Convolutional Neural Networks(합성곱 신경망)
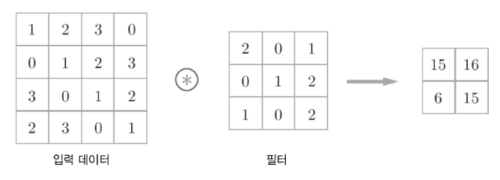
Convolution예전부터 컴퓨터 비전(Computer Vision)분야에서 많이 쓰이는 이미지 처리 방식으로, 입력데이터와 필터의 각각의 요소를 서로 곱한 후 다 더하면 출력값이 나오는 방식.
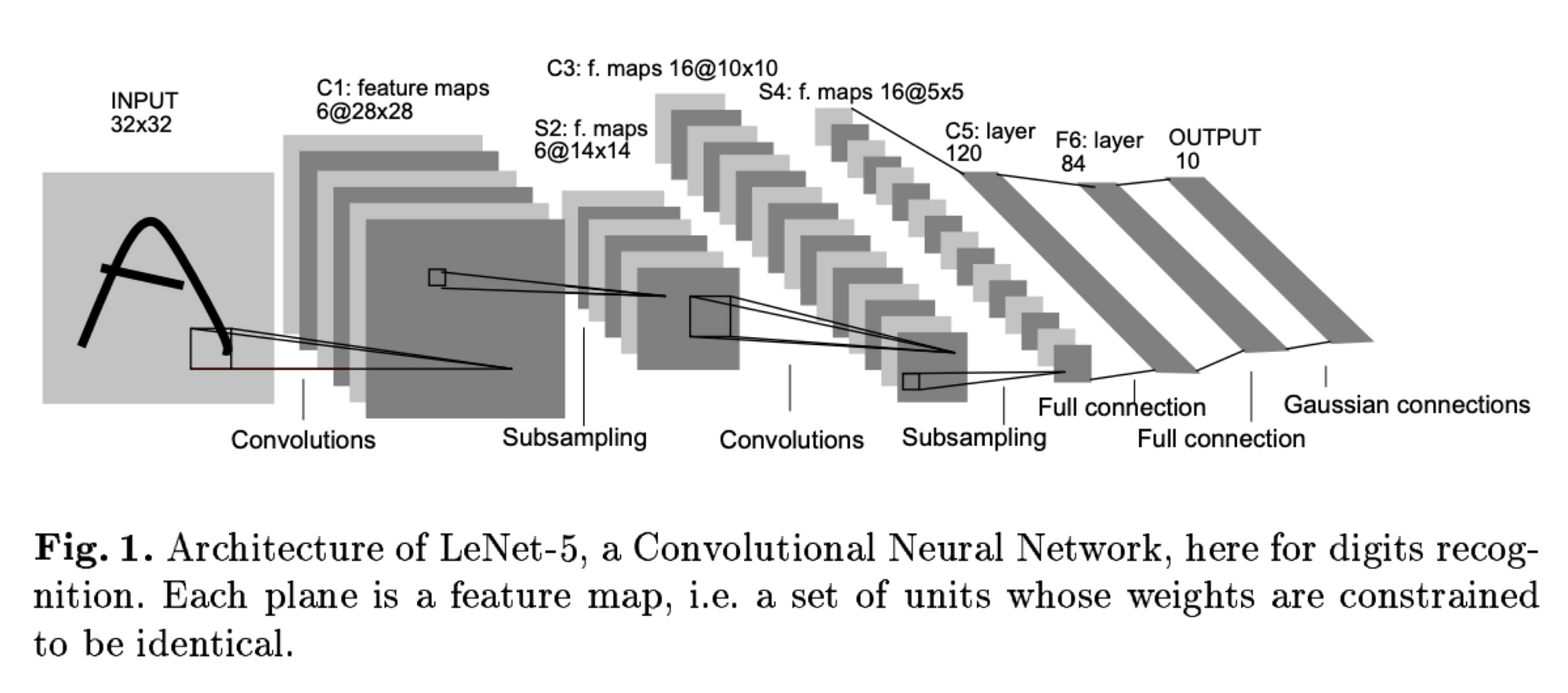
르쿤 교수는 합성곱을 이용한 이 신경망 디자인을 합성곱 신경망(CNN)이라고 명칭하였고,
이미지 처리에서 엄청난 성능을 보이는 것을 증명했는데, CNN의 발견 이후 딥러닝은 전성기를 이루었다고 볼 수 있다.
