앱의 콘텐츠나 데이터 자체를 저장/보관하는 특별한 객체를 무엇이라고 하는가?
User Defaults
앱 실행 중 키-값 쌍을 지속적으로 저장하는 사용자의 기본 데이터베이스에 대한 인터페이스이다.
대용량의 데이터보다 자동로그인 여부, 아이디, 환경설정에서의 기본 설정 값과 같은 단일 데이터 등을 보관한다.
장점
- UserDefaults는 사용하기 쉽다.
- Thread-Safe 하다. CoreData와 Realm은 Thread-Safe 하지 않기 때문에 멀티 스레드 환경에서 주의를 해야한다.
단점
- 동일한 키의 값을 쉽게 재정의 할 수 있다 (키 충돌 가능성).
- UserDefaults는 암호화되지 않는다.
- Unit Test 시 UserDefault는 잘못된 값을 일으킬 수 있다.
- UserDefaults는 앱의 어느 곳에서나 전역적으로 변경 될 수 있으므로 inconsistent한 상태에서 쉽게 실행할 수 있다.
- plist에 데이터가 저장되기 때문에 앱이 삭제되면 데이터도 모두 삭제됩니다.
간단한 소규모 데이터를 쉽게 저장하고 싶을 때 UserDefaults를 사용하는 것이 좋다. 만약 데이터가 앱이 삭제되도 남아있어야 하거나, 보안이 중요하다면 UserDefaults는 절대 사용하면 안 된다.
CoreData
오프라인 사용을 위해 애플리케이션의 영구 데이터를 저장하고, 임시 데이터를 캐시하고, 단일 장치에서 앱에 실행 취소 기능을 추가한다.
-
영속성: 앱을 종료해도 지워지지 않음
Core Data는 개체를 저장소에 매핑하는 세부 정보를 추상화하여 데이터베이스를 직접 관리하지 않고도 Swift 및 Objective-C에서 데이터를 쉽게 저장할 수 있도록 한다.
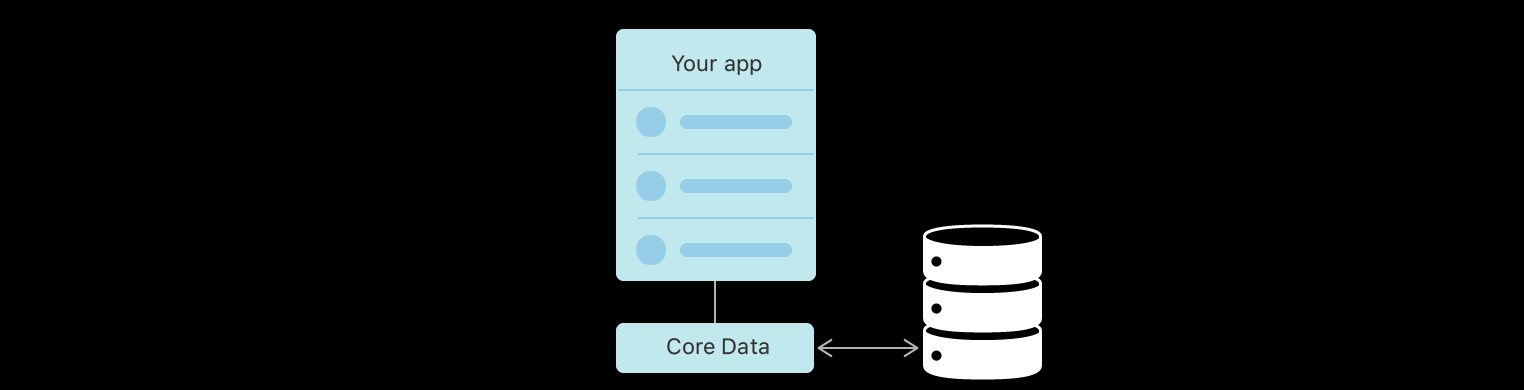
이 영속성 기능은 SQLite를 기반으로 지원하는데 일반적인 데이터베이스와는 차이가 있다.
