아키텍처를 구축하는 동안 PM이 지식 기반으로 쓰일 문서를 만들어 주었다.
해당 문서는 78장의 타로 카드들의 의미와 해석 방법을 담고 있다.
이 문서를 Bedrock Agent에 연결하여 지식기반으로 사용하고자 한다.
Step 1) 문서 정제하기
해당 문서의 경우 웹 스크래핑 과정에서 띄어쓰기가 잘못 들어가거나 불필요한 정보가 들어간 경우가 많았다. 물론 임베딩 벡터의 특성상 글의 구조보다는 의미 구분이 더 중요하다고는 하지만, 가독성이 지나치게 떨어지면 잘못된 임베딩이 이루어질 수 있다. 또 불필요한 정보는 결국 벡터 저장소를 낭비하는 셈이므로 해당 문서를 정제할 필요가 있었다.
인코딩 문제 해결
CP949로 인코딩된 원본 문서가 정상적으로 열리지 않는 문제가 있어, 파일을 확인한 후 문제가 되는 특수기호들을 처리하였다.
참고로 txt파일을 읽어올 때 errors="backslashreplace" 옵션을 활성화하면 읽어올 수 없는 기호들을 유니코드 이스케이프 형식으로 읽어오기 때문에 어떤 문자가 문제가 되는지 파악하기가 쉽다.
with open('card_meanings_v3.txt', 'r', encoding='cp949', errors="backslashreplace") as f:
content = f.read()
content = content.replace('\\x80', ' ').replace('쪾', ' ')
with open('card_meanings_v4.txt', 'w', encoding='cp949') as f:
f.write(content)문서 정제
인코딩 문제를 해결한 문서를 다듬어야 한다. 통일되지 않은 단락 구분이나 내용 구성을 통일하고 카드 이름을 통일하는 것과 같은 것들 말이다.
수동으로 다듬는 방법도 있고, 한국어 맞춤법 처리 패키지를 사용하는 방법도 있지만 본인의 경우 챗봇의 힘을 빌렸다. anthropic API를 통해 문서를 정제하는 과정을 거쳤다.
Anthropic API
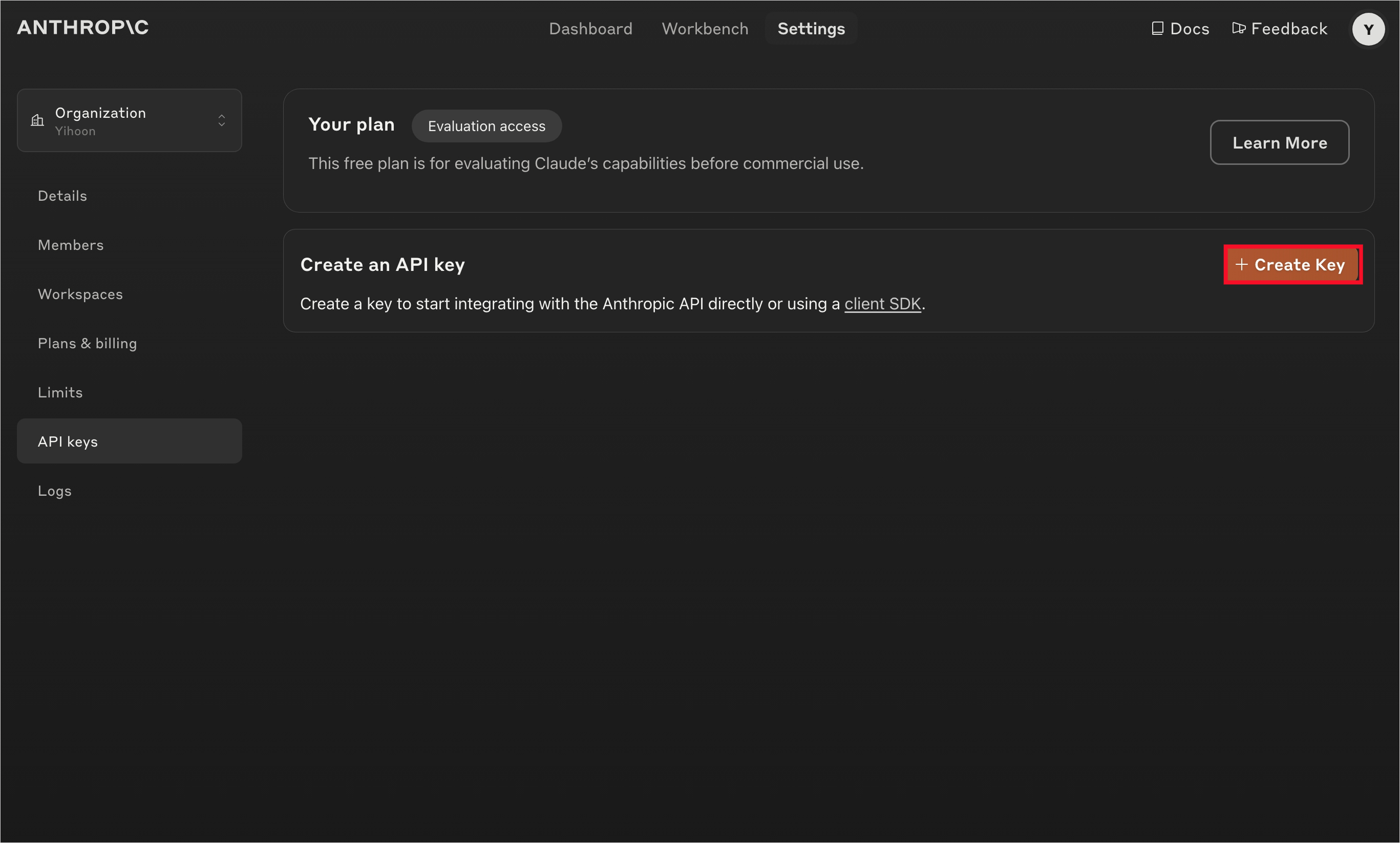
먼저 anthropic console에서 API 키를 발급받는다.
회원가입 시 자신의 회사명과 그 외 정보를 입력한다.
이어서 API 키를 발급한다. 이 키를 분실하면 다시 발급받아야 하므로 잘 보관해 두자.
