네이버 블로그 글을 복사해온 것으로 일부 서식이 맞지 않을 수 있습니다.
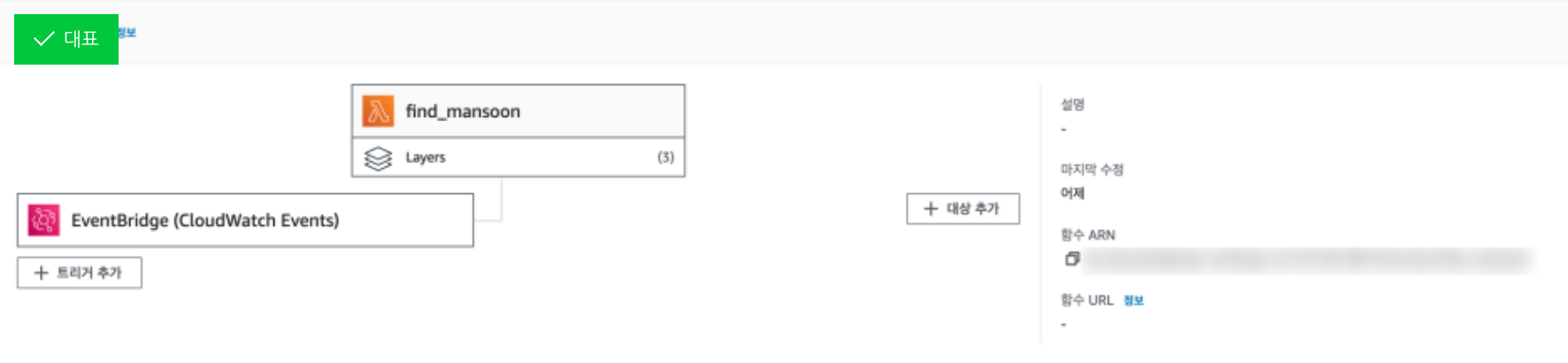
Language: Python
Computing: AWS Lambda
DB: -
CI/CD: -
Scheduling: AWS Eventbridge
Github
https://github.com/Yihoon-J/find_mansoon
AWS Structure
회사 생활 전에는 AWS 개발 업무는 해본 적 없었고,
회사에서 운영한 것들은 어쨋든 완전 단독은 아니니,
사실상 첫 단독 개발 프로젝트(...)였다.
09.11 월
작업 의뢰일
학회 마치고 쉬던 중 과 동기 누나한테서 온 카톡
이런저런 얘기를 하다 작업 의뢰를 받았다.
"매일 보호 중인 동물 목록을 일일이 확인하는 게 너무 힘들어. 이걸 자동화할 수 없을까?"
얼마 전 잃어버렸다는 반려견을 며칠째 찾고 있다는 안타까운 소식을 알고 있었다.
뭐라 위로해야 할 지도 모르겠고, 도와줄 수 있는 것도 생각나지 않아 고민하던 차에 먼저 도움을 청해준 게 무척 고마웠다.
마침 잠시 일을 쉬는 동안 프로젝트 한두 개를 해야겠다는 생각을 하고 있던 차였기도 하고, 더군다나
- 포트폴리오 상에는 OOP로 구현된 코드가 없다는 점,
- AWS를 회사 업무 외에는 써본 경험이 없다는 점
때문에 고민이 많던 찰나에 이 두 가지를 동시에 경험할 수 있는 기회라는 점도 흔쾌히 개발에 착수하기로 한 이유가 되었다.
금방 할 것 같은데? 라는 생각과 함께
"내일 바로 만들어 줄게!"라는 또 한번의 실언을 해 버리고 말았다.
09.12 화
기본 구조 개발
오전에 AWS CLF 시험 끝나고 바로 개발 착수.
생각한 흐름은 다음과 같다.
1. 스케줄러를 구축하여 트리거를 설정한다
2. 트리거 발생 시 국가동물정보시스템에서 원하는 조건의 동물 정보를 긁어 온다.
3. 동물 정보를 텔레그램으로 보내 준다.
모든 과정은 AWS위에서 서버리스로 구축한다. (이 정도면 프리티어 범위 안이거나 요금 나와봤자 얼마 안 된다.)
일단 최소 minimum working solution을 만들고 개선해가는 게 좋다고 회사에서 배웠기 때문에, 그에 해당하는 2번을 먼저 만들었다.
