다른 사이트에 있는 정보를 가져오는 방법?
기존 웹사이트에서는 JSON 대신 XML(eXtensible Markup Language)을 이용하여 가져왔었다.
//XML:확장 가능한 마크업 언어로 이런 식이이었다.
<name> 철수</name>
<title>제목</title>
//JSON
{
name:"철수",
title:"제목"
}스크랩핑
데이터 스크랩핑(data scraping)은 컴퓨터 프로그램이 다른 프로그램으로부터 들어오는 인간이 읽을 수 있는 출력으로부터 데이터를 추출하는 기법이다. wiki백과
우린 이를 통해서 원하는 사이트에서 정보를 뽑아와 마음대로 가공할 수 있다.
디스코드에서 특정사이트를 입력하면 헤드 태그 안의 메타태그에서 og태그를 찾고 스크랩핑해서 치어리오를 사용해서 가져온 것도 스크랩핑을 통해 가져온다고 볼 수 있다.

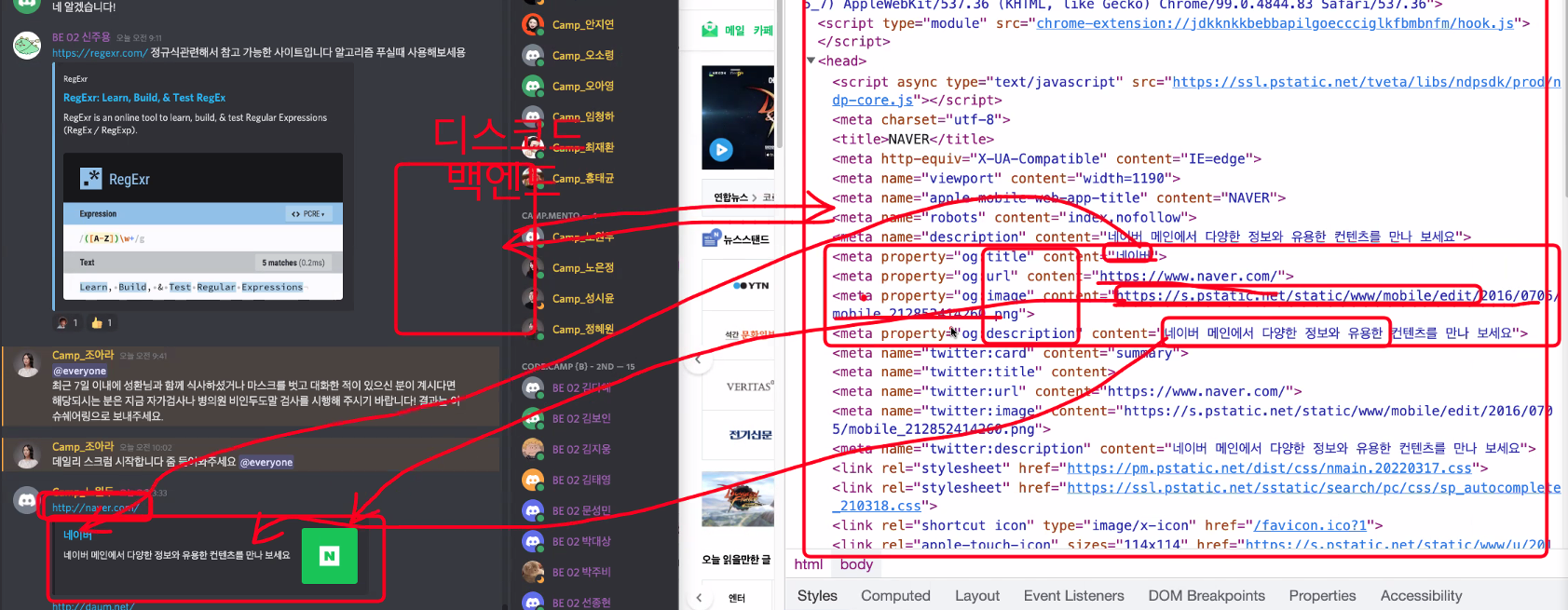
이번엔 특정 사이트에 가서 한 번만 스크랩해서 가져올 것이다.
