
🍕Pandas란?
- 데이터 분석에 관련된 기능을 제공하는 파이썬 라이브러리
- 큰 데이터를 빠르게 처리(indexing, slicing, sorting 등)
- 데이터들의 연산
- 외부데이터 ( csv, txt, excel등) 의 처리
- 설치 : cmd -> pip install pandas 입력
- pands.pydata.org 들어가서 pands의 기능들에 대해 공부하고 숙지하기
series : pandas 를 구성하는 자료형(1차원 자료형)
series list, numpy, tuple, dict 생성


🧨Series는?
- index, value 형태로 구성되어 있다.
- 데이터타입 확인 방법은 dtype으로 확인 가능
- Series는 연산이 가능하다.
- 1차원 자료형
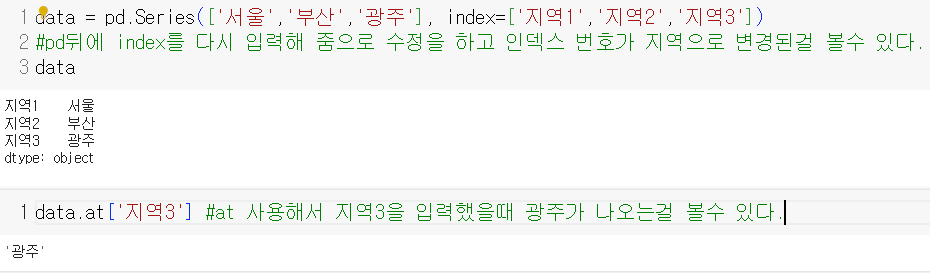
