
💡 이 문서를 읽으면 아래 질문들에 답변할 수 있어요!
1. AWS Lambda가 무엇인가요?
2. AWS Lambda는 어떤 문제를 해결하기 위해 등장했나요?
3. AWS Lambda을 사용하면 어떤 점이 좋나요? - Lambda의 장점
4. AWS Lambda의 한계는 무엇인가요? - Lambda의 단점
5. AWS Lambda는 어떻게 동작하나요?Overview - What is Lambda?
AWS에서 제공하는 서버리스 컴퓨팅 서비스
[용어 정리]
- 서버리스란?
개발자의 눈에는 서버가 보이지 않는 형태로 서버를 제공해주는 방식
개발자는 서버를 프로비저닝하거나 관리할 필요가 없다.
- 프로비저닝이란?
리소스를 바로 사용할 수 있도록 대기시켜두는 것
어플리케이션을 실행하기 위해 필요한 모든 리소스들(메모리 / CPU / OS / 스토리지 + 코드 실행에 필요한 구성 및 패키지 등등)을 서버에 설치하고, 실행가능한 상태로 준비하는 과정
Lambda는 다음과 같은 문제들을 해결하기 위해 등장
-
서버 유지 및 관리에 대한 부담을 줄이기 위해 →
생산성 향상예전에는 서버가 필요한 서비스를 운영하기 위해 개발자들이 직접 서버를 운영+관리했다.
개발자들은 어플리케이션을 실행하기 위한 서버를 준비하고, OS를 설치하고, 서비스 운영에 적합한 CPU, 메모리, 스토리지 스펙 등을 예상하여 직접 설정해주어야 하는 부담이 있었다.한편, Lambda는 개발자들이 서버를 프로비저닝하거나 유지관리 하지 않고도 코드를 실행할 수 있도록 한다. 즉, 클라우드 제공업체인 AWS에서 어플리케이션을 실행하는데 필요한 리소스들을 알아서 관리해주기 때문에, 개발자들은 서버 관리에 대한 부담을 덜 수 있게 되었다.
⇒ 특히 오토 스케일링과 관련된 부분을 알아서 관리해주기 때문에 트래픽을 예상하여 미리 서버의 스펙을 늘려놓거나 하는 식의 대응을 할 필요가 없어졌다.
이에 따라, 개발자들은 어플리케이션 개발에만 집중할 수 있는 환경을 만들 수 있게 되었고, 이는 개발 속도 향상 (=생산성 향상)으로 이어졌다.
-
서버 비용에 대한 부담을 줄이기 위해 →
비용 절감예전에는 서버 기반 서비스를 운영하기 위해서는 서버가 항상 떠있어야 했으며, 서버가 실행되는 동안 계속해서 비용이 발생하는 구조였다. 이는 트래픽이 없는 시간 동안에도 서버 비용이 청구된다는 부담이 있었고, 특히 비교적 영세한 서비스(유저 트래픽이 미미한 서비스)들에게는 더욱 부담스러운 부분이었다.
Lambda는 기존의 서버 비용 청구 시스템을 개선하기 위해 등장한 서비스 중 하나로, 다음과 같은 동작을 통해 비용이 절감된다는 특징이 있다.
- 외부에서 요청이 들어오면 Lambda가 트리거되어 인스턴스가 하나 뜸(프로비저닝 → 실행)
- 코드 실행이 완료되면, 인스턴스는 다음 요청을 기다리며 유휴 상태 (idle)가 됨
⇒ 요청이 다시 들어왔을 때, 유휴상태인 인스턴스가 있으면 해당 인스턴스가 요청을 받아 코드를 실행
⇒ 유휴상태가 너무 오랫동안 지속되면 더이상 요청이 없을것이라 판단해 인스턴스가 shutdown됨
Lambda는 기본적으로
코드가 실행되는 동안에 대해서만 비용이 청구된다. 즉, 요청이 처리되는 시간 외에는 비용이 청구되지 않아 서버 비용의 부담이 덜하며, 특히 유저 트래픽이 적은 서비스 환경에서는 매우 큰 비용 절감의 효과를 얻을 수가 있다.