이후 CNN은 얼굴 인식, 사물 인식 등에 널리 사용되며 현재도 이미지 처리에서 가장 보편적으로 사용되는 네트워크 구조이다.
Filter, Strides and Padding
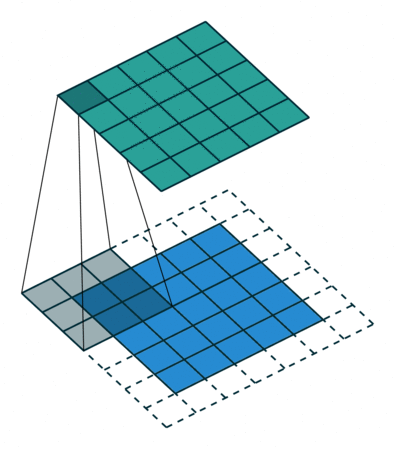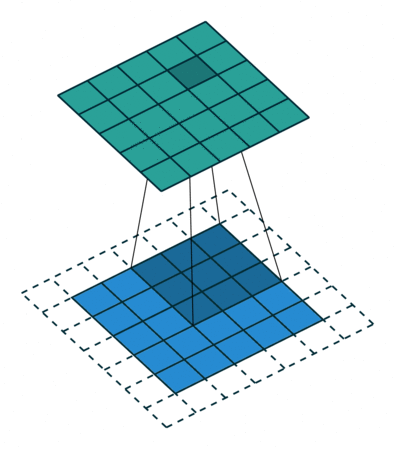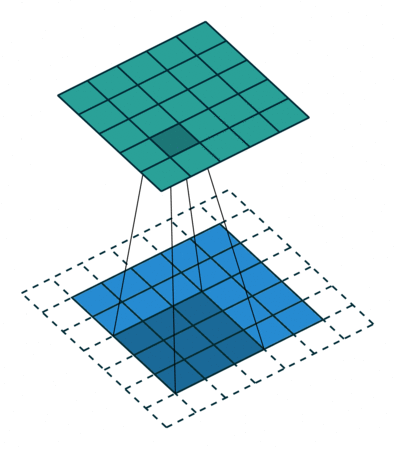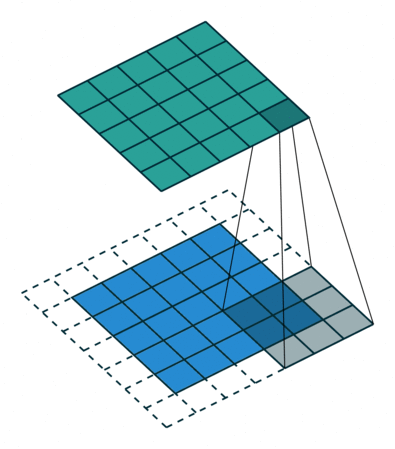
아래와 같이 5x5 크기의 입력이 주어졌을 때, 3x3짜리 필터를 사용하여 합성곱을 하면 3x3 크기의 특성맵(Feature map)을 뽑아낼 수 있다.
필터(Filter 또는 Kernel)를 한 칸씩 오른쪽으로 움직이며 합성곱 연산을 하는데, 이 때 이동하는 간격을 스트라이드(Stride)라고 한다.
