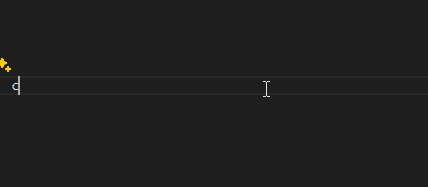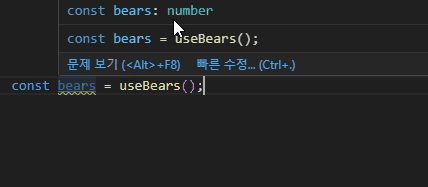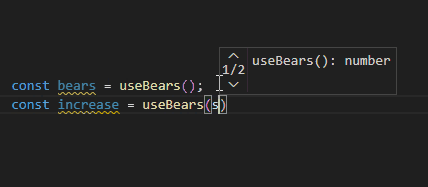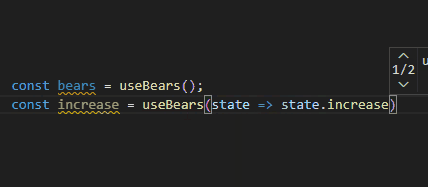
서문
안녕하세요. 인재 채용 플랫폼 잡다의 웹 프론트엔드 개발을 담당하고 있는 배준형입니다.
잡다 프론트엔드 코드는 Typescript로 작성되지만 불필요하게 any 타입이 사용되거나 특정 유틸 함수를 사용하고 나면 반환 값을 any로 추론하는 코드, catch 문에서 전달받은 unknown error 객체를 그대로 사용해서 에러가 발생하고 있는 데도 사용되고 있는 코드들이 존재했습니다.
저는 any 타입을 최대한 사용하지 않고 적절한 타입을 지정하는 것을 중요하게 생각합니다. Typescript가 주는 타입 안정성과 컴파일 단계에서 디버깅 가능, 편집기에서 제공하는 자동 완성 기능 등이 너무 편리하기 때문인데요.
물론 any 타입이 사용되었다고 해서 즉시 문제가 발생하는 것은 아니고, 코드 상으로도 문제는 없어 보입니다. 그러나 코드 수정이나 기능 확장에 어려움이 발생할 가능성이 남아있게 됩니다. 컴파일 단계에서 확인 가능한 에러들도 런타임에 직접 에러를 재현해야 확인할 수 있기에 타입스크립트를 사용하는 이점도 사라지게 되죠.
그래서 타입을 잘 작성할 수 있도록 타입스크립트 기능들을 활용하는 편인데 관련 내용을 공유하고자 합니다.
1. Type Guard
타입 좁히기
타입은 넓히거나 좁힐 수 있습니다. 타입 좁히기를 사용하면 여러 개로 추론되었던 타입이 특정 타입으로 좁혀져서 작업하기가 편해지는데, React를 쓰시는 분들은 주로 useRef, ref props를 사용할 때 자연스럽게 사용했을 것 같아요.
const ref = useRef<HTMLDivElement>(null);
useEffect(() => {
const element = ref.current; // element는 HTMLDivElement | null 타입
if (!element) {
// element가 null type으로 좁혀짐
} else {
// element가 HTMLDivElement type으로 좁혀짐
}
}, []);
return <div ref={ref} />;위와 같은 경우에도 ref.current의 타입이 HTMLDivElement와 null 둘 중 하나의 값으로 추론되니 타입 좁히기를 통해 각각 다른 동작을 적절하게 구현할 수 있겠죠.
저는 이럴 때 null일 경우는 return 하고, HTMLDivELement 타입인 경우에만 동작할 코드를 구현합니다.
useEffect(() => {
const element = ref.current;
if (!element) return;
// element 관련 동작들
}, []);이렇게 하면 element가 null인 경우가 있다고 하더라도 오로지 HTMLDivElement 타입인 경우에 대해서만 코드를 작성하면 됩니다.
위처럼 타입 좁히기는 Primitive Type인 경우는 쉽게 작성할 수 있습니다. 그런데 객체 형태의 타입으로 추론하려면 어떻게 해야 할까요?
