데이터 전처리
목적 : 주어진 원본 데이터를 신경망에 적용하기 쉽도록 만드는 것
방법 : 벡터화, 정규화, 결측치 처리, 피처 엔지니어링
벡터화
- 신경망에서 모든 입력과 타깃은 부동 소수 데이터로 이루어진 <텐서>임
- 이미지, 텍스트, 사운드 등 처리해야 할 것을 먼저 텐서로 변환함
- 벡터화의 예시 : 원-핫 인코딩, 벡터 인코딩 등
정규화
모든 특성이 대체로 비슷한 범위를 가져야한다 -> 학습이 잘 되는 요소 중 하나
-> 어떤 특성은 작은 부동 소수 값이고 다른 특성은 매우 큰 정수 값을 가질 수 있음
비교적 큰 값이나 균일하지 않은 데이터를 신경망에 주입하는 것은 위험하다
-> 업데이트할 기울기가 커져 네트워크가 수렴하는 것을 방해할 수 있음
방법: min_max_scaler, standard_scaler
import numpy as np
x -= x.np.mean(axis = 0)
x /= x.np.std(axis = 0) 결측치 처리 방법
1. 삭제 (Deletion)
- 행 삭제 (Row Deletion): 결측치가 있는 행을 삭제합니다. 결측치가 적고 데이터셋이 충분히 클 때 유용합니다.
- 열 삭제 (Column Deletion): 결측치가 많은 열을 삭제합니다. 특정 열에 결측치가 너무 많아서 유의미한 분석이 어려울 때 사용합니다.
import pandas as pd
# 행 삭제
df.dropna(inplace=True)
# 열 삭제
df.dropna(axis=1, inplace=True)2. 값 대체 (Imputation)
- 평균/중앙값 대체 (Mean/Median Imputation): 수치형 데이터의 경우 결측치를 해당 열의 평균 또는 중앙값으로 대체합니다.
- 최빈값 대체 (Mode Imputation): 범주형 데이터의 경우 결측치를 해당 열의 최빈값으로 대체합니다.
- 고정값 대체: 특정 고정값(예: 0, "Unknown")으로 결측치를 대체합니다.
# 평균 대체
df['column'].fillna(df['column'].mean(), inplace=True)
# 중앙값 대체
df['column'].fillna(df['column'].median(), inplace=True)
# 최빈값 대체
df['column'].fillna(df['column'].mode()[0], inplace=True)
# 고정값 대체
df['column'].fillna(0, inplace=True)
3. 예측 대체 (Predictive Imputation)
- 머신러닝 모델을 사용하여 결측치를 예측하여 대체합니다. 예를 들어, 회귀 모델을 사용하여 수치형 데이터의 결측치를 예측할 수 있습니다.
from sklearn.impute import SimpleImputer
imputer = SimpleImputer(strategy='mean') # 또는 'median', 'most_frequent', 'constant'
df['column'] = imputer.fit_transform(df[['column']])
4. KNN Imputation
- K-최근접 이웃(K-Nearest Neighbors) 알고리즘을 사용하여 결측치를 대체합니다. 결측치가 있는 데이터 포인트의 가장 가까운 이웃들의 값을 사용하여 대체합니다.
from sklearn.impute import KNNImputer
imputer = KNNImputer(n_neighbors=5)
df_imputed = imputer.fit_transform(df)- 회귀 대체 (Regression Imputation)
- 결측치가 있는 열을 타겟 변수로 간주하고 나머지 열을 사용하여 회귀 모델을 학습한 다음 결측치를 예측하여 대체합니다.
from sklearn.linear_model import LinearRegression
# 결측치가 없는 데이터로 학습
train_data = df[df['column'].notna()]
test_data = df[df['column'].isna()]
model = LinearRegression()
model.fit(train_data.drop('column', axis=1), train_data['column'])
# 결측치 예측
predicted_values = model.predict(test_data.drop('column', axis=1))
df.loc[df['column'].isna(), 'column'] = predicted_values
6. 결측치 표시 (Missing Indicator)
결측치가 있는 위치를 표시하는 새로운 이진 변수를 추가합니다. 결측치 처리를 하면서 동시에 결측치의 패턴을 모델에 제공할 수 있습니다.
df['column_missing'] = df['column'].isna().astype(int)결측치 처리 시 고려사항
- 데이터의 특성: 결측치 처리 방법은 데이터의 특성에 따라 다를 수 있습니다. 예를 들어, 결측치가 무작위로 발생했는지 아니면 특정 패턴에 따라 발생했는지를 고려해야 합니다.
