
🧠 Gemma2
- Google은 2024년 5월 14일, 차세대 LLM 모델 Gemma2를 발표했습니다.
- 모델 규모는 9B, 27B 두 가지이며, 특히 27B 모델이 LLaMA3 70B와 유사한 성능을 훨씬 작은 크기로 제공하는 것이 핵심 강점입니다.
- 이후에는 2B On-device 경량 모델도 공개하여,
Google이 모바일·로컬 환경 추론(On-device AI) 에 강하게 집중하고 있음을 보여줍니다.
📚 학습 데이터 및 필터링
- 총 13조 토큰 규모의 공개 데이터에서 학습되었고, 9B 모델 기준으로 8조 토큰이 사용되었습니다.
- 데이터 유형은 주로 웹 텍스트, 코드, 수학이며, 복잡한 논리 추론과 다양한 어휘 학습을 가능케 했습니다.
- 전처리 단계에서는 다음과 같은 필터링이 적용되었습니다
- CSAM(아동 착취물) 필터링
- PII(개인 식별 정보) 제거
- Google 정책 기반 품질 필터링
🧱 모델 아키텍처
- Vocab size는 256K로, 기존 Gemma와 동일
- 핵심 아키텍처 개선점은 다음과 같습니다
-
🧭 RoPE + Context 확장
- RoPE (Rotary Positional Embedding) 를 통해 컨텍스트 길이를 4K → 8K로 확장
- 이를 통해서 기존 Gemma보다 2배 더 많은 컨텍스트 길이를 처리할 수 있게 되었습니다.
-
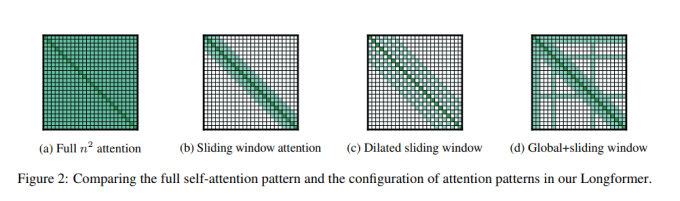
🪟 Sliding Window Attention & Group Query Attention
- 기존 Transformer의 어텐션은 메모리·속도 부담이 큼
- 이를 해결하기 위해 시퀀스를 작은 창(window) 단위로 나눠 어텐션 수행
- 전체 문장이 아닌 부분 단위만 계산해 긴 문서 처리 최적화 + 속도 향상
- 추가적으로 LLAMA처럼 Gemma2도 GQA을 도입하여 어텐션 연산에 대한 최적화를 통해 학습과 추론 과정에서 연산 속도가 향상
-
🧮 Logit Soft Capping
- 로짓(Logit)이 지나치게 클 경우, 특정 단어만 반복 출력되는 현상을 방지
- Logit 값을 soft cap으로 나눈 뒤 tanh로 범위 제한
- 예측 안정성과 다양성 향상
-
📘 지식 증류 (On-policy Distillation)
- 더 큰 teacher 모델의 출력을 사용해 작은 모델 학습
- 일반적인 증류는 teacher 모델의 응답을 기준으로 학습을 하다보면 student 모델에는 없는 토큰이 존재하여 분포 불일치 문제가 있는데, Gemma2는 On-policy Distillation을 통해 이를 해결
- 즉, student 모델이 생성한 문맥에 맞춰 teacher 모델이 응답의 순위를 부여하고, 부족한 응답에 대해서는 출력을 재생성함으로써 student 모델의 분포 일치를 유지하면서 부족한 응답에 대해서는 teacher 모델로 보강하여 좀 더 추론 능력을 향상시켰습니다.