CoreData는 객체 그래프 관리자로, 객체를 직접적으로 연결해서 관리한다.
데이터베이스는 행렬 관계를 이용해 데이터를 읽고 쓰는 반면 CoreData는 객체를 연속적으로 탐색해야 한다는 점이 차이점이다. -
변경의 실행 취소 및 다시 실행
Core Data의 실행 취소 관리자는 변경 사항을 추적하고 개별적으로, 그룹으로 또는 한 번에 모두 롤백할 수 있으므로 앱에 실행 취소 및 다시 실행 지원을 쉽게 추가할 수 있다.
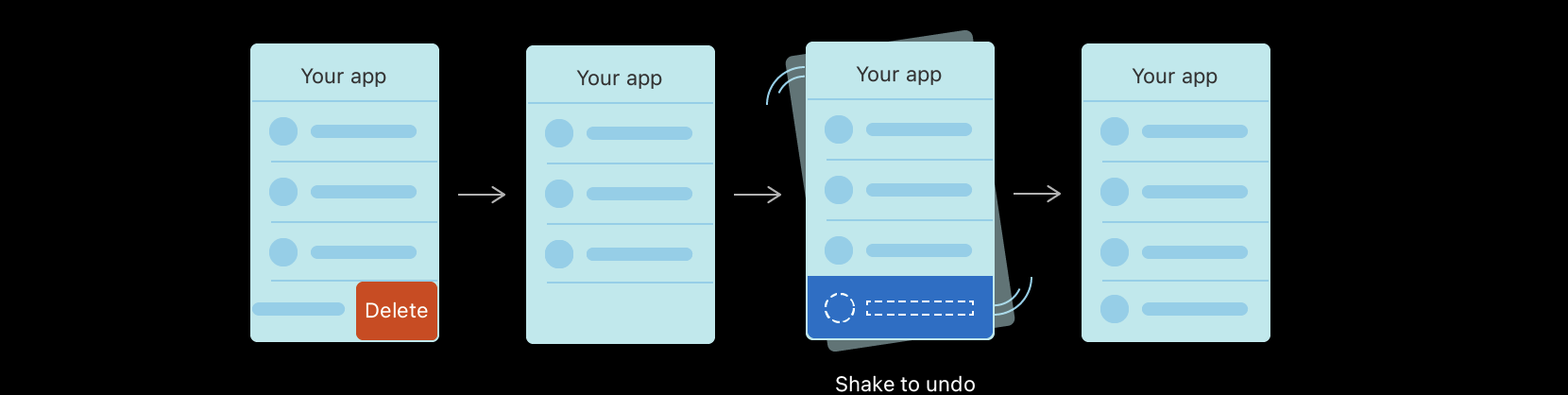
-
백그라운드 데이터 작업
백그라운드에서 JSON을 개체로 구문 분석하는 것과 같은 잠재적인 UI 차단 데이터 작업을 수행한다. 그런 다음 결과를 캐시하거나 저장하여 서버 왕복을 줄일 수 있다.
