
27 배열
27.1 배열이란?
배열(Array)은 여러 개의 값을 순차적으로 나열한 자료구조다
- 배열은 사용 빈도가 매우 높은 가장 기본적인 자료구조로
- 자바스크립트는 배열을 다루기 위한 유용한 메서드를 다수 제공한다.
const arr = ['apple', 'banana', 'orange'];- 배열이 가지고 있는 값을 요소(
element)라고 부르고- 자바스크립트의 모든 값은 배열의 요소가 될 수 있다.
- 배열의 요소는 인덱스(
index)를 가지며 - 배열은 요소의 개수 즉, 배열의 길이를 나타내는
length프로퍼티를 갖는다.- 배열은 인덱스와
length프로퍼티를 갖기 때문에for문을 통해 순차적으로 요소에 접근이 가능하다
- 배열은 인덱스와
// 인덱스로 배열 요소에 접근
arr[0] // ➔ 'apple'
arr[1] // ➔ 'banana'
arr[2] // ➔ 'orange'
// 배열 요소 개수(길이)
arr.length // ➔ 3
// for문을 통해 순차적 요소 접근
// 반복문으로 자료 구조를 순서대로 순회하기 위해서는 자료 구조의 요소에 순서대로
// 접근할 수 있어야 하며 자료 구조의 길이를 알 수 있어야 한다.
const arr = [1, 2, 3];
for (let i = 0; i < arr.length; i++) {
console.log(arr[i]); // 1 2 3
}자바스크립트에 배열이라는 타입은 존재하지 않는다. 배열은 객체 타입이다.
배열은
- 배열 리터럴,
Array생성자 함수,Array.of,Array.from메서드로 생성할 수 있다. - 배열의 생성자 함수는
Array이며, 배열의 프로토타입 객체는Array.prototype이다. - 배열은 객체지만 일반 객체와는 구별되는 독특한 특성이 있다
- 일반 객체와 배열을 구분하는 가장 명확한 차이는 값의 순서와
length프로퍼티다
- 일반 객체와 배열을 구분하는 가장 명확한 차이는 값의 순서와
| 구분 | 객체 | 배열 |
|---|---|---|
| 구조 | 프로퍼티 키와 프로퍼티 값 | 인덱스와 요소 |
| 값의 참조 | 프로퍼티 키 | 인덱스 |
| 값의 순서 | X | O |
length 프로퍼티 | X | O |
27.2 자바스크립트 배열은 배열이 아니다.
자료구조에서 말하는 배열은
- 동일한 크기의 메모리 공간이
- 빈틈없이 연속적으로 나열된 자료구조를 말한다
- 즉, 배열의 요소는 하나의 데이터 타입으로 통일되어 있으며 서로 연속적으로 인접해 있고, 이러한 배열을 밀집 배열이라 한다

자바스크립트에서의 배열은
- 배열의 요소를 위한 각각의 메모리 공간은 동일한 크기를 갖지 않아도 되며,
- 연속적으로 이어져 있지 않을 수도 있다.
- 배열의 요소가 연속적으로 이어져 있지 않는 배열을 희소 배열이라 한다.
- 즉, 자바스크립트의 배열은 일반적인 배열의 동작을 흉내낸 특수한 객체이다
일반적인 배열과 자바스크립트 배열의 장단점을 정리해보면 다음과 같다.
- 일반적인 배열은
- 인덱스로 요소에 빠르게 접근할 수 있다.
- 하지만 특정 요소를 검색하거나 요소를 삽입 또는 삭제하는 경우에는 효율적이지 않다.
- 자바스크립트 배열은
- 해시 테이블로 구성된 객체이므로
- 인덱스로 요소에 접근하는 경우 일반적인 배열보다 성능적인 면에서 느릴수밖에 없는 구조적인 단점이 있다.
- 하지만 특정 요소를 삽입 또는 삭제하는 경우에는 일반적인 배열보다 빠른 성능을 기대할 수 있다.
27.3 length 프로퍼티와 희소 배열
length 프로퍼티는
- 값은 요소의 개수, 즉 배열의 길이를 나타내는
0이상의 정수를 값으로 갖는다.- 일반적인 배열의
length는 배열 요소의 개수, 즉 배열의 길이와 언제나 일치하지만 - 희소 배열의
length는 희소 배열의 실제 요소 개수보다 언제나 크다.
- 일반적인 배열의
의도적으로 희소 배열을 만들어야 하는 상황을 발생하지 않으므로 희소배열 사용은 지양하는것이 좋다.
27.4 배열 생성
✔️ 27.4.1 배열 리터럴
배열 리터럴은 0개 이상의 요소를 쉼표로 구분하여 대괄호([])로 묶는다.
const arr = [1, 2, 3];
console.log(arr.length); // 3✔️ 27.4.2 Array 생성자 함수
Array 생성자 함수를 통해 배열을 생성할 수 있다
Array 생성자 함수는 전달된 인수의 개수에 따라 다르게 동작하므로 주의가 필요하다
// 전달된 인수가 1개이고 숫자인 경우 length 프로퍼티 값이 인수인 배열을 생성한다.
const arr = new Array(10);
console.log(arr); // [empty × 10]
console.log(arr.length); // 10
// 전달된 인수가 없는 경우 빈 배열을 생성한다. 즉, 배열 리터럴 []과 같다.
new Array(); // -> []
// 전달된 인수가 2개 이상이면 인수를 요소로 갖는 배열을 생성한다.
new Array(1, 2, 3); // -> [1, 2, 3]
// 전달된 인수가 1개지만 숫자가 아니면 인수를 요소로 갖는 배열을 생성한다.
new Array({}); // -> [{}]
✔️ 27.4.3 Array.of
ES6에서 도입된 Array.of 메서드는 전달된 인수를 요소로 갖는 배열을 생성한다.
// 전달된 인수가 1개이고 숫자이더라도 인수를 요소로 갖는 배열을 생성한다.
Array.of(1); // -> [1]
Array.of(1, 2, 3); // -> [1, 2, 3]
Array.of('string'); // -> ['string']✔️ 27.4.4 Array.from
ES6에서 도입된 Array.from 메서드는
- 유사 배열 객체 또는 이터러블 객체를 인수로 전달받아 배열로 변환하여 반환한다.
// 유사 배열 객체를 변환하여 배열을 생성한다.