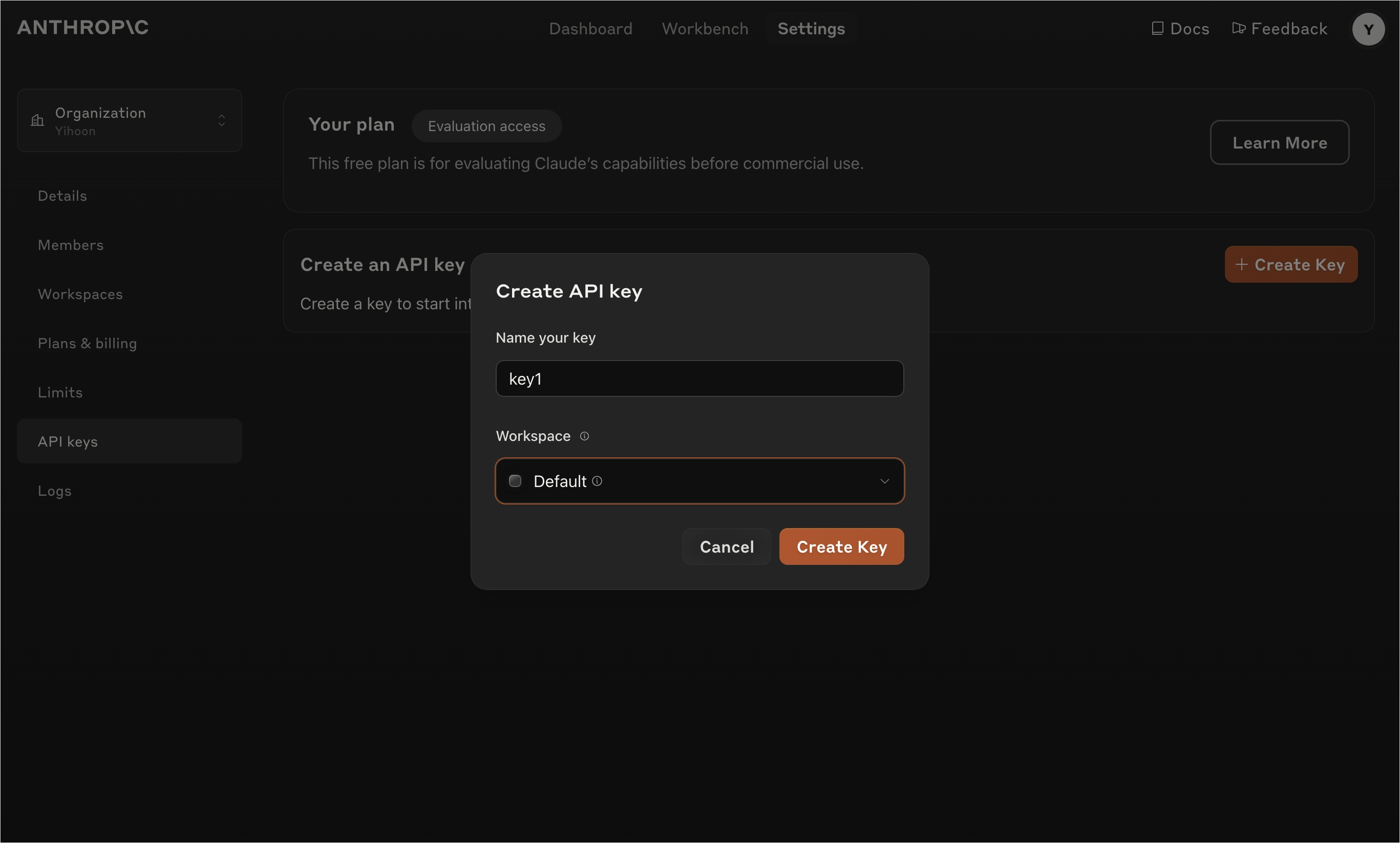
참고로 24년 9월 기준 할당된 사용량은 다음과 같다.
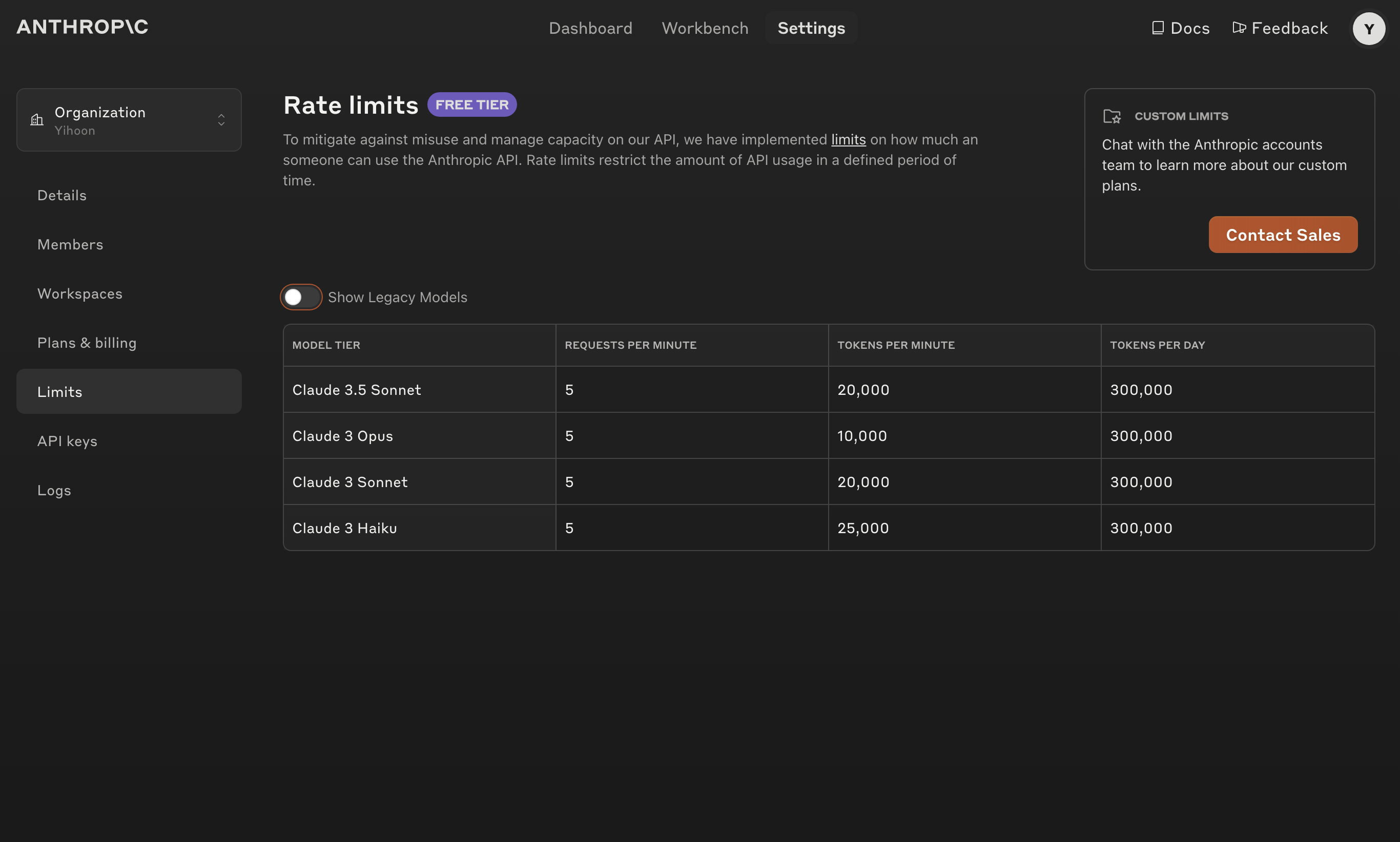
이 키를 그대로 사용할 수 있는 건 아니고, 사용량 결제가 필요하다.
Plans&billing의 Add Funds에서 사용량을 선불로 결제할 수 있다. Pay as you go 체계는 따로 세일즈에 컨택이 필요한 듯하다.