당연히 객체지향으로 접근했고, 클래스 구조는 크게
- 텔레그램 메시지 전송
- 전체 조회 건수 탐색
- 각 건에 대한 상세정보 수집
- 수집된 정보를 바탕으로 최종 메시지 전송
정도의 하위 모듈로 구성하였다.
여기서 두 번째 모듈(조회 건수 탐색)의 역할이 매우 단순하지만 꼭 분리해야만 할 이유가 있는데, 여기서 반환되는 조회 건수가 여러 번 반복되어서 쓰이기 때문이었다.
우선 조회 건수가 0이면 아예 이벤트를 실행하지 않으며, 아닌 경우에도 여기서 반환된 조회 건수에 따라서 페이지 개수와 페이지 내 조회 건수가 달라지며, 마지막으로 메시지를 보내기 전에도 정상적으로 모든 정보를 수집하였는지 한 번더 체크하는 과정에서 조회 건수를 확인한다.
이러한 구조 하에서 웹 크롤링은 bs4를 사용하였다. 어떻게든 lambda의 실행 시간을 줄여야 한다는 것이 주된 목적이었고, 단순히 정보를 긁어 오는 것이므로 정적 크롤링만으로 충분히 가능할 거라고 생각했다.
하루종일 기본 크롤러를 다 짜고 나서 보니 뭔가 잘못됨을 발견하였다.
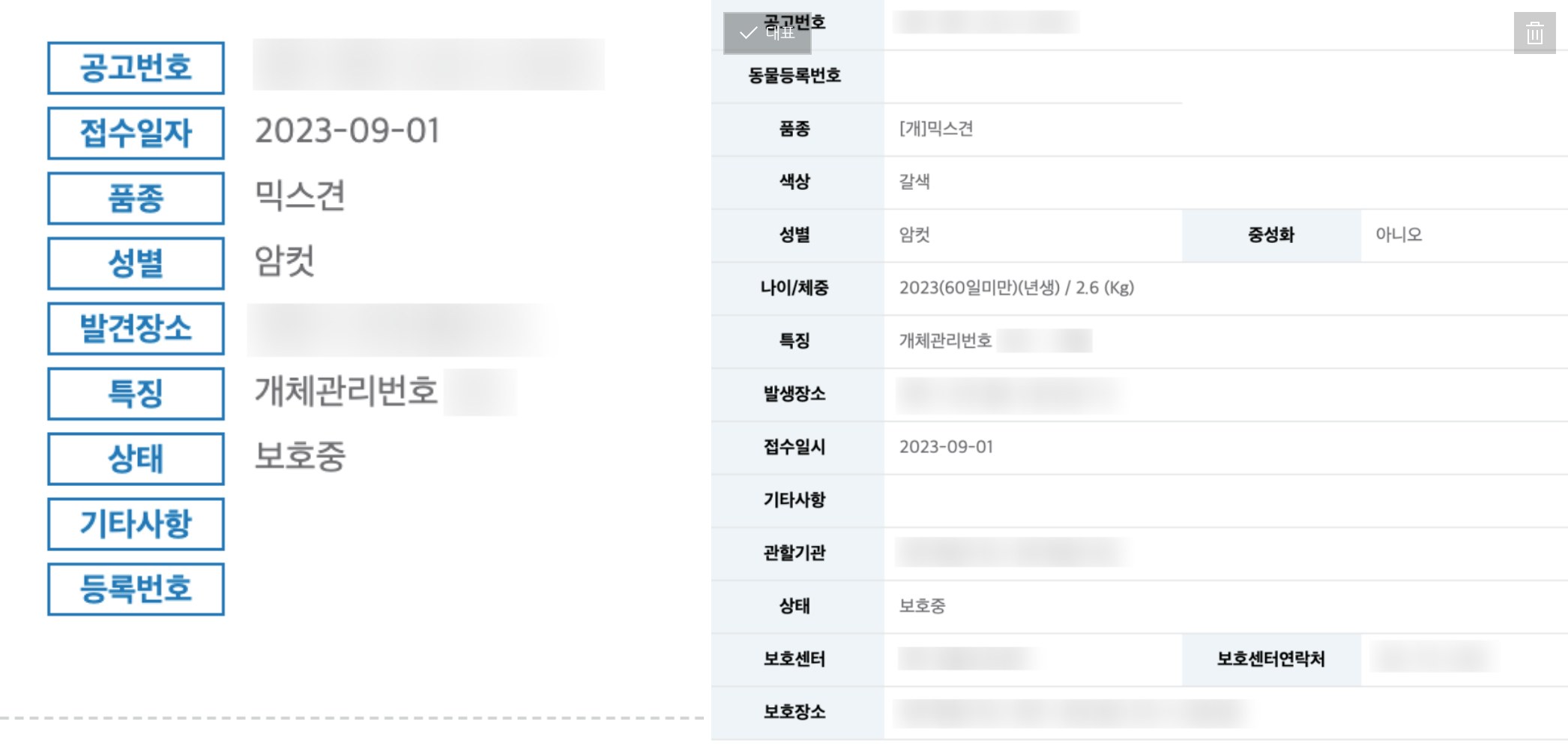
목록 페이지에서 보이는 정보(좌)와, 상세정보 url을 타고 들어가서 보는 정보(우)는 그 양에 있어 완전 다르다는 것...