Array.from({ length: 2, 0: 'a', 1: 'b' }); // ➔ ['a', 'b']
// 이터러블을 변환하여 배열을 생성한다. 문자열은 이터러블이다.
Array.from('Hello'); // ➔ ['H', 'e', 'l', 'l', 'o']27.5 배열 요소의 참조
배열의 요소를 참조할 때에는 대괄호([]) 표기법을 사용한다.
const arr = [1, 2];
// 인덱스가 0인 요소를 참조
console.log(arr[0]); // 1
// 인덱스가 1인 요소를 참조
console.log(arr[1]); // 2배열은 사실
- 인덱스를 나타내는 문자열을 프로퍼티 키로 갖는 객체다.
- 따라서 존재하지 않는 프로퍼티 키로 객체의 프로퍼티에 접근했을때
undefined를 반환하는 것 처럼 - 배열도 존재하지 않는 요소를참조하면
undefined를 반환한다.
27.6 배열 요소의 추가와 갱신
객체 프로퍼티를 동적으로 추가할 수 있는 것처럼
- 배열에도 요소를 동적으로 추가할 수 있다.
- 존재하지 않는 인덱스를 사용해 값을 할당하면 새로운 요소가 추가된다.
- 이때
length프로퍼티 값은 자동 갱신된다
const arr = [0];
// 배열 요소의 추가
arr[1] = 1;
console.log(arr); // [0, 1]
console.log(arr.length); // 2- 이미 존재하는 요소에 값을 재할당하면 요소값이 갱신된다.
// 요소값의 갱신
arr[1] = 10;
console.log(arr); // [0, 10, empty × 98, 100]
const arr = [];
// 배열 요소의 추가
arr[0] = 1;
arr['1'] = 2;
// 프로퍼티 추가
arr['foo'] = 3;
arr.bar = 4;
arr[1.1] = 5;
arr[-1] = 6;
console.log(arr); // [1, 2, foo: 3, bar: 4, '1.1': 5, '-1': 6]
// 프로퍼티는 length에 영향을 주지 않는다.
console.log(arr.length); // 2- 만약 정수 이외의 값을 인덱스처럼 사용하면
- 요소가 생성되는 것이 아니라
- 프로퍼티가 생성되고 이는
length프로퍼티 값에 영향을 주지 않는다.
27.7 배열 요소의 삭제
배열은 사실 객체이기 때문에
- 배열의 특정 요소를 삭제하기 위해
delete연산자를 사용할 수 있다. - 이때
delete연산자는 객체의 프로퍼티를 삭제한다. - 따라서 배열은 희소 배열이 되며
length프로퍼티의 값은 변하지 않으므로delete연산자는 사용하지 않는것이 좋다.
const arr = [1, 2, 3];
// 배열 요소의 삭제
delete arr[1];
console.log(arr); // [1, empty, 3]
// length 프로퍼티에 영향을 주지 않는다. 즉, 희소 배열이 된다.
console.log(arr.length); // 3희소 배열을 만들지 않으면서 배열의 특정 요소를 완전히 삭제하려면 Array.prototype.splice 메서드를 사용한다
27.8 배열 메서드
배열에는
- 원본 배열(배열 메서드를 호출한 배열, 즉 배열 메서드의 구현체 내부에서
this가 가리키는 객체)을 직접 변경하는 메서드와 - 원본 배열을 직접 변경하지 않고 새로운 배열을 생성하여 반환하는 메서드가 있다
✔️ 27.8.1 Array.isArray
Array.isArray는
Array생성자 함수의 정적 메서드로- 전달된 인수가 배열이면
true, 배열이 아니면false를 반환한다.
// true
Array.isArray([]);
Array.isArray([1, 2]);
Array.isArray(new Array());
// false
Array.isArray();
Array.isArray({});
Array.isArray(null);
Array.isArray(undefined);
Array.isArray(1);
Array.isArray('Array');
Array.isArray(true);
Array.isArray(false);
Array.isArray({ 0: 1, length: 1 })✔️ 27.8.2 Array.prototype.indexOf
indexOf 메서드는 원본 배열에서 인수로 전달된 요소를 검색하여 인덱스를 반환한다.
- 원본 배열에 인수로 전달한 요소와 중복되는 요소가 여러 개 있다면 첫 번째로 검색된 요소의 인덱스를 반환
- 원본 배열에 인수로 전달한 요소가 없다면 -1을 반환
const arr = [1, 2, 2, 3];
// 배열 arr에서 요소 2를 검색하여 첫 번째로 검색된 요소의 인덱스를 반환한다.
arr.indexOf(2); // ➔ 1
// 배열 arr에 요소 4가 없으므로 -1을 반환한다.
arr.indexOf(4); // ➔ -1
// 두 번째 인수는 검색을 시작할 인덱스다. 두 번째 인수를 생략하면 처음부터 검색한다.
arr.indexOf(2, 2); // ➔ 2
const foods = ['apple', 'banana', 'orange'];
// foods 배열에 'orange' 요소가 존재하는지 확인한다.
if (foods.indexOf('orange') === -1) {
// foods 배열에 'orange' 요소가 존재하지 않으면 'orange' 요소를 추가한다.
foods.push('orange');
}
console.log(foods); // ["apple", "banana", "orange"]indexOf 메서드 대신 ES7에서 도입된 Array.prototype.includes 메서드를 사용하면 가독성이 더 좋다
const foods = ['apple', 'banana', 'orange'];
if (!foods.includes('orange')) {
// foods 배열에 'orange' 요소가 존재하지 않으면 'orange' 요소를 추가한다.
foods.push('orange');
}
console.log(foods); // ["apple", "banana", "orange"]✔️ 27.8.3 Array.prototype.push
push 메서드는
- 인수로 전달받은 모든 값을 원본 배열의 마지막 요소로 추가하고
- 변경된
length프로퍼티 값을 반환한다. push메서드는 원본 배열을 직접 변경한다.
const arr = [1, 2];
// 인수로 전달받은 모든 값을 원본 배열 arr의 마지막 요소로 추가하고 변경된 length 값을 반환한다.
let result = arr.push(3, 4);
console.log(result); // 4
// push 메서드는 원본 배열을 직접 변경한다.
console.log(arr); // [1, 2, 3, 4]push 메서드는 성능 면에서 좋지 않다.
