RNN
순환 신경망(Recurrent Neural Network, RNN)
Keras로 RNN 구현하기
from tensorflow.keras.layers import SimpleRNN
model.add(SimpleRNN(hidden_units))# 추가 인자를 사용할 때
model.add(SimpleRNN(hidden_units, input_shape=(timesteps, input_dim)))
# 다른 표기
model.add(SimpleRNN(hidden_units, input_length=M, input_dim=N))from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import SimpleRNN
model = Sequential()
model.add(SimpleRNN(3, input_shape=(2,10)))
# model.add(SimpleRNN(3, input_length=2, input_dim=10))와 동일함.
model.summary()model = Sequential()
model.add(SimpleRNN(3, batch_input_shape=(8,2,10)))
model.summary()model = Sequential()
model.add(SimpleRNN(3, batch_input_shape=(8,2,10), return_sequences=True))
model.summary()RNN의 gredient vanishing problem
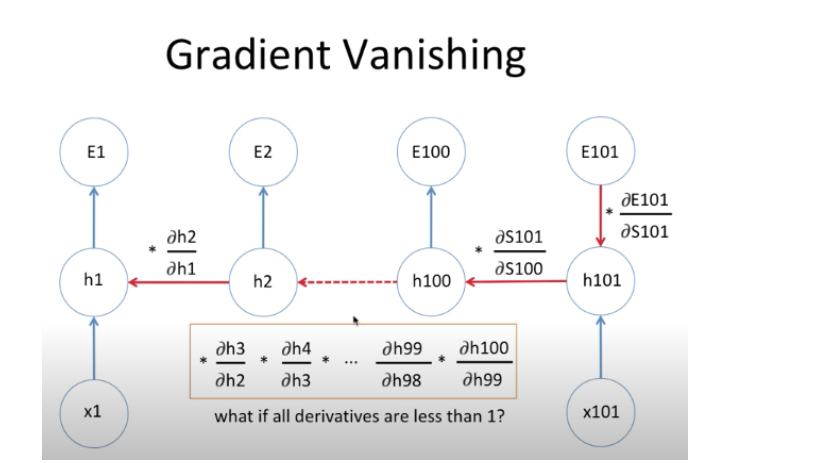
결국 다른 딥러닝 모델들과 마찬가지로 Back propagation 과정을 통해 Gradient 를 편미분하는데,
문제는 RNN 의 구조상 입력 데이터의 길이가 길어지면 에러 값 계산 후
처음 hidden state 까지 back propagation 하며 gradient 주는 과정이 너무 길기 때문에,,
gradient 값이 연산 과정에서 아주 작아져 버림 결국 gradient가 전달이 잘 안된다는것 ==> 이를 Gradient Vanishing 이라 한다. 4
LSTM VS GRU
LSTM의 구조는 아래와 같고, 특징은 2개의 벡터 ( 단기 상태 ht / 장기 상태 Ct ) 3개의 게이트 ( input gate, output gate 그리고 forget gate )를 가지고 있다는 점이다.
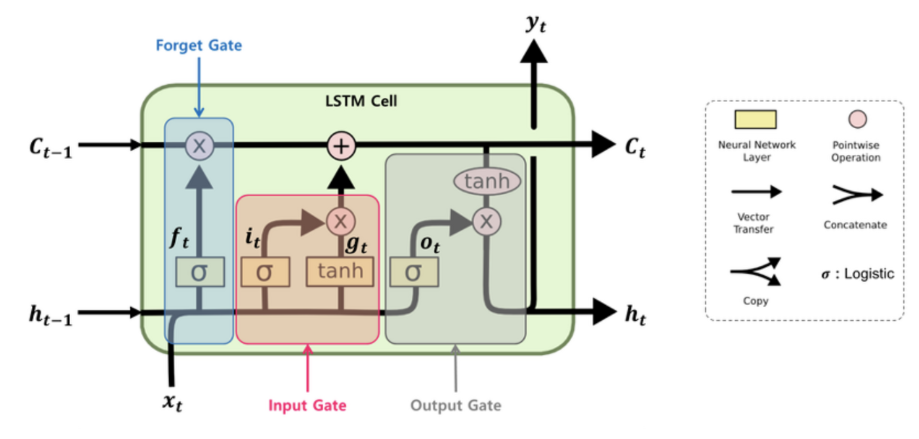
LSTM 셀에서는 상태(state)가 두 개의 벡터 와 로 나누어 진다는 것을 알 수 있다.
ht 를 단기 상태(short-term state), Ct를 장기 상태(long-term state)라고 볼 수 있다.각 게이트를 정말 간단하게만 정리하자면 컨셉은 이렇다
input gate : 이번 입력을 얼마나 반영할지
output gate : 이번 정보를 얼마나 내보낼지
forget gate : 과거 정보를 얼마나 까먹을지
그리고 이 모든 장기기억이 ct에 담김으로써 RNN의 문제를 해결함
GRU
위의 복잡한 구조를 간단히 시킨게 GRU
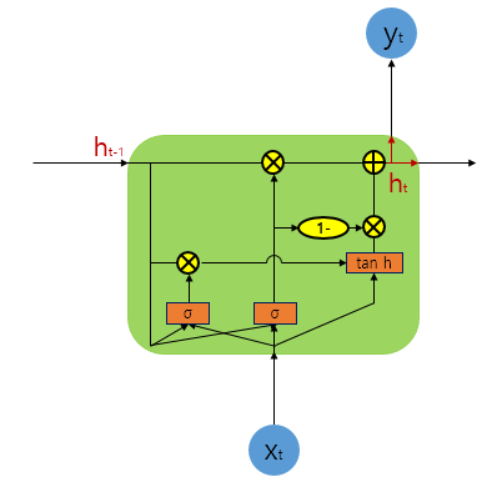
- GRU는 게이트가 2개, LSTM은 3개
- GRU는 내부 메모리 값 ( ct )이 외부에서 보게되는 hidden state 값과 다르지 않음. LSTM에 있는 출력 게이트가 없음 !
- 입력 게이트와 까먹음 게이트가 업데이트 게이트 z로 합쳐졌고, 리셋 게이트 r은 이전 hidden state 값에 바로 적용
- 따라서, LSTM의 까먹음 게이트의 역할이 r과 z 둘 다에 나눠졌다고 생각할 수 있음. 출력값을 계산할 때 추가적인 비선형 함수를 적용하지 않음
존경하는 인물: 현 수원삼성블루윙즈 감독 이정효