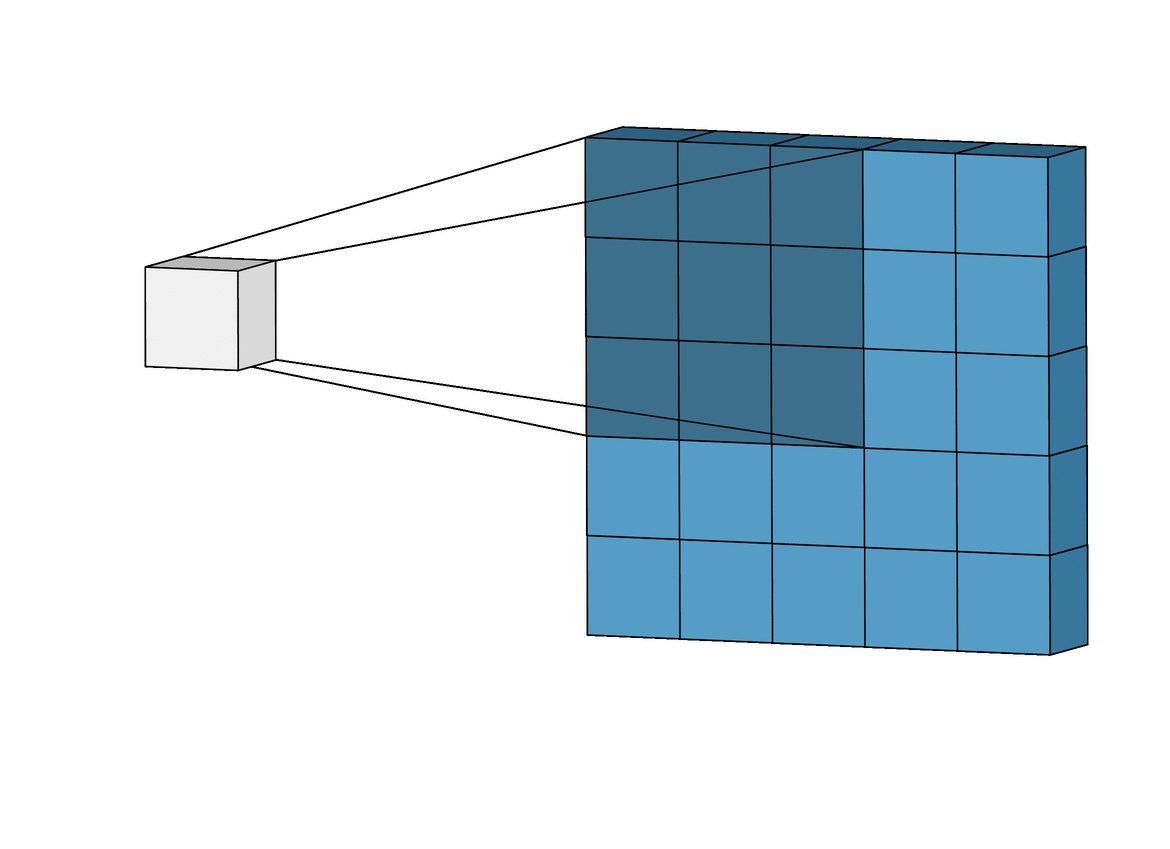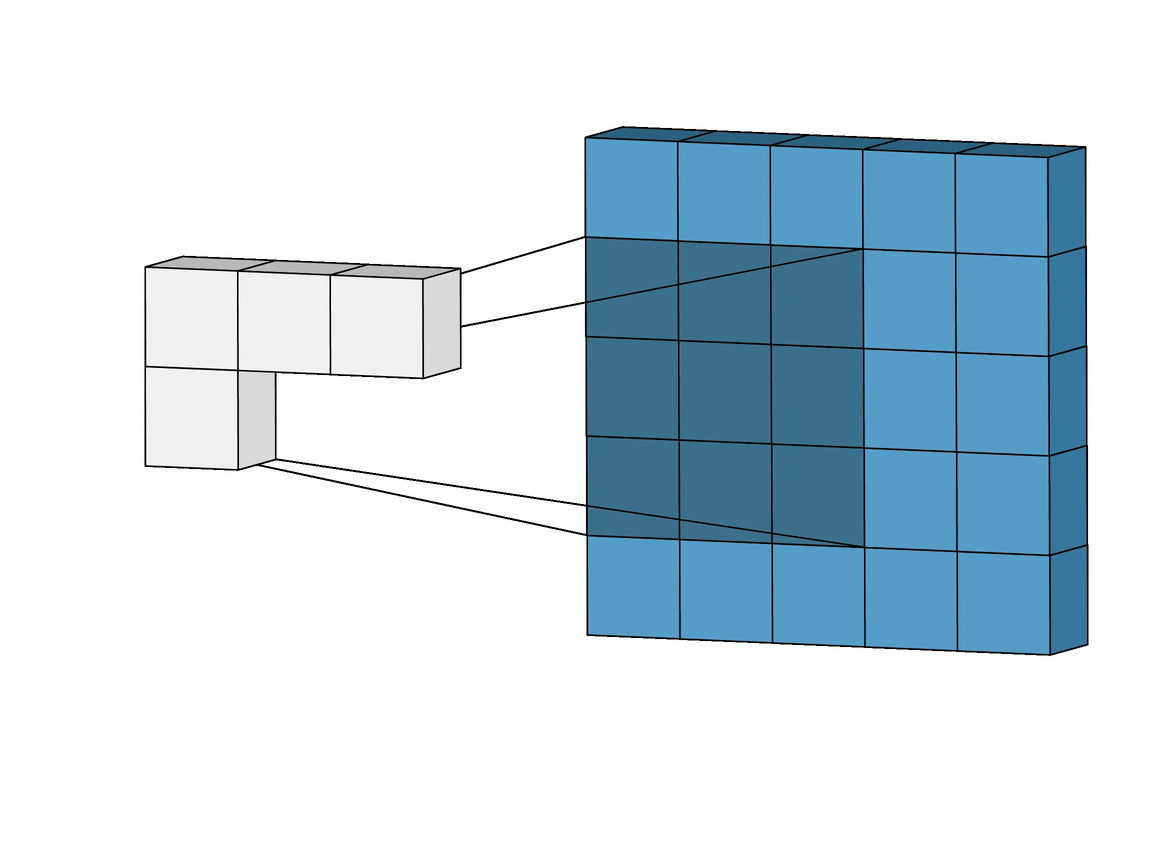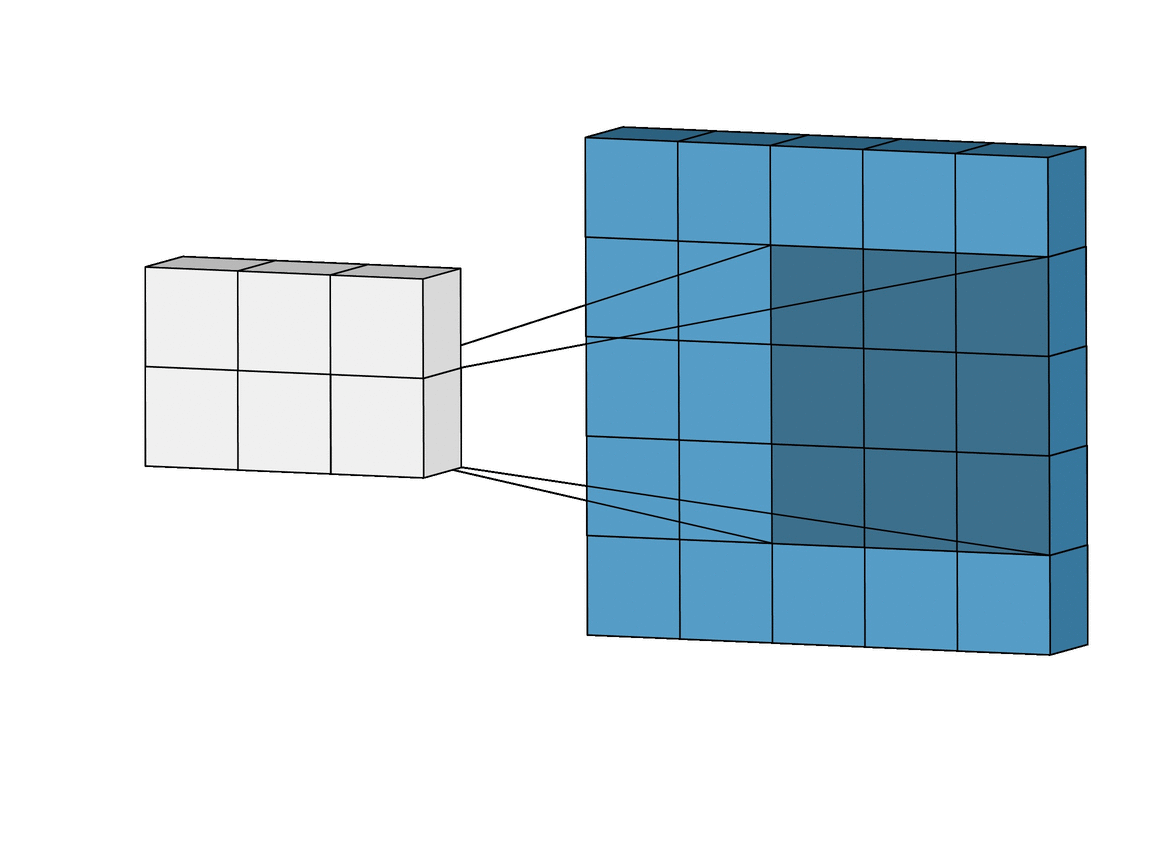