- 결측치 비율: 결측치가 많은 경우, 단순히 결측치를 삭제하는 것은 데이터 손실이 클 수 있습니다.
- 모델의 요구사항: 머신러닝 모델에 따라 결측치 처리 방법이 다를 수 있습니다. 일부 모델은 결측치를 허용하지 않기 때문에 사전에 처리해야 합니다.
결측치 처리는 데이터 분석 및 머신러닝 모델링에서 필수적인 단계로, 데이터의 완전성과 일관성을 보장하기 위해 적절한 방법을 선택하는 것이 중요합니다.
피처 엔지니어링
피처 엔지니어링은 원시 데이터를 머신러닝 알고리즘에 더 적합하게 만들기 위해 데이터를 변환하고 특성(피처)을 생성하는 과정입니다. 피처 엔지니어링은 모델의 성능을 극대화하는 데 중요한 역할을 하며, 데이터 과학 및 머신러닝 프로젝트의 성공에 큰 영향을 미칩니다.
피처 엔지니어링의 주요 단계는 다음과 같습니다:
- 데이터 이해: 데이터를 탐색하고 도메인 지식을 활용하여 데이터를 이해합니다.
- 데이터 전처리: 결측치 처리, 이상치 제거, 데이터 정규화 등을 포함합니다.
- 피처 생성: 기존 데이터를 기반으로 새로운 피처를 생성합니다.
- 피처 선택: 모델 성능에 중요한 피처를 선택하고, 불필요한 피처를 제거합니다.
- 피처 변환: 피처를 스케일링, 인코딩 등으로 변환하여 모델에 적합하게 만듭니다.
import tensorflow as tf
from tensorflow.keras.preprocessing.image import ImageDataGenerator
# 이미지 데이터 제너레이터 설정
datagen = ImageDataGenerator(rescale=1./255, validation_split=0.2)
train_generator = datagen.flow_from_directory(
'path_to_clock_images',
target_size=(224, 224),
batch_size=32,
class_mode='sparse',
subset='training'
)
validation_generator = datagen.flow_from_directory(
'path_to_clock_images',
target_size=(224, 224),
batch_size=32,
class_mode='sparse',
subset='validation'
)
from tensorflow.keras.applications import VGG16
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Flatten
# VGG16 모델을 기반으로 CNN 모델 생성
base_model = VGG16(weights='imagenet', include_top=False, input_shape=(224, 224, 3))
model = Sequential([
base_model,
Flatten(),
Dense(128, activation='relu'),
Dense(24, activation='softmax') # 24시간 형식으로 시간 예측
])
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
model.summary()
history = model.fit(
train_generator,
epochs=10,
validation_data=validation_generator
)
import cv2
import numpy as np
def extract_features(image_path):
img = cv2.imread(image_path)
img_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
edges = cv2.Canny(img_gray, 50, 150)
# Hough Line Transform을 사용하여 시계 바늘 추출
lines = cv2.HoughLinesP(edges, 1, np.pi/180, threshold=80, minLineLength=30, maxLineGap=10)
if lines is not None:
for line in lines:
x1, y1, x2, y2 = line[0]
cv2.line(img, (x1, y1), (x2, y2), (0, 255, 0), 2)
# 중심과 끝 좌표로 벡터 계산 (여기서는 간단히 첫 번째 선만 사용)
angle = np.arctan2(y2 - y1, x2 - x1) * 180 / np.pi
return angle
return None
angle = extract_features('path_to_sample_clock_image.jpg')
print('Extracted angle:', angle)
# 예제에서는 각도 피처를 사용하여 새로운 모델을 설계할 수 있습니다.
# 피처 엔지니어링을 통해 추가적인 유의미한 피처를 생성하여 모델 성능을 높일 수 있습니다.
과적합(Overfitting)과 과소적합(Underfitting)
과적합과 과소적합은 머신러닝 모델의 성능과 관련된 두 가지 주요 문제입니다. 이 개념들을 이해하고 적절한 조치를 취하는 것은 모델의 일반화 성능을 향상시키는 데 매우 중요합니다.
해결 방법:
- 더 많은 데이터 수집: 더 많은 데이터를 사용하여 모델을 학습시킵니다.
- 정규화 (Regularization): L1, L2 정규화를 사용하여 모델의 복잡도를 줄입니다.