-
마이크로서비스 아키텍처 + 이벤트 기반 아키텍처의 유행에 대응하기 위해
2010년대 초반, 웹 어플리케이션 분야가 급격히 성장하면서 모놀리틱한 아키텍처의 한계에 직면했다. 모놀리틱 아키텍처는 어플리케이션을 하나의 코드로 관리하는 구조이기 때문에 확장성이나 유지보수 관점에서 한계가 명확했는데,
- 모놀리틱 아키텍처의 한계 (1) 서비스 확장이 어려움 (2) 한 부분을 고치면 다른 부분에 영향을 미칠 가능성이 농후함 (3) 부분 수정을 하더라도 전체적으로 코드를 테스트하고 보수해야하기 때문에 배포 주기가 길어짐
이러한 한계에 유연하게 대처하기 위해 적극 도입된 것이 바로
마이크로서비스 아키텍처이다.마이크로서비스 아키텍처에서는 각각 독립적인 기능을 수행하는 작은 서비스들을 여러개 구성하여 하나의 시스템을 구성하는 방식으로, 확장성이 뛰어나고 관리할 소스코드의 규모가 작아 유지보수에도 용이하다는 장점이 있다.
이러한 마이크로서비스 아키텍처에서 서로 다른 서비스들이 통신하기 위해 이벤트 기반 메시징 방식을 많이 사용하는데...
이벤트 기반 아키텍처는 어떠한 이벤트 (스토리지에 파일이 생성되는 이벤트 / 데이터베이스에 데이터가 적재되는 이벤트 등)에 의해 트리거되어 어플리케이션이 실행되는 구조로, 실시간 데이터 처리가 필요한 경우에 적합한 패턴이다. 클라우드 서비스가 보편화되고, 사용자의 요청이나 어떠한 이벤트가 발생했을 때 즉각적으로 응답을 요구하는 경우가 많아지면서 이벤트 기반 아키텍처가 유행하기 시작했다.
AWS Lambda는 이러한 마이크로서비스 아키텍처 및 이벤트 기반 아키텍처가 유행하면서 함께 등장/성장한 클라우드 서비스 중 하나로, 유연성과 확장성이 중요한 서비스에 적용하기에 좋다.
- 모놀리틱 아키텍처의 한계 (1) 서비스 확장이 어려움 (2) 한 부분을 고치면 다른 부분에 영향을 미칠 가능성이 농후함 (3) 부분 수정을 하더라도 전체적으로 코드를 테스트하고 보수해야하기 때문에 배포 주기가 길어짐
이러한 특징 덕분에 AWS Lambda는 실무에서 특히 다음과 같은 상황에서 활용하기 좋다.
- MVP를 빠르게 개발하고 테스트해야하는 환경
- 인프라 관리 팀 (DevOps팀)이 따로 없는 조직
- 유연성과 확장성이 강조되어야하는 서비스 혹은 시스템 (마이크로서비스 아키텍처)
- 코드를 계속 실행시키지 않고 특정한 시기에만 실행시킬 때 (배치)
⇒ 람다는 코드가 실행되는 동안에만 비용이 발생하기 때문에 비용 절감에 유리함- 특정 이벤트가 발생한 경우에만 코드를 실행하고 싶은 경우
Why Lambda?
람다를 사용하면 뭐가 좋을까?? 왜 사용할까??
1. 비용 절감의 효과
- Lambda는 평소에는 인스턴스를 띄우지 않고, 이벤트가 발생한 경우에만 인스턴스를 프로비저닝하여 코드를 실행한다. 요청이 한동안 들어오지 않아 유휴상태가 지속될 경우, 인스턴스는 shutdown된다.
- Lambda는 코드 실행 시간(1ms 단위로)과 인스턴스에 할당된 메모리에 비례하여 요금이 청구된다. 따라서 대부분의 경우에는 항상 서버를 띄워야하는 EC2보다 비용이 훨씬 적게 든다.
⇒ 물론, 요청 시간이나 메모리 등을 고려했을 때, EC2보다 비용이 많이 발생하는 임계점을 넘어가면 EC2가 비용이 더 적게 나오는 경우도 있다. 이 때는 Lambda의 비용을 최적화하거나 다른 서비스로 인프라를 옮길 것을 고려해야한다.
2. 생산성 향상의 효과
- Lambda는 서버리스 컴퓨팅 서비스 중 하나로, 개발자가 서버의 유지 관리에 신경쓸 필요가 없다는 특징이 있다. 따라서 개발자는 어플리케이션 개발에만 좀 더 집중할 수 있는 환경이 조성되고, 이는 생산성의 향상으로 이어진다.