마지막 요소로 추가할 요소가 하나뿐이라면 length 프로퍼티를 사용하여 배열의 마지막 요소에 직접 추가하는것이 더 빠르다.
const arr = [1, 2];
// arr.push(3)과 동일한 처리를 한다. 이 방법이 push 메서드보다 빠르다.
arr[arr.length] = 3;
console.log(arr); // [1, 2, 3]✔️ 27.8.4 Array.prototype.pop
pop 메서드는
- 원본 배열에서 마지막 요소를 제거하고 제거한 요소를 반환한다.
- 원본 배열이 빈 배열이면
undefined를 반환한다. push메서드는 원본 배열을 직접 변경한다.
const arr = [1, 2];
// 원본 배열에서 마지막 요소를 제거하고 제거한 요소를 반환한다.
let result = arr.pop();
console.log(result); // 2
// pop 메서드는 원본 배열을 직접 변경한다.
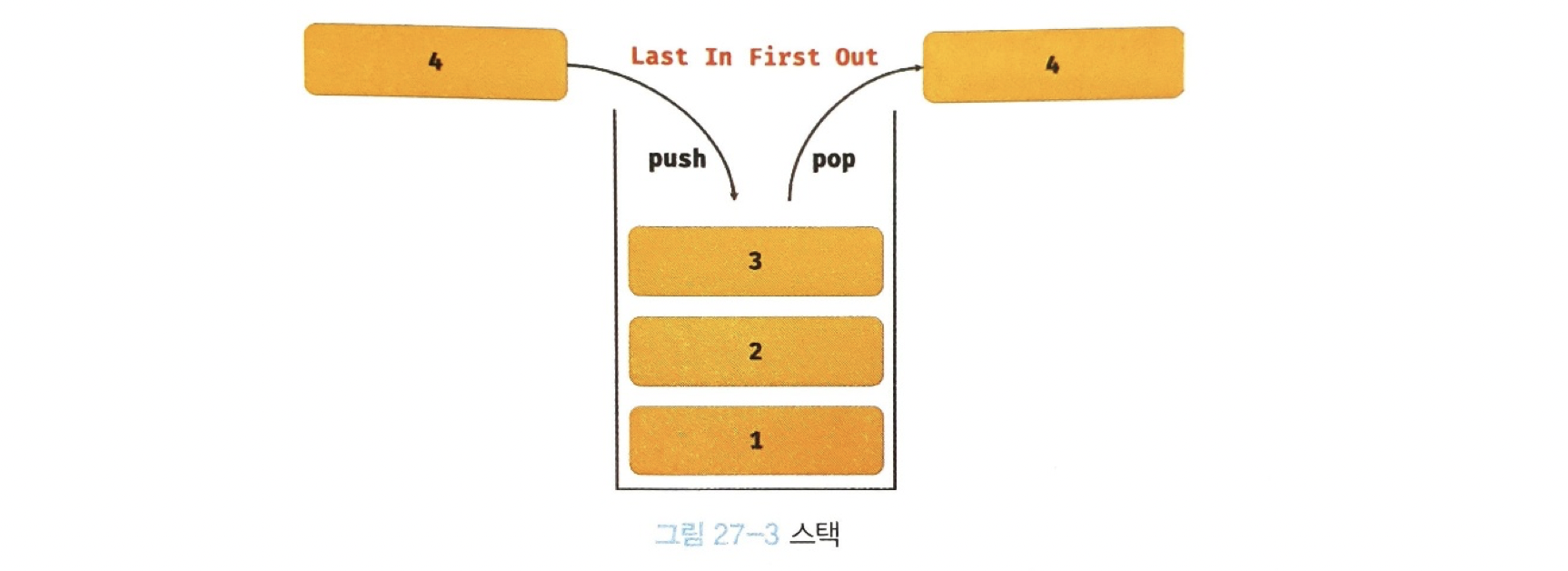
console.log(arr); // [1]pop 메서드와 push 메서드를 사용하면 스택을 쉽게 구현할 수 있다.
💡 스택(stack)
스택은 데이터를 마지막에 밀어 넣고, 마지막에 밀어 넣은 데이터를 먼저 꺼내는 후입 선출(
LIFO - Last In First Out) 방식의 자료구조이다.
✔️ 27.8.5 Array.prototype.unshift
unshift 메서드는
- 인수로 전달받은 모든 값을 원본 배열의 선두에 요소로 추가하고
- 변경된
length프로퍼티 값을 반환한다. unshift메서드는 원본 배열을 직접 변경한다.
const arr = [1, 2];
// 인수로 전달받은 모든 값을 원본 배열의 선두에 요소로 추가하고 변경된 length 값을 반환한다.
let result = arr.unshift(3, 4);
console.log(result); // 4
// unshift 메서드는 원본 배열을 직접 변경한다.
console.log(arr); // [3, 4, 1, 2]✔️ 27.8.6 Array.prototype.shift
shift 메서드는
- 원본 배열에서 첫 번째 요소를 제거하고 제거한 요소를 반환한다.
- 원본 배열이 빈 배열이면
undefined를 반환한다. shift메서드는 원본 배열을 직접 변경한다.
const arr = [1, 2];
// 원본 배열에서 첫 번째 요소를 제거하고 제거한 요소를 반환한다.
let result = arr.shift();
console.log(result); // 1
// shift 메서드는 원본 배열을 직접 변경한다.
