
웹 크롤링(Web crawling)
- 봇이 많은 웹사이트들을 돌아다니면서 URL, 키워드 등을 수집하는것
- 검색 엔진에서 웹사이트를 수집하기 위해 사용된다.
웹 스크래핑(Web scraping)
- 웹 사이트에서 필요한 데이터를 긁어오는 것
파이참 설치하기
- 구글에서 파이참 검색
- 파이참 커뮤니티 버전 다운도르
- 프로젝트 생성
HTML 구조의 이해
HTML은?
- Hyper Text Markup Language 약어로 웹페이지를 위한 언어
HTML 구조
- 태그로 입력

웹페이지의 구조

requests 모듈
- 파이썬에서 HTTP 호출할때 사용되는 대표적인 라이브러리
- 설치방법 : pip install requests
웹페이지 접근할때 REST API 방식으로 접근할때 4가지 방식
- GET 방식 : requests.get(웹페이지 주소) <서버에서 무조건 요청해서 받을때>
- POST 방식 : requests.post(웹페이지 주소) <웹페이지로 내 정보를 전달할때>
- PUT 방식 : requests.put(웹페이지 주소) <수정할때>
- DELETE 방식 : requests.delete(웹페이지 주소) <삭제할때>
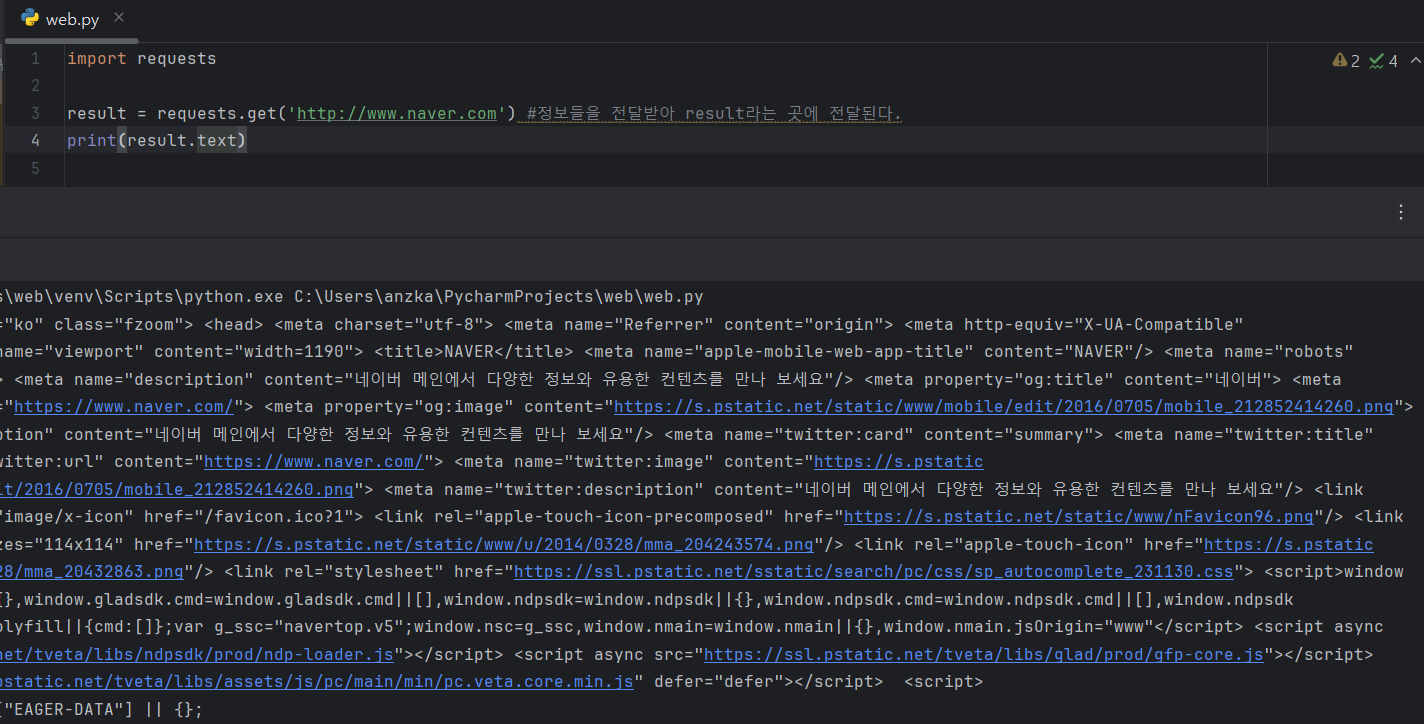
HTML 정보 가져오기
Beautifulsoup 라이브러리
- 의미있는 라이브러리들을 긁어올수 있는 라이브러리
- HTML, XML,JSON 등의 구문을 분석하는데 사용되는 모듈
- BeautifulSoup 설치 : pip install beautifulsoup4
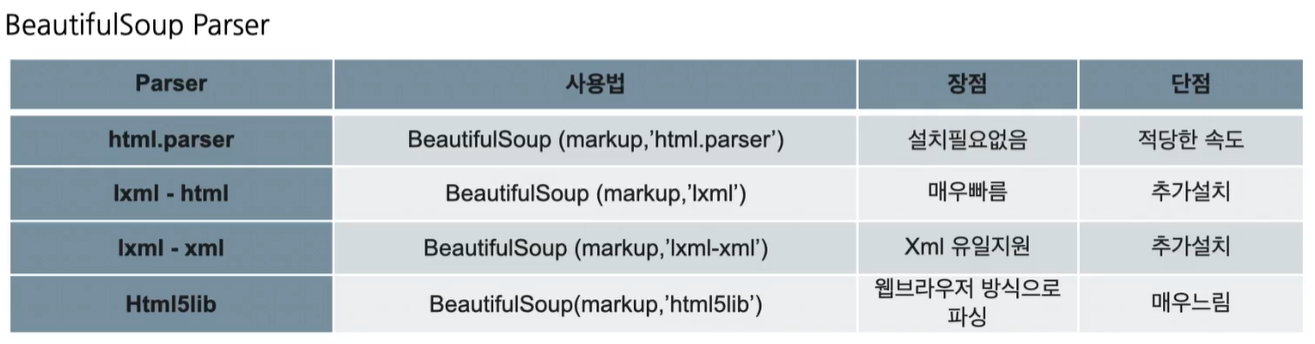
- BeautifulSoup Parser : 구문 분석할때 파싱해주는 것