index 수정 , 조회
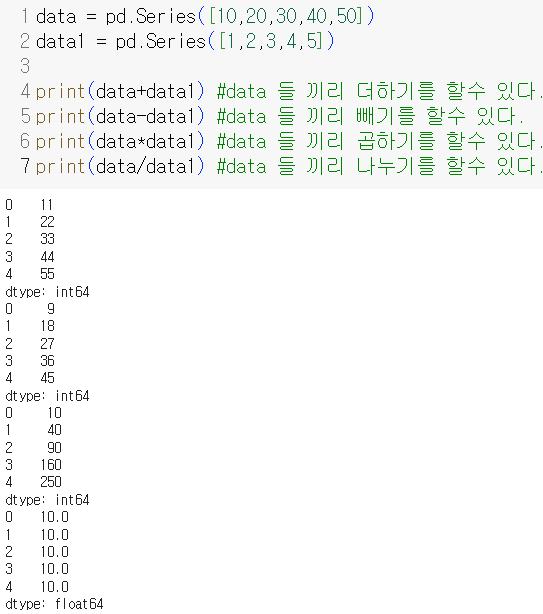
Series연산

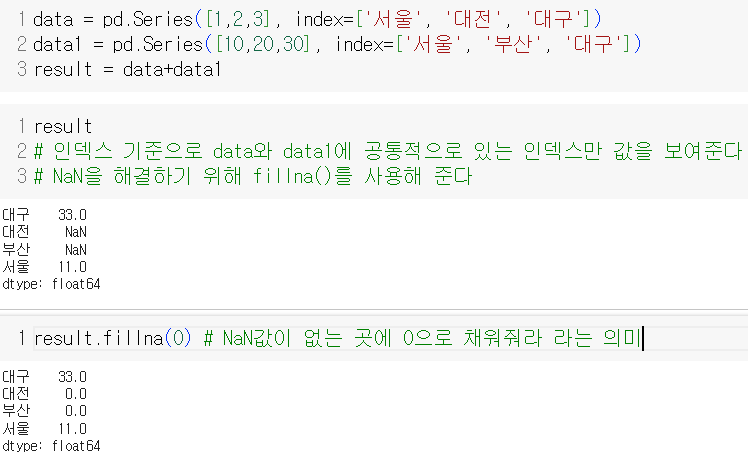
fillna():NaN처리
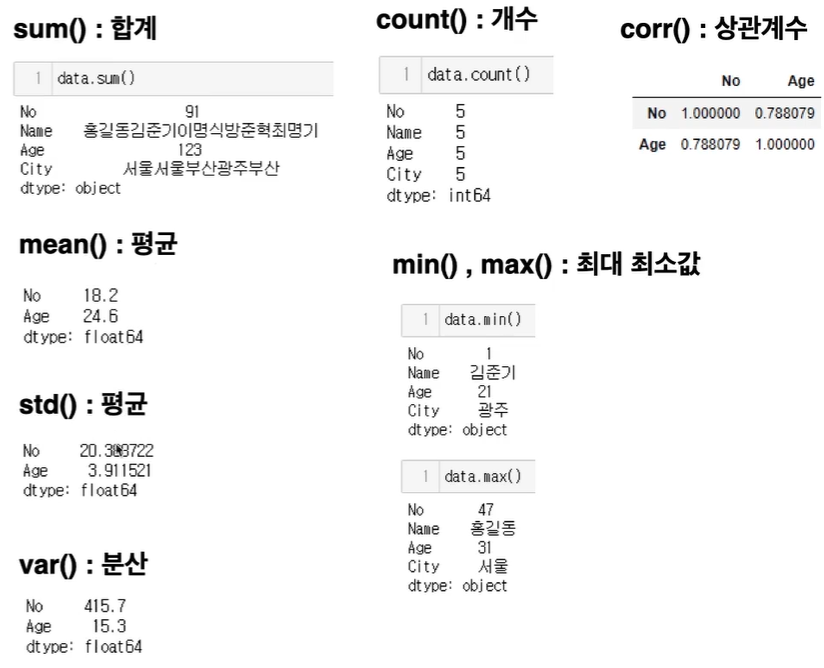
describe() : 통계정보

🧨DataFrame
- 2차원 데이터
- Series 자료형을 테이블 형태로 표현
- from pandas import Series, DataFrame
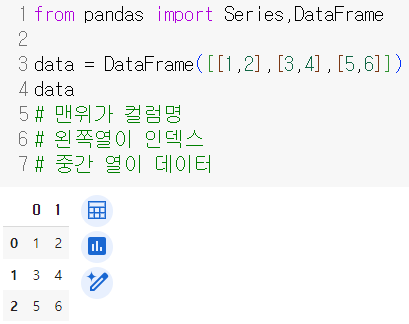
DataFrame 생성방법
- 리스트를 활용한 생성
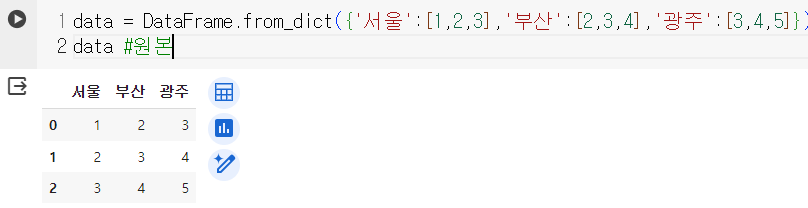
- 딕셔너리를 활용한 생성