특히 지인 반려견의 경우 색상 정보가 매우 중요하기 때문에 꼭 상세 정보를 가져와야만 했다.
기존에 목록 페이지에서 정보를 가져오는 대신 목록 페이지에 있는 '상세보기'url을 가져오고, 추가적으로 그 url에 들어가서 상세 정보를 긁어오는 모듈을 구현하는 쪽으로 설계를 조금 바꾸었다.
이걸 하루가 다 가고 나서야 발견하는 바람에, 자신만만하던 내 데드라인은 이번에도 지키지 못하게 되었다.
09.13 수
기본 코드 구현 완료
며칠 더 시간이 걸린다고 뒤늦게 양해를 구하고,
어제 수정하기로 한 구조를 손대기 시작했다.
그런데 상세 url이 정적 링크가 아닌 js 개체로 되어 있다...

js는 아예 모르기도 하지만, 딱 봐도 얘는 bs4로 해결 가능한 문제가 아니었다.
아무리 고민해봐도 방법은 셀레늄 뿐.
여기서 "Lambda에서 셀레늄 실행이 가능한가?"에 대해서 열심히 찾아보았는데, 일단은 가능하다고 한다.
어차피 다른 방법이 없으니, 아직 lambda를 뜯어보지도 않았지만 열심히 셀레늄으로 코드를 구현해 본다.
단순 반복문이 많이 들어가다 보니 셀레늄을 무한정 사용하면 실행 시간이 너무 길어지고, 상세 페이지 URL을 따오는 최소한의 부분만 셀레늄으로 구현하였다.
즉 상세 페이지 URL접근을 위한 기본적인 파싱이나 상세 페이지 내 정보 파싱은 모두 bs4로 수행하였다.
이렇게 크롤러를 먼저 완성한 후 텔레그램 봇을 만들어 결과 출력을 구현하였다.
텔레그램 작업은 여기 소개된 내용들을 참고하였다.
특히 비동기 세팅이 익숙지 않다 보니 몇 번 헤매다가, 결국 클래스 안에 녹여내는 데까지 성공했다.
