
대용량 트래픽 & 데이터 처리
이번 주차는 동시성 제어에서 한단계 더 나아가 Redis를 활용한 분산락에 대하여 학습하고, 프로젝트에 필요한 부분을 식별하여 적용하는 과정이었습니다.
또한, RedissonCacheManager 및 @Cacheable를 적용하여 캐싱을 통한 무거운 쿼리를 갖는 조회 로직에 적용하는 방법을 습득했습니다.
Redis & 분산락 통합 테스트
먼저, 분산락(Distributed Lock)이란, 서로 다른 서버 인스턴스에 대하여 일관된 락을 제공하기 위한 장치들을 뜻하며, 이번 과정에서는 Redis로 이를 구현했습니다.
분산락을 적용하기 전 주문에 대하여 여러 요청에 대한 동시성 테스트를 작성합니다.
조건
-
상품 10개, 각 재고 10개, 총 100개의 충분한 상품을 설정한다.
-
사용자 10명, 주문 1건 당 상품 5가지를 골라, 각각 2개씩 구매한다.
-
총 10 5 2 = 100개로 재고와 딱 맞아 떨어지는 주문을 동시에 수행한다.
-
사용자 별 초과되지 않게 상품 5개를 고르는 로직
@Test @DisplayName("재고가 10인 10개의 상품을 10명이서 5종류 씩 순서에 상관없이 2개씩 구매할때, 10개의 상품이 모두 정상적으로 판매된다.") void placeOrders_concurrently() throws InterruptedException { /* ... */ Map<Long, List<OrderItemCommand>> carts = new LinkedHashMap<>(); for (int u = 0; u < userCount; u++) { Long userId = users.get(u).getId(); List<OrderItemCommand> original = new ArrayList<>(); for (int k = 0; k < picksPerUser; k++) { int pIndex = (u + k) % productCount; // id 기준으로 1개씩 밀어서 장바구니 담기 Long productId = products.get(pIndex).getId(); original.add(new OrderItemCommand(productId, qtyPerPick)); } List<OrderItemCommand> shuffled = new ArrayList<>(original); Collections.shuffle(shuffled, new Random(userId)); // 랜덤으로 셔플 System.out.printf("사용자: %d,\t원본: [%s],\t랜덤: [%s]%n", userId, formatCart(original), formatCart(shuffled)); carts.put(userId, shuffled); } /* ... */ }
-
-
주문 시 상품의 순서는 무작위로 담는다.
-
쿠폰과 잔액으로 인한 실패는 배제한다.
테스트 결과
1. 상품 정렬 미실시 - 실패(데드락)
- 주문 시 상품을 랜덤 순서로 담아서 요청하고,
OrderFacade에서 그대로 처리 - 이미 이전 주에
sorted로productId기준 정렬을 하는 코드가 있어, 주석 후 실행
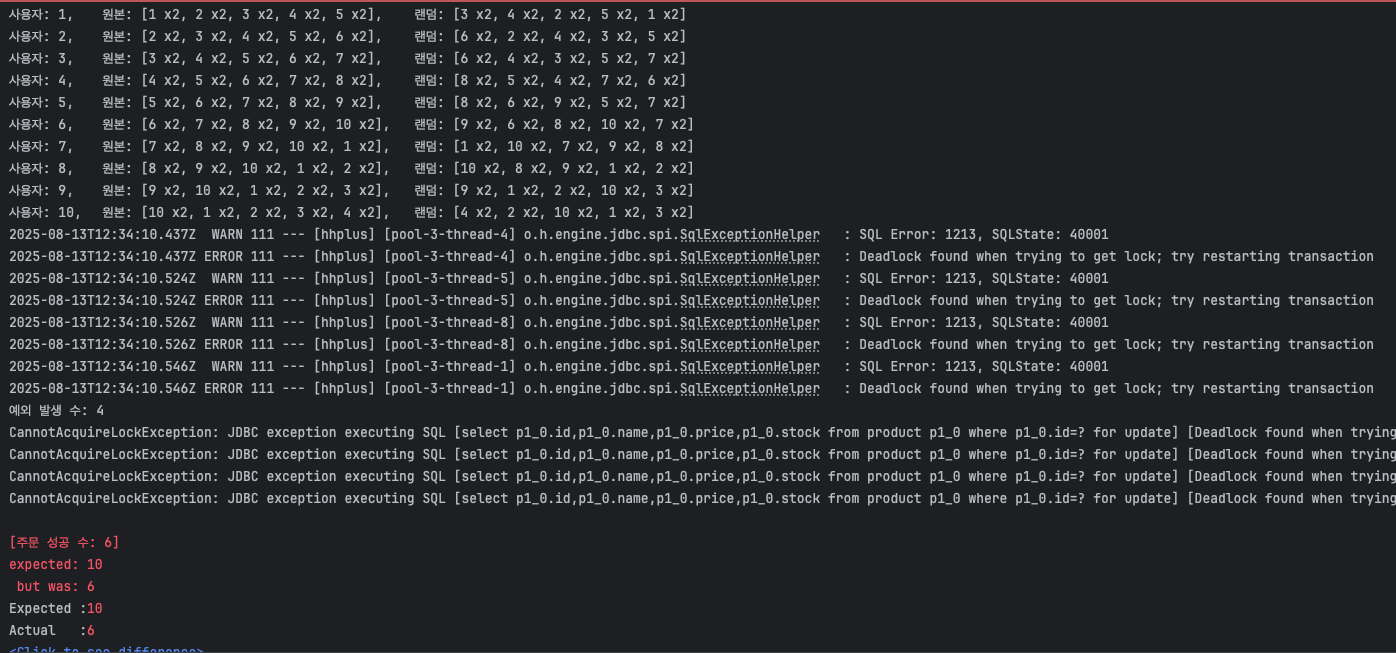
- 이전 주에 비관적 락을 구현하긴 했으나, 에러는 데드락으로 인하여 요청일부가 실패하는 코드가 발생함
- 이외에 간헐적으로 테스트가 통과되어도 재고를 모두 소진하지 못함
2. 상품 정렬 실시 - 실패(재고 미소진)
-