- 사용방법
- 검색할때 참고할 명령어들


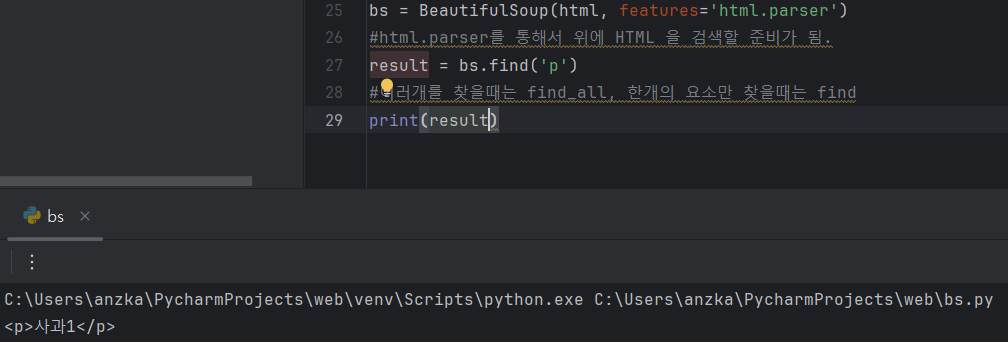
- find로 하나만 찾아서 가져와보기
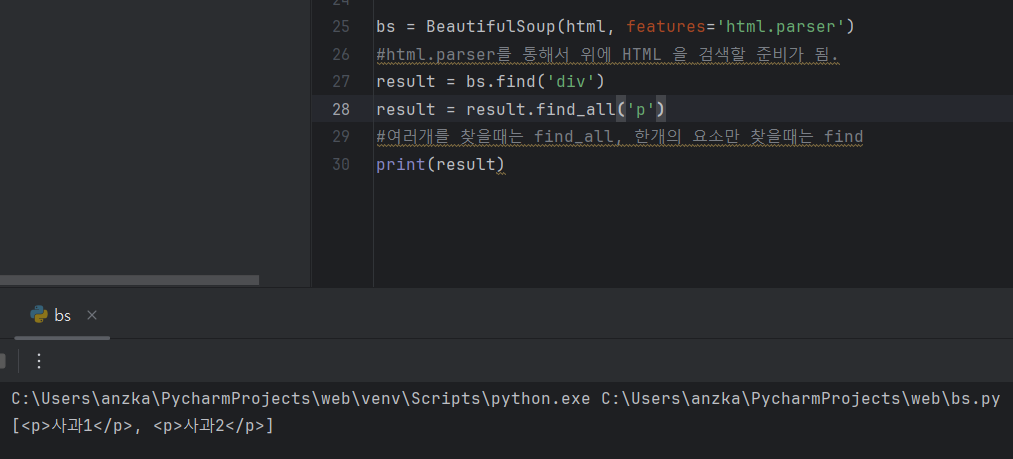
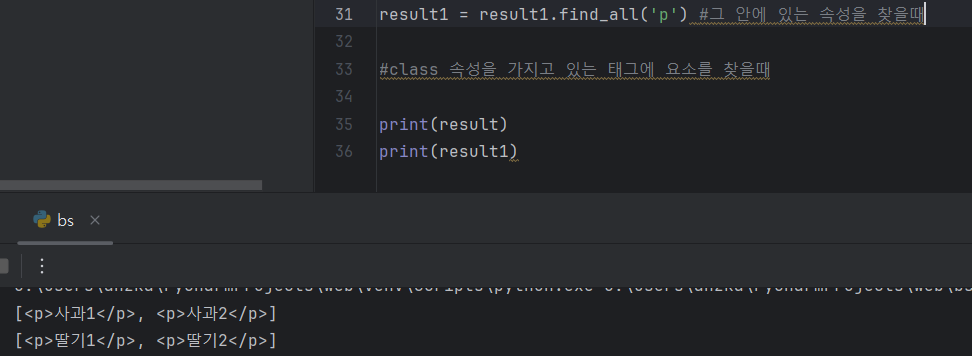
- find_all로 검색한것 전부다 가져와보기(list형태로 출력됨)
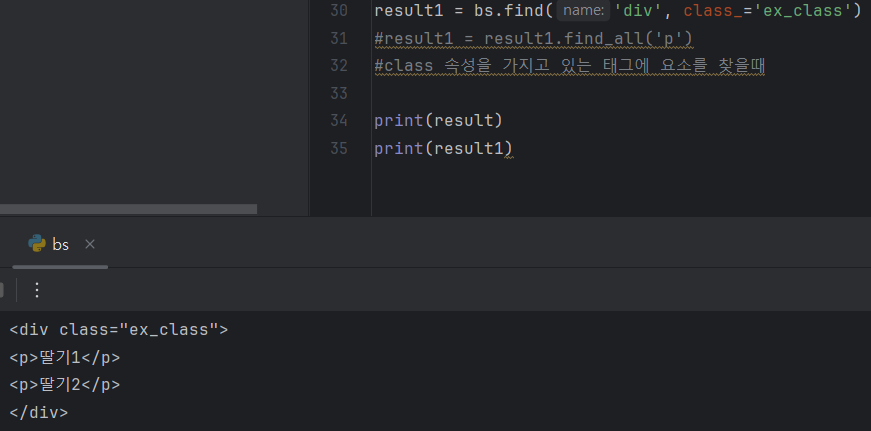
- class 속성을 가지고 있는 태그에 요소를 찾을때