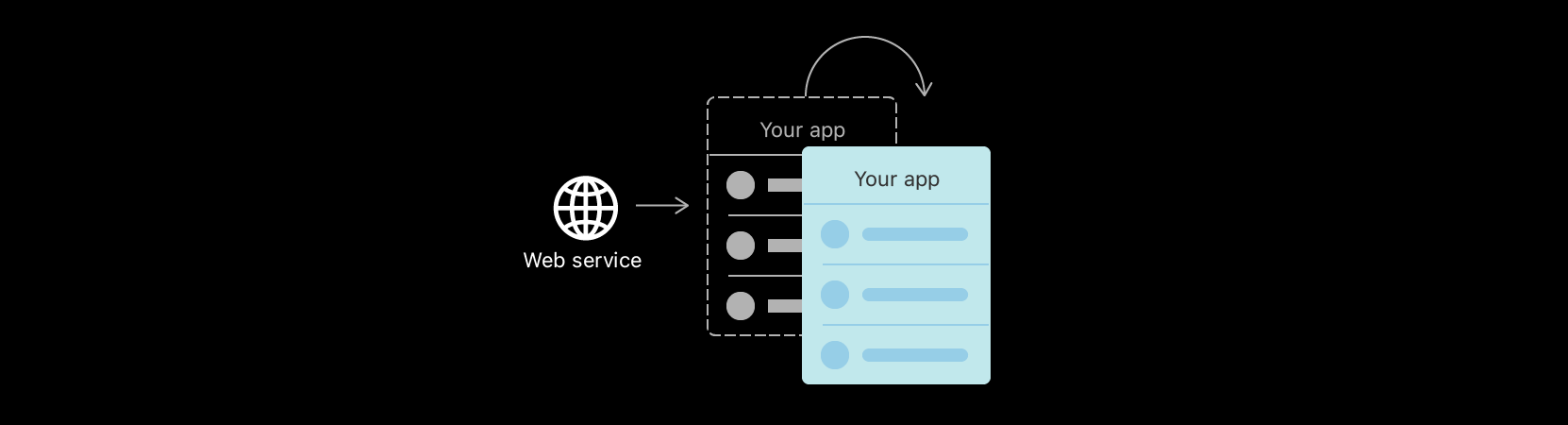
-
동기화 기능
-
버전 관리 및 마이그레이션(Migration)
Thread-Safe 하지 않아 Lock으로 동기화 처리를 해줘야 한다.
대신, 원하는 데이터가 메모리에 올릴 수 있기 때문에 대규모 데이터를 저장해도 메모리 효율이 떨어지지 않는다.
대규모 데이터를 저장해야하는 상황에서 영속성 기능을 포함한 CoreData의 다른 기능도 필요하다면 CoreData를 선택하는 것이 적절하다.
Realm
Realm(렘)은 오픈소스 데이터베이스 관리시스템(DBMS)으로 모바일 환경을 주요 타깃으로 삼은 데이터베이스이다.
iOS에서는 CoreData를 대체하는 모바일 디비로 NoSQL 데이터베이스를 지향한다.
(TMI: Realm을 인수한 몽고DB가 NoSQL의 대표주자라고 한다. NoSQL은 여러 유형의 데이터베이스를 사용하는 것으로 관계형 데이터베이스인 RDBMS와 다른 길을 지향한다고 한다.)
장점
- Realm의 가장 큰 장점은 성능이다.
Realm은 데이터 컨테이너 모델을 사용하며 데이터 객체를 Realm에 객체로 저장한다.
즉, Realm은 객체 중심의 데이터베이스이다.
따라서 ORM(Object Relational Mapping)을 통한 테이블과 객체 간의 변환이 필요 없어 빠른 속도로 쿼리를 수행할 수 있다.- 두 번째 장점은 가이드와 패치노드가 잘 관리되고 있다는 점이다.
어떤 점이 변했는지 자세히 적어두기 때문에 변화가 생겼을 때 빠르게 대처할 수 있다.
패치노트는 realm github 에서 확인할 수 있다.
Apple Doc UserDefault
Apple Doc CoreData
UserDefaults / CoreData / Realm 간단 비교
Class의 성능 향상 방법들을 나열
- 상속, 오버라이드를 사용하지 않을 경우 final 키워드 활용한다.
Swift에서는 Method Dispatch 메커니즘과 관련이 있다. 이 Dispatch는 Thread와 관련된 DispatchQueue가 아닌,
어떤 연산(operation)을 실행해야하는지 결정하도록 돕는 메커니즘이다.
Swift에서는 Static Dispatch와 Dynamic Dispatch, 두 가지의 방식이 존재한다.