OrderFacade에서productId로sorted수행(주석 해제)@Transactional public Order placeOrder(Long userId, List<OrderItemCommand> orderItems, Long couponId) { User user = userService.findById(userId); List<OrderItem> items = orderItems.stream() .sorted(Comparator.comparing(OrderItemCommand::getProductId)) // 상품 순서 정렬 .map(command -> { Product product = productService.verifyAndDecreaseStock(command.getProductId(), command.getQuantity()); return OrderItem.of(product, product.getPrice(), command.getQuantity(), 0); }) .toList(); }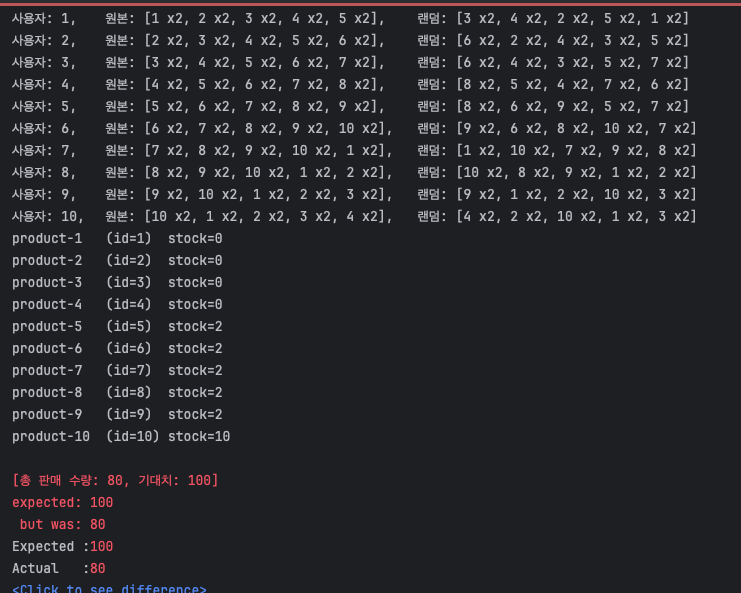
-
순서에 의한 데드락은 발생하지 않는 것으로 확인
-
하지만, 여전히 재고 차감은 기대치 만큼 발생하지 않음
-
경쟁 조건이 발생하여 재고 업데이트가 누락되는 것으로 추정
Redis 및 분산락 적용
분산락 커스텀 어노테이션 구현
-
DistributedLock.java: 분산락 적용을 위한 커스텀 어노테이션
prefix: 도메인 별lock을 획득하기 위한key(LockKey.java)ids: 멀티 키를 위한id배열, 주로PK를 사용
-
DistributedLockAspect.java: 커스텀 어노테이션 기반 AOP 구현 클래스
-
@Order(Ordered.HIGHEST_PRECEDENCE): 최우선 순위 보장- 기본
@Transactional은LOWEST_PRECEDENCE로 등록됨
- 기본
-
lock함수: @DistributedLock 어노테이션이 붙은 메서드를 실행하기 전 후로, 분산락 처리-
prefix와ids를 기반으로 멀티 키를 획득, 문자열 사전 순 정렬List<String> lockKeys = toKeys(prefixStr, idsVal).stream().sorted().toList(); // 키 목록 생성, 정렬 -
정렬 기반 순차 락(Sequential Sorted Locking)
- 정렬된 키를 기준으로 for 문으로 모든 키를 획득
- 중간에 획득하지 못하면 에러를 발생시키도록 구현
@Around("@annotation(kr.hhplus.be.server.common.lock.DistributedLock)") public Object lock(ProceedingJoinPoint joinPoint) throws Throwable { /* ... */ List<RLock> acquiredLocks = new ArrayList<>(); try { for (String key : lockKeys) { RLock lock = redissonClient.getLock(key); // 정렬된 순서대로 락획득 boolean locked = lock.tryLock( distributedLock.waitTimeoutMillis(), distributedLock.ttlMillis(), TimeUnit.MILLISECONDS ); if (!locked) { for (RLock l : acquiredLocks) { try { l.unlock(); } catch (Exception ignore) {} } throw new IllegalStateException("Failed to acquire lock: " + key); } acquiredLocks.add(lock); } return joinPoint.proceed(); // 비즈니스 로직 실행 } finally { Collections.reverse(acquiredLocks); for (RLock l : acquiredLocks) { try { l.unlock(); } catch (IllegalMonitorStateException e) { log.info("Lock already unlocked: {}", l.getName()); } } } }- 데드락 문제는 회피가 가능하나 원자성이 보장되지 않음