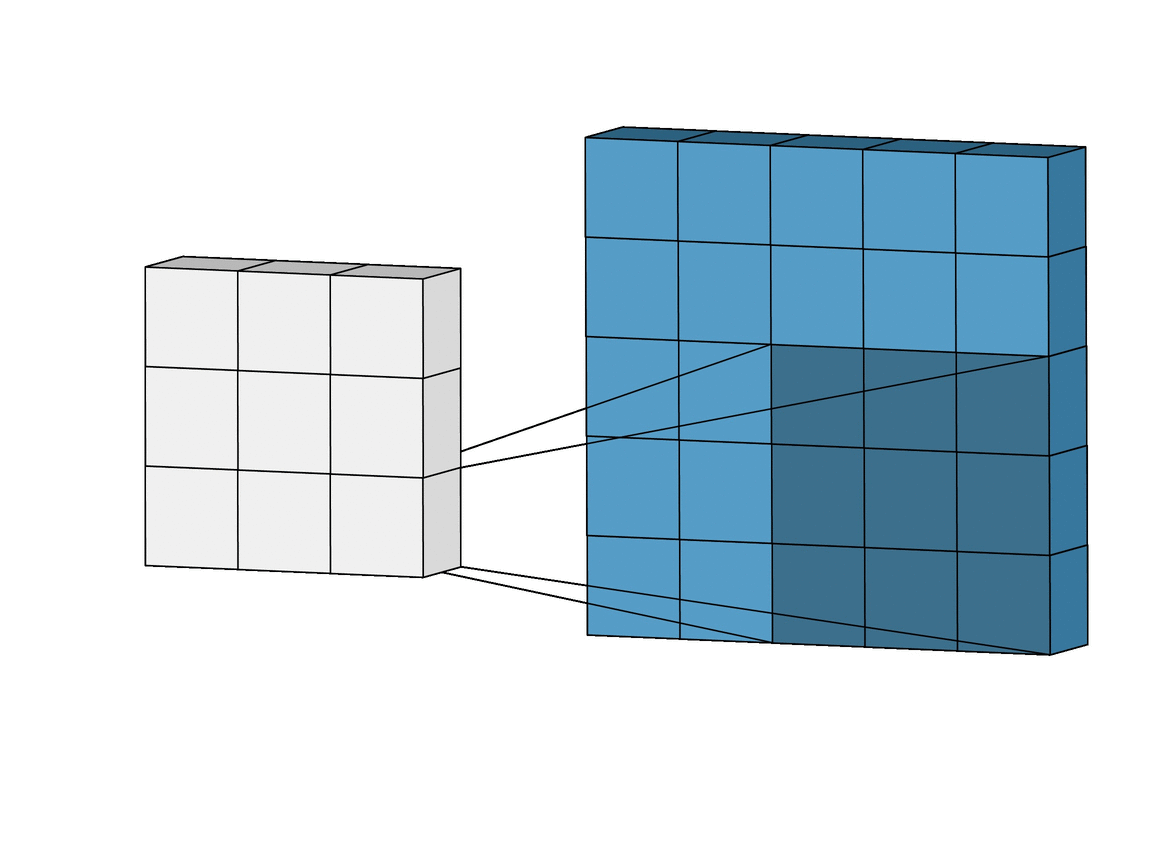
그런데 이렇게 연산을 하게 되면 합성곱 연산의 특성상 출력값인 특성 맵의 크기가 줄어든다. (위의 사진의 결과, 5x5 ➡️ 3x3)
이런 현상을 방지하기 위해서 우리는 패딩(Padding 또는 Margin)을 주어, 스트라이드가 1일 때 입력값과 특성 맵의 크기를 같게 만들 수 있다.