비동기 세팅: 정해진 실행 순서를 기다리는 것이 아니라 여러 코드를 동시에 실행할 수 있도록 하는 것
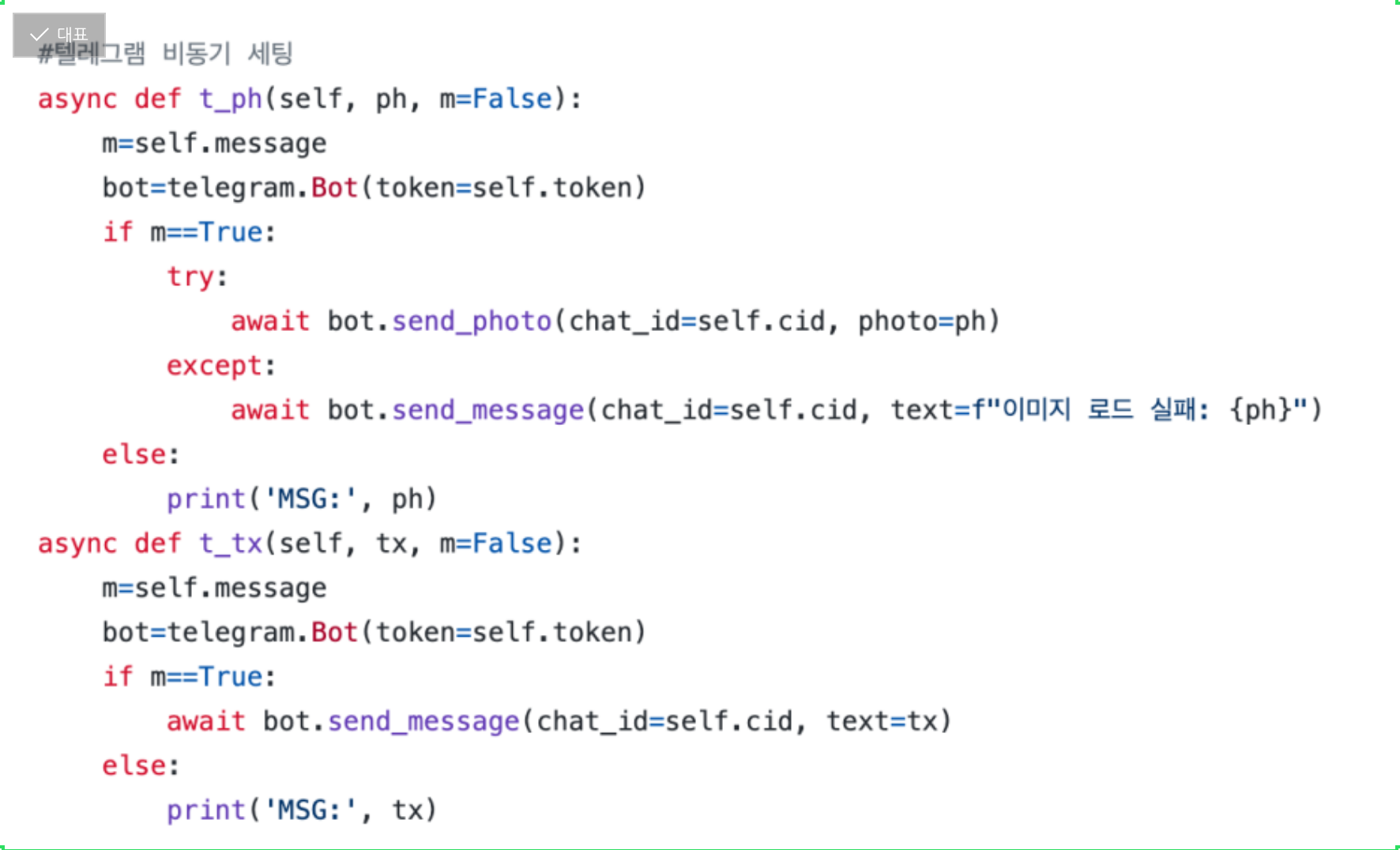
중간중간 테스팅을 위해서 m인자를 True로 지정 시 슬랙을 보내고, False로 지정 시 터미널에서 출력되는 구조를 취했다.
그리고 개 사진을 확인해야 하기 때문에, 사진을 보낼 수 있는 함수를 따로 정의하였다. try-except 문으로 사진 전송에 성공하면 사진을 보내고, 실패하면 사진 url이라도 보내는 코드.
그렇게 구현한 결과물은
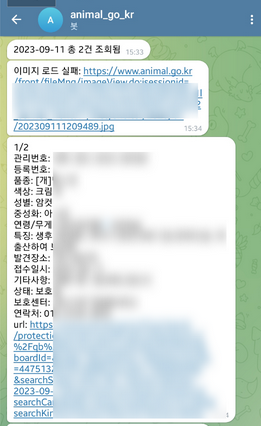
대략 이렇다.
근데 아무리 테스트해봐도 텔레그램에서 이미지 전송이 되질 않는다. 이미지 url만 보내면 되는 걸로 아는 데 뭐가 문제였는지는 아직도 모르겠다. 용량 문제를 다들 이야기하던데 썸네일 이미지 활용해서 용량 허용 한도 안에서만 보냈다...ㅜㅜ
물론 이미지를 받아서 어딘가 DB에 넣고 보내는 방법도 있겠지만 한시가 급한 상황에서 일이 너무 커질 것 같았기에,
우선 이미지 링크 클릭해서라도 보면 되겠지 라는 생각으로 여기서 초안을 마무리했다.