-
멀티락(RedissonMultiLock)
- 여러 RLock을 묶어서 하나의 락처럼 취급함
- 내부적으로 모든 키에 대해 tryLock을 수행하고 전부 성공해야만 획득 완료
@Around("@annotation(kr.hhplus.be.server.common.lock.DistributedLock)") public Object lock(ProceedingJoinPoint joinPoint) throws Throwable { /* ... */ RedissonMultiLock multiLock = new RedissonMultiLock(lockList.toArray(new RLock[0])); try { boolean locked = multiLock.tryLock( distributedLock.waitTimeoutMillis(), distributedLock.ttlMillis(), TimeUnit.MILLISECONDS ); if (!locked) { throw new IllegalStateException("Failed to acquire multi lock: " + lockKeys); } return joinPoint.proceed(); } finally { try { multiLock.unlock(); } catch (IllegalMonitorStateException e) { log.info("MultiLock already unlocked: keys={}", lockKeys); } } }- 순차락과 달리 멀티키로 단일 대기 수행
- 순차락에 비해 성능 및 오버헤드가 락 개수 및 경합도에 비례하여 커짐
-
-
toKeys함수:DistributedLock.ids()값(단일값, 배열, Iterable)을 모두List<String>락 키 목록으로 변환
-
분산락 적용
- OrderFacade.java: 커스컴 AOP 적용
-
OrderFacade에서 사용되는Product, Coupon, Balance, Order중 다른 사용자와 경합이 많이 발생하는Product로 분산락 적용함 -
Coupon, Balance, Order기존 DB락으로 유지 -
로직 변경없이
@DistributedLock적용 -
@Order(Ordered.HIGHEST_PRECEDENCE)로 구현되어 있어@Transactional보다 먼저 진입, 나중에 해제됨@Component @RequiredArgsConstructor public class OrderFacade { /* ... */ @Transactional @DistributedLock(prefix = LockKey.PRODUCT, ids = "#orderItems.![productId]") public Order placeOrder(Long userId, List<OrderItemCommand> orderItems, Long couponId) { /* ... */ List<OrderItem> items = orderItems.stream() .sorted(Comparator.comparing(OrderItemCommand::getProductId)) // 상품 순서 정렬 .map(command -> { Product product = productService.verifyAndDecreaseStock(command.getProductId(), command.getQuantity()); return OrderItem.of(product, product.getPrice(), command.getQuantity(), 0); }) .toList(); /* ... */ } }