Type Guard
그런 경우는 Type Guard를 통해 타입을 추론할 수 있습니다.
interface Human {
name: string;
age: number;
}
interface Animal {
name: string;
leg: number;
}
type HumanOrAnimal = Human | Animal;이런 타입이 있다고 가정해 보겠습니다. 두 타입 모두 name 항목이 있지만, 나머지 항목은 다른데요. 이를 이용해 Type Guard를 생성해 보겠습니다.
function isHuman(target: HumanOrAnimal): target is Human {
return "age" in target;
}Type Guard는 반환 값의 타입을 is 키워드와 함께 작성해주면 되고, 함수 자체는 boolean 타입을 반환해야 합니다. 함수의 반환 값이 true인 경우 매개변수의 타입이 is 키워드 뒤에 지정해준 타입으로 추론됩니다.
function someFunction(target: HumanOrAnimal) {
if (isHuman(target)) {
console.log(target.age); // target: Human
} else {
console.log(target.leg); // target: Animal
}
}Type Guard 활용하기
Type Guard는 isString, isNumber 등 여러 활용 방법이 있는데, try catch 문에 unknown error 타입을 추론하는 경우에도 사용하고 있습니다.
try, catch 문의 error는 any, unknown 외에는 타입을 지정해줄 수 없습니다.

잡다에서 API 호출 요청에 대해 에러가 하면 errorCode, errorData, errorMessage 등을 내려주고 있는데요. error의 타입을 지정할 수 없어서 기존 코드의 대부분은 e: any 형태로 타입을 지정하여 errorCode 등에 접근해 사용하고 있었어요.
코드 상 문제는 없지만 더 안정성을 높이기 위해 Type Guard를 정의해 사용하도록 수정하고 있습니다.
export function hasErrorResponse(e: unknown): e is { response: object } {
return (
typeof e === "object" && e !== null && "response" in e && typeof e.response === "object" && e.response !== null
);
}
export function hasErrorData(e: unknown): e is { response: { data: object } } {
return hasErrorResponse(e) && "data" in e.response && typeof e.response.data === "object";
}
export function hasErrorCode(e: unknown): e is { response: { data: { errorCode: string } } } {
return hasErrorData(e) && "errorCode" in e.response.data && typeof e.response.data.errorCode === "string";
}
export function hasErrorMessage(e: unknown): e is { response: { data: { message: string } } } {
return hasErrorData(e) && "message" in e.response.data && typeof e.response.data.message === "string";
}try {
} catch (e) {
if (hasErrorMessage(e)) {
console.log(e.response.data.message); // message: string
} else {
// Unknown error 핸들링
}
}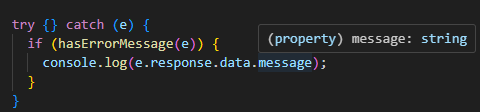
그러면 위와 같이 error 객체의 타입이 추론 가능해지게 됩니다. 자동 완성 기능도 지원되고요.
이렇게 쓰게 되면 타입 안정성이 증가하므로 예상치 못한 오류가 발생했을 때 오류를 방지할 수 있습니다. 코드 가독성도 높아지고, 적절히 재활용할 수도 있습니다. 그런데, any 타입으로 지정했다면 사용하지 않았을 함수들이 사용되니 런타임에 약간의 오버헤드가 발생할 수는 있습니다.
상황에 따라 적절히 사용해주면 되겠지만, 위의 경우는 에러가 발생하는 경우에만 함수를 호출하기 때문에 사용자가 오버헤드를 느낄만한 정도는 아닐 것으로 판단되어 error 객체의 타입을 추론하기 위해 적절히 사용하고 있습니다.
위에서 설명한 Type Guard 외에도 여러 가지 방법을 더 사용할 수 있습니다. instanceof, typeof, in 등의 키워드를 Type Guard로 사용할 수도 있는데요. 관련 내용을 더 자세히 설명하는 article을 공유하는 것으로 설명을 대체하겠습니다.
2. Function Overloads
함수를 작성하다 보면 특정 함수가 여러 형태의 인자를 받게 만들고 싶은 경우가 발생합니다. 타입스크립트에서는 함수의 시그니처를 여러 개 선언하는 Function Overloads 기능을 활용하여 다양한 방식으로 호출할 수 있는 함수를 선언할 수 있습니다.
React Hook도 Function Overloads를 이용해 다양한 인자를 받는 Hook들을 제공하도록 작성 되어 있는데요. 그 중 하나인 useState는 초깃값이 있거나 없는 경우에 대한 시그니처가 다릅니다.