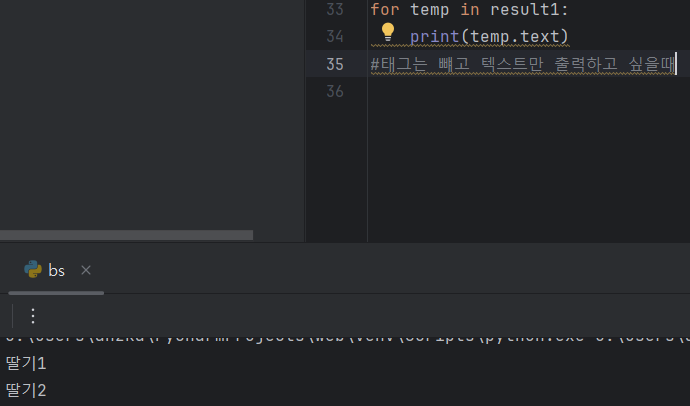
- 태그 빼고 텍스트만 출력해보기
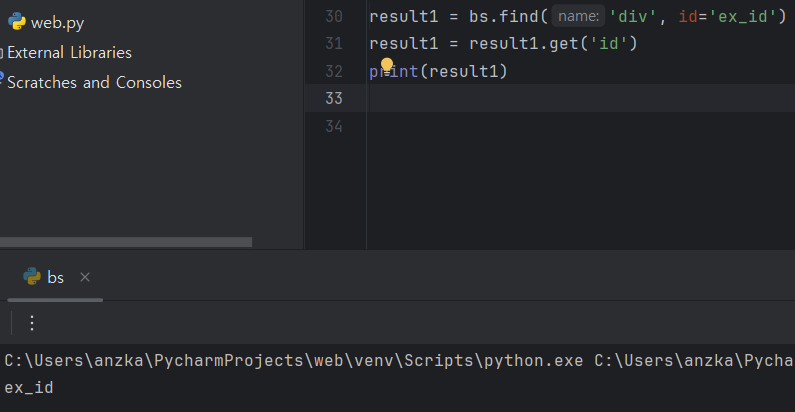
※ get이라는 명령어로 특정태그의 값을 가지고 올수 있다.
네이버 도서 순위 스크래핑
- 인터넷 웹페이지 주소를 복사

- 주소 불러와서 텍스트로 출력
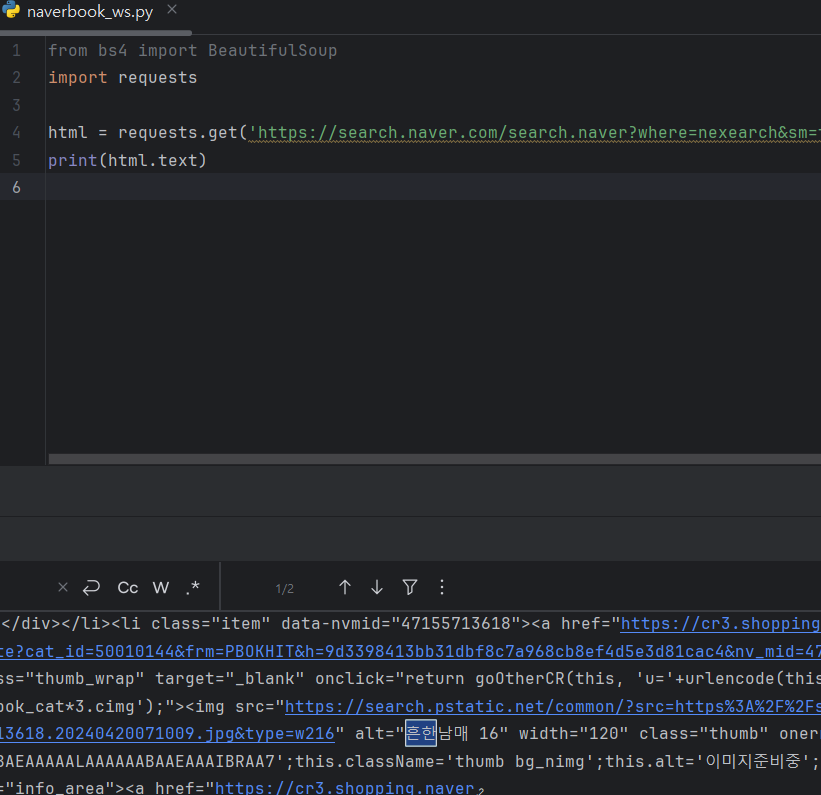
- 텍스트중 내가 원하는 정보 찾기
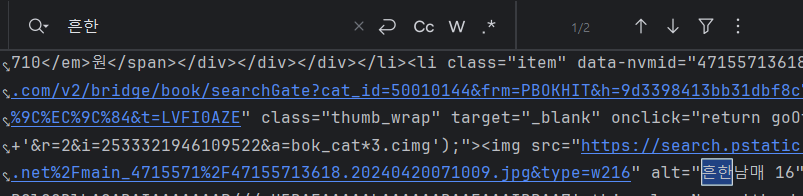