- 때문에 DevOps 팀이 없어서 전문적으로 인프라를 관리하기 어렵거나, MVP 단계의 서비스를 빠르게 테스트하거나, Growth 조직과 같이 가설-검증이 빠르게 이루어져야하는 상황에서는 Lambda를 활용하기에 매우 적합하다.
3. 확장성과 유연성
- Lambda는 이벤트에 의해 트리거되기 때문에 사용자의 요청에 대한 즉각적인 응답이나 처리를 해야하는 경우에 대응하기 좋다.
- 특히 마이크로서비스 아키텍처에서는 기능 단위로 서비스를 잘게 쪼개서 배포하기 때문에 코드가 비교적 가벼울텐데, 이 때 배포나 유지보수에 이점이 있는 람다를 안 쓸 이유는 없음
- 작은 단위로 서비스를 분리해 람다로 배포하고, 서로 이벤트 기반의 메시지를 주고받으며 트리거하는 구조로 시스템을 구성하기에 좋다.
Limitation
위와 같은 상황에서는 유용하게 사용할 수 있지만, 람다에는 한계 역시 존재하니 해당 내용들에 대해 알아두고, 해당 내용이 서비스 배포에 있어서 커다란 이슈가 된다면 람다 사용을 피하는 것이 좋다.
1. 배포 패키지 사이즈 제한
- 압축 시 50MB, 압축 해제 시 250MB의 제한
⇒ 그 이상의 사이즈를 갖게 되면 Lambda 사용이 불가능 - 단, (도커) 컨테이너 이미지로 말아서 올리면 10GB까지도 가능하긴 함
2. 실행 시간이 최대 15분 (900초) 제한
- 15분이 넘어가는 경우 connection이 자동으로 끊김.
- 15분 이상 실행되어야하는 배치성 작업에는 Lambda를 사용하지 않는 것이 좋음
3. 처음 호출되는 인스턴스에 대해서는 cold start를 하기 때문에 초기 latency가 발생
- 이미 떠있는 인스턴스에 대해서는 warm start가 가능하지만, 유휴상태인 인스턴스가 없는 경우 항상 cold start를 하기 때문에 프로비저닝 시간으로 인한 초기 latency가 발생할 수 있다.
특히 1, 2번의 문제 때문에 DB 백업, 영상 인코딩 같이 많은 컴퓨팅 용량이 단시간내에 많이 필요할경우 상당히 비효율적이다.
How Lambda Works?
람다의 동작 방식과 생애 주기에 대해 알아본다.
1. 람다의 이벤트 처리 방법 (Work Flow)
외부로부터 어떤 이벤트(요청)가 들어왔을 때, 람다는 다음과 같은 순서로 해당 이벤트를 처리한다.
1. 실행환경 (컨테이너) 준비
- 실행환경(컨테이너)로 코드를 다운로드 받음
- Lambda에 설정된 Memory, Runtime, Configuration 대로 환경을 세팅
2. 초기화 코드 (Init Code)를 실행
3. Lambda 함수 코드 (이벤트 핸들러)를 실행하여 이벤트를 처리
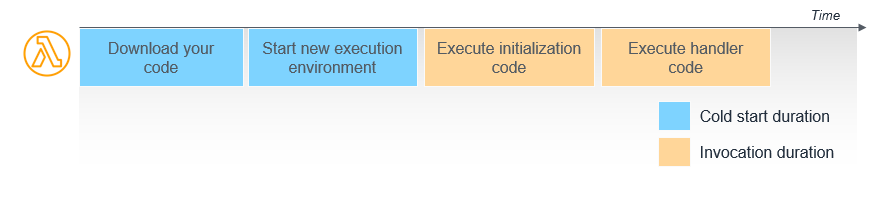
파란 부분이 1번에 해당하는 실행환경 준비 기간이고, 이 기간을 보통 Cold Start 기간이라고 한다.
⇒ 근데 다른 자습서 내용을 보니까 initialization code까지도 cold start라고 취급하는 경우가 있었다. 사실상 이벤트 핸들러가 실행되기 전까지를 cold start라고 보면 될 것 같다.
⇒ Cold Start에 대한 자세한 내용은 여기를 참고해보자.
1번 기간은 Lambda 실행시간에 포함되지 않으므로 비용이 청구되는 기간이 아니다.