// useState
function useState<S>(initialState: S | (() => S)): [S, Dispatch<SetStateAction<S>>];
function useState<S = undefined>(): [S | undefined, Dispatch<SetStateAction<S | undefined>>];왜 이렇게 나눠서 선언한 것일까요? 하나의 useState에서 initialState를 Optional로 제공하면 안 될까요?
function useState<S>(initialState?: S | (() => S)): [S, Dispatch<SetStateAction<S>>];이런 식으로요. 이렇게 설정하면 굳이 Function Overloads로 두 가지 경우를 작성하지 않아도 초깃값이 있거나 없는 경우 모두 제어할 수 있지 않을까요?
Function Overloads 기능을 사용한 이유는 매개변수를 Optional로 설정한 경우 추론되는 S의 타입이 undefined로도 추론되기 때문입니다.
function useCustomState<S>(initialState?: S | (() => S)): [S, Dispatch<SetStateAction<S>>] {
const [state, setState] = useState(initialState);
return [state, setState] as const;
}
const [state, setState] = useCustomState(0); // state: number | undefined
이러면 초깃값을 number 타입으로 넘겨서 number 타입으로만 사용된다고 하더라도 undefined인 경우에 대한 코드를 작성해줘야 하는 번거로움이 생깁니다. 사용자는 불필요한 코드들을 같이 작성해줘야 하겠죠.
여기서 Function Overloads를 사용하면 이러한 문제를 해결할 수 있습니다.
function useCustomState<S = undefined>(): [S | undefined, Dispatch<SetStateAction<S | undefined>>];
function useCustomState<S>(initialState: S | (() => S)): [S, Dispatch<SetStateAction<S>>];
function useCustomState<S>(
initialState?: S | (() => S),
): [S | undefined, Dispatch<SetStateAction<S | undefined>>] | [S, Dispatch<SetStateAction<S>>] {
const [state, setState] = useState(initialState);
return [state, setState] as const;
}
const [state, setState] = useCustomState(0); // state: number
const [string, setString] = useCustomState<string>(); // string: string | undefined

이렇게 작성해주면 매개변수를 optional로 지정한 것과 똑같이 initialState를 주거나 안 줄 수 있는데, 두 경우 모두 적절하게 타입 추론이 됩니다.
Function Overloads 활용하기
Function Overloads 기능은 어디에 활용하면 좋을까요? 개인적으로 자주 활용하는 기능은 아니지만, Zustand를 사용할 때 유용하게 사용하고 있습니다.
Zustand는 전역 상태 라이브러리로 스토어를 생성한 다음 해당 스토어를 매개변수 없이 호출하면 모든 전역 상태를 구독하는 특징을 갖고 있는데요.
import { create } from "zustand";
interface BearState {
bears: number;
increase: (by: number) => void;
}
const useBearStore = create<BearState>((set) => ({
bears: 0,
increase: (by) => set((state) => ({ bears: state.bears + by })),
}));
const { bears, increase } = useBearStore(); // 전체 상태를 가져옴이렇게 사용하는 경우 특정 상태 하나만 변경되어도 전체 스토어가 변경된 것으로 판단하고 불필요한 리렌더링이 발생합니다.
그래서 useBearStore 같은 스토어 생성 함수는 export 하지 않고, selector로 선택한 값만 export 하는 방식이 권장되고 있어요.
export const bears = useBearStore((state) => state.bears);
export const increase = useBearStore((state) => state.increase);그런데 상태가 많아질수록 export하는 코드들도 많아지게 되니 생각보다 불편합니다. 그냥 useBearStore를 가져오기 해서 useBearStore((state) => state.bears) 형태로 사용하면 되지 않을까요? 많은 데이터들을 모두 export 키워드로 작성해주는 것도 코드 가독성이 좋지는 않을 것 같아요.
그래서 여기에 Function Overloads를 사용합니다.
export function useBears(): BearState["bears"];
export function useBears<T>(selector: (state: BearState) => T): T;
export function useBears(selector = (state: BearState) => state.bears) {
return useBearStore(selector);
}zustand 생성 함수로 만든 useBearStore는 export 하지 않고, export해서 사용할 useBears hook을 따로 만들어서 사용합니다. selector가 없는 경우 bears를 반환하고 selector가 있는 경우 selector에 의한 state 반환이 가능해지는 것이죠.