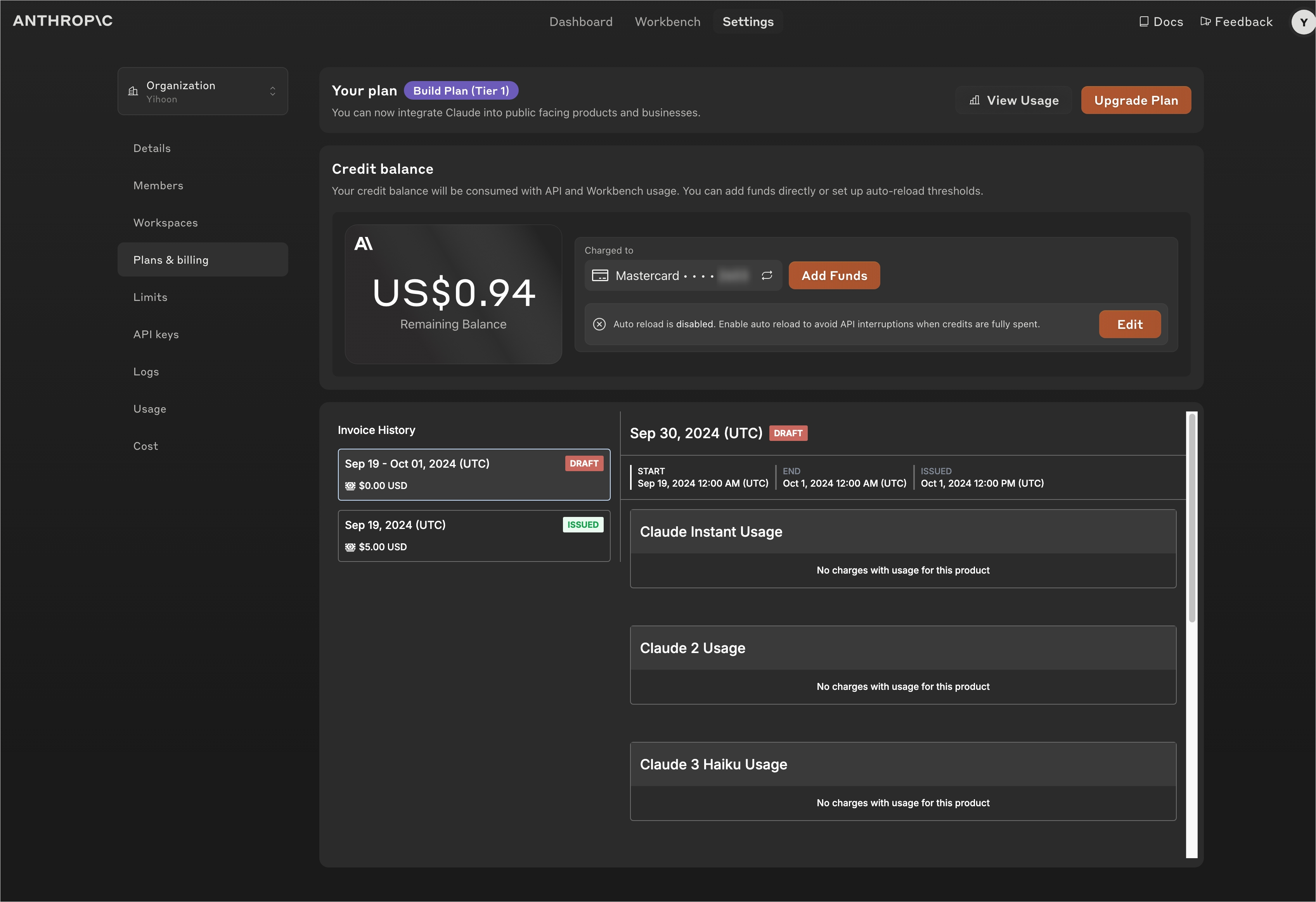
참고로 나의 경우 Claue 3.5 Sonnet으로 78번의 정제 작업을 수행하는 데 약 3달러가 사용되었다.
이제 Python 코드로 API를 호출하여 문서를 정제하자.
Text_processing.py
먼저 API 키를 포함한 Anthropic Client 개체를 정의한다.
import os
import re
import anthropic
import time
apikey="MYAPIKEYMYAPIKEY"
client=anthropic.Anthropic(api_key=apikey)이어서 파일을 읽어온다.
def read_text_file(file_path)
with open(file_path, 'r', encoding='cp949') as file:
return file.read()이어서 텍스트를 청크로 나누는 작업을 수행한다. 한꺼번에 모든 문서를 처리할 수는 없기 때문에 이를 한 문단 단위로 나누었다.
def split_text(text, max_tokens=4000):
paragraphs = re.split(r'\n{2,}', text)
chunks = []
current_chunk = ""
for paragraph in paragraphs:
if len(current_chunk) + len(paragraph) <= max_tokens:
current_chunk += paragraph + "\n\n"
else:
if current_chunk:
chunks.append(current_chunk.strip())
current_chunk = paragraph + "\n\n"
if current_chunk:
chunks.append(current_chunk.strip())
return chunks청크로 나누어진 문서를 정제한다.
def process_chunk(chunk):
response=client.messages.create(
model="claude-3-5-sonnet-20240620",
max_tokens=4000,
messages=[
{"role": "user", "content": f"이 문서는 타로 카드의 의미와 해석을 포함하고 있어. (중간 생략) 답변에 다른 불필요한 멘트를 달지 말아 줘. {chunk}"}
]
)
return response.content[0].text끝으로 main 함수를 정의한다. 이때 12초간 API 호출을 정지하는 이유는 분당 최대 호출 횟수인 5회를 넘지 않도록 하기 위함이다.
def main(input_file):
text=read_text_file(input_file)
chunks=split_text(text)[:-1]
processed_chunks=[]
for i, chunk in enumerate(chunks):
print(f"{i+1}/{len(chunks)}")
processed_chunks.append(process_chunk(chunk))
print('12초간 호출 정지...')
time.sleep(12)
final_text="\n\n".join(processed_chunks)
output_file=os.path.splitext(input_file)[0]+"_processed.txt"
with open(output_file, 'w', encoding='utf-8') as f:
f.write(final_text)
if __name__=="__main__":
input_file="./card_meanings_v4.txt"
main(input_file)Step 2) 벡터 저장소 준비하기
지식 기반으로 쓰일 벡터 저장소를 구축하는 가장 쉬운 방법은 OpenSearch Serverless를 사용하는 방법이다. 실제로 전편에서 이를 이용해 지식 기반을 구축한 과정을 소개했었다.
하지만 해당 서비스를 지속적으로 사용하에는 비용이 다소 부담스러웠고, 그 대안으로 Aurora Serverless를 사용하였다. 여기서의 설명을 참고하였음을 밝힌다.