-
조건부 업데이트 쿼리 수정
- ProductRepository.java: 조건부 업데이트 쿼리
-
비관적 락에서 조건부 업데이트 쿼리로 수정
-
분산락에서
productId단위로 직렬화를 보장하기 때문에, DB 업데이트 시 원자적 차감만을 이용하여 성능적 이점을 확보함public interface ProductRepository extends JpaRepository<Product, Long> { /* 코드는 남아 있으나 미사용 */ @Query(""" UPDATE Product p SET p.stock = p.stock - :qty WHERE p.id = :id AND p.stock >= :qty """) @Modifying int decreaseStockIfAvailable(@Param("id") Long id, @Param("qty") int qty); }
-
- ProductService.java
-
verifyAndDecreaseStock내부 로직 변경@Service @RequiredArgsConstructor public class ProductService { /* ... */ @Transactional public Product verifyAndDecreaseStock(Long productId, int requiredQuantity) { int updatedRows = productRepository.decreaseStockIfAvailable(productId, requiredQuantity); if (updatedRows == 0) { throw new IllegalStateException("상품 재고가 부족하거나 상품을 찾을 수 없습니다."); } return productRepository.findById(productId) .orElseThrow(() -> new ProductNotFoundException("상품을 찾을 수 없습니다.")); } }
-
테스트 성공 결과
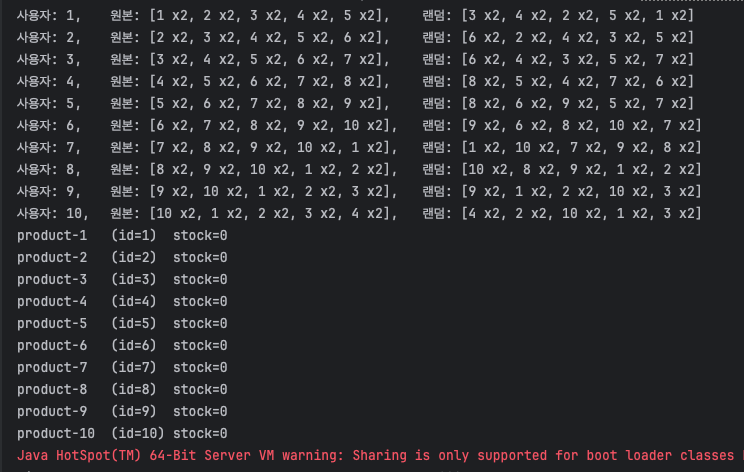
- 통합 테스트 목적에 맞게 테스트가 수행됨
- 주문된 상품 순서에 관계없이
- 모든 주문이 통과하고
- 모든 상품의 재고가 소진됨
- 순차락, 멀티락 동일하게 통과, 현재는 멀티락 적용
TestContainer 세팅
@Profile("test") 테스트 환경 세팅
- IntegrationTestContainersConfig.java
- 기존에 있던 MySQL 테스트 컨테이너와 병합
- 단일 Redis를 컨테이너에 띄우고, 기본 포트 6379로 매핑함
public static final GenericContainer<?