- 웹페이지안에서 개발자도구로 찾아올 요소들 검색
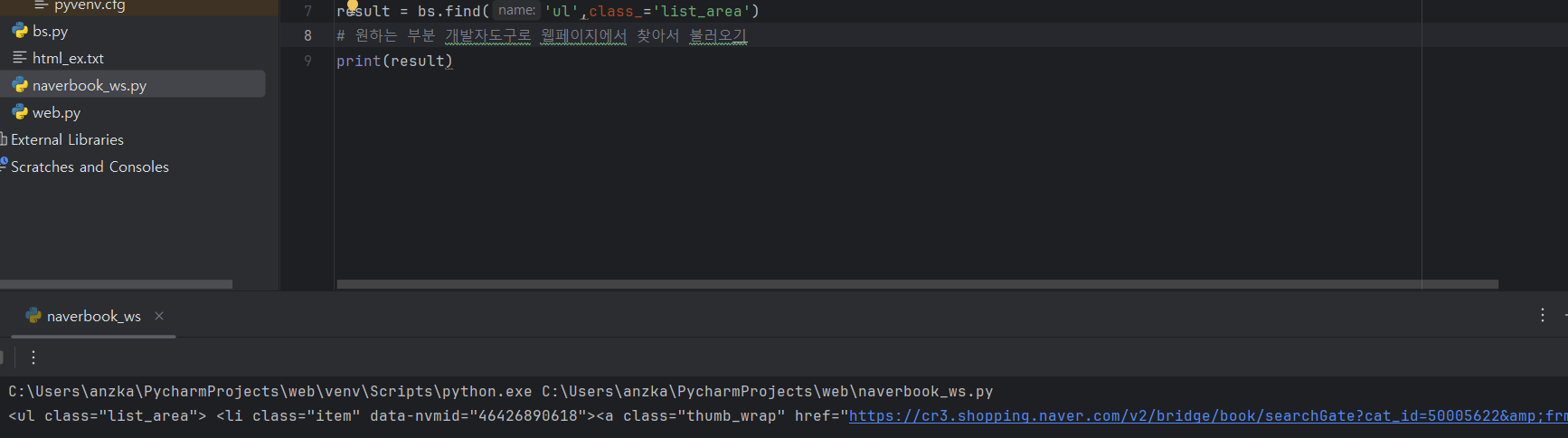
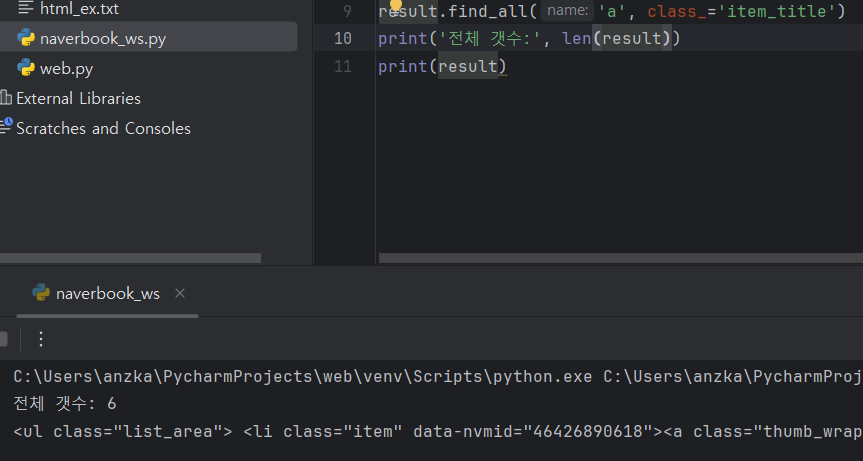
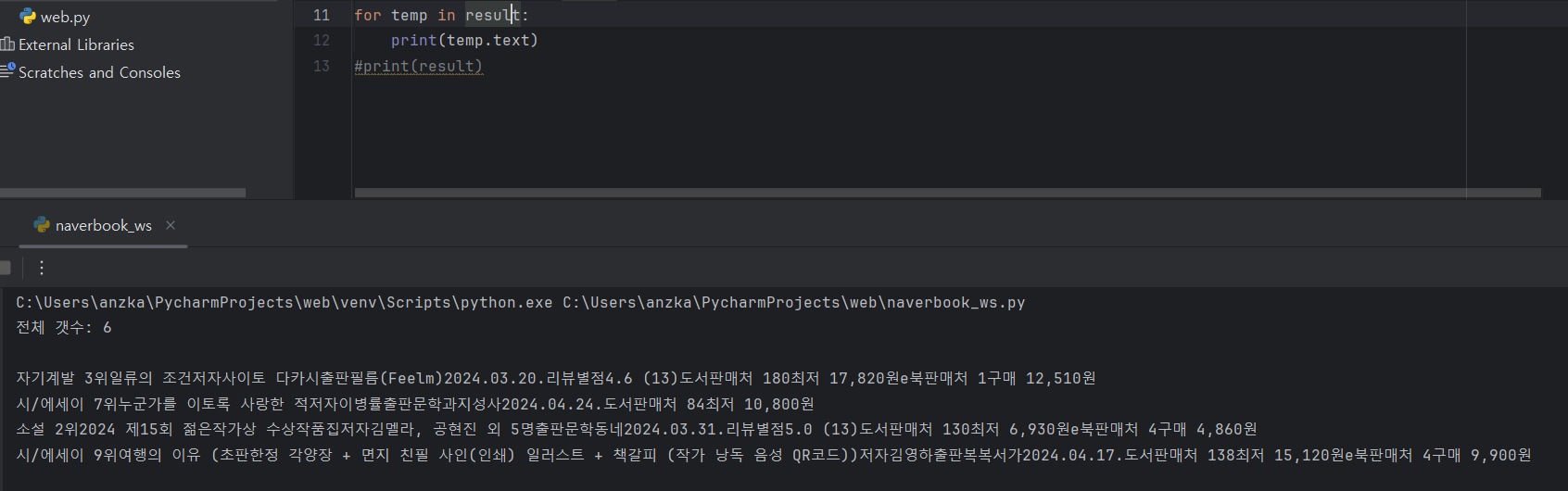
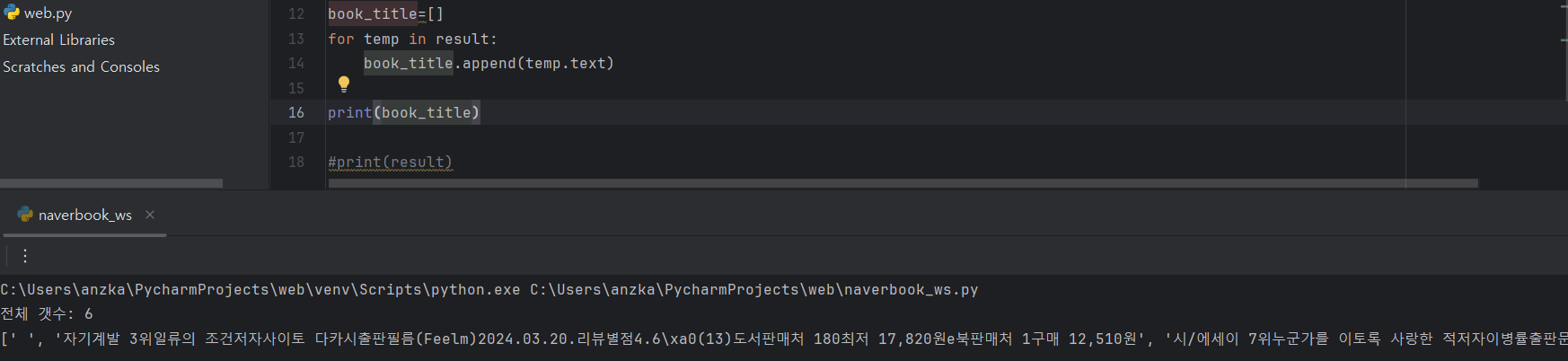
- 찾은 요소 안에서 책 이름과 갯수 찾아보기
- 다른 정보 없이 반복문 사용해서 책의 이름들만 가져와보기

개발자 기록 끄적