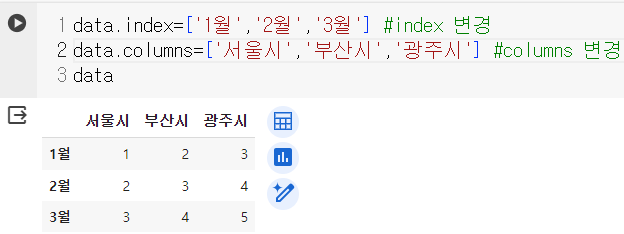
- index, column 설정

- index, column 변경
- 데이터조회 : 컬럼명 방법
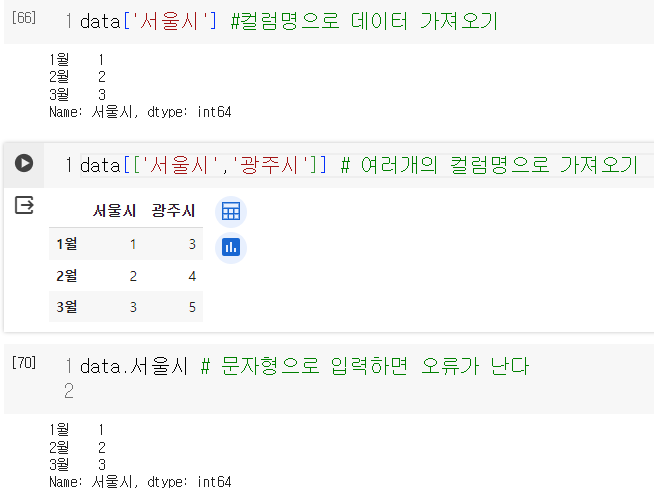
- 데이터조회 : 인덱스

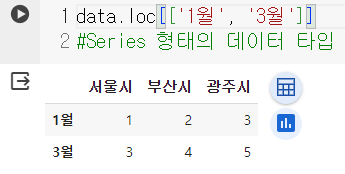

- 데이터조회 : 인덱스, 컬럼 동시사용



DataFrame 합치기
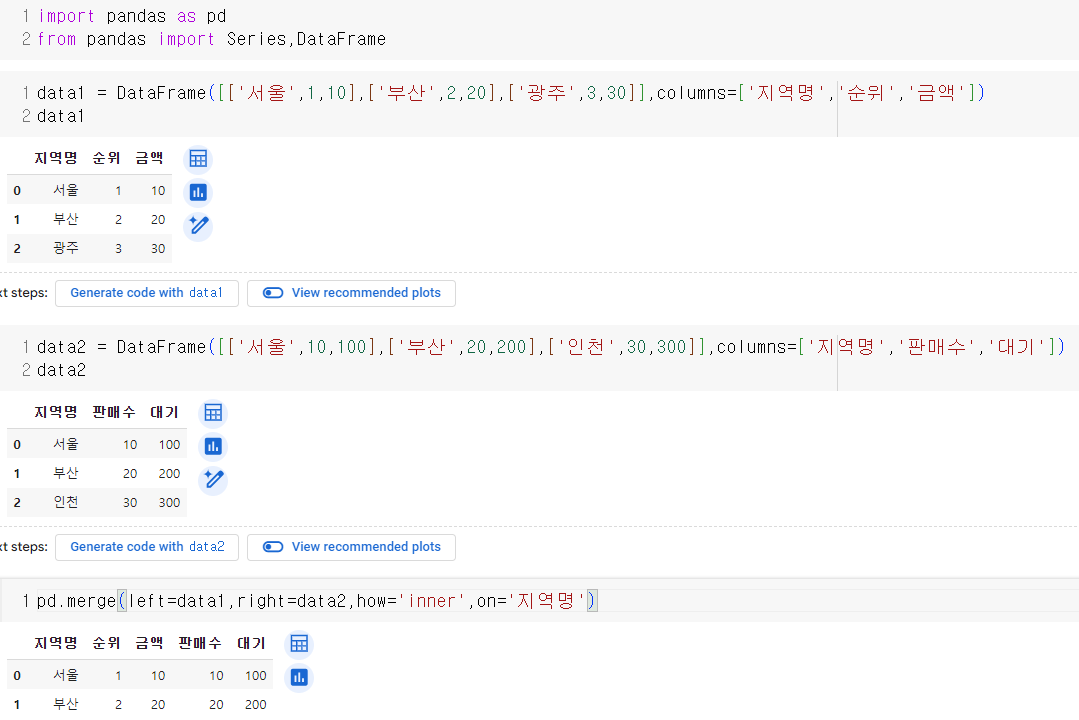
merge
- pd.merge(left,right,how,on)
- left : 합칠 왼쪽 데이터프레임
- right : 합칠 오른쪽 데이터플임
- how : inner, left, right, outer
- on : 두 데이터를 합칠 기준 컬럼