RDS
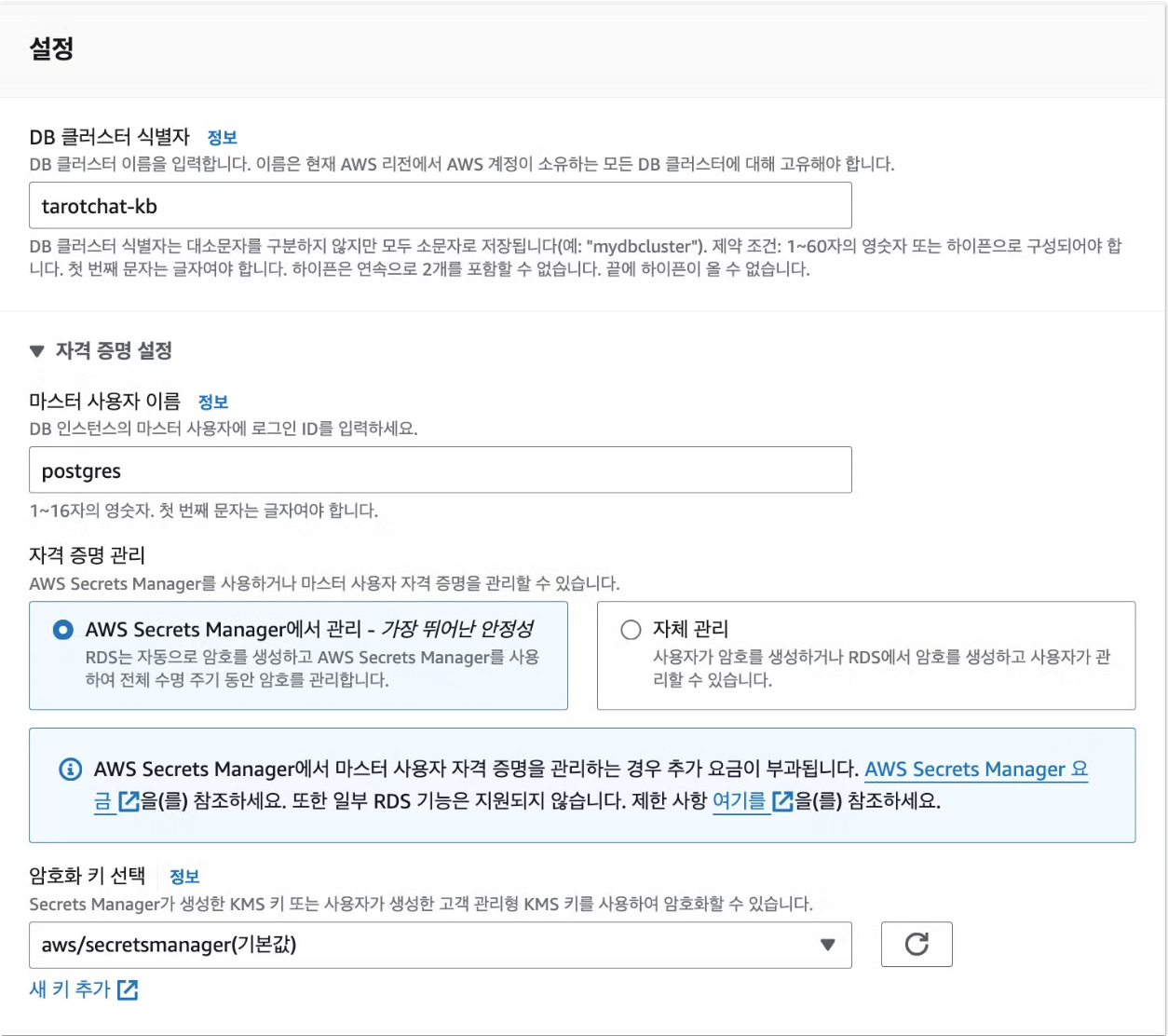
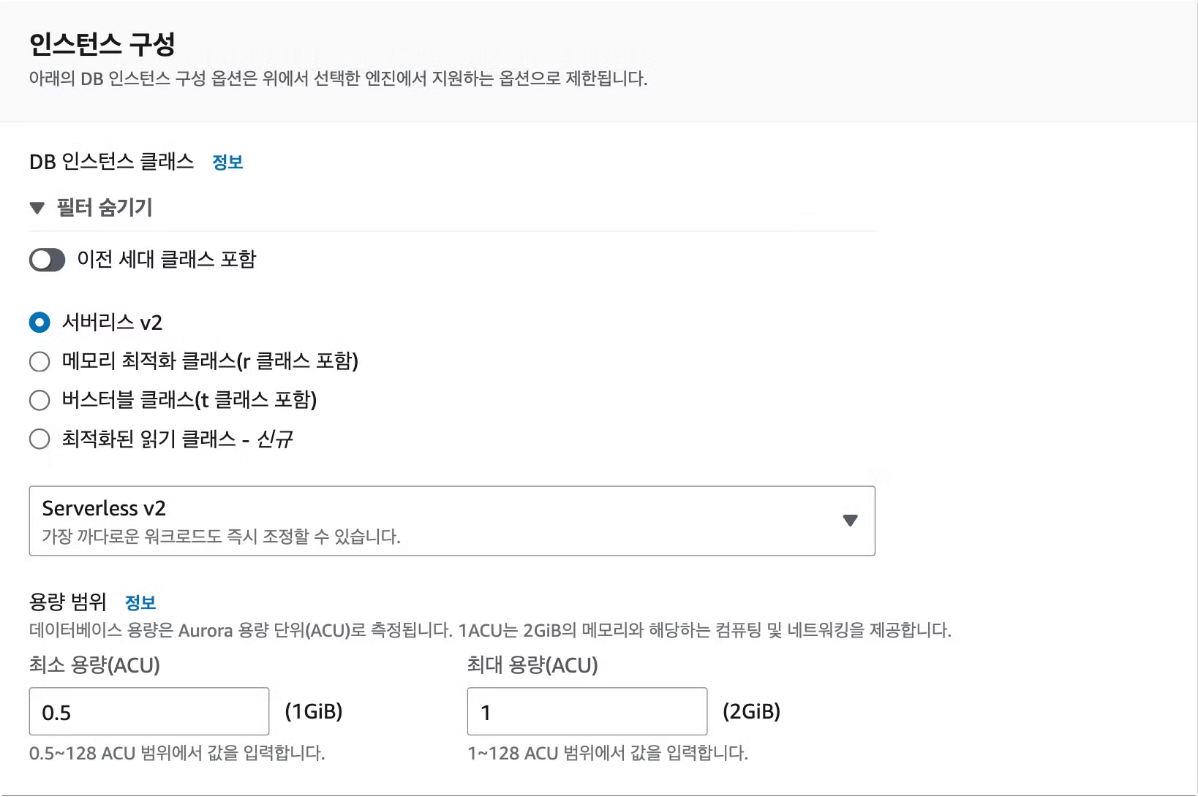
먼저 PostgreSQL 인스턴스를 만든다. 이때 반드시 준수해야 하는 옵션은 다음과 같다:
- 자격 증명 관리: Secrets Manager 사용
- 인스턴스 클래스: Serverless
