신분당선 데이터마이닝 프로젝트 5주차 기록
팀명 : 아신낭
주제 : 신분당선 시간별 수요 데이터 마이닝 프로젝트
팀장 : 아주대학교 박종일
팀원 : 아주대학교 김용찬, 아주대학교 임재환
1주차
박종일 : 데이터 수집 및 계획 + 데이터 분석(DA), 통계 정리, 데이터마이닝
김용찬 : 데이터 수집 머신러닝 기법 수립(lightgbm) , 데이터마이닝
임재환 : 데이터 수집 및 레퍼런스 참조, 데이터 마이닝
2주차
주제 구체화: 재환 - 카카오 / 용찬 - 넥슨 / 종일 - 포스코 /
출근길 커피를 들고 신입사원처럼 출근하기!
3주차
데이터 구체화!
나는 신입사원으로 절대 시각을 하지 않는 자기 관리 역량이 뛰어난 사람!
박종일 : 모델링 분석
김용찬 : 모델링 분석
임재환 : 모델링 분석
4주차
데이터 구체화(다시)
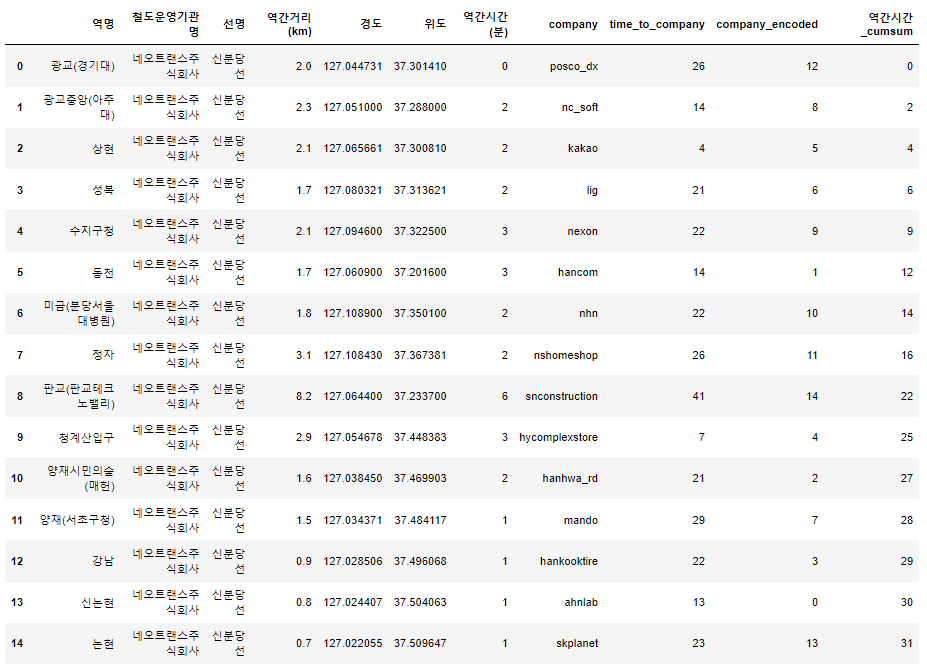
데이터 구성에 있어, 정형화된 데이터를 만들지 못하여 다시 데이터 컬럼을 구성하기로 결정하였음.
지하철 혼잡도 API를 통하여 새로운 컬럼과 함께 데이터를 구성하고자 함
박종일 : 데이터 정형화 및 데이터 분석
김용찬 : 데이터 분석 및 구체화
임재환 : 통계 정리
-> 주제는 3주차와 동일하게 구성하는 것을 목표
5주차
데이터 분석 결과 정리
지하철 혼잡도, 신분당 공공데이터 등을 토대로 혼잡도 EDA 및 회귀식 산정
박종일 : 회귀식 산정
김용찬 : 데이터 분석 및 시각화
임재환 : 데이터 분석 및 시각화
박종일
LG aimers 4기 수료
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.metrics import (
accuracy_score,
confusion_matrix,
f1_score,
precision_score,
recall_score,
)
from sklearn.model_selection import train_test_split
train = pd.read_csv('train.csv')
test = pd.read_csv("submission.csv")
def label_encoding(series: pd.Series) -> pd.Series:
"""범주형 데이터를 시리즈 형태로 받아 숫자형 데이터로 변환합니다."""
my_dict = {}
# 모든 요소를 문자열로 변환
series = series.astype(str)
for idx, value in enumerate(sorted(series.unique())):
my_dict[value] = idx
series = series.map(my_dict)
return series
# 레이블 인코딩할 칼럼들
label_columns = [
"customer_country",
"business_subarea",
"business_area",
"business_unit",
"customer_type",
"enterprise",
"customer_job",
"inquiry_type",
"product_category",
"product_subcategory",
"product_modelname",
"customer_country.1",
"customer_position",
"response_corporate",
"expected_timeline",
]
df_all = pd.concat([train[label_columns], test[label_columns]])
for col in label_columns:
df_all[col] = label_encoding(df_all[col])
for col in label_columns:
train[col] = df_all.iloc[: len(train)][col]
test[col] = df_all.iloc[len(train) :][col]
predictor = TabularPredictor(
label='is_converted',
eval_metric='f1_macro'
).fit(
train_data=train_data,
presets='best_quality',
time_limit=3600*8,
num_stack_levels=3)
df_sub = pd.read_csv("submission.csv")
df_sub["is_converted"] = pred
## automl 및 부스팅 및 트리 계열 모델 적용
## EDA 및 전처리 , 데이터 클래스 불균형 해결 - smote 기법 등
## 자연어 전처리 등으로 비정형 데이터 전처리 적용 - okt 등
임재환
감정 분석 - 자연어처리 총 공부 정리
-
텍스트 마이닝이란?