하지만 새로운 실행환경(컨테이너)이 세팅될 때, 해당 기간 만큼 초기 latency가 발생할 수 있다는 점을 유념해두어야 한다.
2, 3번에 해당하는 기간은 Lambda 실행시간에 포함되므로, 해당 기간에 대해서는 요금이 발생한다.
다만, Initialization Code 부분의 경우, 첫 번째 이벤트에 대해서만 실행되는 코드이고, 두 번째 호출부터는 실행되지 않는다. 따라서 2번 코드도 Cold Start에 영향을 미치는 부분이라고 생각하면 될 것 같다.
초기화 코드(init code)란, 람다 함수 코드 내에서 호출하는 라이브러리들을 준비하고, global 변수들을 메모리 상에 올려두는 등의 초기화 작업을 수행하는 코드이다. 하나의 실행환경(컨테이너)에 대해 최초 request(이벤트)가 들어왔을 때 호출된다.
하나의 실행환경(컨테이너)은 실행 시간동안 하나의 이벤트만 처리할 수 있다. 따라서 만약 어떤 실행환경(컨테이너)가 이벤트를 처리 중이라면, 해당 실행환경(컨테이너)는 Freeze된다. 이후 이벤트 처리가 완료되면, 해당 실행환경(컨테이너)은 유휴 상태(Idle)가 되어 다음 이벤트를 처리할 수 있게 된다.
하나의 실행환경(컨테이너)은 특정 시간동안 리소스 관리 및 성능 향상을 위해 유지된다.
⇒ 이 때 유지되는 시간은 non-deterministic하다. 즉, 개발자는 이 시간이 얼마동안 유지되는지 정확하게는 알 수 없다. 개발자들 피셜 대충 5분 정도라고 한다.
따라서 이 시간동안 동일한 Lambda 함수에 대해 다른 이벤트가 들어오면, 우리는 해당 실행환경(컨테이너)를 재사용할 수가 있다. 즉, warm start가 가능하다.
즉, 실행환경(컨테이너)에 대한 두 번째 요청부터는 이미 cold start 부분과 init code 부분이 완료된 상태이기 때문에 일반적으로 좀 더 빨리 request(이벤트)를 처리할 수 있다.
⚠️ 람다의 실행환경(컨테이너) 재사용은 유용하지만, 언제 종료될지 그 정확한 주기가 불분명하기 때문에 성능 최적화를 위해서는 이에 의존해서는 안된다.
2. 람다의 수명주기 (Life Cycle)
위에서 살펴본 이벤트 처리 방법 (workflow)와 겹치는 내용이지만, 이 부분은 람다의 life cycle에 대해 좀 더 초점을 두고 정리한다.
람다는 정확히 3단계의 life cycle을 갖는다.
(1) init 단계
위에서 언급한 cold start부분이다. 새로운 실행환경(컨테이너)를 요청하여 준비된 실행환경(컨테이너)에 람다 함수 코드를 다운로드 받고, 사용자가 람다 함수를 생성했을 때 지정해둔 런타임, 메모리, configuration 등을 세팅하는 과정이다. 또한, 람다 함수 코드에서 init code 부분(라이브러리 및 global 변수 세팅)을 실행한다.
(2) invoke 단계
실제 람다 함수 핸들러가 호출되어, 코드가 실행되는 단계이다. 하나의 request(이벤트)에 대한 처리가 완료되면, 람다는 다음 request(이벤트)를 처리할 준비를 한다.
(3) shutdown 단계
람다 함수 실행을 위해 세팅되어 있던 실행환경(컨테이너)가 죽는 단계이다. 람다 함수는 일정 기간동안 호출을 받지 않으면, 런타임을 종료하고, 실행환경(컨테이너)를 제거한다.
3. 람다의 통신 과정
마찬가지로, 람다의 수명주기 및 이벤트 처리 (workflow)와 내용이 겹치지만, 이 부분은 sequential vs. concurrent 통신 방식의 차이에 대해 정리하는 부분이므로 한 번 더 정리하도록 한다.
(1) Sequential한 방법
외부에서 어떠한 요청이 들어오면, Lambda는 새로운 실행환경(컨테이너)을 띄우고, 해당 실행환경에서 람다 함수의 코드를 실행할 수 있도록 이벤트를 발생시킨다. 이 때, 하나의 컨테이너는 하나의 이벤트만 처리 가능하므로, 해당 컨테이너가 이벤트를 처리하는 동안에는 freeze 상태가 된다.