- 퍼블릭 액세스 허용
- RDS 데이터 API 활성화
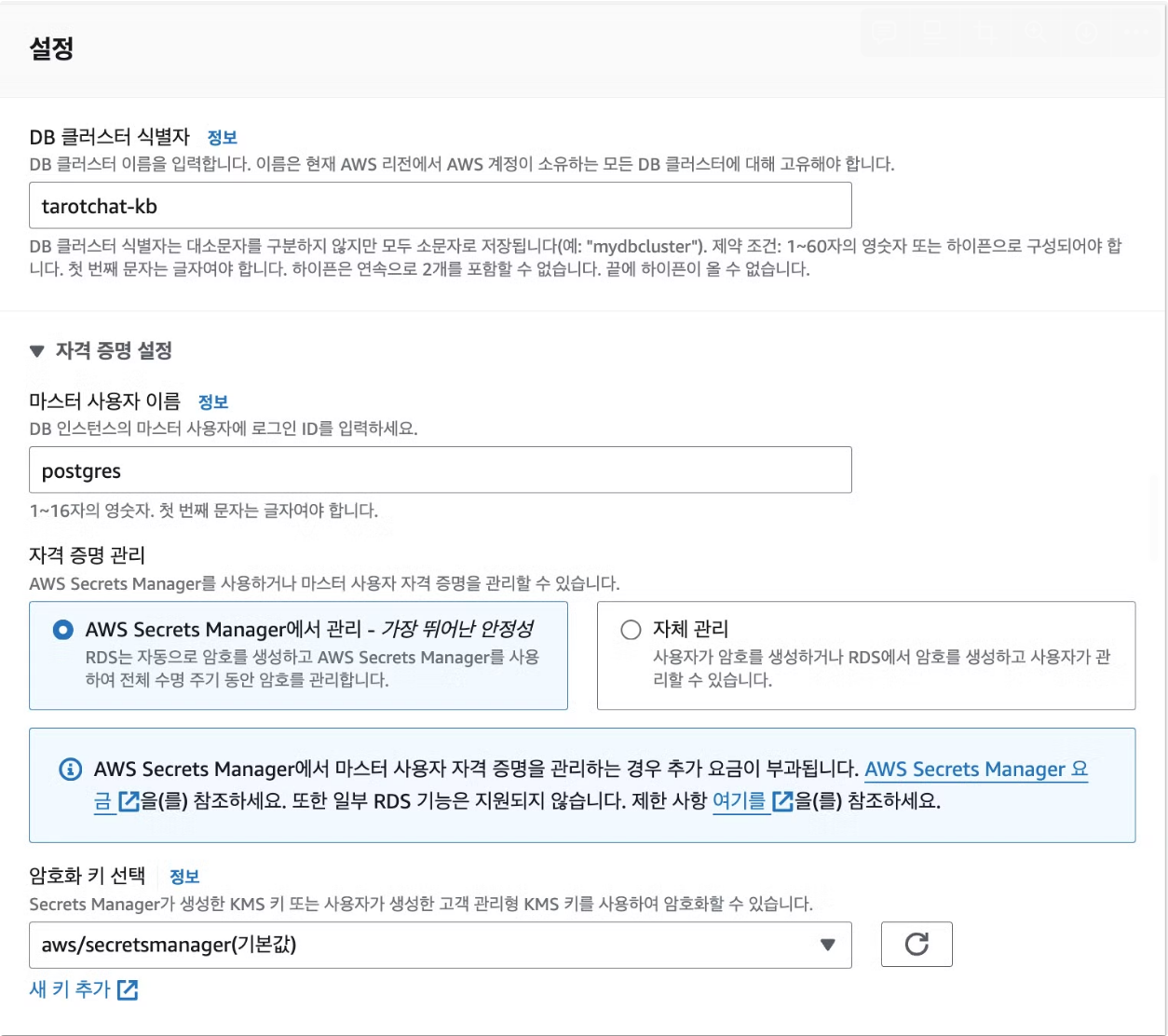
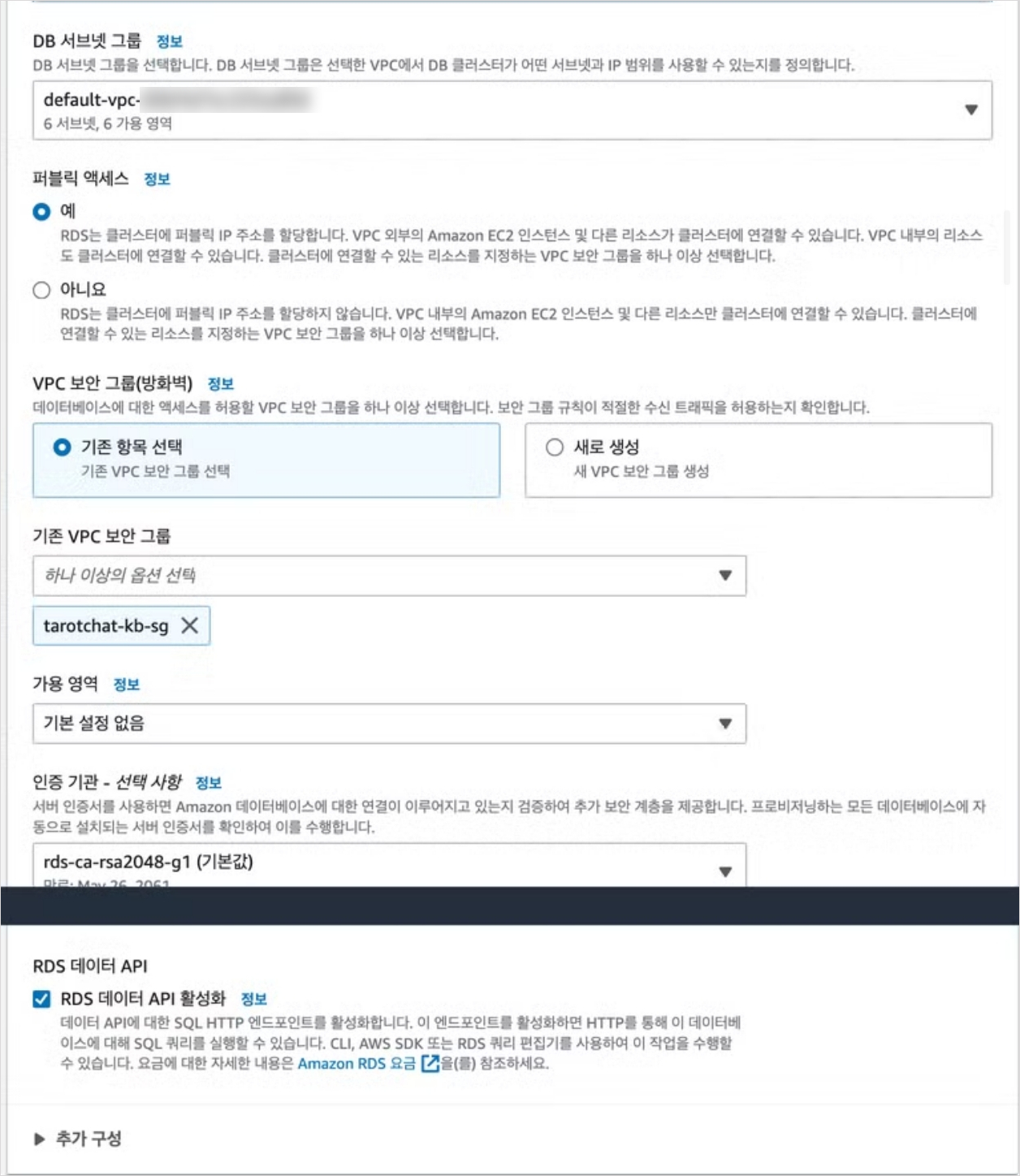
이렇게 인스턴스를 생성했다면 DB를 기본 세팅하는 작업이 필요하다.
일단 해당 인스턴스와 연결된 Secrets Manager ARN을 복사한다.