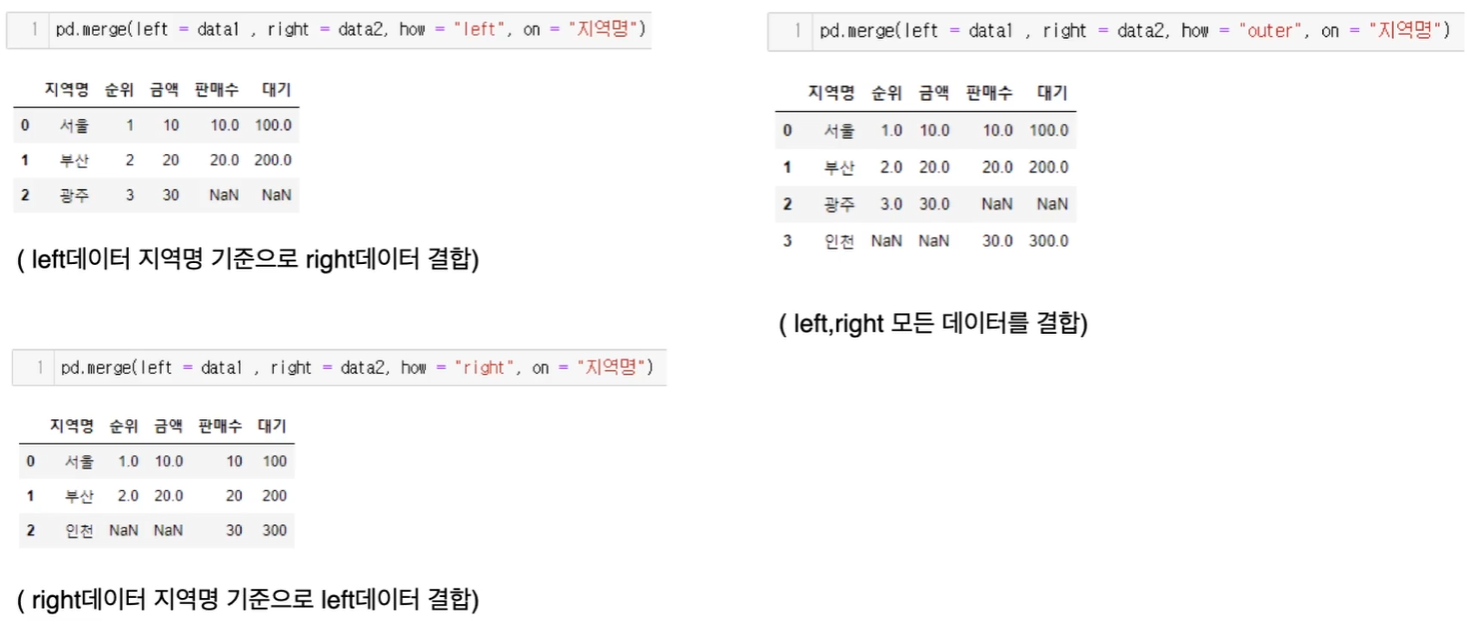
how옵션
- inner : left,right에서 둘다 존재하는 컬럼 데이터만 합침
- left : left 데이터 프레임 기준으로 합침
- right : right 데이터프레임 기준으로 합침
- outer : left, right의 모든 data합침
🍟merge를 이용
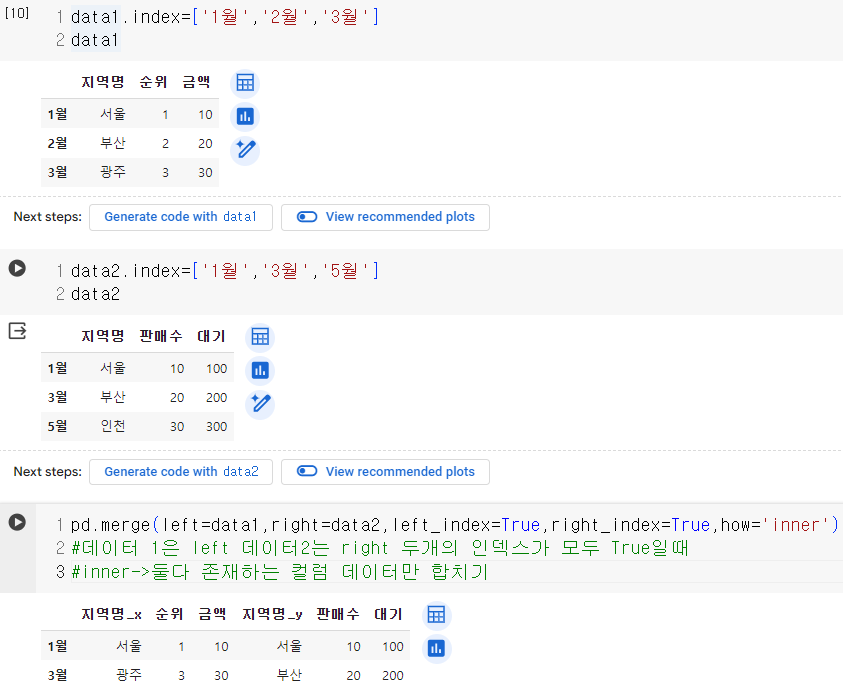
🍟index 기준으로 결합
DataFrame 연산

DataFrame 파일처리(매우 중요)
csv불러오기
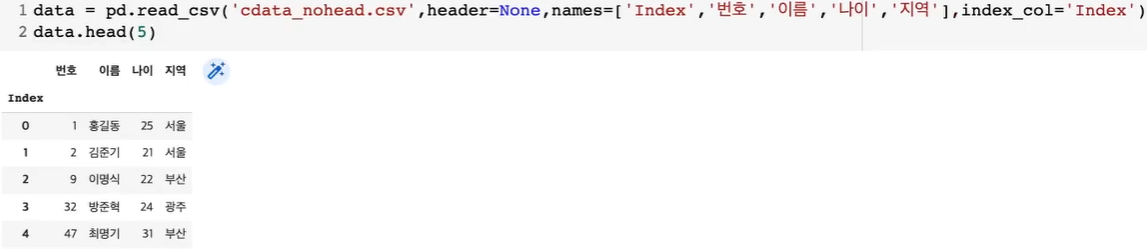
- pd.read_csv(FilePath, sep, header, names, index_col,skiprows, nrows, encoding)
