
서문
안녕하세요. 인재 채용 플랫폼 잡다의 웹 프론트엔드 개발을 하고 있는 배준형입니다.
저희 팀에서는 React-Query를 이용하여 Data Fetching을 구현하는데요. 사용 방법은 익숙해졌지만, React-Query가 어떻게 데이터를 캐싱 하는지, 어떤 방식으로 동작하는지는 잘 모릅니다.
공식 문서에서 제시하는 사용법만 익혀도 기능 구현에 문제는 없겠지만, 동작 원리를 조금이라도 안다면 이를 더 잘 활용할 수 있게 되고, 그 과정에서 얻게 되는 Skill들을 개인적인 작업에도 활용할 수 있을 것 같았습니다.
그래서 React-Query에서 제공하는 핵심 로직, 유틸 등의 코드를 확인해보고 파악한 내용들을 공유하고자 합니다.
query-core 동작 원리 살펴보기
※ 여기서는 Tanstack Query v5.18.0 버전으로 살펴봅니다. 버전 별로 내용이 상이할 수 있으니 참고 부탁드립니다.🙏
https://github.com/TanStack/query
이해를 돕기 위해 가져온 코드 중 일부 내용, Generic Type 등은 생략했습니다.
가장 먼저 React-Query 중 이해하기 쉬울 것이라 예상하고 useQuery부터 살펴봤는데요.
// useQuery.ts
export function useQuery(options: UseQueryOptions, queryClient?: QueryClient) {
return useBaseQuery(options, QueryObserver, queryClient)
}
// useBaseQuery.ts
export function useBaseQuery(
options: UseBaseQueryOptions,
Observer: typeof QueryObserver,
queryClient?: QueryClient,
): QueryObserverResult {
// ...
const client = useQueryClient(queryClient)
const defaultedOptions = client.defaultQueryOptions(options)
// ...
const [observer] = React.useState(
() =>
new Observer(
client,
defaultedOptions,
),
)
// ...
}useQuery 내부에서 useBaseQuery만 사용하므로 그대로 useBaseQuery를 분석해 보려 했지만 이해하기가 쉽지 않았습니다. QueryClient, QueryObserver 같은 것들이 사용되고 있는데, 그 내용들을 먼저 확인해야 분석하기가 더 수월할 것 같습니다.
그래서 query-core에서 QueryClient, QueryCache 등의 내용을 먼저 확인하겠습니다. React-Query docs에서도 core 부분을 먼저 설명하고 있기도 하고요.
QueryClient
export class QueryClient {
#queryCache: QueryCache
#mutationCache: MutationCache
// ...
constructor(config: QueryClientConfig = {}) {
this.#queryCache = config.queryCache || new QueryCache()
this.#mutationCache = config.mutationCache || new MutationCache()
// ...
}
// ...
}#queryCache: query의 결과를 캐싱 하기 위한 QueryCache 인스턴스#mutationCache: mutation의 결과를 캐싱 하기 위한 MutationCache 인스턴스
QueryClient는 쿼리 결과를 캐싱 하여 동일한 쿼리가 반복 호출될 때 성능을 최적화하는 역할을 수행합니다. 그 과정에서 #queryCache 멤버 변수가 사용됩니다.
QueryCache
export interface QueryStore {
has: (queryHash: string) => boolean
set: (queryHash: string, query: Query) => void
get: (queryHash: string) => Query | undefined
delete: (queryHash: string) => void
values: () => IterableIterator<Query>
}
export class QueryCache extends Subscribable<QueryCacheListener> {
#queries: QueryStore
constructor(public config: QueryCacheConfig = {}) {
super()
this.#queries = new Map<string, Query>()
}
// ...
}#queries: 실제 쿼리를 저장하는 스토어
QueryCache는 쿼리 결과를 캐싱 하기 위한 클래스입니다. Map 객체에 쿼리 해시값을 키로 쿼리 객체를 저장하고, 이를 통해 쿼리 결과를 캐싱 합니다.
QueryClient는 #queryCache 멤버 변수로 할당한 QueryCache 클래스를 통해 캐싱을 관리하며 직접 QueryCache를 조작하기보단 대부분의 경우 QueryClient를 통해 QueryCache에 대한 접근, 조작하게 됩니다. 다만 특수한 상황에서 캐시 내부 동작을 완벽히 제어하고자 한다면
queryClient.getQueryCache().subscribe 등을 활용할 수도 있습니다.