> REDIS = new GenericContainer<>(DockerImageName.parse("redis:7.2")) .withExposedPorts(6379); RedissonClient을Bean으로 등록@Bean(destroyMethod = "shutdown") public RedissonClient redissonClient() { String addr = "redis://" + REDIS.getHost() + ":" + REDIS.getFirstMappedPort(); Config cfg = new Config(); cfg.useSingleServer() .setAddress(addr) .setConnectTimeout(10_000) .setTimeout(3_000) .setRetryAttempts(3) .setRetryInterval(1_500) .setPingConnectionInterval(1_000) .setKeepAlive(true) .setTcpNoDelay(true); return Redisson.create(cfg); }MySQL과 동일하게 종료 처리함@PreDestroy public void shutdown() { if (REDIS.isRunning()) REDIS.stop(); if (MYSQL.isRunning()) MYSQL.stop(); }- 모든 통합 테스트에
@ActiveProfiles("test")로 동작함
데이터 처리 & 캐싱 전략
조건
- 동일한 파라미터로 반복적인 조회가 발생하는 경우
- 쿼리 연산의 비용의 큰 경우
- 변경 빈도가 낮아 특정 시간동안 같은 정보를 제공해도 값이 유효한 경우
피해야 할 조건
- 명확한 캐싱 키가 없는 경우
- 쿼리 연산의 비용이 작아 캐싱의 이득이 적은 경우
- 실시간 데이터처럼, 일관성이 중요한 경우
- 쓰기 빈도가 높아 변경이 자주 발생하는 경우
캐싱 대상 서비스 판단
- 조회와 관련된 서비스 기능
- 잔액 조회 API
- 사용자 별 조회를 하더라도, 충전이나 사용이 빈번함
- 일관성이 중요한 기능으로 캐싱 불필요 판단
- 상품 조회 API
- 상품 읽기에 대한 접근은 매우 빈번하고, 상품 메타 데이터의 경우 변경이 적음(재고 제외)
- 재고값의 경우 수정이 빈번함.
- 현재 상품 테이블은 재고 테이블이 분리되어있지 않고, 조회 쿼리 비용이 높지 않음.
- ID, 이름, 가격, 재고
- 따라서, 현재는 캐싱 불필요 판단
- 상위 상품 조회 API ← 캐싱 구현
- 상품 별, 일자 별, 주문 수량 관련하여 쿼리 연산이 복잡함
- 연산을 해야하는 주문 테이블의 경우, 당일을 포함하면 주문량에 따라 변경되는 정보이지만,
- -1 ~ -3일을 기준으로 캐싱 하는 경우 하루 단위의 캐싱이 가능
- 캐싱 이점이 가장 큼
- 잔액 조회 API
Redis 기반 캐시 적용
통합 테스트 코드 및 Top Products 조회 계층 배치
-
TopProductQueryServiceTest.java
-
테스트 흐름
-
더미 상품을 6가지 생성 후 3일 치 주문 아이템 생성 저장
- 1번부터 6번까지 총 수량이 적어지는 방향으로 3일에 각각 나눠서 생성
-
웜업 1회 수행 후 20회 조회하여 요청 시간을 측정
-
반환된 결과 순위가 설정한 순위와 같은 지 확인
-
5개만 가져왔는 지 확인
@DisplayName("최근 3일(어제 ~ 그저께) Top5 상품을 Native Repository를 통해 조회한다") @Test void top5InLast3Days() { queryService.top5InLast3Days(); // 1회 수행 // 쿼리 수행 20회 기록 StopWatch sw = new StopWatch(); sw.start("top5-query-x20"); List<TopProductView> result = new ArrayList<>(); for (int i = 0; i < 20; i++) { result = queryService.top5InLast3Days(); } sw.stop(); System.out.println(sw.prettyPrint()); // 순위 검증 