- FilePath : 파일경로, sep: 구분자, header(컬럼명) : 없을경우 none
- names : header가 없을 시 컬럼명 입력가능, skiprows : 파일에서 행을 건너뛰고 불러옴
- index_col : 컬럼을 index로 사용, nrows : 입력한 개수만큼의 데이터만 읽음
- encoding : 인코딩 타입 입력, 데이터가 한글이면 'CP949'
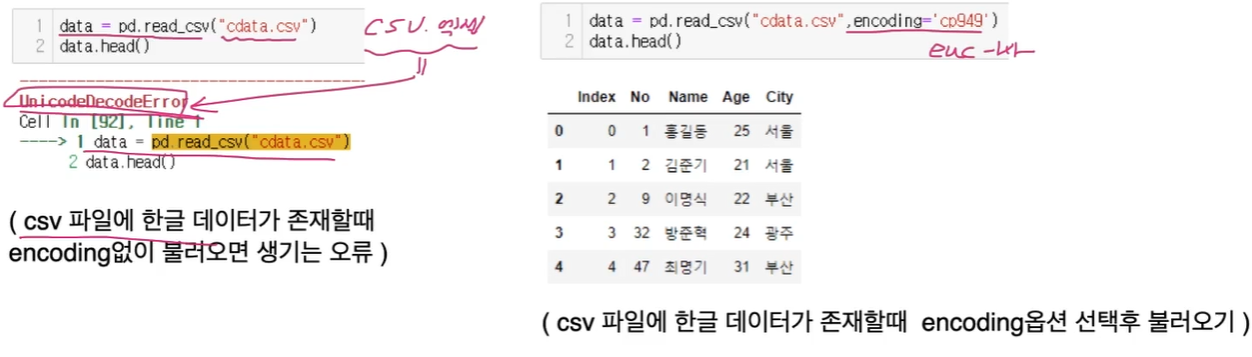
csv를 불러오기 및 작성연습
- data = pd.read_csv('data1.csv')
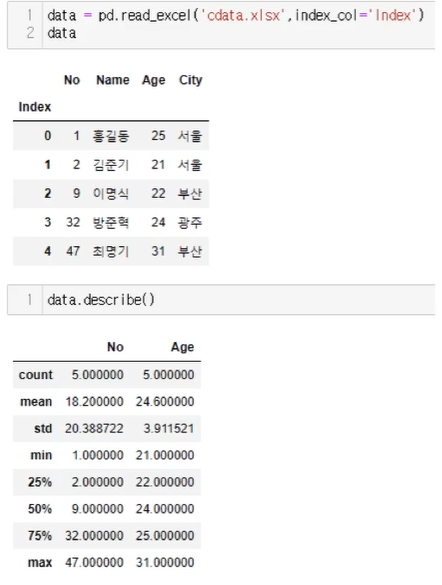
DataFrame 통계
- describe() : 통계 요약(데이터 개수, 평균, 표준편차, 최소값, 4분위값, 최대값)