QueryClient - fetchQuery
QueryClient에서 fetchQuery 메서드는 옵션에 따라 쿼리를 fetch 하고 결과를 반환하는 비동기 메서드입니다.
export class QueryClient {
#queryCache: QueryCache
// ...
fetchQuery(
options: FetchQueryOptions,
): Promise<TData> {
const defaultedOptions = this.defaultQueryOptions(options)
// ...
const query = this.#queryCache.build(this, defaultedOptions)
return query.isStaleByTime(defaultedOptions.staleTime)
? query.fetch(defaultedOptions)
: Promise.resolve(query.state.data as TData)
}}
// ...
}여기서 서버 API를 호출하기 전에 기존에 캐싱 된 데이터가 있는지, 있다면 바로 반환할지 StaleTIme 기준으로 API를 호출할지 결정됩니다.
#queryCache의 build 메서드를 호출하여 반환된 쿼리를 사용합니다. 이 쿼리에서 staleTime을 체크하는데, stale 상태이면 query.fetch()를 호출하여 서버 API를 호출하고, stale 상태가 아니면 기존 캐싱 된 데이터를 바로 반환합니다.
staleTime은 react-query에서 데이터가 stale 상태가 되는 시간을 지정합니다. 이 시간 이후에는 데이터가 오래된 것으로 간주하고 refetch가 트리거 됩니다.
QueryClient fetchQuery 함수의 사용은 아래와 같이 이루어집니다.
try {
const data = await queryClient.fetchQuery({ queryKey, queryFn })
} catch (error) {
console.log(error)
}queryKey, queryFn 두 가지 인자를 넘겨주면서 사용하는데, 이를 바탕으로 캐싱 된 데이터가 있는지 없는지 판단하는 것이죠. 내부적으로 #queryCache 변수가 할당되어 사용되고 있고, 특정 조건에 따라 캐싱 값을 사용할지 서버 API를 호출할지 결정되지만 사용할 때는 캐시가 사용되는지 아닌지 확인할 필요 없이 그냥 호출만 하면 됩니다.
QueryCache - build
위에서 fetchQuery 메서드를 호출할 때 캐싱 된 query 받아와서 사용하는데, 그때 사용되는 메서드가 build 메서드입니다. build 메서드는 새로운 쿼리를 생성하거나 캐시에서 기존 쿼리를 검색할 때 사용됩니다.
export class QueryCache extends Subscribable<QueryCacheListener> {
#queries: QueryStore
// ...
build(
client: QueryClient,
options: QueryOptions,
state?: QueryState,
): Query {
const queryKey = options.queryKey!
const queryHash =
options.queryHash ?? hashQueryKeyByOptions(queryKey, options)
let query = this.get(queryHash)
if (!query) {
query = new Query({
cache: this,
queryKey,
queryHash,
options: client.defaultQueryOptions(options),
state,
defaultOptions: client.getQueryDefaults(queryKey),
})
this.add(query)
}
return query
}
// ...
}주어진 쿼리 키와 옵션을 사용하여 쿼리를 구성하고, 그 쿼리가 있다면 그대로 반환하고, 없다면 캐시에 쿼리를 추가합니다.
cache Map에 캐싱된 쿼리가 있는 경우 쿼리를 가져올 때 queryKey가 아닌 queryHash가 cache Map에 key 값으로 활용됩니다. 만약 queryHash가 없는 경우 hashQueryKeyByOptions 함수를 호출하여 queryKey와 options에 기반한 hash 값을 생성하는데요.
export function hashQueryKeyByOptions(
queryKey: TQueryKey,
options?: QueryOptions,
): string {
const hashFn = options?.queryKeyHashFn || hashKey
return hashFn(queryKey)
}
export function hashKey(queryKey: QueryKey | MutationKey): string {
return JSON.stringify(queryKey, (_, val) =>
isPlainObject(val)
? Object.keys(val)
.sort()
.reduce((result, key) => {
result[key] = val[key]
return result
}, {} as any)
: val,
)
}해당 함수는 함께 전달된 options에 queryKeyHashFn 함수가 있다면 사용하지만 없다면 미리 정의된 hashKey 함수가 사용됩니다.
hashKey 함수는 주어진 queryKey 또는 MutationKey를 문자열로 변환하는 역할을 합니다. 이 변환 과정에서 JSON.stringify 메서드를 사용하며, 이 메서드의 두 번째 인자로 전달되는 함수를 통해 특정 처리를 수행합니다.
그 과정에서 정렬(sort)이 이루어지므로 키의 순서가 일관되게 유지됩니다. 예를 들어 { a: 1, b: 2 }, { b: 2, a: 1 } 두 객체에 대한 키는 동일하게 '{"a":2,"b":1}' 문자열을 반환합니다. 이 과정을 통해 동일한 queryKey에 대해 동일한 해시 키를 사용하게 되는 것이죠.