이제 람다로 옮기고 스케줄러만 구성하면 계속해서 저 정보들을 올려 줄 수 있겠지..?
...라고 생각한 제가 바보였어요
09.14(목)
람다랑 씨름한 날
Lambda가 뭔지는 일하면서 그리고 CLF 준비하면서 대략 알고는 있었다. 하지만 써본 적은 이번이 처음이다.
동빈나 강의 보면서 기본 사용법을 익히고, 코드를 옮기고 있는데 생각난 문제.
셀레늄은 어떻게 돌리지...?
람다는 서버리스니까 크롬을 깔 수도 없고, 크롬드라이버는 뭘 깔아야 하는지도 모르고, 그랬을 때 람다가 과연 크롬을 버텨 줄까?
그리고 크롬드라이버는 어디에 올려 둬야 하는거지?
그래도 다행히, 람다에서 셀레늄을 돌리려는 시도는 아주 많았고, 디테일한 가이드도 많았다.
람다에 셀레늄을 세팅하는 방법은 여기를 중심으로 다양한 소스들을 참고하였다.
다양한 소스들을 찾아 본 결과를 요약하자면
- 셀레늄 패키지는 그냥 레이어로 올린다
- 웹드라이버는 리눅스 버전을 구해서 레이어로 올린다
- 대신 크롬 드라이버를 gui없이 돌아가도록 (headless) 세팅해 주고, 버전 등의 다른 옵션들도 지정해야 한다.
레이어를 올리는 것도 처음에는 많이 헤매서, 처음에는 폴더 구조도 잘못 짜서 올리고, 여러 번 지웠다 올렸다 반복하고, 버전 열몇 개씩 쌓이고 했었는데,
익숙해지니 관리하는 나름의 요령(?)도 생겼다.
환경을 바꿀 일이 잘 없을 것 같은 패키지들을 따로 레이어로 구분해 픽스해 두고, 여러 호환성 문제나 코드 최적화하는 과정에서 자주 변하는 패키지들만 따로 묶어서 수시로 업로드했다.
업로드하는 zip파일 용량이 작아지기도 하고, 혹시 레이어 파일을 잘못 건드렸을 때도 로컬에서 다시 올려야 하는 패키지가 적어서 관리하기도 편했다.
3.8 환경에서 세팅과 개발을 마치고, 드디어 코드가 돌아가는데

오...
로컬에서 크롬드라이버 정말 많이 썼지만 한번도 본 적 없는 에러다.
찾아보니 결론은 "니가 3.8버전 써서 안됨"이었다.
3.7로 낮추면 동작한다고 한다.
올ㅋ 그렇다면 3.7로 낮춰야징!
이제 크롬드라이버는 잘 작동하는데...

3.7로 낮추니 또 이런 문제가 생겼다.
Final이라는 기본 모듈을 호출하지 못해서 생기는 문제인데, 이게 3.8부터 들어왔다고 한다.
나의 경우는 Final모듈이 telegram패키지에서 필요해서 생기는 문제였다.
즉, 3.8이상에서도 3.7 이하에서도 코드가 실행이 안 되는 (...) 초유의 난관에 봉착했다.
아... 어쩌지?
일단 하루종일 람다랑 씨름했기에 오늘은 여기서 끝.
09.15(금)
문제회피(?) & 완성
저렇게 버전 문제가 생겼을 때 이상적인 솔루션은 도커이다.
람다에는 도커를 띄우고, 컨테이너 내에 커스텀된 환경에서 모든 작업을 수행함으로서 버전 차이와 같은 문제를 근본적으로 해소하는 것.
동시에 람다에 가해지는 부담을 줄일 수도 있으므로 가장 이상적인 솔루션이지만,
일단 나는 도커를 실제 프로젝트에 써본 경험이 없다. 강의로만 공부한 것들을 다 녹여내면서 배포하려면 시간이 너무 오래 걸릴 것 같았다.
게다가 텔레그램으로 이미지 전송이 계속 실패하면서, 다른 방법을 찾아야겠다고 생각했다.
그러던 중 생각난 대안은 바로 Slack Hook였다.
Slack Hook은 단순히 json구문만 짜 주면 알아서 동작하는 Web API이기 때문에 별도의 복잡한 패키지를 요구하지 않는다.