텍스트 마이닝, 또는 텍스트 데이터 마이닝은 비정형 텍스트 데이터에서 패턴, 트렌드, 관계 등을 발견하여 정보를 추출하고 지식을 도출하는 과정입니다. 이는 데이터 마이닝의 한 분야로, 텍스트 데이터의 특성을 고려한 전처리, 특징 추출, 모델링 기법이 적용됩니다. -
텍스트 마이닝 과정
- 데이터 수집: 소셜 미디어, 뉴스, 포럼, 리뷰 사이트 등에서 텍스트 데이터 수집
- 데이터 전처리: 텍스트 정제(특수 문자 제거, 소문자 변환 등), 토큰화, 불용어 제거, 어간 추출 등의 과정을 통해 데이터를 분석에 적합한 형태로 변환
- 특징 추출: 단어 빈도수, TF-IDF(Term Frequency-Inverse Document Frequency) 등의 방법을 사용하여 텍스트에서 특징을 추출
- 패턴 분석 및 지식 도출: 머신러닝 알고리즘(분류, 군집화, 연관 규칙 학습 등)을 적용하여 패턴을 발견하고 지식을 도출
-
감정 분석이란?
감정 분석(Sentiment Analysis)은 텍스트 데이터에 표현된 사람의 의견, 감정, 태도 등을 자동으로 분석하는 과정입니다. 이는 주로 긍정적, 중립적, 부정적과 같은 감정의 극성을 판별하는 작업으로, 제품 리뷰, 소셜 미디어 포스트, 뉴스 기사 등에서 고객의 태도나 여론의 경향을 이해하는 데 사용됩니다. -
감정 분석 과정
- 데이터 준비: 텍스트 마이닝 과정과 유사하게 데이터를 수집하고 전처리합니다.
- 특징 추출: 텍스트에서 감정 분석에 필요한 특징을 추출합니다. 이는 텍스트 마이닝에서의 특징 추출 방법과 유사할 수 있습니다.
- 감정 모델링: 머신러닝(예: SVM, 나이브 베이즈) 또는 딥러닝(예: RNN, LSTM) 기법을 사용하여 감정 분석 모델을 구축합니다.
- 결과 분석 및 해석: 모델을 통해 얻은 결과를 분석하고 해석하여, 텍스트에 담긴 감정의 극성(긍정, 부정, 중립)을 이해합니다.
import numpy as np
import pandas as pd
from sklearn.datasets import load_files
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import CountVectorizer, TfidfTransformer
from sklearn.naive_bayes import MultinomialNB
from sklearn.pipeline import Pipeline
from sklearn.metrics import classification_report
# 데이터셋 로드
# scikit-learn에 내장된 'movie_reviews' 데이터셋을 사용합니다.
# 실제 사용 시 해당 데이터셋을 다운로드하거나 자신의 데이터셋으로 대체하세요.
moviedir = r'scikit_learn_data/movie_reviews' # 데이터셋 경로 설정 필요
movie_reviews = load_files(moviedir, shuffle=True)
# 데이터셋 분할
X_train, X_test, y_train, y_test = train_test_split(
movie_reviews.data, movie_reviews.target, test_size=0.25, random_state=42)
# 텍스트 전처리 및 모델 파이프라인 구성
text_clf = Pipeline([
('vect', CountVectorizer()), # 단어 카운트 벡터화
('tfidf', TfidfTransformer()), # TF-IDF 변환
('clf', MultinomialNB()), # 나이브 베이즈 분류기
])
# 모델 학습
text_clf.fit(X_train, y_train)
# 예측 및 성능 평가
predicted = text_clf.predict(X_test)
print(classification_report(y_test, predicted, target_names=movie_reviews.target_names))
# 새로운 데이터에 대한 예측
reviews_new = ['This movie was excellent, with good acting and storyline.',
'The movie was a bit boring and I fell asleep halfway through.']
predicted = text_clf.predict(reviews_new)
for review, category in zip(reviews_new, predicted):
print(f'Review: {review}\nPredicted sentiment: {movie_reviews.target_names[category]}\n')
김용찬

import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import SimpleRNN, Dense
# RNN 모델 구성
model = Sequential()
model.add(SimpleRNN(50, return_sequences=True, input_shape=(None, 1)))
model.add(SimpleRNN(50))
model.add(Dense(1))
model.compile(optimizer='adam', loss='mean_squared_error')
# 데이터 준비 (여기서는 예시를 위한 더미 데이터 사용)
import numpy as np
X = np.random.rand(100, 10, 1) # 100개의 샘플, 각 샘플은 10개의 시간 스텝, 각 시간 스텝에는 1개의 특성
y = np.random.rand(100, 1) # 각 샘플에 대한 타겟
# 모델 학습
model.fit(X, y, epochs=20, batch_size=32)
LLM(Large Language Models) 간단 프로젝트
GPT를 이용한 텍스트 생성
OpenAI의 GPT 라이브러리인 transformers를 사용
from transformers import GPT2LMHeadModel, GPT2Tokenizer
# 모델과 토크나이저 로드
tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
model = GPT2LMHeadModel.from_pretrained('gpt2')
# 생성할 텍스트의 시작 부분
input_text = "The future of AI in healthcare is"
input_ids = tokenizer.encode(input_text, return_tensors='pt')
# 텍스트 생성
output = model.generate(input_ids, max_length=50, num_return_sequences=1)
# 생성된 텍스트 출력
print(tokenizer.decode(output[0], skip_special_tokens=True))
## 해당 모델을 지속적으로 파인 튜닝하며 개인 프로젝트에 사용하는 것이 목적