Query
여기까지 살펴본 내용으로 QueryClient를 통한 data fetching은 아래의 흐름으로 이루어집니다.
QueryClient에서fetchQuery호출QueryCache의build를 통해 캐싱 된(또는 새로운)query반환- 반환된
query의fetch를 통해 데이터 fetching 진행
여기서 사용되는 Query 클래스는 하나의 쿼리 상태와 데이터를 나타내는 클래스입니다.
export class Query extends Removable {
queryKey: TQueryKey
queryHash: string
options!: QueryOptions<TQueryFnData, TError, TData, TQueryKey>
state: QueryState<TData, TError>
#cache: QueryCache
#observers: Array<QueryObserver<any, any, any, any, any>>
// ...
constructor(config: QueryConfig<TQueryFnData, TError, TData, TQueryKey>) {
super()
this.#observers = []
this.#cache = config.cache
this.queryKey = config.queryKey
this.queryHash = config.queryHash
this.state = this.#initialState
// ...
}
fetch(options?: QueryOptions, fetchOptions?: FetchOptions): Promise<TData> {}
onFocus(): void {}
// ...
}queryKey: 쿼리를 식별하는 QueryKeyqueryHash: 쿼리 해시값options: 해당 쿼리의 옵션들state: 쿼리의 현재 상태(idle,loading등)cache: 연결된 QueryCache
생성된 쿼리 인스턴스는 idle, loading 등의 상태를 가지며 데이터를 저장하고 API를 호출하는 등의 역할을 수행합니다. fetch 메서드를 통해 서버 API를 호출하여 쿼리를 수행하거나 onFocus 메서드를 통해 포커스 시 수행될 액션을 정의할 수 있습니다.
query-core/src/Query.ts - onFocus 메서드
onFocus(): void {
const observer = this.#observers.find((x) => x.shouldFetchOnWindowFocus())
observer?.refetch({ cancelRefetch: false })
// Continue fetch if currently paused
this.#retryer?.continue()
}아직 observer가 무엇인지 살펴보진 않았지만, onFocus 메서드 내부에서 shouldFetchOnWindowFocus 등의 키워드를 통해 focus 시 fetch 해야 하는 구독 observer를 찾은 다음 refetch 키워드로 다시 fetch 해오는 것을 확인할 수 있습니다.
useQuery를 사용하면 브라우저 탭 전환이나 Focus 전환 시 다시 데이터를 Fetch 해오는 기능은 Query 클래스에서 onFocus 기능을 활용한다는 것을 알 수 있고, 이를 잘 활용하면 다양한 사용 사례를 만들 수 있겠죠.
중간 정리
지금까지의 QueryClient - QueryCache - Query에 대한 관계도를 표현하면 다음과 같습니다.
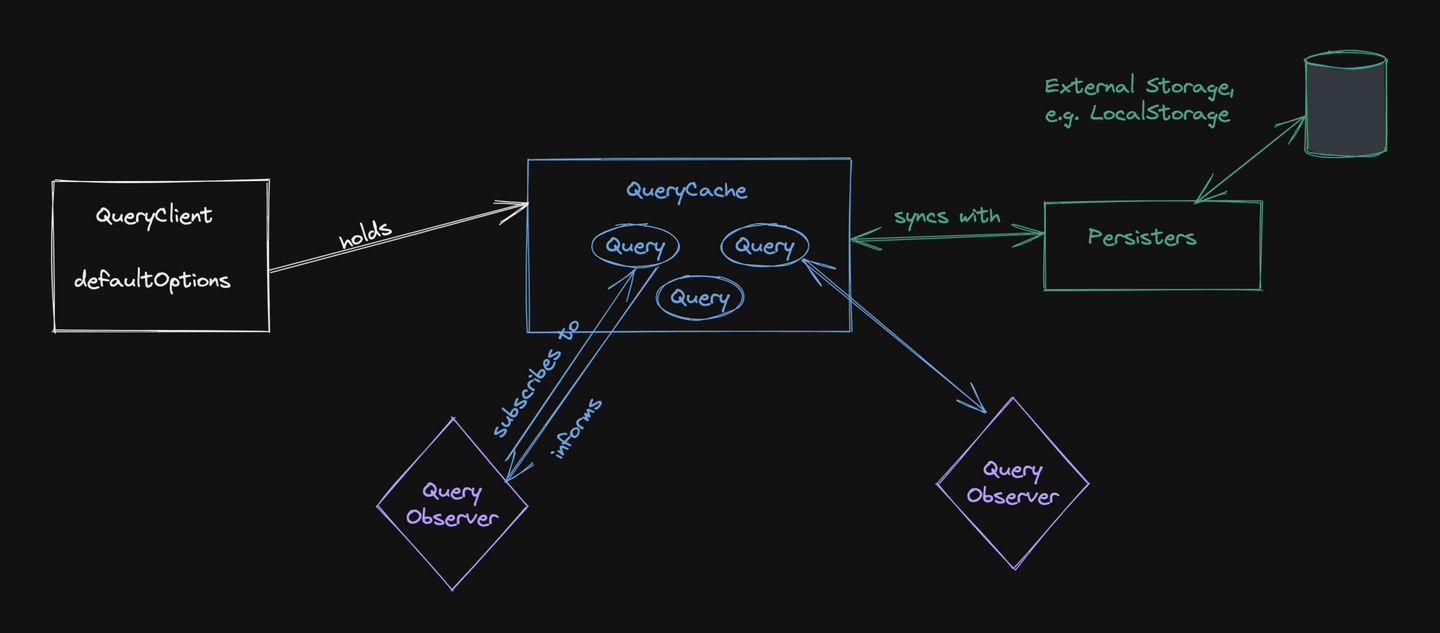
생성된 QueryClient 인스턴스는 QueryCache를 가지고 있고, QueryCache에서 Query를 캐싱, 컨트롤합니다.