따라서 내가 맞닥뜨린 호환성 문제에서 매우 자유로울 것이다.
그리고 텔레그램에서 이미지 전송에 계속 실패했기 때문에, 이미지 전송 성공 가능성을 높일 방법을 찾아야 한다.
슬랙은 이미지 url만 보내 주면 알아서 이미지를 찾아서 보내 주기 때문에, 어쩌면 이 방법이 더 쉽게 먹힐지도 모른다는 생각이 들었다.
이러한 점들을 종합해 봤을 때, 도커로 문제를 '잡는'것보다는 텔레그램 출력 부분을 슬랙으로 바꿔서 문제를 '피하는'쪽을 택했다.
slack hook기반의 봇은 회사에서 써본 적 있기 때문에 만드는 게 그리 어렵지 않았다.
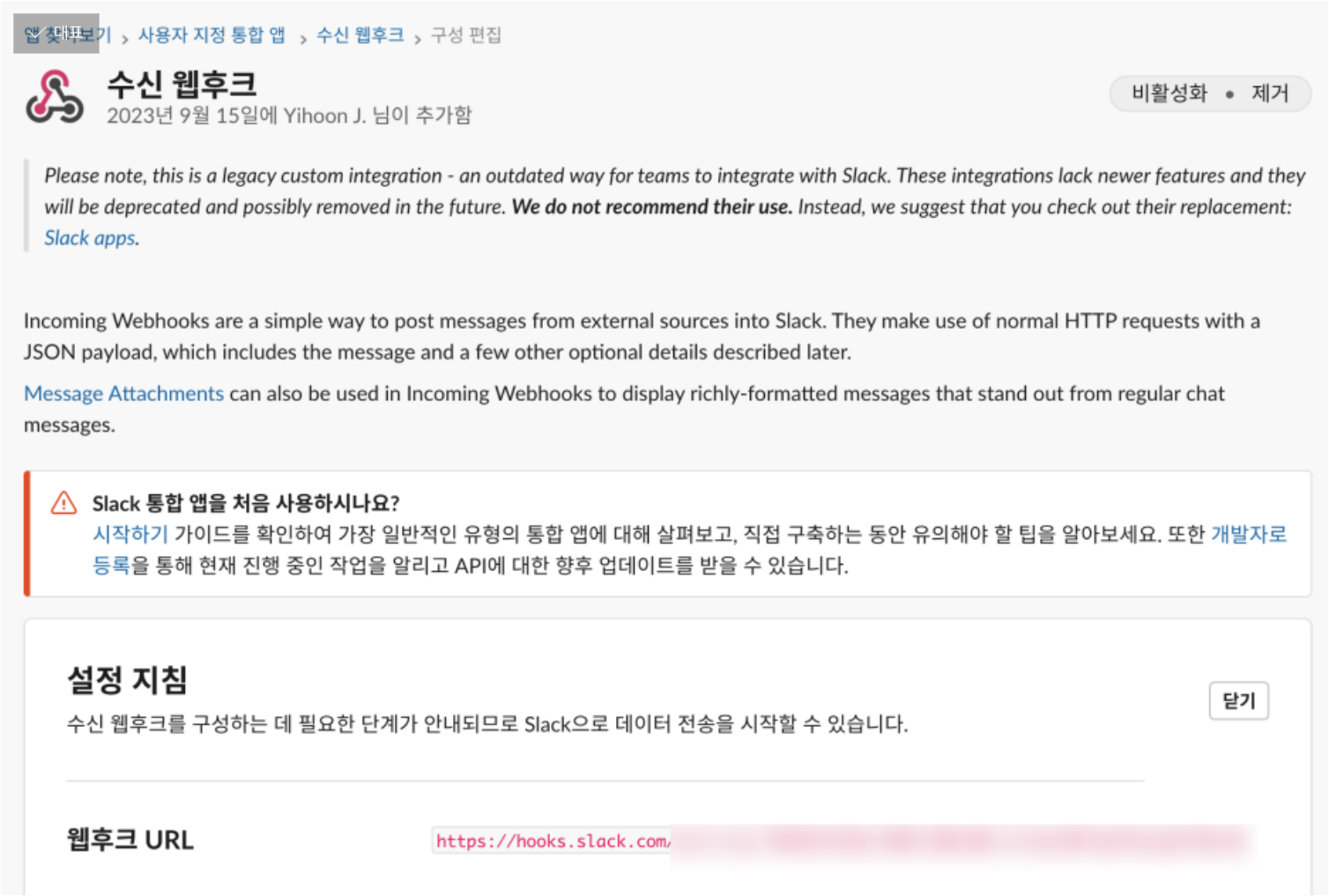
더 이상 비동기 세팅도 고집할 필요가 없었고, 이미지 전송도 잘 되는 것을 확인하였다.