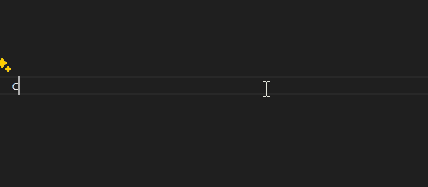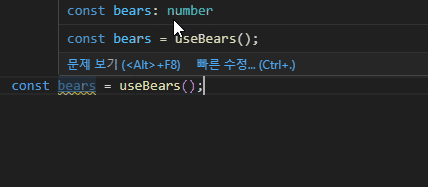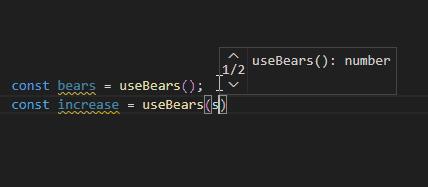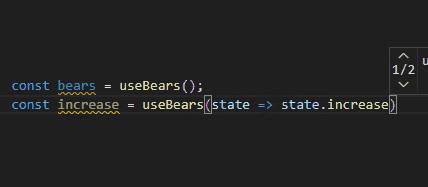
이렇게 쓰면 전체 State를 구독해 불필요한 리렌더링이 일어나는 경우가 없어집니다. Selector도 추론이 잘되고 Selector 없이 호출한 경우에도 잘 추론이 되는 것을 확인할 수 있습니다.
그러면, 복잡하게 Function Overloads 기능을 활용하지 않고 하나의 함수만 작성하는 것과는 뭐가 다를까요? 차이를 알아보기 위해 한 번 작성해 보겠습니다.
export function useBears<T>(selector: (state: BearState) => T = (state: BearState) => state.bears as T) {
return useBearStore(selector);
}
const bears = useBears(); // bears: unknown
const numberBears = useBears<number>(); // numberBears: number
const stringBears = useBears<string>(); // stringBears: string
const increase = useBears((state) => state.increase); // (by: number) => void이렇게 작성하면 함수에 인자를 넘겨주지 않았을 때 bears의 타입 추론이 제대로 이루어지지 않습니다. Generic을 직접 넘겨서 해결할 수는 있는데, 어떤 타입을 넘겨도 에러가 발생하지 않기에 Human Error가 발생할 확률도 남아있게 됩니다.

캡처에서 보이듯이 bears는 실제로 number 타입인데 unknown으로 추론되고 있고, 제네릭을 통해 number 타입으로 보정할 수는 있지만, number가 아닌 타입으로 제네릭 타입을 넘겼을 때도 에러가 발생하지 않습니다.
export function useBears(): BearState["bears"];
export function useBears<T>(selector: (state: BearState) => T): T;
export function useBears(selector = (state: BearState) => state.bears) {
return useBearStore(selector);
}Function Overloads로 지정한 함수를 사용하면 이런 경우도 에러를 뱉어 정확하게 추론되는 것을 확인할 수 있습니다.

이런 식으로 Function Overloads를 잘 활용하게 되면 불필요한 코드 중복을 줄이고 안정성이 높은 코드를 작성할 수 있습니다.
3. Generic
제네릭 타입은 단일 타입이 아닌 다양한 타입으로 작동하는 함수나 컴포넌트에서 사용할 수 있는데요. 간단한 수준의 제네릭은 이해하기가 쉬워서 대부분 적절히 사용할 수 있을 것 같아요.
function get<T>(state: T) {
return state;
}
const state = get({ id: 1 }); // state: { id: number }
const state2 = get(10); // state2: numberstate와 state2는 같은 함수를 사용하지만 반환되는 값의 타입은 각각 전달한 매개변수의 타입으로 결정됩니다.
이 정도 함수는 어렵지 않은데요. 상대적으로 더 복잡한 고차 함수나 고차 컴포넌트를 쓰는 경우 제네릭 타입이 익숙하지 않아서 그런 것인지 any 타입을 사용하는 코드들이 종종 보였습니다. 고차 함수, 고차 컴포넌트 모두 적절히 제네릭을 활용하지 않으면 반환된 함수나 컴포넌트의 타입이 제대로 추론되지 않는 문제가 생깁니다.