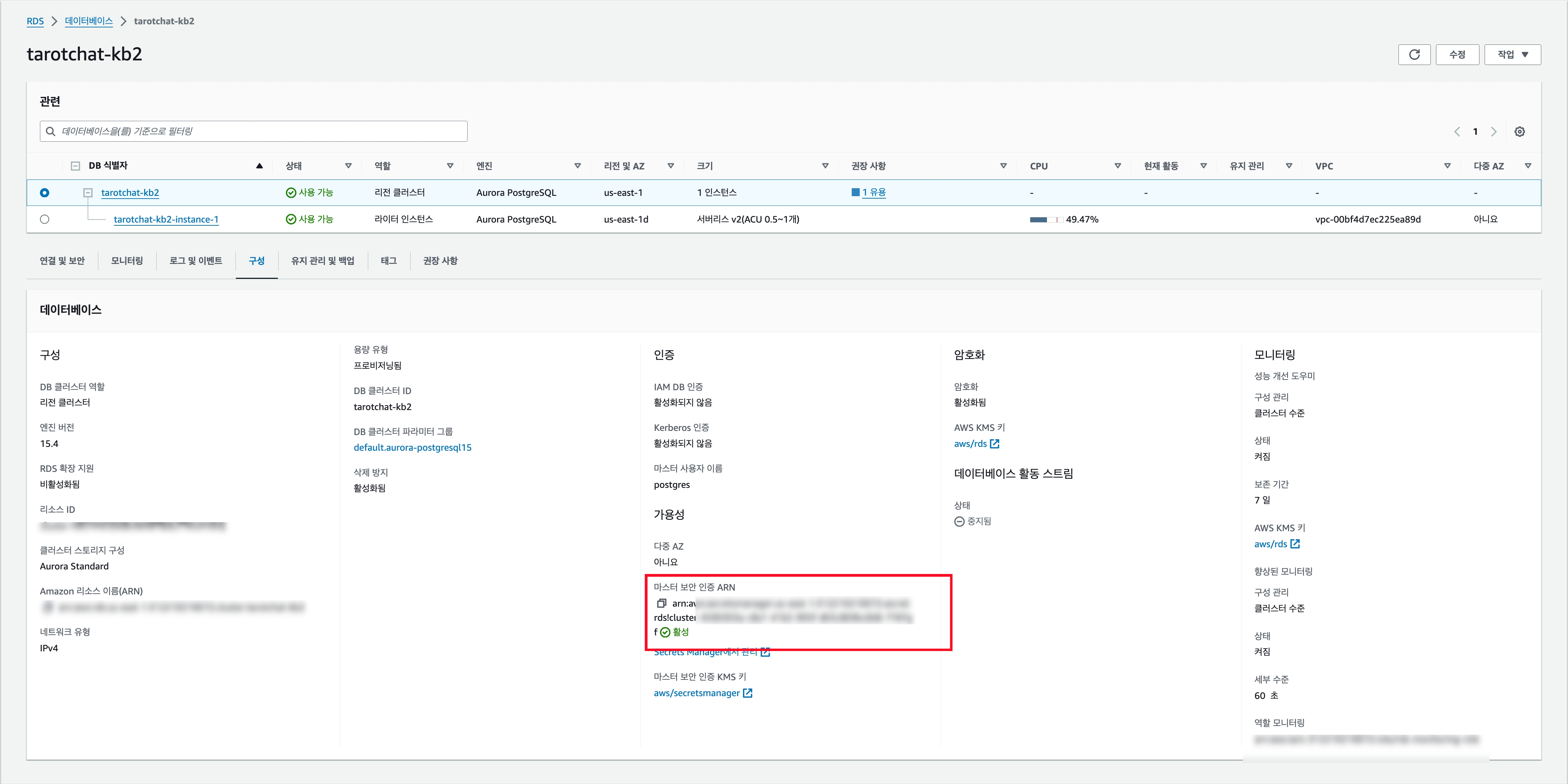
그리고 쿼리 편집기로 이동해서 해당 인스턴스에 접속한다. 물론 pgAdmin과 같은 별도 에디터를 사용해도 무방하다. 접속한 후 아래의 쿼리들을 날리자.
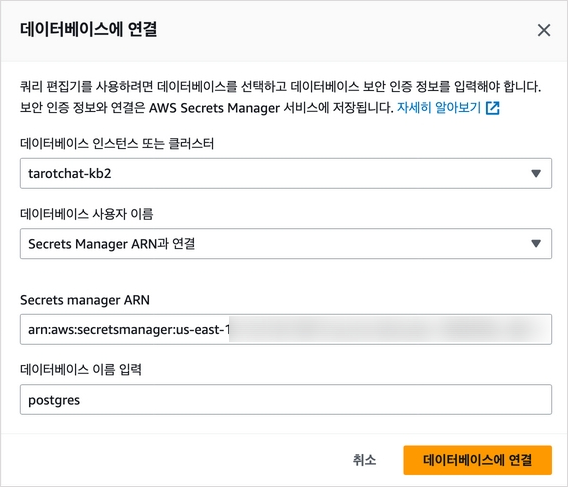
PostgreSQL
우선 pgvector 설치가 필요하다.
CREATE EXTENSION IF NOT EXISTS vector;이어서 pgvector 버전을 확인해야 한다. 버전이 0.5.0 이상인지 확인하자.
SELECT extversion FROM pg_extension WHERE extname='vector';지식 기반으로 사용될 스키마를 생성한다.
CREATE SCHEMA bedrock_knowledgebase;다음으로 Role을 생성하고 여기에 해당 스키마에 대한 모든 권한을 부여한다.
이때 username과 password는 Secrets Manager의 것을 사용한다.