앞서 언급한 Lambda Selenium 포스팅에서 컴퓨팅 한도를 넉넉하게 잡아야 함을 알려 준 덕분에, 메모리 1024mb, 실행 시간도 300초로 잡아 주었다.
(가끔 데이터가 100건 가량으로 많은 날들은 300초로 안 되어서 결국 900초로 과감히 다시 늘렸다)
전송할 데이터가 많은 기준 날짜를 잡아서 맥시멈으로 부하가 걸리는 날에도 문제가 없는지 테스트해봤는데
응 어림도 없지
slack hook의 경우 초당 1개 이상의 메시지가 계속해서 들어오면 스팸으로 간주하고 메시지 전송을 차단한다고 한다.

현재 수준으로는 "슬랙봇 시작"이라는 문구와 데이터 수집 진행 수준, 그리고 보호 동물 한 건당 두 개 (이미지, 텍스트)의 메시지를 보내는데, 이게 거의 동시에 쏟아져 들어오니 블락시키는 것.
지금 정보 수집하는 데 시간이 최소 30초, 많게는 5분 이상도 소요되는데,
최종 수신자 입장에서는 모듈이 돌아가는 걸 보고 있으면 오히려 오래 돌아가는 게 체감되어 더 불편할 것 같아서,
실행 진행상황과 관련된 문구는 전송하지 않기로 했다.
그리고 결과 문구도 건수 하나 당 메시지 하나에 모두 concat시켜서 건수를 최소화하고,
결과 출력 시에도 1초의 sleep을 걸어 주었다.
그랬더니 잘 된다!
기쁜 마음으로 최종 커밋까지 마치고 스케줄러도 만들어 주었다.
AWS에서 스케줄러를 써 본 경험은 없다.
하지만 분명 AWS에 있을 거라고 생각하고 서치해 보았다.
이렇게 단순히 시간 단위로 반복하는 것은 Eventbridge라는 제품을 쓰면 된다.
사용도 매우 간단하다. 실행 주기를 정하는 Cron표현식이 익숙지 않아서 한참 헤매다가, AWS 공식 도큐먼트를 참고해서 완성할 수 있었다.