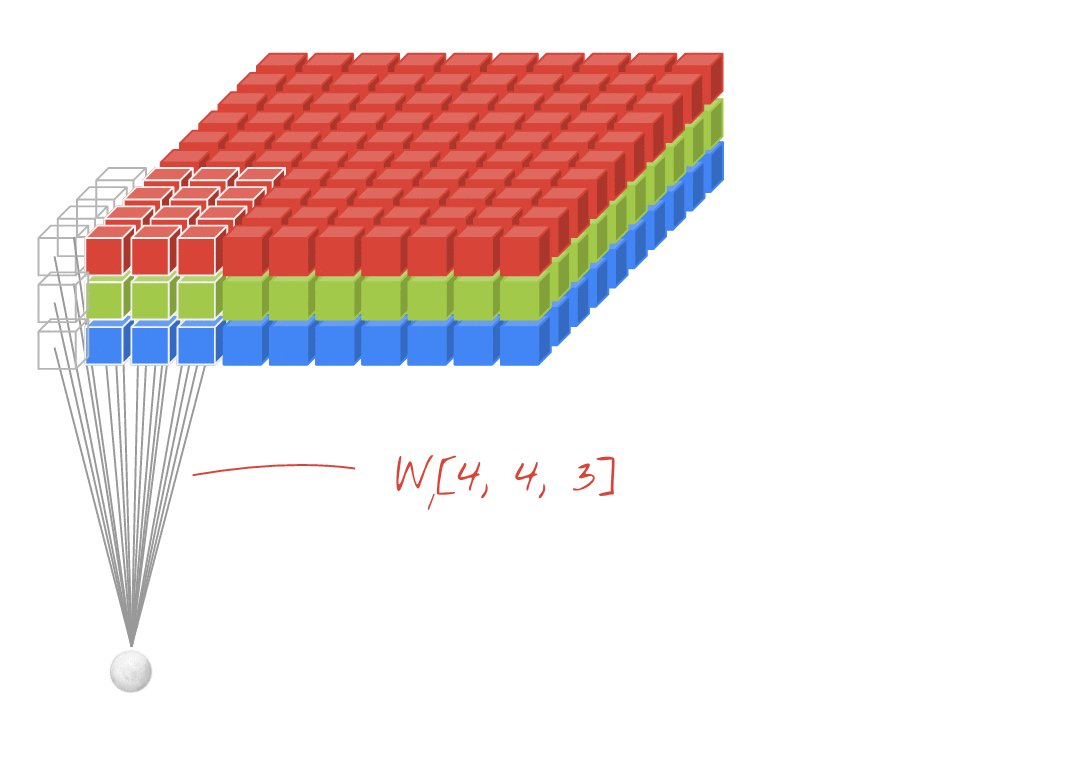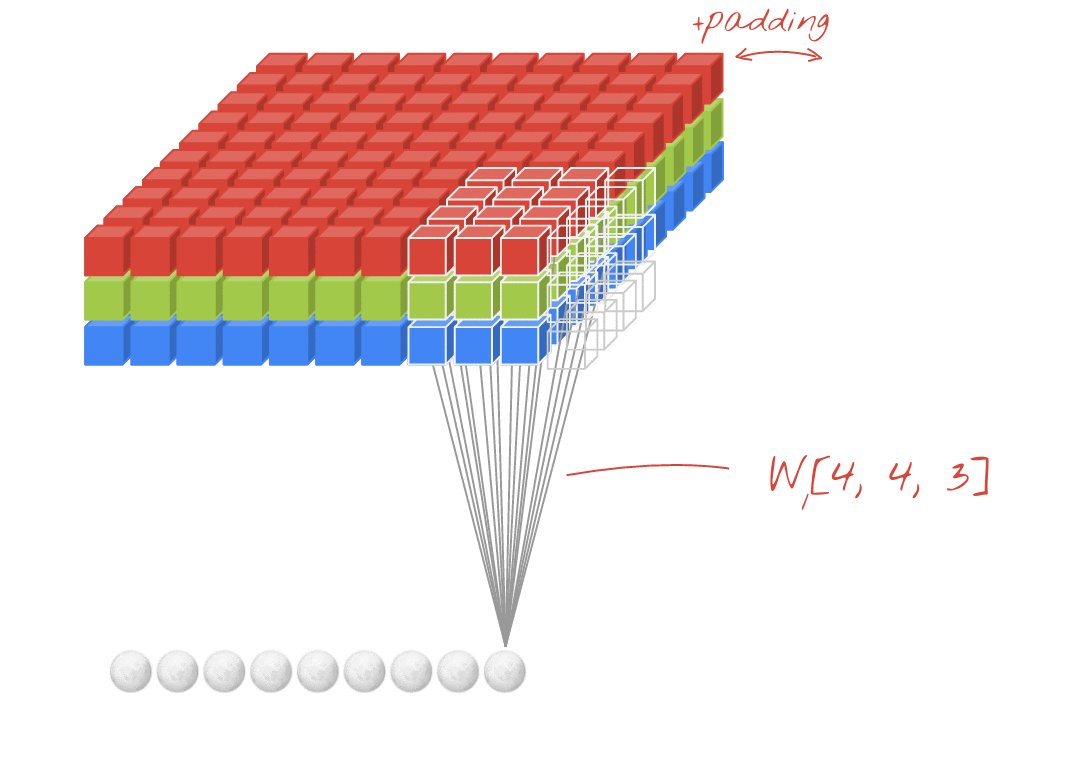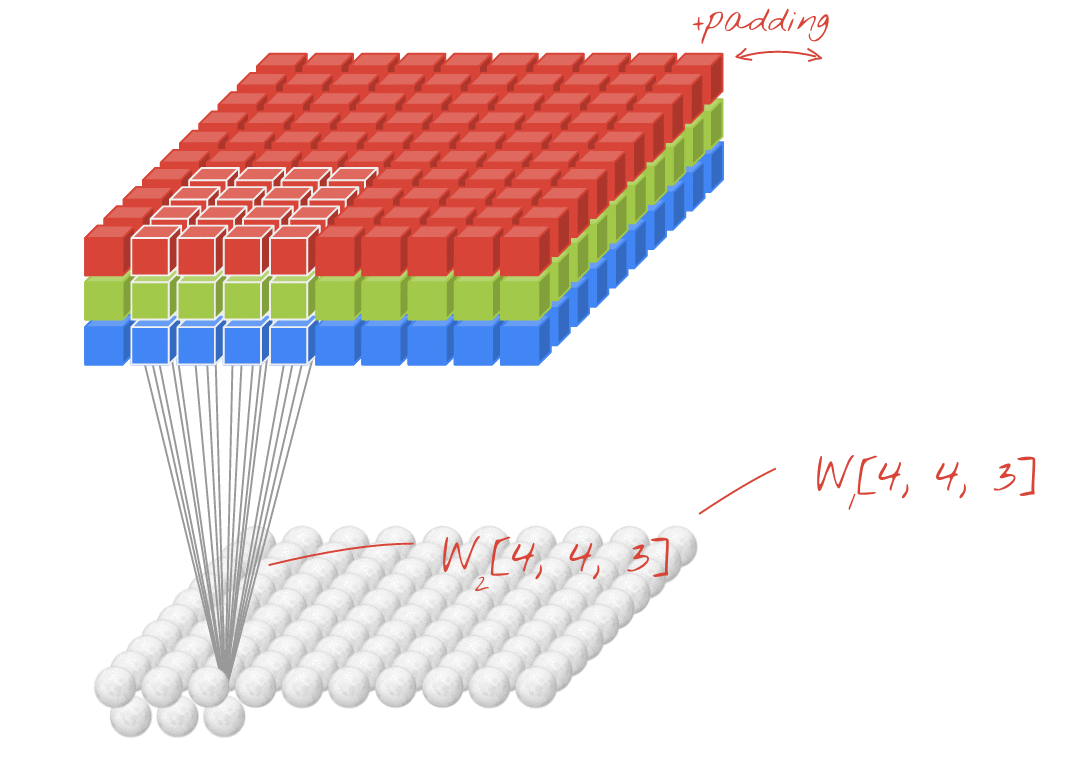