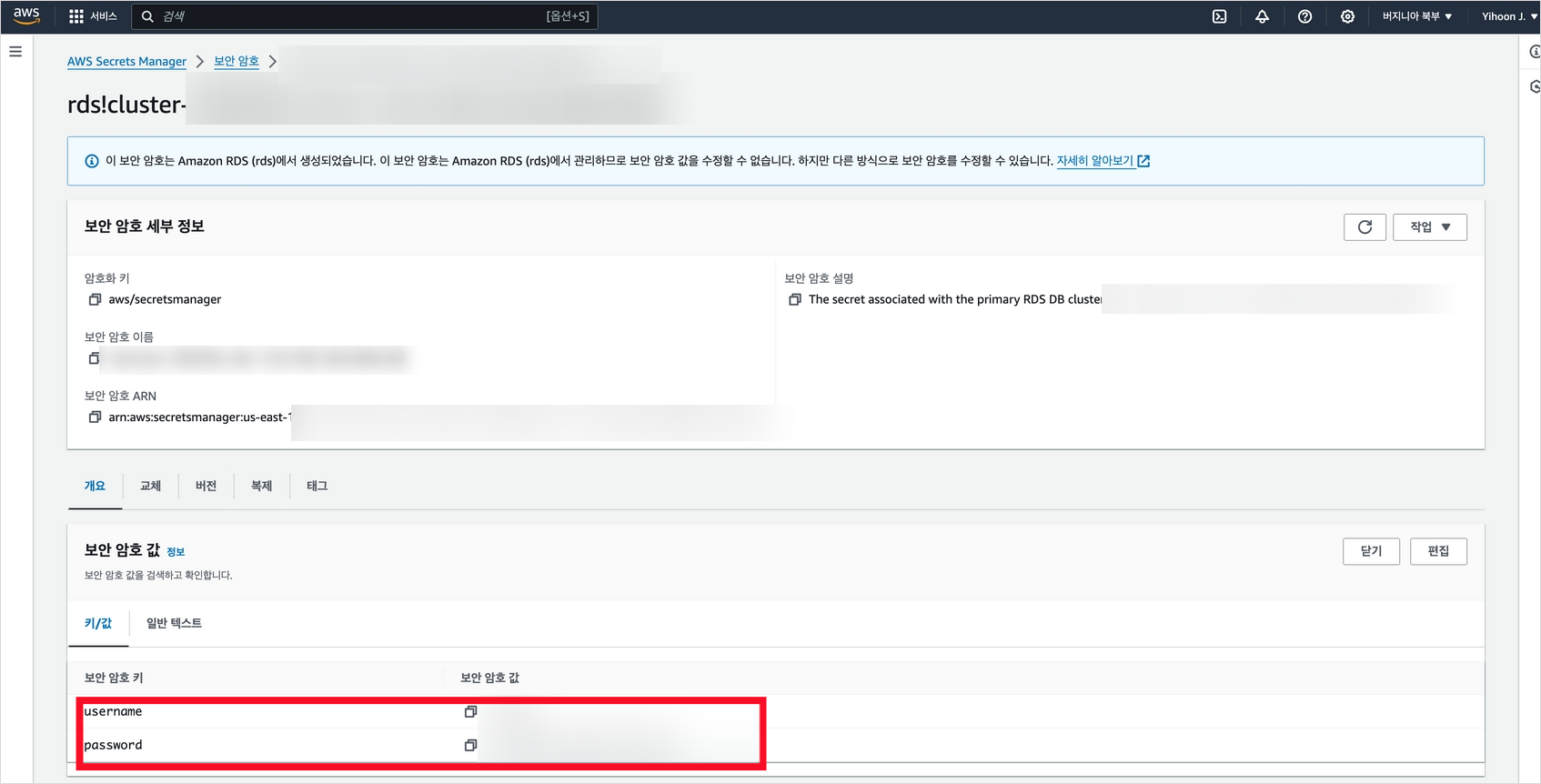
CREATE ROLE username WITH PASSWORD 'password' LOGIN;
GRANT ALL ON SCHEMA bedrock_knowledgebase to yihoon;이제 bedrock 연동을 위한 테이블과 인덱스를 생성한다. embedding의 경우 자신이 벡터 임베딩 시 사용할 임베딩 벡터 차수에 맞도록 벡터 차수를 지정해야 한다.
나의 경우 Titan Embeddings V2를 활용하였고 이때 기본 벡터 차수는 1024이므로 차수 또한 1024로 설정하였다.
CREATE TABLE bedrock_knowledgebase.bedrock_kb (
id uuid PRIMARY KEY,
embedding vector(1024),
chunks text,
metadata json
);마지막으로 인덱스를 테이블에 생성한다.
CREATE INDEX on bedrock_knowledgebase.bedrock_kb
USING hnsw (
embedding vector_cosine_ops
);
DELETE TABLE bedrock_knowledge.bedrock_kb;
TRUNCATE bedrock_knwoledgebae.bedrock_kb;Step 3) Bedrock 지식 기반 생성
테이블 세팅을 마쳤다면 Bedrock 에이전트에 지식 기반을 설정할 차례이다.
Bedrock
에이전트를 만들고 Agent Builder에 진입한다.
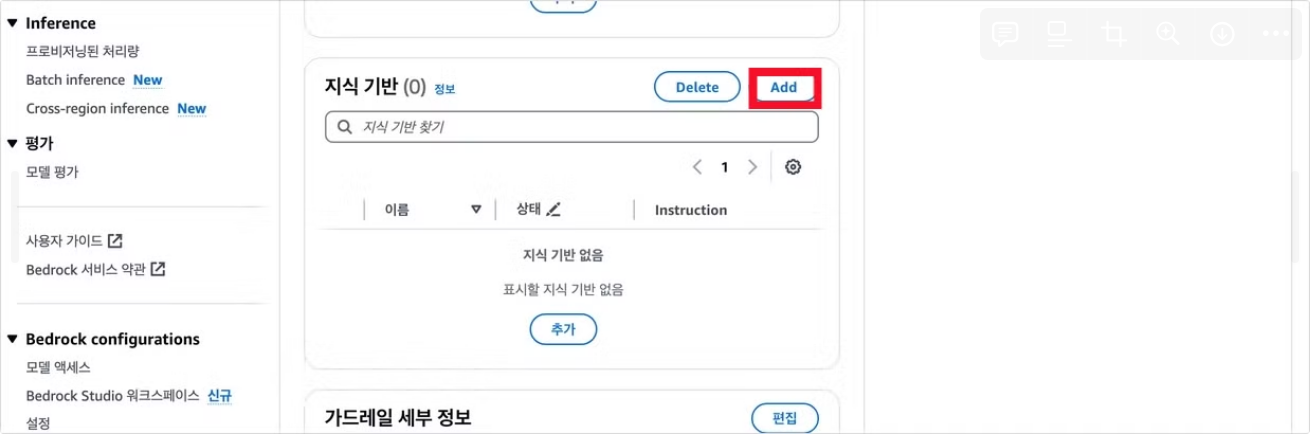
지식 기반 영역에서 Add를 눌러 지식기반 추가 메뉴에 진입할 수 있다. 여기서 만들어 둔 지식 기반을 선택하고 지식 기반 지침을 작성한다.
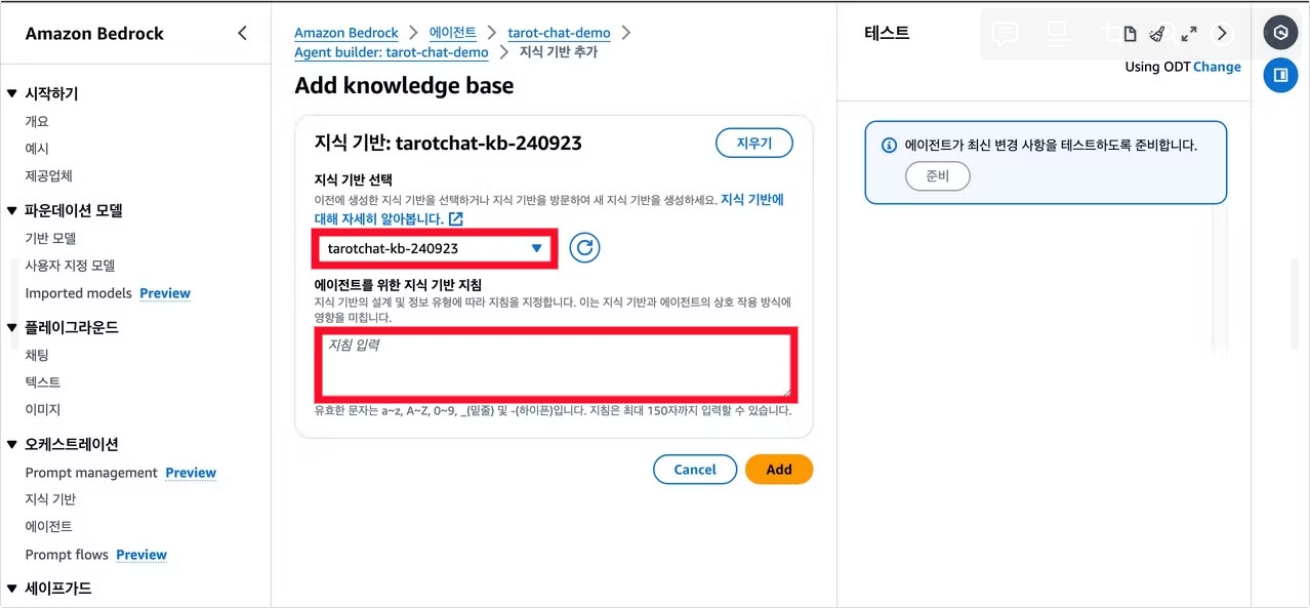
지식기반이 성공적으로 구축되었다면 저장 후 Agent Builder를 종료하고 테스트하면 된다.