스크래핑 실습
아래 사진과 같은 방식으로 태그를 골라낼 것이다.
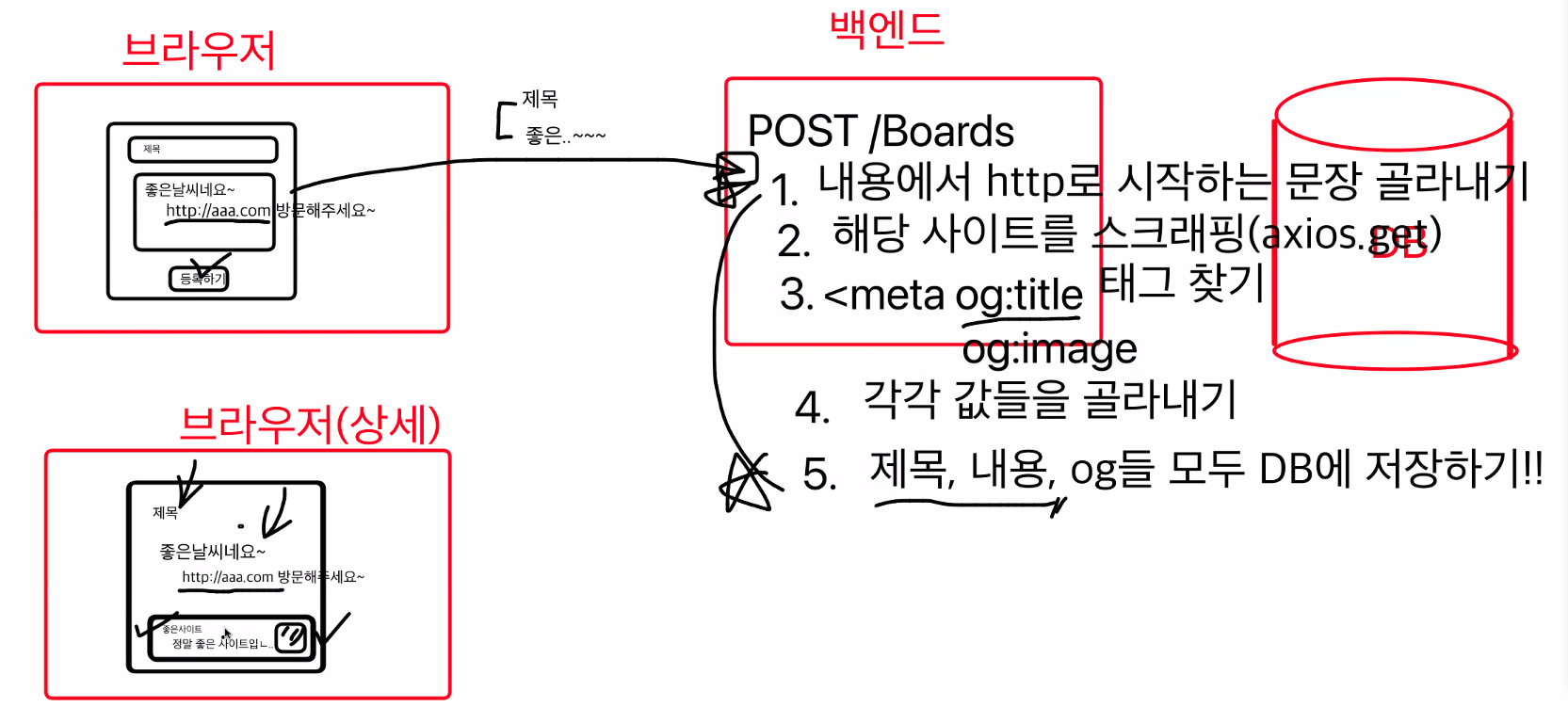
치어리오를 다운받고, OG태그를 잘라내기 위한 소스코드를 작성한다.
yarn add cheerioimport axios from "axios";
import cheerio from 'cheerio'
async function createBoardAPI(mydata) {
// 3. 게시글에서 url찾아서 스크래핑
const targetURL = mydata.contents.split(" ").filter( el => el.startsWith("http"))[0]
// 1. 스크래핑
const aaa = await axios.get(targetURL)
// 2. OG골라내기
const $ = cheerio.load(aaa.data)
//each는 cheerio문법으로
$("meta").each((_, el) => {
if ($(el).attr('property')) {
const key = $(el).attr('property').split(":")[1]
const value = $(el).attr('content')
console.log(key, value)
}
})
}
const frontendData = {
title: ":안녕하세요",
contents: "여기 정말 좋은 거 같아요! 한번 꼭 놀러오세요! 여기는 https://www.naver.com 이에요!!"