QueryClient에서 fetchQuery 메서드를 통해 API를 호출하는데, 호출하기 전 QueryCache 멤버 변수의 build 메서드를 통해 캐시가 있다면 캐시 된 쿼리, 없다면 새로 추가된 쿼리를 사용하고, 그 쿼리의 StaleTime 등을 확인하여 캐시 된 데이터를 반환할지, API를 호출할지 결정합니다.
Query - #dispatch
쿼리는 각 인스턴스별 상태를 갖고 있고, 이는 fetching, paused, idle 등의 상태로 구분되어 사용됩니다. 이 상태는 #dispatch 메서드를 통해 각 상태 변화를 구독자들(React 컴포넌트)에게 전파하여 컴포넌트가 업데이트될 수 있게 하는 역할을 수행합니다.
export class Query extends Removable {
// ...
#dispatch(action: Action<TData, TError>): void {
const reducer = (state: QueryState): QueryState => {
switch (action.type) {
case 'failed':
case 'pause':
// ...
case 'continue':
return {
...state,
fetchStatus: 'fetching',
}
case 'fetch':
return {
...state,
fetchFailureCount: 0,
fetchFailureReason: null,
fetchMeta: action.meta ?? null,
fetchStatus: canFetch(this.options.networkMode)
? 'fetching'
: 'paused',
...(!state.dataUpdatedAt && {
error: null,
status: 'pending',
}),
}
case 'success':
return {
...state,
data: action.data,
dataUpdateCount: state.dataUpdateCount + 1,
dataUpdatedAt: action.dataUpdatedAt ?? Date.now(),
error: null,
isInvalidated: false,
status: 'success',
...(!action.manual && {
fetchStatus: 'idle',
fetchFailureCount: 0,
fetchFailureReason: null,
}),
}
case 'error':
case 'invalidate':
case 'setState':
// ...
}
}
this.state = reducer(this.state)
notifyManager.batch(() => {
this.#observers.forEach((observer) => {
observer.onQueryUpdate()
})
this.#cache.notify({ query: this, type: 'updated', action })
})
}
}dispatch 메서드는 메서드 내부에서 reducer 함수를 정의하고, 이 함수를 사용하여 현재 쿼리 상태를 업데이트합니다. 그 후 notifyManager를 사용하여 모든 관찰자에게 쿼리 업데이트를 알리며, 쿼리 캐시의 모든 리스너에게 notify 메서드를 호출하여 상태가 변경되었음을 알립니다.
요약하자면 쿼리 인스턴스의 상태가 변경되면 그 상태 변화는 구독자(React 컴포넌트)에게 알려지고, 구독자는 알림을 받아 로직을 수행합니다. 이를 통해 데이터를 리렌더링 하거나 에러 발생 시 리트라이 로직 수행 등의 작업을 수행할 수 있겠죠.