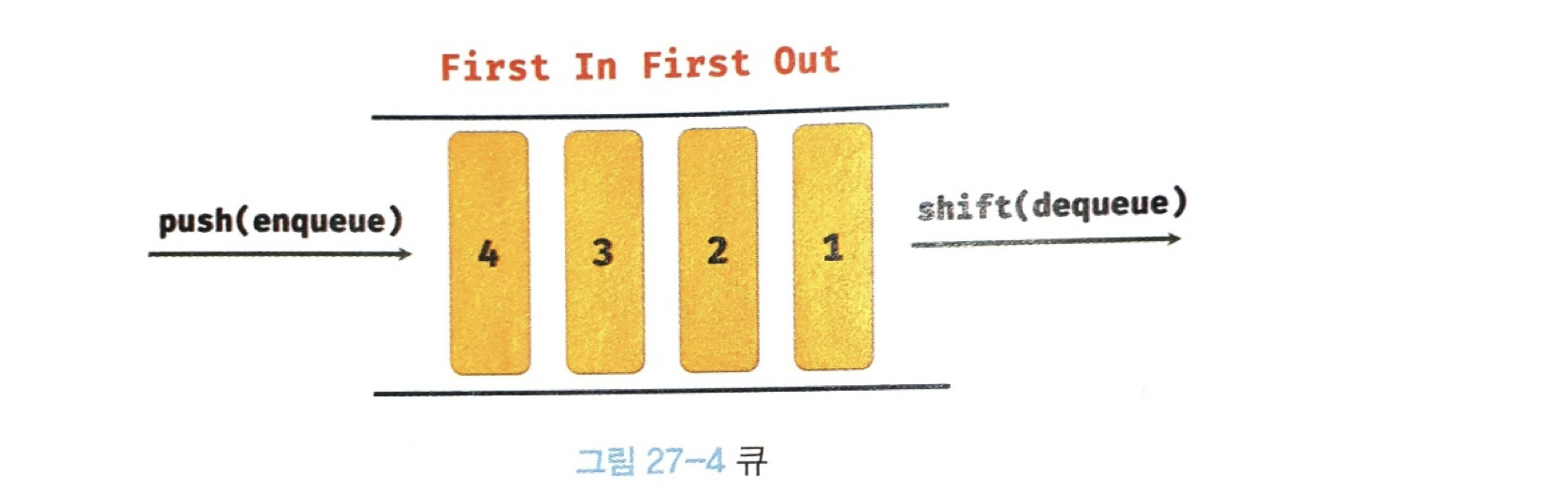
console.log(arr); // [2]shift 메서드와 push 메서드를 사용하면 큐을 쉽게 구현할 수 있다.
💡 큐(queue)
큐는 데이터를 마지막에 밀어 넣고, 가장 먼저 밀어 넣은 데이터를 먼저 꺼내는 선입 선출(
FIFO - First in First Out) 방식의 자료구조이다.
✔️ 27.8.7 Array.prototype.concat
concat 메서드는
- 인수로 전달된 값들(배열 또는 원시값)을 원본 배열의 마지막 요소로 추가한 새로운 배열을 반환한다.
- 인수로 전달한 값이 배열인 경우 배열을 해체하여 새로운 배열의 요소로 추가한다.
- 원본 배열은 변경되지 않는다.
const arr1 = [1, 2];
const arr2 = [3, 4];
// 배열 arr2를 원본 배열 arr1의 마지막 요소로 추가한 새로운 배열을 반환한다.
// 인수로 전달한 값이 배열인 경우 배열을 해체하여 새로운 배열의 요소로 추가한다.
let result = arr1.concat(arr2);
console.log(result); // [1, 2, 3, 4]
// 숫자를 원본 배열 arr1의 마지막 요소로 추가한 새로운 배열을 반환한다.
result = arr1.concat(3);
console.log(result); // [1, 2, 3]
// 배열 arr2와 숫자를 원본 배열 arr1의 마지막 요소로 추가한 새로운 배열을 반환한다.
result = arr1.concat(arr2, 5);
console.log(result); // [1, 2, 3, 4, 5]
// 원본 배열은 변경되지 않는다.
console.log(arr1); // [1, 2]✔️ 27.8.8 Array.prototype.splice
push, pop, unshift, shift 메서드는
- 모두 원본 배열을 직접 변경하는 메서드이며
- 원본 배열의 처음이나 마지막 요소를 추가하거나 제거한다.
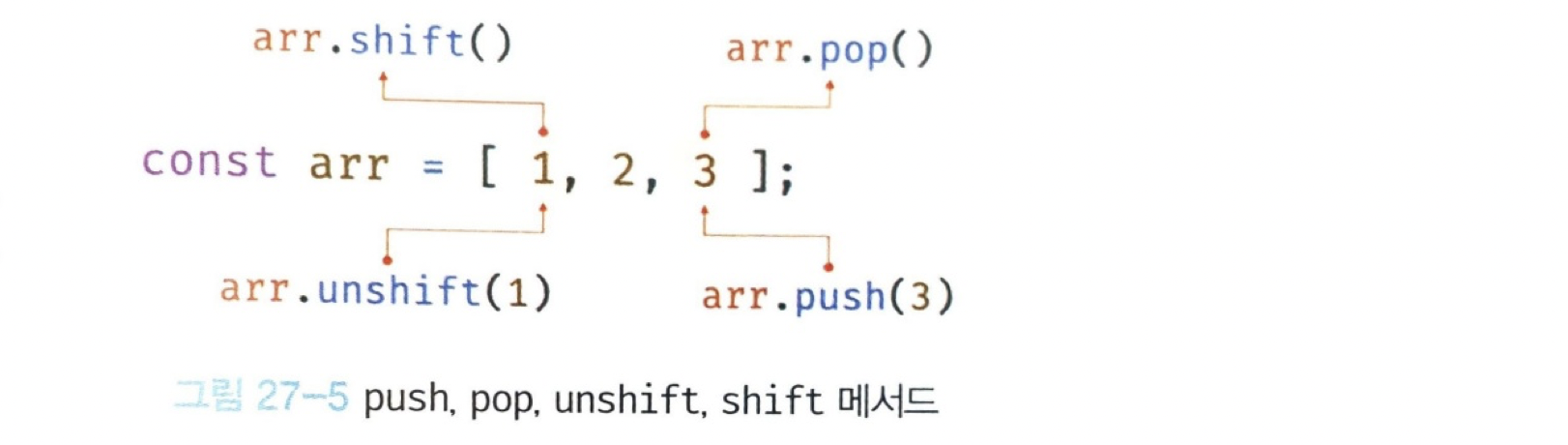
원본 배열 중간에 요소를 추가하거나 중간에 있는 요소를 제거하는 경우 splice 메서드를 사용한다
splice메서드는 3개의 매개변수가 있으며start: 원본 배열의 요소를 제거하기 시작할 인덱스이다.start만 지정하면 원본 배열의 모든 요소를 제거한다.start가 음수일 경우 배열의 끝에서의 인덱스를 나타낸다.
deleteCount(옵션): 원본 배열의 요소를 제거하기 시작할 인덱스인start부터 제거할 요소의 개수이다.deleteCount가 0인 경우 아무런 요소도 제거되지 않는다.
items(옵션): 제거한 위치에 삽입할 요소들의 목록이다.- 생략할 경우 원본 배열에서 요소를 제거하기만 한다.