- 드롭아웃 (Dropout): 학습 과정에서 무작위로 뉴런을 비활성화하여 모델의 일반화 성능을 향상시킵니다.
- 교차 검증 (Cross-Validation): 데이터를 여러 부분으로 나누어 교차 검증을 통해 모델의 성능을 평가합니다。
- 단순한 모델 사용: 너무 복잡한 모델 대신 단순한 모델을 사용합니다.
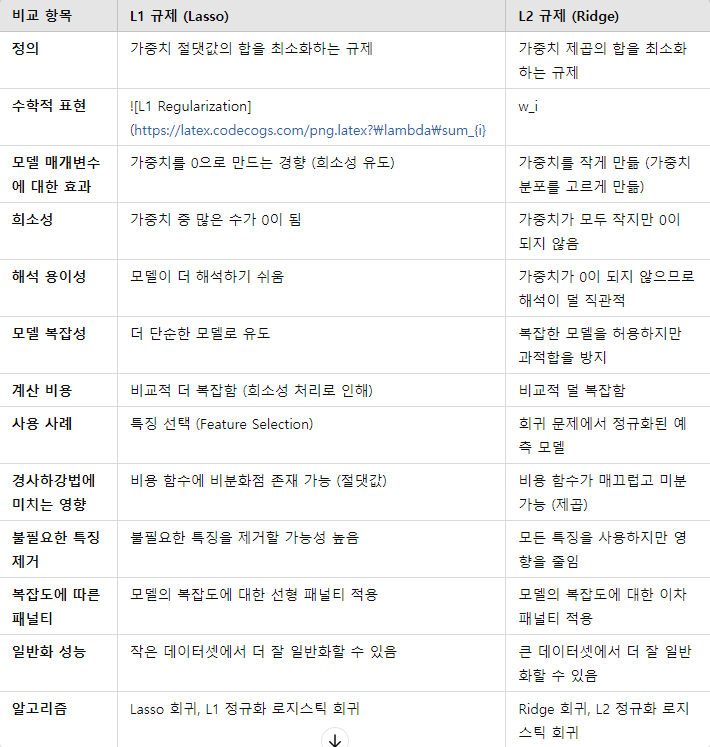
주요 차이점 및 특징 요약
- L1 규제:
- 가중치 절댓값의 합에 비례하여 페널티를 부여합니다.
- 많은 가중치를 0으로 만들어 모델을 희소하게 만듭니다.
- 특징 선택(feature selection)에 유리하며, 불필요한 특징을 제거합니다.
- 비용 함수에 비분화점이 존재할 수 있어 계산이 더 복잡할 수 있습니다.
- L2 규제:
- 가중치 제곱의 합에 비례하여 페널티를 부여합니다.
- 모든 가중치를 작게 만들어 모델의 복잡도를 줄입니다.
- 특징을 제거하지 않지만, 모든 특징의 영향을 줄입니다.
- 비용 함수가 매끄럽고 미분 가능하여 계산이 더 용이합니다.
두 규제 방식은 모두 과적합을 방지하고 모델의 일반화 성능을 향상시키는 데 사용되지만, 구체적인 상황과 데이터셋에 따라 선택해야 합니다. 예를 들어, L1 규제는 특징 선택이 중요한 경우에 유리하며, L2 규제는 대부분의 특징이 중요하고 큰 데이터셋을 다룰 때 유리합니다.
드롭아웃 기법
드롭아웃(Dropout)은 인공신경망의 학습 과정에서 무작위로 일부 뉴런을 비활성화(드롭)함으로써 과적합(overfitting)을 방지하고 모델의 일반화 성능을 향상시키는 정규화 기법입니다. 드롭아웃은 학습 과정 중 각 훈련 단계에서 네트워크의 일부 뉴런을 무작위로 선택하여 0으로 설정하고, 이를 통해 네트워크가 특정 뉴런이나 경로에 지나치게 의존하지 않도록 합니다.
