db")
const resolvers = {
Query: { // **Query :** 저장된 데이터 가져오기 (REST 에 GET 과 비슷합니다.)
getUser: async (_, { email, pw }) => {
db.findOne({
where: { email, pw }
}) ... // 실제 디비에서 데이터를 가져오는 로직을 작성합니다.
...
}
},
Mutation: { // **Mutation :** 저장된 데이터 수정하기 ( Create , Update , Delete )
createUser: async (_, { email, pw, name }) => {
...
}
}
Subscription: { // **Subscription :** 실시간 업데이트
newUser: async () => {
...
}
}
};🐙 과제
과제를 완벽하게 완료하지 못했기 때문에 주말에 복습하면서 다시 해볼 생각이다.
🐣 Bareminimum
- 코드스테이츠 아고라 스테이츠 레포지토리에 접근해 1개 이상의 데이터를 조회하기
- 현재 내가 로그인 되어 있는지 확인할 수 있는 쿼리 짜기 (API에 접속중인 유저가 본인인지 확인)
🔥 Advanced
- 쿼리해 온 데이터를 React 앱으로 만들었던 나만의 아고라스테이츠에 적용해 구성해보기 (주말에 해보자)
💡 새롭게 알게 된 것
1. GitHub GraphQL API는 정말로 유용한 도구였다..!
실습할 때 설렁설렁 클릭해보면서 흠... 이렇게 작동하나보군. 하고 넘어간게 내 죄였다.😈
쿼리에 들어갈 내용을 explore에서 커스텀(?)해서 긁어오다시피 할 수 있으므로... 사실은 정말 유용한 도구였다...
2. create-react-app으로 만든 경우 환경변수 사용할 때 주의할 점
create-react-app 명령어로 리액트를 만들었으면 환경 변수 이름 앞에 반드시 REACT_APP_ 이라는 걸 붙여야 인식하고, 그렇지 않으면 보안상의 이유로 인식하지 않는다고 한다.
(그리고 환경변수를 바꾸었으면 반드시 npm run start로 리액트를 다시 시작해야 변경사항이 적용된다고 함.)
토큰이 보안상 중요하기 때문에 환경 변수를 사용해야겠다는 생각은 있었는데, 오랜만에 사용하려니 노드에서 사용했던 것처럼 dotenv를 사용해야하나...? 이러다 페어랑 머리 맞대로 끄적끄적 썼는데, 환경 변수에 REACTAPP을 붙여주지 않아서 제대로 인식이 되지 않았었다.
실시간 세션에서 강사님 말씀으론 환경 변수를 잘만 사용하면 development 환경일 때와 test 환경일 때를 나누어서 token을 적용해줄수도 있다고 한다. (아래와 같이)
const { REACT_APP_GITHUB_AGORA_STATES_TOKEN, NODE_ENV } = process.env;
//위와 같이 적용해준 상태일 때
let token;
if (NODE_ENV === 'development' || NODE_ENV === 'test') {
token = REACT_APP_GITHUB_AGORA_STATES_TOKEN;
}3. discussion과 discussions는 다르구나...!
discussion을 설정하고 뒤에 옵션으로 자꾸 number를 설정하라고 떠서 페어와 이게 대체 뭐지... 하면서 머리를 맞대고 고민했는데, 게시글 번호에 해당하는 옵션이었다. 근데 내가 알기로는 게시글을 몇 개까지 가지고 올 수 있는지 설정해줄 수 있는 옵션이 있었던 거 같은데... 뭔가 이상한 느낌이 들었지만 일단 당장 뜨는 에러들을 처리하느라 바빴다.
나중에 스터디원과 이야기를 하다가 discussion이 아니라 discussions를 사용했어야 한다는 것을 알게 되었고... discussions는 first라는 옵션을 사용해 최근 게시물들을 몇 개까지 가지고 올 지 설정할 수 있었다는 것을 알게 되었다...! 충격과 공포. 삽질을 엄청나게 해버린자의 눈물...🤣
4. 깃허브는 나보다 똑똑하다 : 알아서 토큰을 만료시켜주는 똑쟁이 깃허브 (feat.메일함)
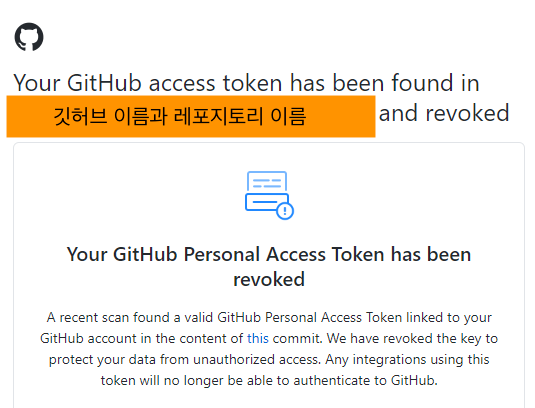
bad cridential 에러를 해결하는 과정에서 여러가지 시도를 해보다가 '혹시 내 토큰에 문제가 있는 건가..!'하는 결론에 다다랐는데(사실은 토큰 자체에 문제가 있다기 보다 환경 변수 설정에 문제가 있었던 거였지만) 그런데 원래 내가 가진 토큰이 기한이 없는 토큰이었기에 의아해하던 와중 페어가 발견한 글에서 실마리를 찾을 수 있었다.
토큰을 포함한 상태의 코드를 그대로 공개해서 깃허브에 push 하게 되면 토큰이 함께 발행되었다는 것을 깃허브에서 인지하고 해당 토큰을 바로 만료시켜버린다는 것이었다... 보안이 진심인 깃허브... 그리고 토큰이 만료되지 않도록 gitignore 설정해주기 같은 것들을 잊지 않도록 조심해야겠다!