Query - fetch
fetch 메서드는 데이터를 가져오기 위해 사용하는 메서드입니다. QueryClient에서 fetchQuery를 통해 데이터 fetching을 시도하면 조건에 따라 Query.fetch() 메서드가 호출됩니다.
fetch(
options?: QueryOptions,
fetchOptions?: FetchOptions,
): Promise<TData> {
// fetching 중이라면 새로운 fetch를 중단합니다.
if (this.state.fetchStatus !== 'idle') {
// fetch 중단 로직
}
// ...
// retryer를 정의하여 에러 핸들링, 재시도 로직을 작성해주고, abortController를 통해 취소할 수 있도록 합니다.
this.#retryer = createRetryer({
fn: context.fetchFn as () => Promise<TData>,
abort: abortController.abort.bind(abortController),
onSuccess: (data) => {}
onError,
onFail: (failureCount, error) => {},
onPause: () => {},
onContinue: () => {},
retry: context.options.retry,
retryDelay: context.options.retryDelay,
networkMode: context.options.networkMode,
})
// fetching 중이 아니라면 status를 'fetch' 상태로 업데이트 합니다.
if (
this.state.fetchStatus === 'idle' ||
this.state.fetchMeta !== context.fetchOptions?.meta
) {
this.#dispatch({ type: 'fetch', meta: context.fetchOptions?.meta })
}
this.#promise = this.#retryer.promise
return this.#promise
}전체 코드는 약 200줄가량 되는데요. 요약하자면
- fetchStatus를 확인하여 fetching 중이라면 새로운 fetch를 중단
- abortController API를 이용해서 fetching을 취소할 수 있게 컨트롤
retryer를 생성해 에러 핸들링 및 재시도 로직을 정의, 데이터 fetching 결과(성공, 실패, 중단 등)를 캐시와 state 업데이트
하는 로직이 담겨 있습니다.
react-query를 사용해 본 적이 있는 분들은 아시겠지만, useQuery를 통해 데이터 fetching을 하는 컴포넌트를 한 페이지에 여러 개 렌더링 시키더라도 API 호출은 1회만 진행되는데요. 그 이유는 동일한 queryKey를 가진 컴포넌트들은 기존에 생성된 동일 Query 인스턴스의 fetchStatus를 보고 새로운 요청을 중단하기 때문입니다. 이를 통해 react-query는 상태 공유 및 요청 최적화가 가능하죠.
정리
QueryClient:queryCache를 멤버 변수로 가지며,fetchQuery메서드로 데이터 fetchingQueryCache: Map 객체 형태로<queryKey, Query>형태로 캐싱 하며,fetchQuery를 통해 데이터 fetching이 진행될 때build메서드로 캐싱 된(또는 새로운) 쿼리 반환하여 사용Query: 인스턴스별 상태를 가지며 상태 변화를 리액트 컴포넌트에 알려 업데이트를 진행하도록 하고,fetch메서드를 통해 데이터 fetching 진행
React-Query의 기능 분석
캐싱
- QueryClient - QueryCache의 Map 객체를 통해 queryKey를 키로 하는 객체로 캐싱
여러 API 요청에 대해 API 1회만 호출
- QueryClient - QueryCache - Query의 각 상태를 dispatch를 통해 업데이트
- fetch 메서드가 호출됐을 때 fetchStatus 값을 확인하여 fetching 중이라면 새로운 API 호출을 중단하여 최적화
브라우저 탭 전환 간 focus됐을 때 fetching 진행
- QueryClient - QueryCache - Query의 onFocus 메서드를 활용하여 focus 됐을 때 fetching 진행
이번 글에서 알아본 내용은 위와 같이 정리할 수 있을 것 같고, Query-Core 내용으로 핵심 로직들은 어느 정도 파악이 된 것 같습니다. 코드를 분석해 보니 관련 내용들을 참고하여 비슷한 최적화 처리가 가능하지 않을까 싶어요. 예를 들면, 변화가 거의 없는 API 응답 데이터를 전역 상태로 관리한다고 했을 때 status 값을 활용해서 똑같은 함수를 호출하더라도 status에 따라 값을 반환하거나 API 응답을 반환하도록 처리할 수 있도록 할 수 있을 것 같습니다.
React-Query의 로직만 파악했다기보다 그 로직들을 이해하면서 관련 기술, 일련의 최적화 흐름들을 체득할 수 있었던 것 같습니다.
제 글에서는 생략된 코드들도 많고 확인하지 못한 코드들도 많이 남아있습니다.
useQuery, useMutation, QueryObserver 클래스부터 hydrate, dehydrate를 통한 SSR 지원 등 알아두면 좋은 기능들을 확인할 수 있는 좋은 기회가 많이 남아있습니다. 관련 내용들을 조금씩 정리하여 포스팅하고자 합니다.
참조