Debounce 유틸 함수 타입 개선하기
const debounce = (fn: Function, ms = 300) => {
let timeoutId: ReturnType<typeof setTimeout>;
return function (this: any, ...args: any[]) {
clearTimeout(timeoutId);
timeoutId = setTimeout(() => fn.apply(this, args), ms);
};
};이 코드는 30 seconds of typescript 페이지에서 확인할 수 있는 debounce 함수입니다. 이 함수를 호출하면 중첩된 함수를 반환하는 구조로 되어 있는데, 함수만 봐선 문제가 없어 보이죠?
const add = (a: number, b: number) => {
console.log(a + b);
};
const debouncedAdd = debounce(add, 200); // debouncedAdd: (this: any, ...arg: any[]) => void;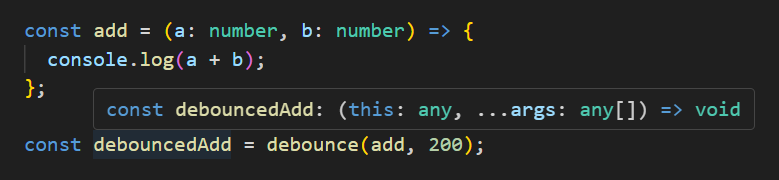
하지만 실제 사용해보면 타입 추론이 제대로 되지 않습니다. debouncedAdd 함수는 200ms가 debounce되는 기능은 제대로 수행하지만 매개변수 타입들이 제대로 추론되지 않죠. 이런 경우 코드를 작성하는 시점에는 문제가 발생하지 않지만, 타입을 검사한 것이 아니므로 런타임에서 오류가 발생할 가능성이 남아있게 됩니다.
console.log(debouncedAdd(2, 3)); // 5
console.log(debouncedAdd(null, undefined)); // ??
console.log(add(null, undefined)); // error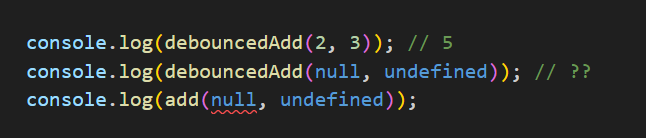
이렇게 number가 아닌 타입의 값이 들어왔을 때 아무런 에러를 잡아내지 못합니다. 그냥 add 함수를 썼다면 number가 아닌 타입의 값이 전달되면 에러를 보여주겠죠.
이런 함수를 제네릭을 활용하여 추론이 되도록 수정해 봅시다.
const debounce = <T extends (...args: any[]) => void>(fn: T, ms = 300) => {
let timeoutId: ReturnType<typeof setTimeout>;
return (...args: Parameters<T>) => {
clearTimeout(timeoutId);
timeoutId = setTimeout(() => fn.apply(this, args), ms);
};
};- fn의 타입을
Function대신T extends (...args: any[]) => void타입으로 지정 - 반환하는 함수의 매개변수
…args: any[]타입을Parameters<T>로 지정
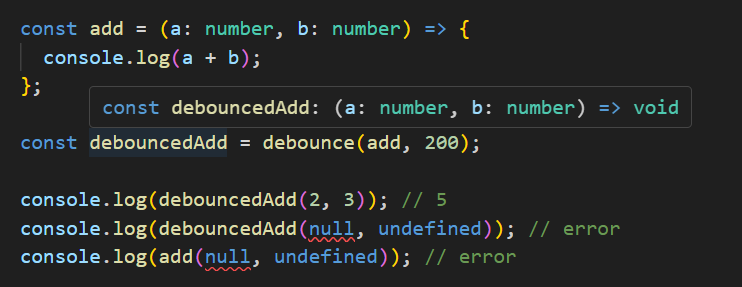
수정하니 반환된 함수의 타입도 적절히 추론되었죠. 이런 방식으로 제네릭을 유용하게 사용할 수 있습니다.
이런 경우 사용할 수 있는 빌트인 타입들이 아래와 같이 있으니 참고해 주시면 감사하겠습니다.
Parameters<Type>: 함수 타입의 매개변수에 사용된 타입으로 구성된 타입을 생성합니다.ReturnType<Type>: 함수 타입의 반환 타입으로 구성된 타입을 생성합니다.React.ComponentProps<Type>: Type 요소의 프로퍼티로 구성된 타입을 생성합니다.
4. infer
타입스크립트를 사용하다 보면 타입이 작성되어 있지 않은 Array의 Item 타입이나 함수의 매개변수 타입 등을 알고 싶은 경우가 생깁니다.