- 원본 배열을 직접 변경한다
const arr = [1, 2, 3, 4];
// 원본 배열의 인덱스 1부터 2개의 요소를 제거하고 그 자리에 새로운 요소 20, 30을 삽입한다.
const result_1 = arr.splice(1, 2, 20, 30);
// 원본 배열의 인덱스 1부터 0개의 요소를 제거하고 그 자리에 새로운 요소 100을 삽입한다.
const result_2 = arr.splice(1, 0, 100);
// 원본 배열의 인덱스 1부터 2개의 요소를 제거한다.
const result_3 = arr.splice(1, 2);
// 원본 배열의 인덱스 1부터 모든 요소를 제거한다.
const result_4 = arr.splice(1);배열에서 특정 요소를 제거하려면
indexOf메서드를 통해 특정 요소의 인덱스를 취득한 다음splice메서드를 사용한다.
filter 메서드를 사용하여 특정 요소를 제거할 수도 있다. 하지만 특정 요소가 중복된 경우 모두 제거된다.
✔️ 27.8.9 Array.prototype.slice
slice 메서드는
- 인수로 전달된 범위의 요소들을 복사하여 배열로 반환한다.
- 원본 배열은 변경되지 않는다.
slice메서드는 두개의 배개변수를 갖는다.start: 복사를 시작할 인덱스다. 음수인 경우 배열 끝에서의 인덱스를 나타낸다. 음수일 경우 배열 끝에서의 인덱스를 나타낸다.end(옵션): 복사를 종료할 인덱스다.end는 생략 시 기본값은length프로퍼티 값이다.
const arr = [1, 2, 3];
// arr[0]부터 arr[1] 이전(arr[1] 미포함)까지 복사하여 반환한다.
arr.slice(0, 1); // ➔ [1]
// arr[1]부터 arr[2] 이전(arr[2] 미포함)까지 복사하여 반환한다.
arr.slice(1, 2); // ➔ [2]
// 배열의 끝에서부터 요소를 한 개 복사하여 반환한다.
arr.slice(-1); // ➔ [3]
// 배열의 끝에서부터 요소를 두 개 복사하여 반환한다.
arr.slice(-2); // ➔ [2, 3]
// 원본은 변경되지 않는다.
console.log(arr); // [1, 2, 3]slice 메서드의 인수를 모두 생략하면
- 원본 배열의 복사본을 생성해 반환한다.
- 이때 생성된 복사본은 얕은 복사를 통해 생성된다.
const arr = [1, 2, 3];
// 인수를 모두 생략하면 원본 배열의 복사본을 생성하여 반환한다.
const copy = arr.slice();
console.log(copy); // [1, 2, 3]
console.log(copy === arr); // false💡 얕은복사와 깊은복사
객체를 프로퍼티 값으로 갖는 객체의 경우
- 얕은 복사는 한 단계까지만 복사하는 것을 말하고
- 깊은 복사는 객체에 중첩되어 있는 객체까지 모두 복사하는 것을 말한다.
slice메서드, 스프레드 문법,Object.assign메서드는 모두 얕은 복사를 수행한다
✔️ 27.8.10 Array.prototype.join
join 메서드는
- 원본 배열의 모든 요소를 문자열로 변환한 후,
- 인수로 전달받은 문자열, 즉 구분자로 연결한 문자열을 반환한다.
- 구분자는 생략 가능하며 기본 구분자는 콤마(
,)다.
const arr = [1, 2, 3, 4];
// 기본 구분자는 ','이다.
// 원본 배열 arr의 모든 요소를 문자열로 변환한 후, 기본 구분자 ','로 연결한 문자열을 반환한다.
arr.join(); // ➔ '1,2,3,4';
// 원본 배열 arr의 모든 요소를 문자열로 변환한 후, 빈문자열로 연결한 문자열을 반환한다.
arr.join(''); // ➔ '1234'
// 원본 배열 arr의 모든 요소를 문자열로 변환한 후, 구분자 ':'로 연결한 문자열을 반환한다.ㄴ
arr.join(':'); // ➔ '1:2:3:4'✔️ 27.8.11 Array.prototype.reverse
reverse 메서드는
- 원본 배열의 순서를 반대로 뒤집는다.
- 이때 원본 배열이 변경된다.
- 반환값은 변경된 배열이다.
const arr = [1, 2, 3];
const result = arr.reverse();
// reverse 메서드는 원본 배열을 직접 변경한다.
console.log(arr); // [3, 2, 1]
// 반환값은 변경된 배열이다.
console.log(result); // [3, 2, 1]✔️ 27.8.12 Array.prototype.fill
ES6에서 도입된 fill 메서드는
- 인수로 전달받은 값을 배열의 처음부터 끝까지 요소로 채운다.
- 이때 원본 배열이 변경된다.
const arr = [1, 2, 3, 4, 5];
// 인수로 전달 받은 값 0을 배열의 처음부터 끝까지 요소로 채운다.
arr.fill(0);
console.log(arr); // [0, 0, 0, 0, 0]
// 인수로 전달받은 값 0을 배열의 인덱스 1부터 끝까지 요소로 채운다.
arr.fill(5, 1);
console.log(arr); // [0, 5, 5, 5, 5]
// 인수로 전달받은 값 0을 배열의 인덱스 1부터 3 이전(인덱스 3 미포함)까지 요소로 채운다.
arr.fill(7, 1, 3);
console.log(arr); // [0, 7, 7, 5, 5]fill 메서드를 사용하면 배열을 생성하면서 특정 값으로 요소를 채울 수 있다.
const arr = new Array(3);
console.log(arr); // [empty × 3]
// 인수로 전달받은 값 1을 배열의 처음부터 끝까지 요소로 채운다.
const result = arr.fill(1);
// fill 메서드는 원본 배열을 직접 변경한다.
console.log(arr); // [1, 1, 1]
// fill 메서드는 변경된 원본 배열을 반환한다.
console.log(result); // [1, 1, 1]✔️ 27.8.13 Array.prototype.includes
ES7에서 도입된includes 메서드는
- 배열 내에 특정 요소가 포함되어 있는지 확인하여
true또는false를 반환한다. - 첫 번째 인수로 검색할 대상을 지정한다.
const arr = [1, 2, 3];
// 배열에 요소 2가 포함되어 있는지 확인한다.
arr.includes(2); // ➔ true
// 배열에 요소 100이 포함되어 있는지 확인한다.
arr.includes(100); // ➔ false- 두 번째 인수로 검색을 시작할 인덱스를 전달할 수 있다.
- 두 번째 인수를 생략할 경우 기본값 0이 설정된다.