GMT기준 시각이기 때문에 21시를 기준으로 설정하였다. 즉 한국 시간으로는 매일 오전 6시에 lambda function이 실행된다.
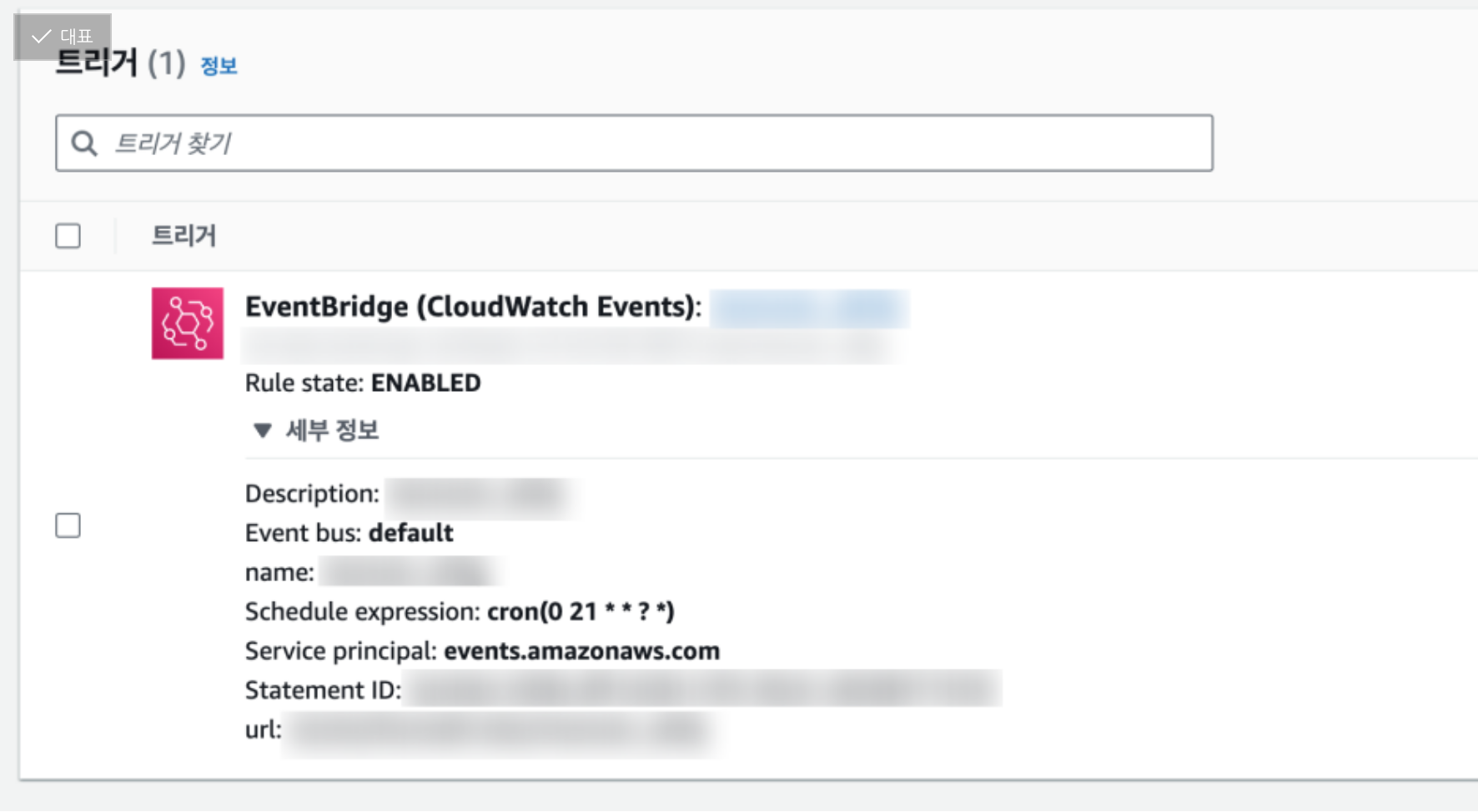
그리고 다음 날 오전 6시에 정상적으로 슬랙 온 거 확인하고 개발 완료!
아침에 눈 뜨자마자 핸드폰 확인했을 때모든게 완벽했다...
이 짜릿함으로 개발 하는거 아닐까?
배운 점들
- AWS로 단독 개발은 처음이다. 회사에서도 EC2컴퓨팅은 해 봤지 Lambda는 처음이었다. 처음에 많이 헤매서 그렇지 막상 까 보니 쉽고, 유용하고, 그리고 무엇보다도 프리 티어 사용량이 나같은 학부생 수준에게는 정말 차고 넘친다.
- Python에서 버전 문제로 홍역을 겪은 적이 별로 없는데, 이번에 제대로 경험한 듯. 버전 호환 문제를 사전에 확실히 체크하면 좋겠지만, 현실적으로 어려운 일이므로 가급적 간단한 패키지, 기본 모듈들 위주로 사용하자.
- 개발 기간은 항상 여유있게 잡자. 나는 내 생각만큼 고수가 아니다...
여유가 된다면...
일단은 필요하지 않다고 생각해서 구현하지 않았다만, 수집한 정보를 DB에 저장하는 프로세스도 어쩌면 필요할지도 모르겠다. 예전에 수집한 정보가 필요하다면, 그때그때 실행하는 것보다는 바로바로 꺼내서 확인하는 게 더 빠를 테니까. 이건 상의해보고 결정하기로.
스케줄러를 최대한 간단하게 짠다고 짠 거긴 한데, 그래도 실행 시간이 너무 오래 걸린다. 특히 상세 url을 셀레늄으로 긁어 오는 데 시간이 너무 오래 걸려서, 이 부분을 최적화할 방법을 찾아야 한다. 아직 리소스에 여유가 있으므로 multiprocessing을 통해서 실행 시간을 단축시키는 쪽으로 보완을 수행할 생각.
