
정수인코딩
- 텍스트 데이터를 숫자로 변환하는 과정
- 자연어 처리에서 텍스트 데이터를 그대로 사용할 수 없음
-텍스트 데이터를 수치 데이터로 변환하여 연산을 수행- 텍스트 데이터를 정수로 인코딩하면, 각 단어를 고유한 값으로 대응
-고유한 값으로 대응시키면, 모델이 단어를 구분할 수 있음- 정수 인코딩을 사용하면, 각 단어의 빈도수계산에 용이함
-모델이 학습할 때 단어의 빈도수를 고려하여 가중치를 조절가능- 정수 인코딩은 단어의 유사도계산등에 사용
-단어 간의 거리를 계산하여 가까운 단어들끼리 그룹화하거나, 유사한 단어를 찾을 때 사용
분석해서 정수 인코딩 할 데이터 준비

인코딩 원리(명사기준)

- konlpy 필요
- 명사추출을 하려면 Okt 필요
- 명사추출
- 빈도수 알아보기(딕셔너리형태 Key와 value)
- 반복문과 조건문 사용해서 2번이상 나온 단어들만 사용해보기
- 가장 많이 나온 단어부터 적게 나온 단어순으로 정렬해보기(lambda함수 사용)
- 빈도수가 많은 순으로 인덱스 순서를 정해보기
- 만들어놓은 사전을 가지고 하나의 문장을 정수 인코딩 해서 나타내보기
단어들에 해당하는 것을 정수 인코딩


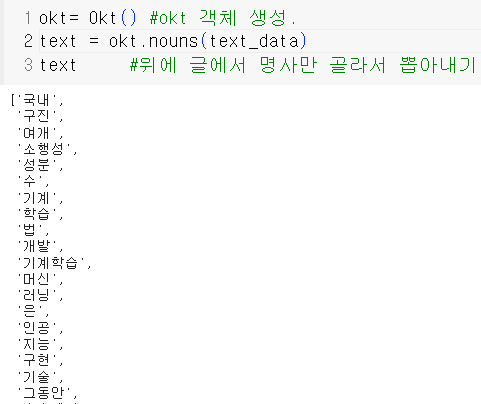






명사로 나누어 놓은것을 만들어 놓은 사전에 있는 인덱스에 맞는게 있다면 정수 인코딩으로 표현할 수 있다.
케라스
- 케라스를 사용하면 복잡한 단어사전 만드는 과정을 케라스를 통해 자동으로 만들수 있다.
분석해서 정수 인코딩 할 데이터 준비
- konlpy 필요
- keras 임포트(Tokenizer를 사용하는 이유)

- 명사만 추출

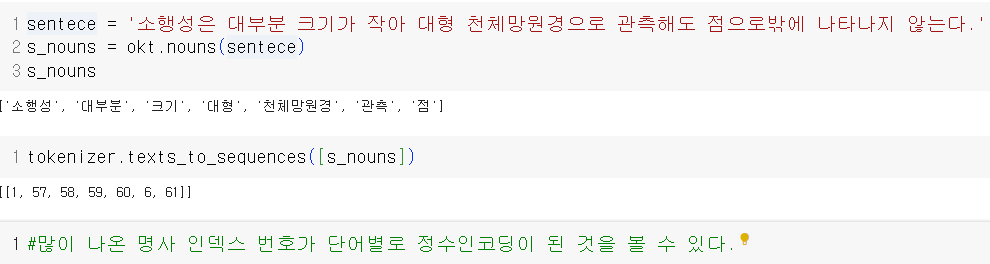
- Tokenizer 사용

- 정수인코딩 해보기

개발자 기록 끄적