- 만약 두 번째 인수에 음수를 전달하면
length프로퍼티 값과 음수 인덱스를 합산하여(length+index) 검색 시작 인덱스를 설정한다.
const arr = [1, 2, 3];
// 배열에 요소 1이 포함되어 있는지 인덱스 1부터 확인한다.
arr.includes(1, 1); // ➔ false
// 배열에 요소 3이 포함되어 있는지 인덱스 2(arr.length - 1)부터 확인한다.
arr.includes(3, -1); // ➔ true✔️ 27.8.14 Array.prototype.flat
ES10에서 도입된 flat 메서드는
- 인수로 전달한 깊이 만큼 재귀적으로 배열을 평탄화한다.
- 중첩 배열을 평탄화할 깊이를 인수로 전달할 수 있다.
- 인수를 생략할 경우 기본값은 1이다.
- 인수로
Infinity를 전달하면 중첩 배열 모두를 평탄화한다.
- 인수로
[1, [2, 3, 4, 5]].flat(); // ➔ [1, 2, 3, 4, 5]
// 중첩 배열을 평탄화하기 위한 깊이 값의 기본값은 1이다.
[1, [2, [3, [4]]]].flat(); // ➔ [1, 2, [3, [4]]]
[1, [2, [3, [4]]]].flat(1); // ➔ [1, 2, [3, [4]]]
// 중첩 배열을 평탄화하기 위한 깊이 값을 2로 지정하여 2단계 깊이까지 평탄화한다.
[1, [2, [3, [4]]]].flat(2); // ➔ [1, 2, 3, [4]]
// 2번 평탄화한 것과 동일하다.
[1, [2, [3, [4]]]].flat().flat(); // ➔ [1, 2, 3, [4]]
// 중첩 배열을 평탄화하기 위한 깊이 값을 Infinity로 지정하여 중첩 배열 모두를 평탄화한다.
[1, [2, [3, [4]]]].flat(Infinity); // ➔ [1, 2, 3, 4]27.9 배열 고차 함수
고차 함수는
- 함수를 인수로 전달받거나
- 인수를 반환하는 함수를 말한다.
자바스크립트의 함수는 일급 객체이므로 함수를 값처럼 인수로 전달할 수 있으며 반환할 수도 있다
💡함수형 프로그래밍
순수 함수와 보조 함수의 조합을 통해
- 로직 내에 존재하는 조건문과 반복문을 제거하여 복잡성을 해결하고
- 변수의 사용을 억제하여 상태 변경을 피하려는 프로그래밍 패러다임이다.
➔ 순수 함수를 통해 부수 효과를 최대한 억제하여 오류를 피하고 프로그래밍 안정성을 높이려는 노력의 일환이라고 할 수 있다
자바스크립트는 고차 함수를 다수 지원한다. 특히 배열은 매우 유용한 고차 함수를 제공한다.
✔️ 27.9.1 Array.prototype.sort
sort 메서드는
- 배열의 요소를 정렬한다.
- 원본 배열을 직접 변경하며 정렬된 배열을 반환한다.
- 오름차순으로 정렬한다.
const fruits = ['Banana', 'Orange', 'Apple'];
// 오름차순(ascending) 정렬
fruits.sort();
// sort 메서드는 원본 배열을 직접 변경한다.
console.log(fruits); // ['Apple', 'Banana', 'Orange']- 문자열 요소로 이루어진 배열의 정렬은 아무런 문제가 없지만,
- 숫자 요소로 이루어진 배열을 정렬할 때는 주의가 필요하다
sort메서드의 기본 정렬 순서는 유니코드 코드 포인트의 순서를 따른다.- 따라서 숫자 요소를 정렬할 때는
sort메서드에 정렬 순서를 정의하는 비교 함수를 인수로 전달해야 한다. - 비교 함수는 양수나 음수 또는 0을 반환해야 한다.
- 따라서 숫자 요소를 정렬할 때는
const points = [40, 100, 1, 5, 2, 25, 10];
// 숫자 배열의 오름차순 정렬. 비교 함수의 반환값이 0보다 작으면 a를 우선하여 정렬한다.
points.sort((a, b) => a - b);
console.log(points); // [1, 2, 5, 10, 25, 40, 100]
// 숫자 배열에서 최소/최대값 취득
console.log(points[0], points[points.length]); // 1 100
// 숫자 배열의 내림차순 정렬. 비교 함수의 반환값이 0보다 작으면 b를 우선하여 정렬한다.
points.sort((a, b) => b - a);
console.log(points); // [100, 40, 25, 10, 5, 2, 1]
// 숫자 배열에서 최대값 취득
console.log(points[0]); // 100✔️ 27.9.2 Array.prototype.forEach
forEach 메서드는
for문을 대체할 수 있는 고차 함수다.- 자신의 내부에서 반복문을 통해 자신을 호출한 배열을 순회하면서
- 수행해야할 처리를 콜백 함수로 전달받아 반복 호출한다.
forEach메서드는 언제나undefined를 반환한다.
const numbers = [1, 2, 3];
let pows = [];
// forEach 메서드는 numbers 배열의 모든 요소를 순회하면서 콜백 함수를 반복 호출한다.
numbers.forEach(item => pows.push(item ** 2));
console.log(pows); // [1, 4, 9]forEach 메서드의 콜백 함수는
forEach메서드를 호출한 배열의 요소값과 인덱스,forEach메서드를 호출한 배열 자체, 즉this를 순차적으로 전달받을 수 있다.
// forEach 메서드는 콜백 함수를 호출하면서 3개(요소값, 인덱스, this)의 인수를 전달한다.
[1, 2, 3].forEach((item, index, arr) => {
console.log(`요소값: ${item}, 인덱스: ${index}, this: ${JSON.stringify(arr)}`);
});
/*
요소값: 1, 인덱스: 0, this: [1,2,3]
요소값: 2, 인덱스: 1, this: [1,2,3]
요소값: 3, 인덱스: 2, this: [1,2,3]
*/✔️ 27.9.3 Array.prototype.map
map 메서드는
- 자신을 호출한 배열의 모든 요소를 순회하면서
- 인수로 전달받은 콜백 함수를 반복 호출한다.
- 콜백 함수의 반환값들로 구성된 새로운 배열을 반환한다.
- 요소값을 다른 값으로 매핑한 새로운 배열을 생성하기 위한 고차함수다
const numbers = [1, 4, 9];
// map 메서드는 numbers 배열의 모든 요소를 순회하면서 콜백 함수를 반복 호출한다.