이벤트 처리가 완료되면, 해당 컨테이너는 idle 상태가 된다.
이 때 만약 컨테이너의 idle 상태가 너무 오랜 시간동안 유지된다면 해당 컨테이너는 폐기(shutdown)된다.
또는, 하나의 이벤트를 너무 오랜 시간동안 처리하게 된다면, 컨테이너는 해당 이벤트를 오랫동안 처리한 후 폐기(shutdown)된다.
(2) concurrent한 방법
사실상, 람다는 concurrent하게 동작한다. 하지만 위에서 언급한 바와 같이, 하나의 실행환경(컨테이너)은 한 번에 하나의 이벤트(요청)만 처리한다. 따라서 이벤트(요청)를 처리하는 동안 해당 실행환경(컨테이너)은 freeze된다.
이 때, 만약 실행환경(컨테이너)들이 전부 freeze상태임에도 불구하고 새로운 이벤트(요청)가 계속 들어오는 경우, 람다는 새로운 실행환경(컨테이너)을 가져오도록 트리거한다. (즉, 새로운 인스턴스를 띄운다.) 이런식으로, concurrent하게 처리할 이벤트(요청)들에 대해 실행환경(컨테이너)는 계속해서 생성된다.
당연히, 이벤트가 발생할 때마다 인스턴스를 새로 띄워서 실행환경을 매번 세팅하는 것은 매우 비효율적이다. Lambda는 이를 효율적으로 처리하기 위해 실행환경을 재사용할 수 있도록 했으며, Lambda는 계속해서 발생하는 이벤트들에 대해 다음과 같이 동작한다.
만약 idle한 다른 실행환경이 존재한다면, 해당 실행환경(컨테이너)에서 이벤트를 받아 처리할 수 있다. 새로운 실행환경이 만들어지는 경우는 idle한 실행환경이 없는 경우이다.
위에서도 람다의 한계에 대해 언급했지만, 람다의 생애주기와 workflow를 언급했으니 한 번 더 짚고 넘어가자. Lambda는 유휴 상태인 실행환경(컨테이너)이 없는 경우, 계속해서 인스턴스를 띄워 실행환경을 세팅하게 된다. 이 때, 다음과 같은 문제들이 있을 수 있는데,
1. 새로운 실행환경(컨테이너)을 트리거하고 준비할 때마다 cold start를 겪어야 한다.
AWS에서는 람다 함수마다 concurrent 인스턴스 용량을 할당할 수 있도록 reserved concurrency와 provisioned concurrency를 설정할 수 있도록 해두었다. 이에 대한 자세한 내용은 여기를 참고한다.
2. concurrent하게 띄울 수 있는 실행환경(컨테이너) 수에 limit이 존재한다.
리전별 concurrent 인스턴스 할당량은 1000개에서 시작한다.하지만 이 limit은 AWS에 요청하여 늘릴 수 있긴 하다. (근데 요청하면 최대 2주 걸린다고 하니, 필요하다면 미리 요청해두도록 하자.)
4. (참고) 버스트 동시성 할당량
concurrency limit이 일정 수준에 도달할 경우(burst limit에 도달할 경우), 그 이후부터는 매분 500개(리전마다 다르지만, 우리나라 기준으로는 500개)씩 실행환경(컨테이너)가 확장된다. 이러한 확장은 모든 request(이벤트)를 동시에 충분히 처리할 수 있을 때까지, 또는 concurrency limit에 도달할 때까지 계속 확장된다.