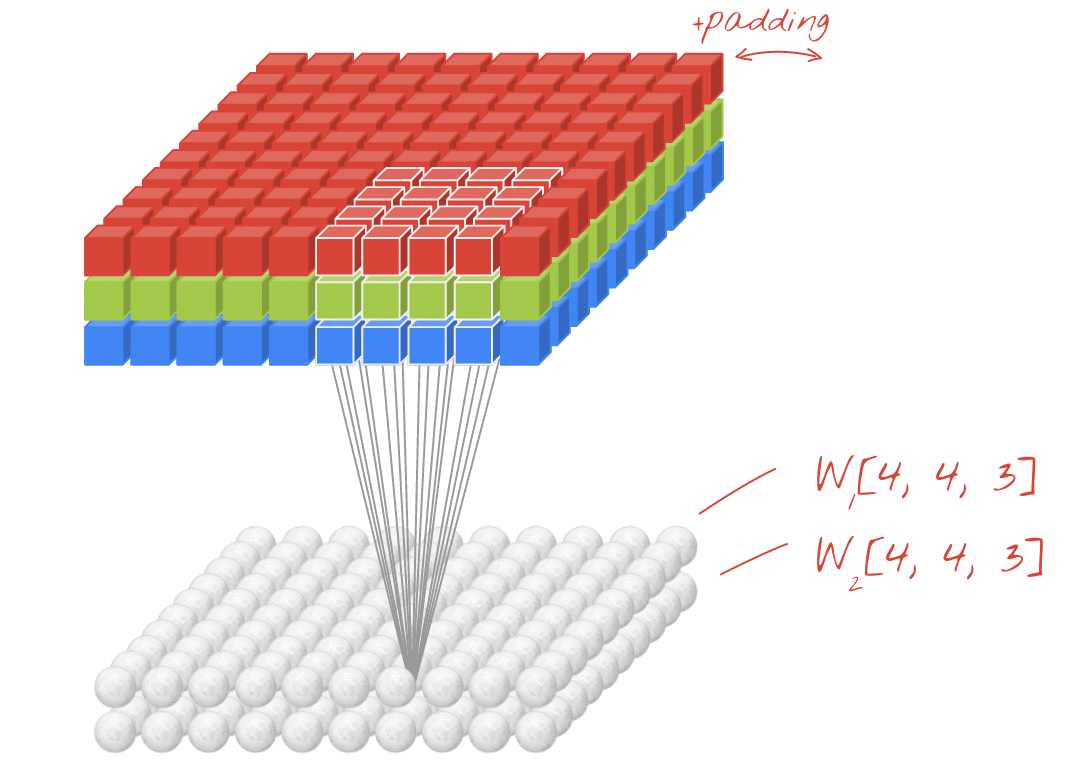
위에서는 1개의 필터를 사용하여 연산을 하였지만, 여러개의 필터를 이용하여 합성곱 신경망의 성능을 높일 수 있다.
그리고 이미지는 3차원(가로, 세로, 채널)이므로 아래와 같은 모양이 되는데,
이 그림에서의 입력과 출력은 다음과 같다.
- 입력 이미지 크기 : (10, 10, 3)
- 필터의 크기 : (4, 4, 3)
- 필터의 개수 : 2
- 출력 특성 맵의 크기 : (10, 10, 2)