- 드롭아웃의 구현
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout
from tensorflow.keras.datasets import mnist
from tensorflow.keras.utils import to_categorical
# MNIST 데이터셋 로드 및 전처리
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train = x_train.reshape(-1, 784).astype('float32') / 255
x_test = x_test.reshape(-1, 784).astype('float32') / 255
y_train = to_categorical(y_train, 10)
y_test = to_categorical(y_test, 10)
# 모델 정의
model = Sequential([
Dense(512, activation='relu', input_shape=(784,)),
Dropout(0.5, name='dropout_1'),
Dense(512, activation='relu'),
Dropout(0.5, name='dropout_2'),
Dense(10, activation='softmax')
])
# 모델 컴파일
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
# 모델 훈련
history = model.fit(x_train, y_train, epochs=10, batch_size=128, validation_split=0.2)
단순 홀드아웃 검증 (Simple Holdout Validation)
단순 홀드아웃 검증은 데이터셋을 두 개의 부분으로 나누어 모델을 평가하는 가장 기본적인 방법입니다. 데이터셋을 훈련 데이터와 테스트 데이터로 나누고, 훈련 데이터를 사용하여 모델을 학습시킨 후 테스트 데이터를 사용하여 모델의 성능을 평가합니다.
- 특징:
간단함: 구현이 쉽고 빠르게 적용할 수 있습니다.
데이터 사용 효율성: 전체 데이터 중 일부만 테스트에 사용되므로, 데이터가 충분히 많을 때 적합합니다. - 단점:
편향 가능성: 데이터셋을 나누는 방법에 따라 성능 평가가 크게 달라질 수 있습니다.
불안정성: 한 번의 평가로는 모델의 성능을 일반화하기 어렵습니다.
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_iris
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
# 데이터 로드
data = load_iris()
X, y = data.data, data.target
# 데이터 분할 (훈련: 80%, 테스트: 20%)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 모델 학습
model = RandomForestClassifier()
model.fit(X_train, y_train)
# 모델 평가
y_pred = model.predict(X_test)
print("Accuracy:", accuracy_score(y_test, y_pred))
K-겹 교차 검증 (K-Fold Cross-Validation)
K-겹 교차 검증은 데이터셋을 K개의 부분으로 나누어 K번의 학습과 평가를 진행하는 방법입니다. 각 부분이 한 번씩 테스트 데이터로 사용되고 나머지 K-1개의 부분이 훈련 데이터로 사용됩니다.
- 특징:
안정성: 모델 성능 평가의 편향을 줄이고, 다양한 데이터 분할에 대한 평균 성능을 제공합니다.
데이터 사용 효율성: 모든 데이터가 훈련과 테스트에 사용되므로 데이터 활용도가 높습니다. - 단점:
계산 비용: K번 모델을 학습시켜야 하므로 계산 비용이 증가합니다.
from sklearn.model_selection import cross_val_score
from sklearn.datasets import load_iris
from sklearn.ensemble import RandomForestClassifier
# 데이터 로드
data = load_iris()
X, y = data.data, data.target
# K-겹 교차 검증 (K=5)
model = RandomForestClassifier()
scores = cross_val_score(model, X, y, cv=5)
print("Cross-Validation Scores:", scores)
print("Mean Accuracy:", scores.mean())
셔플링(Shuffling)
셔플링은 데이터셋을 무작위로 섞는 과정입니다. 셔플링은 데이터셋이 정렬되어 있거나 특정 순서가 있을 때, 이를 무작위로 섞어 학습 과정에서 편향을 줄이고 모델의 일반화 성능을 높이는 데 사용됩니다.
- 특징:
편향 제거: 데이터셋의 순서로 인한 편향을 제거합니다.
모든 검증 방법에 사용 가능: 셔플링은 홀드아웃 검증이나 교차 검증과 함께 사용될 수 있습니다. - 단점:
무작위성: 완전히 동일한 결과를 얻기 위해서는 무작위 시드를 설정해야 합니다.
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_iris
# 데이터 로드
data = load_iris()
X, y = data.data, data.target
# 데이터 셔플링 및 분할
X, y = np.random.permutation(X), np.random.permutation(y)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 모델 학습 및 평가
model = RandomForestClassifier()
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
print("Accuracy:", accuracy_score(y_test, y_pred))
요약
- 단순 홀드아웃 검증: 데이터를 훈련 세트와 테스트 세트로 나누어 평가합니다. 구현이 간단하지만 편향될 수 있습니다.
- K-겹 교차 검증: 데이터를 K개의 부분으로 나누어 각 부분을 한 번씩 테스트 세트로 사용합니다. 안정적이고 데이터 활용도가 높지만 계산 비용이 큽니다.
- 셔플링: 데이터셋을 무작위로 섞어 편향을 줄입니다. 모든 검증 방법과 함께 사용할 수 있습니다.
각 방법은 데이터의 특성, 모델의 복잡도, 계산 자원 등을 고려하여 적절히 선택해야 합니다.