assertThat(result).hasSize(5); assertThat(result.get(0).soldQty()).isGreaterThanOrEqualTo(result.get(1).soldQty()); assertThat(result.get(1).soldQty()).isGreaterThanOrEqualTo(result.get(2).soldQty()); assertThat(result.get(2).soldQty()).isGreaterThanOrEqualTo(result.get(3).soldQty()); assertThat(result.get(3).soldQty()).isGreaterThanOrEqualTo(result.get(4).soldQty()); List<Long> ids = result.stream().map(TopProductView::productId).toList(); assertThat(ids).containsExactlyInAnyOrderElementsOf( productRepository.findAll().stream() .filter(p -> List.of("p1", "p2", "p3", "p4", "p5").contains(p.getName())) .map(Product::getId) .toList() ); }
-
-
seedOrderItems함수: 상품과 총량을 역으로 3일에 나눠서 주문 아이템 생성 -
persistItems함수: 상품, 수량, 생성 일자(orderedDate), 생성 시간(orderedAt)으로 1일치 주문 아이템을 횟수만큼 생성
-
-
조회용 도메인 분리
analytics- 엔드포인트가 /products/top 이지만, 실제 사용하는 정보는 OrderItem을 사용함.
- OrderFacade나 ProductService에 넣지 않고, 별도로 분리.
- 최초
Product도메인에 있었던ProductStatistics를 제거하고, 상위 판매 상품 조회용 도메인을 분리함. JPA repository가 아닌Native repository로 조회용 쿼리만 수행.
-
레이어 배치만 수행한 후 테스트 코드 컴파일만 통과하도록 임시 함수로 구현함(빈 배열 반환)
상품 조회 로직 구현
-
TopProductNativeRepository.java
-
시작일자, 종료일자, 획득할 상품수를 받아 상위 상품 목록을 반환하는 함수 구현
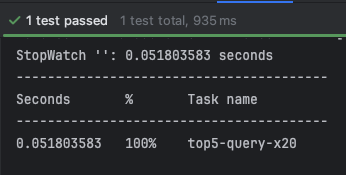
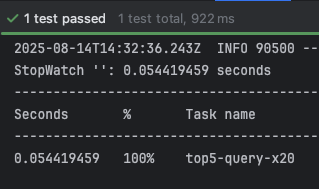
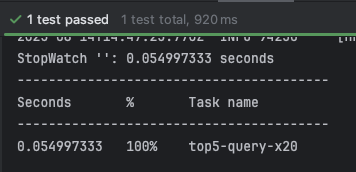
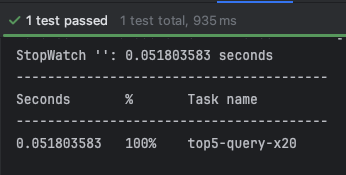
- 테스트 수행 결과
- 0.051 ~ 0.055 초 측정됨
- 테스트 수행 결과
-
Cache 환경 설정
- RadissonCacheConfig.java
- cacheManager 를 Bean으로 등록하여 cacheName 별 TTL 설정
- CacheNames.TOP_PRODUCTS는 자정을 기준으로 초기화 하기 위해, 캐시된 시간으로부터 자정 + 지터값을 적용하여 TTL에 설정, maxIdleTime은 0으로 비활성(자정까지 유지)
- CacheNames.java: cacheName 상수
- CacheKey.java
- 캐시 키 ENUM 값
- "CACHE:TOP_PRODUCTS", "CACHE:PRODUCT", "CACHE:BALANCE"처럼 고정된 Prefix를 Enum 상수로 정의.
- key(Object... parts) 메서드로 prefix 뒤에 여러 파라미터를 붙여 최종 캐시 키 문자열 생성.