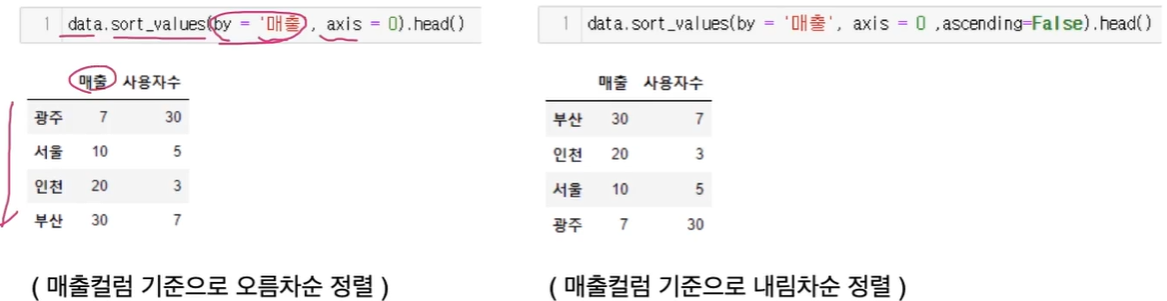
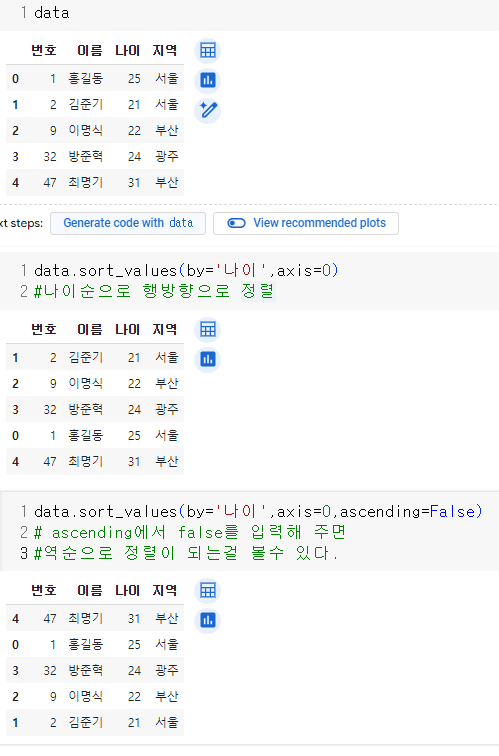
sort_value() : 정렬
- ascending : True - 오름차순, False - 내림차순 정렬
- inplace : True 이면 정렬한 값을 DataFrame에 바로 반영
- by : 정렬할 기준 변수
- axis : 0 - 행방향 정렬, 1= 열방향 정렬
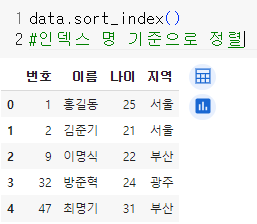
sort_index() : index명 기준으로 정렬
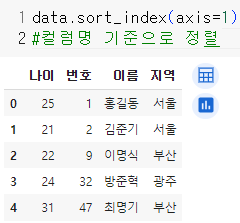
컬럼명 기준으로 정렬
※ pandas.pydata.org 들어가서 user guide에 들어가서 꼭꼭 익히면서 공부하기

개발자 기록 끄적