// 그리고 콜백 함수의 반환값들로 구성된 새로운 배열을 반환한다.
const roots = numbers.map(item => Math.sqrt(item));
// 위 코드는 다음과 같다.
// const roots = numbers.map(Math.sqrt);
// map 메서드는 새로운 배열을 반환한다
console.log(roots); // [ 1, 2, 3 ]
// map 메서드는 원본 배열을 변경하지 않는다
console.log(numbers); // [ 1, 4, 9 ]map메서드가 생성하여 반환하는 새로운 배열의length프로퍼티 값은map메서드를 호출한 배열의length프로퍼티 값과 반드시 일치한다.
✔️ 27.9.4 Array.prototype.filter
filter 메서드는
- 자신을 호출한 배열의 모든 요소를 순회하면서
- 인수로 전달받은 콜백 함수를 반복 호출한다.
- 그리고 콜백 함수의 반환값이
true인 요소로만 구성된 새로운 배열을 반환한다. - 이때 원본 배열은 변경되지 않는다.
const numbers = [1, 2, 3, 4, 5];
// filter 메서드는 numbers 배열의 모든 요소를 순회하면서 콜백 함수를 반복 호출한다.
// 그리고 콜백 함수의 반환값이 true인 요소로만 구성된 새로운 배열을 반환한다.
// 다음의 경우 numbers 배열에서 홀수인 요소만을 필터링한다(1은 true로 평가된다).
const odds = numbers.filter(item => item % 2);
console.log(odds); // [1, 3, 5]filter메서드가 생성하여 반환한 새로운 배열의length프로퍼티 값은filter메서드를 호출한 배열의length프로퍼티 값과 같거나 작다
filter로 중복 제거하기const uniq = arr => arr.filter((v, i, self) => self.indexOf(v) === i ); console.log(uniq([2, 1, 2, 3, 4, 3, 4])); // [2, 1, 3, 4]
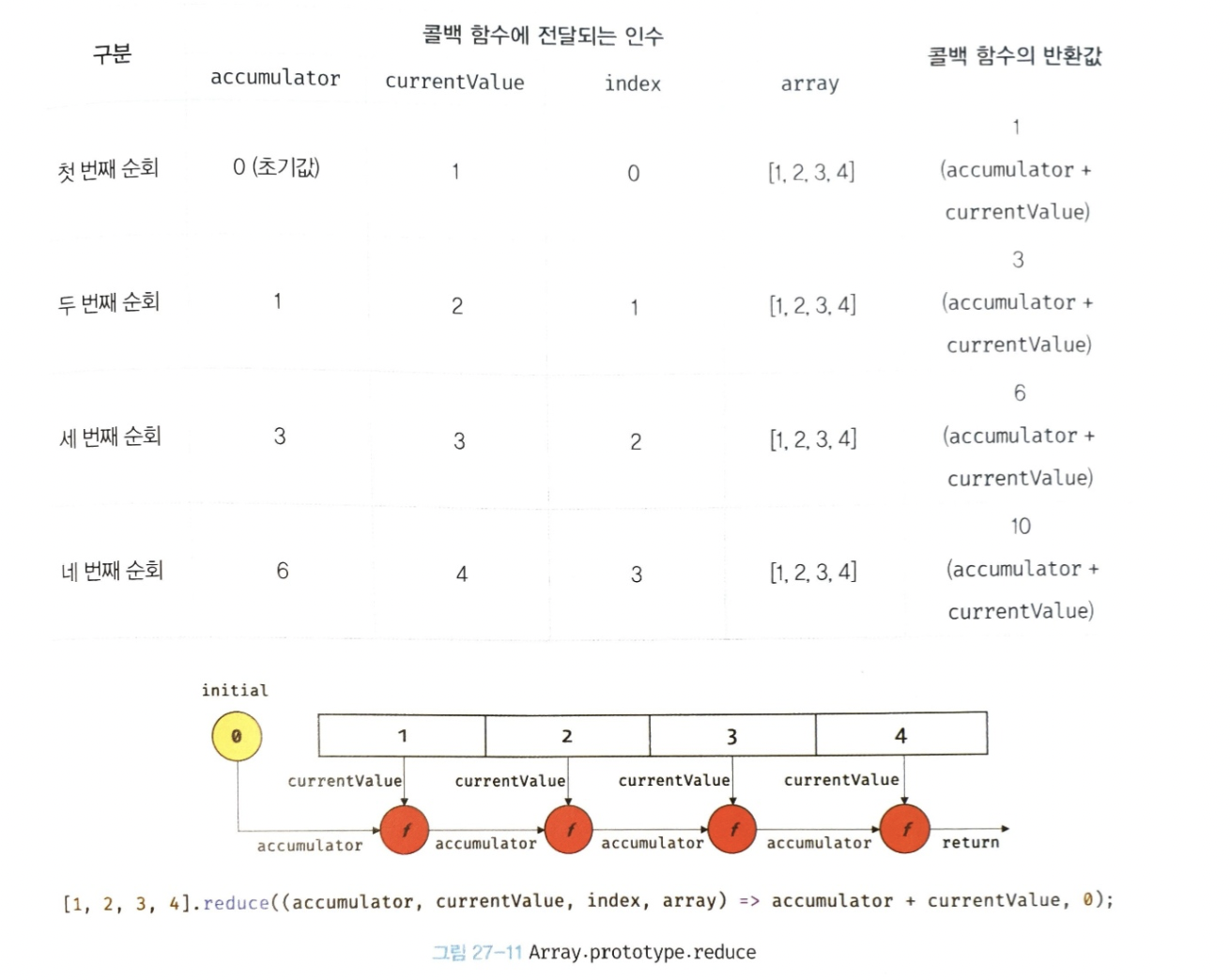
✔️ 27.9.5 Array.prototype.reduce
reduce 메서드는
- 자신을 호출한 배열을 모든 요소를 순회하며
- 인수로 전달받은 콜백 함수를 반복 호출한다.
- 그리고 콜백 함수의 반환값을 다음 순회 시에 콜백 함수의 첫 번째 인수로 전달하면서
- 콜백 함수를 호출하여 하나의 결과값을 만들어 반환한다.
- 이때 원본 배열은 변경되지 않는다.