예를 들어
const someFunc = (a: { id: number }, b: boolean) => // ...
const someArray = [
{ id: 1 },
{ id: 2 },
];someFunc 함수의 첫 번째의 타입이나 someArray의 각의 아이템들은 { id: number } 타입인데, 이 타입을 추론하고 싶은 경우가 있을 수도 있겠죠. 라이브러리 함수나 타입을 사용한다든지 일부 타입을 특정 유형에서 추출하고 싶은 경우가 생깁니다.
그럴 때 infer 키워드를 사용합니다. infer는 조건부 유형 내에서 다른 유형 구조에서 유형을 추출하는 데 사용됩니다. 정의만 봐선 무슨 뜻인지 이해하기가 어려운데 어떤 식으로 사용할 수 있을지 알아보겠습니다.
함수의 매개변수 타입과 반환 값의 타입 추론하기
type ReturnType<T extends (...args: any) => any> = T extends (...args: any) => infer R ? R : any;빌트인으로 사용 가능한 ReturnType은 infer 키워드를 사용하고 있습니다. ReturnType의 제네릭 타입은 함수 형태인데, 이 함수의 반환되는 타입 R을 추론할 수 있으면(infer R) R을 사용하고 아닌 경우 any가 됩니다.
type TypeA = ReturnType<() => string>; // string
function noop() {}
type TypeB = ReturnType<typeof noop>; // void이렇게 특정 함수의 반환되는 값의 타입을 함수로부터 추출하여 할당할 수 있게 됩니다.
같은 방식으로 매개변수의 타입을 추론하는 것도 가능한데요.
function add(a: number, b: number) {
return a + b;
}
type GetFunctionFirstArgs<T> = T extends (...args: [infer U, ...any[]]) => any ? U : never;
type TypeA = GetFunctionFirstArgs<typeof add>; // TypeA: number비슷한 방식을 나열하여 두 번째, 세 번째 매개 변수의 타입도 알아낼 수 있겠죠.
배열의 요소 타입 추론하기
type ComplexObjectArray = {
a: number;
b: {
c: string;
d: boolean;
};
}[];이런 타입이 있다고 가정해 봅시다. 저는 배열 내부에 들어가는 요소의 타입을 알고 싶어요. 그런 경우에도 infer 키워드를 이용해 추론할 수 있습니다.
type ComplexObjectArray = {
a: number;
b: {
c: string;
d: boolean;
};
}[];
type ArrayType<T> = T extends (infer Item)[] ? Item : T;
type ArrayItem = ArrayType<ComplexObjectArray>; // ArrayItem: { a: number; b: { c: string; d: boolean; } }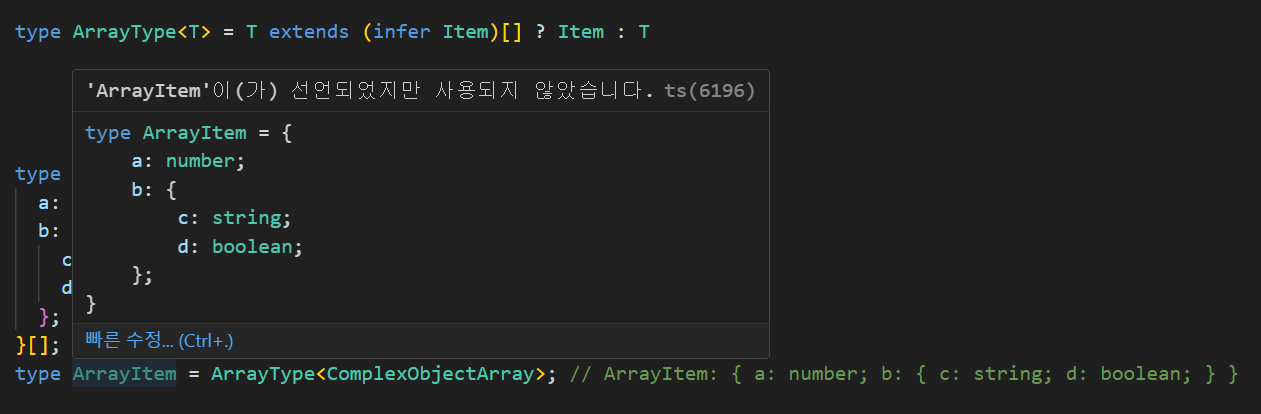
ArrayType<T> 타입은 제네릭 T 타입이 배열 형태인데, 이 배열의 아이템 타입을 추론할 수 있으면 그 타입을 사용합니다.