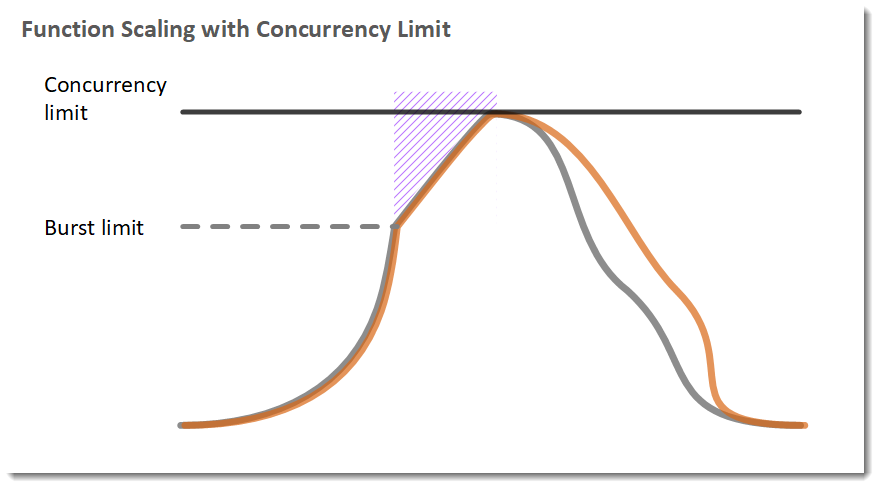
5. Concurrency 제어와 관련해서 AWS에서 제공하는 기능
(1) Reserved Concurrency - Max Limit 제한
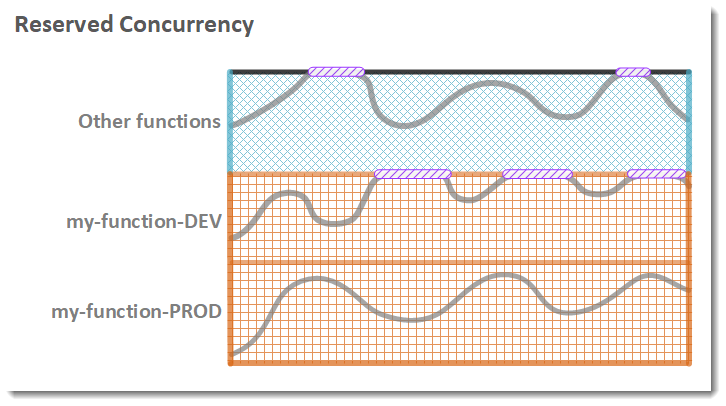
: 계정의 사용 가능한 concurrency(디폴트 1000개) 중 일부를 함수에 예약한다. 이렇게 하면, 함수가 너무 많은 동시성을 사용하지 못하도록 제한(특정 람다 함수에 대해 concurrency limit을 조절)할 수 있다.
해당 설정은 무료이다.
(2) Provisioned Concurrency - 미리 준비해둘 Min Limit 지정
: Cold Start를 줄이기 위한 방안으로 사용된다. 지정한 concurrency 개수만큼 미리 실행환경(컨테이너)을 준비시켜둔다. 즉, 외부에서 요청을 보내지 않아도, 개발자가 concurrency로 지정한 개수만큼의 실행환경(컨테이너)을 미리 세팅해두고, init 코드 역시 돌려둔다. 따라서 concurrency 개수만큼의 동시 요청이 있을 경우에는 cold start없이 바로 람다 함수 코드(이벤트 핸들러)를 실행시킬 수 있다.
또한, 해당 설정을 사용할 경우, 람다는 application auto scaling과 통합하여 사용률을 바탕으로 provisioned concurrency에 대한 자동 크기 조정 역시 지원할 수 있다.
다만, provisioned concurrency 설정은 유료이다.
Scenario
실무에서 람다를 사용하면서 발생 가능한 케이스들을 가정하고, 각 경우에 어떻게 대응하면 좋을지에 대해 간단히 정리한다.
Case1.
Lambda에서 Reserved Concurrency를 30개로 설정하여 동시 요청 수를 최대 30개만 받도록 제한된 경우, 30개 이상의 동시 요청이 들어오면 Lambda는 이를 어떻게 처리하는가?
1. 대기 지연 - Throttle
Lambda에서는 기본적으로 내부 대기열(큐)이 존재하기 때문에, 만약 허용되는 동시 요청 수(30개) 이상의 요청이 들어오는 경우, 각 요청들을 큐에 쌓아둔다. 이 때 큐에 쌓인 요청들은 Lambda가 해당 요청을 처리할 수 있을 때까지 대기한 후 하나씩 처리하게 되고, 이 과정에서 약간의 지연이 발생할 수 있다.
⇒ 이 대기 시간은 개발자가 설정 가능, 최대 5분까지 지연시킬 수 있음
2. 429 Error 반환
Reserved Concurrency에 설정한 값(여기에서는 30)보다 많은 동시 요청이 들어오는 경우, Lambda는 과부화가 걸려 429 (Too Many Request) 에러를 반환하게 되고, 동시성 한도 초과를 알린다.