}
createBoardAPI(frontendData);결과

크롤링
다른 사이트에 있는 정보를 주기적으로 여러 번 가져온다. 실제로 브라우저에 접속을 해서 데이터를 가져온다. 최근 DATA에 대한 가치가 많이 높아졌다. 이로 인해 여러 사건들이 발생했다. 그 중 한가지인 여기어때 크롤링 사건을 소개한다.
여기어때 크롤링 사건 위 링크를 통해 접속해보면 여기어때가 야놀자의 DATA를 맘대로 이용하여 벌어진 사건인데 크롤링을 할 때에는 이를 허용한 사이트에서만 해야하고 너무 자주 많이 정보를 가져가면 서버에서 차단 당할 수 있으니 조심하자.
robots.txt파일을 통해 크롤링이 가능한 부분을 확인할 수 있다.
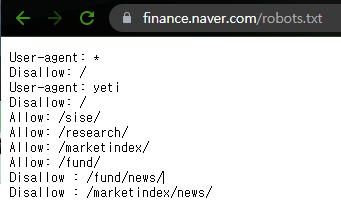
크롤링 해온 데이터를 db에 저장하는 방식으로 코드를 작성해보았다. 이때 스타벅스의 음료 리스트를 출력해오도록 하였다.
import puppeteer from 'puppeteer'
import mongoose from 'mongoose'
import { Starbucks } from './models/starbucks.model.js'
mongoose.connect("mongodb://localhost:27017/~~~")
.then(()=>console.log('connected'))
.catch(e=>console.log(e));
async function startCrawling() {
const browser = await puppeteer.launch({
headless: false// false 일 경우 실행 시 웹사이트 확인 가능
});
const page = await browser.newPage()
await page.setViewport({ width: 1280, height: 720 })
await page.goto("https://www.starbucks.co.kr/menu/drink_list.do")
await page.waitForTimeout(1300)
for (let i = 1; i <= 10; i++) {
await page.waitForTimeout(500)
// #container > div.content > div.product_result_wrap.product_result_wrap01 > div > dl > dd:nth-child(2) > div.product_list > dl > dd:nth-child(2) > ul > li:nth-child(2) > dl > dt > a > img
// #container > div.content > div.product_result_wrap.product_result_wrap01 > div > dl > dd:nth-child(2) > div.product_list > dl > dd:nth-child(2) > ul > li:nth-child(1) > dl > dt > a > img
const img = await page.$eval(`#container > div.content > div.product_result_wrap.product_result_wrap01 > div > dl > dd:nth-child(2) > div.product_list > dl > dd:nth-child(2) > ul > li:nth-child(${i}) > dl > dt > a > img`, el => el.getAttribute("src"))
const name = await page.$eval(`#container > div.content > div.product_result_wrap.product_result_wrap01 > div > dl > dd:nth-child(2) > div.product_list > dl > dd:nth-child(2) > ul > li:nth-child(${i}) > dl > dd`, el =>el.textContent)
console.log(`이미지: ${img} 이름: ${name}`)
const starbucks = new Starbucks({
name : name,
img : img
})
console.log(starbucks)
await starbucks.save()
}
//browser닫기
await browser.close()
}
startCrawling()
db에 잘 저장이 된 것을 볼 수 있다.

마치며
내가 원하는 정보를 시간과 장소의 제약없이 컴퓨터가 대신 가져올 수 있다는 점을 통해 정보화시대에 조금은 뒤쳐지지 않게 된 기분이 든다... 법을 잘 지키며 이용하자!