React 컴포넌트 Props 타입 추론하기
type InterProps<T> = T extends React.ComponentType<infer T> ? T : never;
const Component = (props: { name: string; age: number }) => {
return <></>;
};
type ComponentProps = InterProps<typeof Component>; // { name: string; age: number }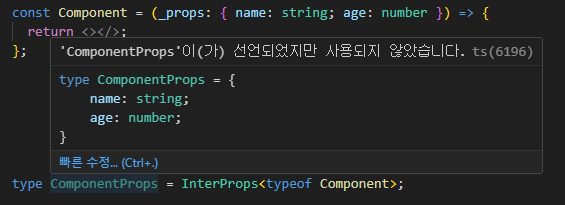
컴포넌트의 Props로 추론할 수 있습니다. 이를 잘 활용하면 컴포넌트는 제공하지만 Type을 따로 제공하지 않는 라이브러리를 사용할 때 적절하게 쓰일 수 있습니다.
중첩된 배열, 객체 내부에 존재하는 모든 타입 추론하기
infer 키워드를 사용하는 타입을 재귀적으로 사용하면서 중첩된 객체에 사용된 모든 값의 타입을 추론할 수도 있습니다.
중첩된 배열의 값 타입 추론
type FlattenType<T> = T extends readonly (infer U)[] ? FlattenType<U> : T;
const nestedArray = [1, ["abc", [null]], [undefined], [[true]]] as const;
type NestedArrayType = FlattenType<typeof nestedArray>; // true | 1 | "abc" | null | undefined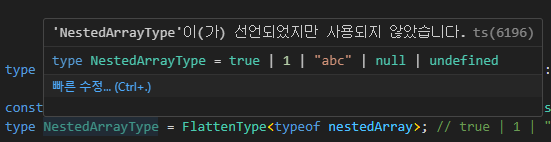
중첩된 객체의 Value 타입 추론
type FlattenObjectValue<T> = T extends Record<string, infer U> ? FlattenObjectValue<U> : T;
const nestedObject = {
a: 1,
b: {
c: "d",
e: {
f: "g",
h: {
i: "j",
},
},
},
} as const;
type NestedObjectValueType = FlattenObjectValue<typeof nestedObject>; // 1 | "g" | "d" | "j"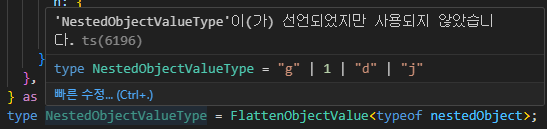
이런 식으로 Type 자체를 재귀적으로 사용하면서 중첩된 배열이나 객체의 key, value 등에 대한 타입을 모두 추론해올 수 있습니다.
함수의 매개 변수 타입이나 배열 아이템 타입, 객체 Key, Value 타입, 컴포넌트 Props 타입, 프로미스의 반환 타입 등을 추출하고 싶다면 infer 키워드를 이용해 각각 Utility Type처럼 선언해준 후 사용하면 해당 타입들을 쉽게 추론할 수 있습니다.
정리
- Type Guard 함수를 통해 타입 좁히기가 가능하다.
- Type Guard 함수는
Boolean을 반환하고,true인 경우 타입이 지정한 값으로 추론된다. - Function Overloads 기능을 통해 함수의 다양한 인자들을 받도록 선언할 수 있습니다.
- Generic을 잘 활용하여 매개변수나 Props, 반환되는 함수나 컴포넌트의 타입을 추론할 수 있다.
- infer 키워드를 통해 조건부 유형 내에서 다른 유형 구조에서 유형을 추출할 수 있다.
이번 글의 내용은 타입스크립트를 사용할 때 활용하는 방법들에 대한 내용을 담았습니다. 단순히 타입을 작성하고 그 타입 그대로 지정하여 사용하는 일이 훨씬 많아서 대체로 어려움은 없지만, 이 글의 내용을 활용할만한 상황에 처해졌을 때 타입스크립트 기능을 잘 모른다면 시간이 너무 지체되니 any 타입으로 지정하고 넘어가는 경우도 많아져서 한 번 정리해 보았습니다.
타입스크립트는 안정성이 높고 편리하지만, 타입을 지정하기 어려운 특정 상황에서는 편리함이 잊힐 만큼 시간이 오래 걸리기도 합니다. 그럴 때도 적절하게 타입을 잘 활용하기 위해 타입스크립트 기능을 잘 익히는 것도 중요하다고 생각합니다.
참조