예를 들어, 만약 요청이 람다의 대기열에서 대기 가능하도록 지연시간을 5분으로 걸어두었는데, 요청의 실제 대기 시간이 설정했던 지연시간(5분)을 넘어간 경우, 해당 요청은 처리되지 못하고 429 에러가 반환된다.
즉, Lambda는 더이상 사용할 수 있는 실행환경이 부족할 때 자동으로 요청을 대기(throttle) 시키지만, 동시성 제한을 크게 초과하거나 대기 시간이 너무 긴 경우 429 에러가 발생하게 된다.
⇒ 이를 방지하려면 동시성 제한(reserved concurrency)을 늘리거나, 요청 재시도를 구현하는 방식으로 대응해야한다.
Case2.
Lambda를 API Gateway와 함께 API 서버로 활용하는 경우, Case1과 같은 상황이 발생하면 Lambda는 이를 어떻게 처리되는가?
Lambda의 동시성 처리 로직과 별개로, API Gateway는 29초라는 timeout 제한이 있다.
따라서 Lambda가 최대 5분간 지연 가능함과 별개로, API Gateway 단에서는 요청에 대한 응답이 29초 내로 이루어지지 않으면 클라이언트와의 연결을 끊어버리면서 504 Gateway Timeout 에러를 반환한다. 즉, API Gateway와 함께 사용하는 경우에는 지연 없이 무조건 29초 안에 응답이 처리되어야 한다.
이를 해결하는데 여러가지 방법이 있을 수 있으나, 여기서는 크게 2가지 경우로 처리하는 방식을 설명한다.
(1) API Gateway와 Lambda간의 연결을 비동기로 처리
API Gateway에서는 비동기 호출을 설정할 수가 있는데, 이 때 API Gateway는 다음과 같이 동작하게 된다.
-
클라이언트로부터 요청이 들어오면, API Gateway는 람다로 해당 요청을 토스하고, 클라이언트에게 즉시 202(Accepted - 요청이 받아들여졌고, 지금 처리중이야) 상태코드를 반환함.
-
Lambda에서는 요청을 처리…
⇒ 다만 여기서 발생할 수 있는 문제는, 클라이언트 측에서는 요청이 제대로 처리되었는지를 알 수 없다는 것임. Lambda가 요청을 성공했는지, 실행하다가 오류가 나서 죽었는지 알 수 없음. 따라서 클라이언트가 요청 결과 상태를 알아야 하는 경우, 클라이언트에게 상태를 알려줄 수 있는 별도의 메커니즘을 설계해야함.
⇒ 또한, 만약 Lambda로 요청이 왔는데 이미 Lambda가 동시성 최대치까지 다 끌어다 쓰고 있어서 더이상 인스턴스를 띄울 수 없는 경우... 해당 요청은 대기열에서 대기하게 될텐데, 이 때 해당 요청의 대기 시간이 5분을 넘어가게 되면 그 요청은 실행도 못해보고 그냥 실패하는게 됨. 근데 클라이언트에서는 이 사실을 알기 어려움. 마찬가지로, 서버 단에서 푸시 메시지를 보낸다던가 클라이언트에서 계속 상태를 폴링한다거나..(그치만 비효율적일듯)
(2) 별도의 SQS를 두고, Lambda에서 처리해야하는 요청들을 SQS에 쌓아두었다가 처리하는 방식의 설계
하지만 이 방법은 GET과 같이 클라이언트에 응답을 반환해주어야하는 경우에 대해서는 대응이 불가능하고, POST와 같이 일방적으로 처리하면 되는 구조에서나 사용 가능한 방법이다. (어차피 SQS로 요청을 보내고 나면 Lambda에서 언제 처리될지도 모르고, API Gateway는 무조건 29초 넘어가는 순간 연결 끊고 504를 뱉을테니까)
GET 응답이 필요한 경우에 대해서는 다른 방식을 사용해야한다. API Gateway와 Lambda 간의 연결을 비동기로 처리하거나, 캐시를 사용하여 응답 속도를 빠르게 하는 방식으로. (어차피 도메인 사용을 위해 Route53-CloudFront를 사용하고 있다면, CloudFront에서 캐시 설정을 해서 이를 적극 활용하는 것도 방법임)
References