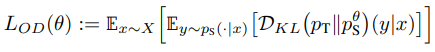
-
🧬 모델 병합 (Model Merging with Warp)
- 다양한 사전학습 모델을 효율적으로 병합해 새로운 모델을 구성
- 기존 LLM 병합과 달리, Warp 알고리즘을 통해 레이어별 중요도에 따라 구조적으로 병합 → 성능 손실 최소화
BenchMark
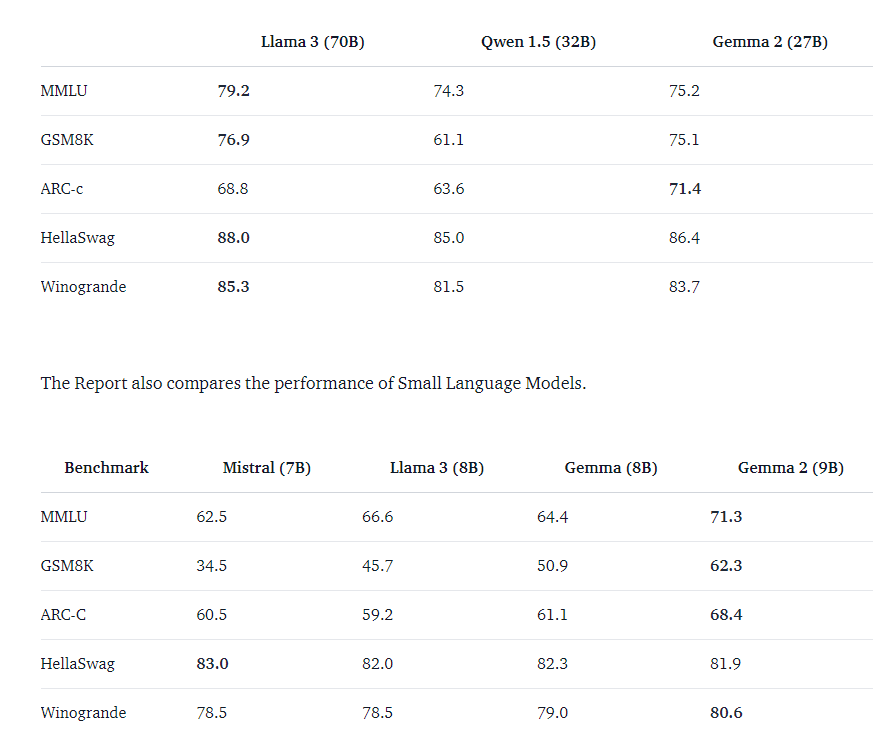
- 해당 벤치마크를 보면, 9B의 경우 Llama3 70B과 유사한 수준을 나타내고, 비슷한 모델 파라미터에서는 가장 우수한 성능을 발휘합니다.
Gemma2 사용해보기
사용한 패키지 버전
- flash_attn == 2.5.9.post1
- accelerate == 0.30.1
- sentencepiece == 0.2.0
- torch == 2.3.0
- transformers == 4.42.3
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline, TextStreamer
import torch
tokenizer = AutoTokenizer.from_pretrained(
"google/gemma-2-9b-it",
)
model = AutoModelForCausalLM.from_pretrained(
"google/gemma-2-9b-it",
torch_dtype=torch.bfloat16,
device_map='auto',
)
streamer = TextStreamer(tokenizer)
messages = [
{"role": "user", "content": "대한민국의 수도에 대해 알려줘"},
]
input_ids = tokenizer.apply_chat_template(
messages,
add_generation_prompt=True,
return_tensors="pt"
).to(model.device)
terminators = [
tokenizer.eos_token_id,
tokenizer.convert_tokens_to_ids("<|end_of_turn|>")
]
outputs = model.generate(
input_ids,
max_new_tokens=512,
eos_token_id=terminators,
do_sample=False,
repetition_penalty=1.05,
streamer = streamer
)
response = outputs[0][input_ids.shape[-1]:]
print(tokenizer.decode(response, skip_special_tokens=True))
# 결과
대한민국의 수도는 **서울**입니다.
서울은 한국의 역사, 문화, 경제 중심지이며, 약 970만 명의 인구를 가진 대도시입니다. - 기존 Gemma는 아쉬웠는데, 이번 Gemma2는 한국어 생성도 잘하고, 미세조정을 하면, 해당 도메인에 맞게 잘 대답하여 앞으로 한국어 미세조정 모델 만들 시 Gemma2를 사용하시면 좋을 거 같습니다.

NLP Developer