// [1, 2, 3, 4]의 모든 요소의 누적을 구한다.
const sum = [1, 2, 3, 4].reduce((accumulator, currentValue, index, array) => accumulator + currentValue, 0);
console.log(sum); // 10reduce 메서드는
- 첫 번째 인수로 콜백 함수,
- 두 번째 인수로 초기값을 전달받는다.
reduce메서드의 콜백 함수에는- 4개의 인수
- 초기값 또는 콜백 함수 이전의 반환값,
reduce메서드를 호출한 배열의 요소값과 인덱스,reduce메서드를 호출한 배열 자체(this)가 전달된다.
- 초기값 또는 콜백 함수 이전의 반환값,
- 4개의 인수
reduce메서드를 호출할 때는 언제나 초기값을 지정하는 것이 안전하다.
✔️ 27.9.6 Array.prototype.some
some 메서드는
- 자신을 호출한 배열의 요소를 순회하면서
- 인수로 전달된 콜백 함수를 호출한다.
- 이때
some메서드는 콜백 함수의 반환값이 단 한번이라도 참이면true, 모두 거짓이면false를 반환한다.
forEach, map, filter 메서드와 마찬가지로 some 메서드의 콜백 함수는 some 메서드를 호출한 배열의 요소값과 인덱스, filter 메서드를 호출한 배열 자체, 즉 this를 순차적으로 전달받을 수 있고, 화살표 함수를 사용해 this로 사용할 객체를 전달할 수 있다.
// 배열의 요소 중에 10보다 큰 요소가 1개 이상 존재하는지 확인
[5, 10, 15].some(item => item > 10); // ➔ true
// 배열의 요소 중에 0보다 작은 요소가 1개 이상 존재하는지 확인
[5, 10, 15].some(item => item < 0); // ➔ false
// 배열의 요소 중에 'banana'가 1개 이상 존재하는지 확인
['apple', 'banana', 'mango'].some(item => item === 'banana'); // ➔ true
// some 메서드를 호출한 배열이 빈 배열인 경우 언제나 false를 반환한다.
[].some(item => item > 3); // ➔ false✔️ 27.9.7 Array.prototype.every
every 메서드는
- 자신을 호출한 배열의 요소를 순회하면서
- 인수로 전달된 콜백 함수를 호출한다.
- 이때
every메서드는 콜백 함수의 반환값이 모두 참이면true, 단 한번이라도 거짓이면false를 반환한다.
// 배열의 모든 요소가 3보다 큰지 확인
[5, 10, 15].every(item => item > 3); // ➔ true
// 배열의 모든 요소가 10보다 큰지 확인
[5, 10, 15].every(item => item > 10); // ➔ false
// every 메서드를 호출한 배열이 빈 배열인 경우 언제나 true를 반환한다.
[].every(item => item > 3); // ➔ true✔️ 27.9.8 Array.prototype.find
find 메서드는
- 자신을 호출한 배열의 요소를 순회하면서
- 인수로 전달된 콜백 함수를 호출하여 첫 번째 요소를 반환한다.
- 콜백 함수의 반환값이
true인 요소가 존재하지 않는다면undefined를 반환한다.
const users = [
{ id: 1, name: 'Lee' },
{ id: 2, name: 'Kim' },
{ id: 2, name: 'Choi' },
{ id: 3, name: 'Park' }
];
// id가 2인 첫 번째 요소를 반환한다. find 메서드는 **배열이 아니라 요소를 반환**한다.
users.find(user => user.id === 2); // ➔ {id: 2, name: 'Kim'}
// Array#filter는 배열을 반환한다.
[1, 2, 2, 3].filter(item => item === 2); // ➔ [2, 2]
// Array#find는 요소를 반환한다.
[1, 2, 2, 3].find(item => item === 2); // ➔ 2✔️ 27.9.8 Array.prototype.findIndex
findIndex 메서드는
findIndex메서드는 자신을 호출한 배열의 요소를 순회하면서- 인수로 전달된 콜백 함수를 호출하여 반환값이
true인 첫 번째 요소의 인덱스를 반환한다. - 콜백 함수의 반환값이true인 요소가 존재하지 않는다면-1을 반환한다.
const users = [
{ id: 1, name: 'Lee' },
{ id: 2, name: 'Kim' },
{ id: 2, name: 'Choi' },
{ id: 3, name: 'Park' }
];
// id가 2인 요소의 인덱스를 구한다.
users.findIndex(user => user.id === 2); // ➔ 1
// name이 'Park'인 요소의 인덱스를 구한다.
users.findIndex(user => user.name === 'Park'); // ➔ 3
// 위와 같이 프로퍼티 키와 프로퍼티 값으로 요소의 인덱스를 구하는 경우
// 다음과 같이 콜백 함수를 추상화할 수 있다.
function predicate(key, value) {
// key와 value를 기억하는 클로저를 반환
return item => item[key] === value;
}
// id가 2인 요소의 인덱스를 구한다.
users.findIndex(predicate('id', 2)); // ➔ 1
// name이 'Park'인 요소의 인덱스를 구한다.
users.findIndex(predicate('name', 'Park')); // ➔ 3✔️ 27.9.10 Array.prototype.flatMap
flatMap 메서드는
map메서드를 통해 생성된 새로운 배열을 평탄화한다.- 즉
map메서드와flat메서드를 순차적으로 실행하는 효과가 있다. - 단 1단계만 평탄화할 수 있다.
const arr = ['hello', 'world'];
// map과 flat을 순차적으로 실행
arr.map(x => x.split('')).flat();
// ➔ ['h', 'e', 'l', 'l', 'o', 'w', 'o', 'r', 'l', 'd']
// flatMap은 map을 통해 생성된 새로운 배열을 평탄화한다.
arr.flatMap(x => x.split(''));
// ➔ ['h', 'e', 'l', 'l', 'o', 'w', 'o', 'r', 'l', 'd']
const arr = ['hello', 'world'];
// flatMap은 1단계만 평탄화한다.
arr.flatMap((str, index) => [index, [str, str.length]]);
// ➔ [[0, ['hello', 5]], [1, ['world', 5]]] => [0, ['hello', 5], 1, ['world', 5]]
// 평탄화 깊이를 지정해야 하면 flatMap 메서드를 사용하지 말고 map 메서드와 flat 메서드를 각각 호출한다.
arr.map((str, index) => [index, [str, str.length]]).flat(2);
// ➔ [[0, ['hello', 5]], [1, ['world', 5]]] => [0, 'hello', 5, 1, 'world', 5