- CacheKey.TOP_PRODUCTS.key("LAST_N_DAYS", 3, "TOP", 5) → "CACHE:TOP_PRODUCTS:LAST_N_DAYS:3:TOP:5"
캐싱 구현
-
-
@CacheConfig(cacheNames = CacheNames.TOP_PRODUCTS)클래스 레벨 지정하여, 각 함수에서 생략 -
기본 기능
top5InLast3Days는 확장 가능한topNLastNDays함수를 호출하되, 클래스 내부에서 호출하므로, 각각@Cacheable을 적용 -
top5InLast3Days는 3일 5개로 고정된 키 발행,topNLastNDays는 파라미터에 의해 발행 -
@EnableCaching으로 캐싱 활성화,Bean으로 등록된RedissonCacheConfig>cacheManager로 TTL 적용@Service @RequiredArgsConstructor @Transactional(readOnly = true) @CacheConfig(cacheNames = CacheNames.TOP_PRODUCTS) public class TopProductQueryService { private final TopProductNativeRepository repository; @Cacheable( key = "T(kr.hhplus.be.server.common.cache.CacheKey).TOP_PRODUCTS" + ".key('LAST_N_DAYS', 3, 'TOP', 5)", sync = true ) public List<TopProductView> top5InLast3Days() { return topNLastNDays(3, 5); } @Cacheable( key = "T(kr.hhplus.be.server.common.cache.CacheKey).TOP_PRODUCTS" + ".key('LAST_N_DAYS', #days, 'TOP', #limit)", sync = true ) public List<TopProductView> topNLastNDays(int days, int limit) { if (days <= 0) throw new IllegalArgumentException("days 는 1 이상이어야 합니다."); if (limit <= 0) throw new IllegalArgumentException("limit 는 1 이상이어야 합니다."); LocalDate today = LocalDate.now(); // 오늘을 제외하고, LocalDate from = today.minusDays(days); LocalDate to = today.minusDays(1); return repository.findTopSoldBetween(from, to, limit); } }-
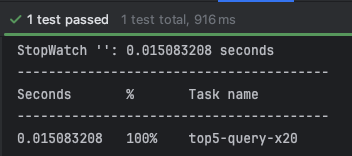
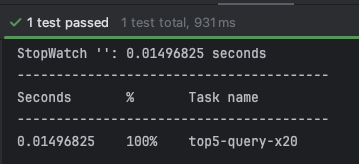
-
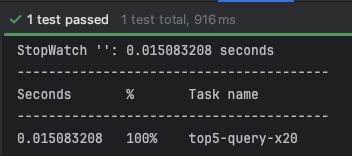
테스트 수행 결과
- 0.014 ~ 0.015 초 측정됨
- 테스트 코드 상에 1회 웜업 진행 후 20회를 측정함
-
-
캐싱 테스트 수행 결과 비교
캐싱 전
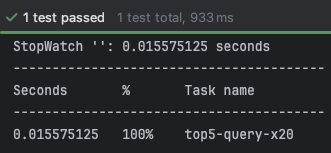
캐싱 후
결과
- 20회 시행 결과 평균 0.054초에서 평균 0.015초로 개선됨(약 70% 개선)
- 호출 시행 횟수가 많아질수록 절감 폭이 누적되어 더 큰 향상이 기대됨
마치며
- 이번 주차도 2일 정도를 테스트 환경 세팅하는데 소비했습니다. 안해도 되는 작업이었는데, 무지했던 상태라서 해야하는 줄 알고 잘못 접근했습니다.
- 그래도 적절히 남은 시간으로 필요한 것들만 잘 구현했다고 느껴지는 과제였습니다.
- Redis를 직접 구현해서 사용하는게 처음이었는데, 구현은 의외로 별것 아니었다는 것과 오히려 docker 쪽 세팅이 더 시간이 소요되는 작업이었다는 것을 알게 되었습니다.
- 현업에서 아직 락 개념이 적용된 로직이 없어서 바로 사용하진 않겠지만, 적어도 어떻게 세팅하고 쓰는 지 알게되는 과정이어어서 좋았습니다.