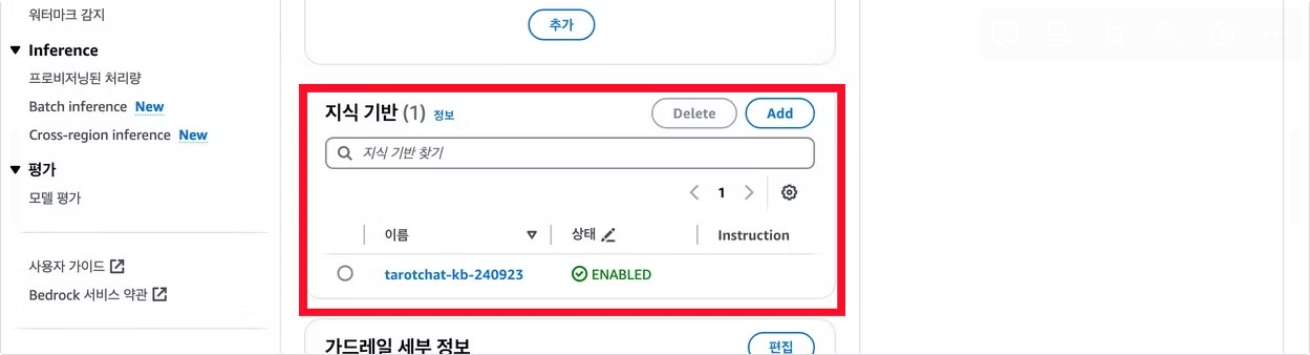
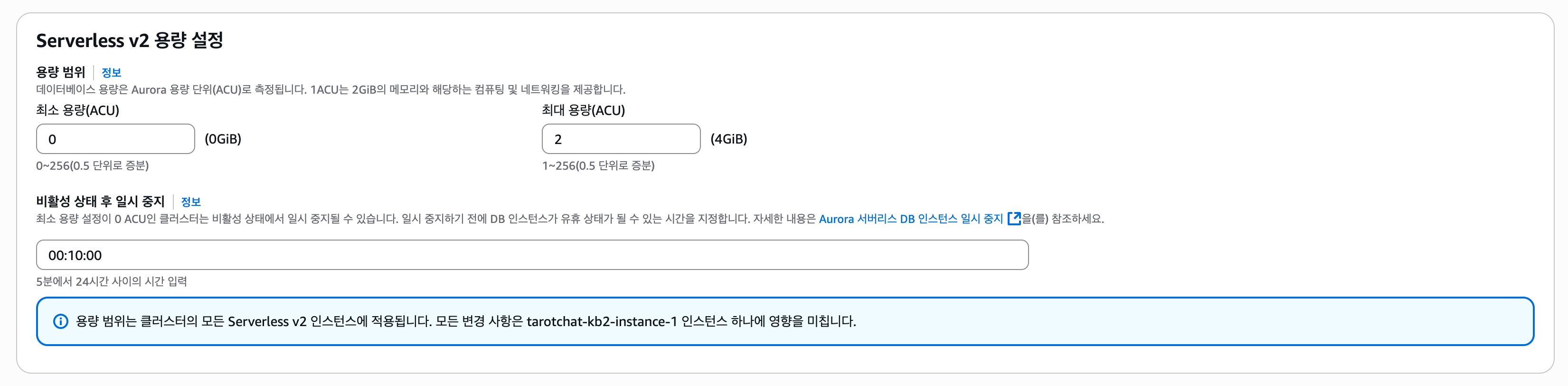
추가: Aurora 일시정지하기
지식 기반 생성 이후 RDS 요금이 다소 부담스러웠다. 작업 당시 사용한 PostgreSQL 15.4 버전은 Serverless V2에서 최소 ACU를 0.5 이하로 설정할 수 없었고, 이 때문인지 항상 CPU 사용량이 상당히 높게 유지되고 있었다
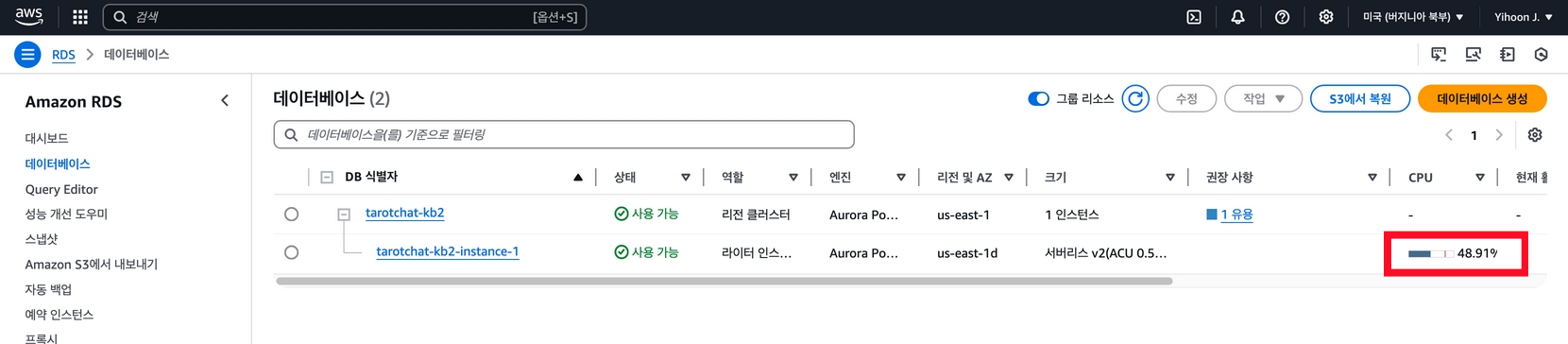
최근 다시 확인해보니 ACU를 0으로 낮추고, 해당 상태가 오래 지속될 경우 자동으로 정지하는 기능이 추가되었다.
먼저 버전을 15.09 이상으로 업데이트하고, 그 후 최소 ACU를 0으로 변경하면 된다.
물론 이 경우 서비스 사용을 위해 Aurora를 재개하는 로직이 필요하지만, 해당 로직이 생기더라도 비용 절감이 더 중요한 입장이기에 해당 방식으로 RAG 데이터베이스를 운용 중에 있다.