Static Dispatch는 값, 참조타입 모두 지원되고, Dynamic Dispatch는 참조타입에서만 지원된다.
Dynamic Dispatch를 위해서는 상속이 필요한데 값 타입은 상속을 지원하지 않기 때문이다.
두 Dispatch의 차이를 쉽게 말해 호출할 함수를 '컴파일 타임'에 결정하냐, '런 타임'에 결정하냐 차이이다.
즉, struct는 Static Dispatch, class의 경우 Dynamic Dispatch를 사용하게 된다.
Static Dispatch
호출될 함수를 '컴파일 타임'에 결정하고 런타임 때 실행하는 매커니즘이다.
Dynamic Dispatch
'런 타임'에 호출될 함수를 결정한다.
이 때문에 Swift에서는 클래스마다 함수 포인터들의 배열인 vTable(Virtual Dispatch Table)이라는 것을 유지한다.
하위 클래스가 메서드를 호출할 때, 이 vTabel 을 참조하여 실제 호출할 함수를 결정한다.
더 자세하게 말하자면, '런 타임' 시점에 클래스의 vTable을 탐색하고 실제 불릴 함수 포인터를 찾아 실행하게 된다.
이 과정들이 '런 타임'에 일어나기 때문에 성능상 손해를 보게 된다.
그렇다면 Dynamic Dispatch는 언제 사용할까?
Reference Type, Value Type, Protocol
- Reference Type의 Class는 상속의 가능성이 있고 서브 클래스에서 함수를 호출(오버라이딩)할 수 있기 때문에 Dynamic Dispatch를 사용한다. (단, extension에 정의된 메서드는 오버라이딩 불가, @objc 키워드 추가 시 가능)
- Value Type은 값 타입만 취급하기 때문에 사용하지 않는다.
- Protocol의 경우 extension을 이용하여 메서드를 정의하고, struct라도 이 프로토콜을 채택하여 메서드를 오버라이딩할 경우 Dynamic Dispatch를 사용하게 된다.
이 경우 예외가 있다. 프로토콜 인터페이스에 메서드를 정의할 경우 인스턴스의 메서드를 protocol을 참조하게 되어서 Dynamic Dispatch를 사용하게 된다. 단, protocol 인터페이스에 메서드가 없고 extension 에서만 정의할 경우 Static Dispatch를 이용하게 된다.
? 그러면 프로토콜 인터페이스에 명시를 안하고 extension에 메서드 정의하는 게 이득 아닌가?
따라서 final 키워드를 붙여줄 경우 '런 타임'이 아닌 '컴파일 타임'에 함수를 결정하게 된다.
vTable이란?
동적 디스패치(또는 런타임 메소드 바인딩)를 지원하기 위해 프로그래밍 언어에서 사용되는 메커니즘이다.
- private 키워드 활용
private을 사용하면 클래스의 선언부 외부에서는 해당 메서드나 프로퍼티를 볼 수조차 없다. 이런 메서드나 프로퍼티들은 컴파일러가 쉽게 Static Dispatch를 결정하도록 해준다.
- WMO(Whole Module Optimization) 사용
모듈 전체를 하나의 덩어리로 컴파일 하여, internal level 에 대해서 오버라이딩이 되는지 안 되는지를 추론 할 수있게 되고 오버라이딩이 되지 않을 경우, 내부적으로 final을 붙힌다.
즉, Swift는 기본적으로 컴파일을 할 때 모듈 내의 파일들을 하나 하나씩 컴파일 하는데,
하나의 모듈을 컴파일 할 때 파일 하나하나씩이 아니라, 모듈 전체를 확인하며 컴파일 하는 것이다.
단, 이것은 Swift 클래스의 기본 접근 제어자가 internal이기 때문에 가능한 것이다.
만약 public, open 키워드를 붙일 경우, 외부 모듈에서도 접근할 수 있기 때문에 WMO를 사용하여도 Dynamic Dispatch로 동작한다고 한다.
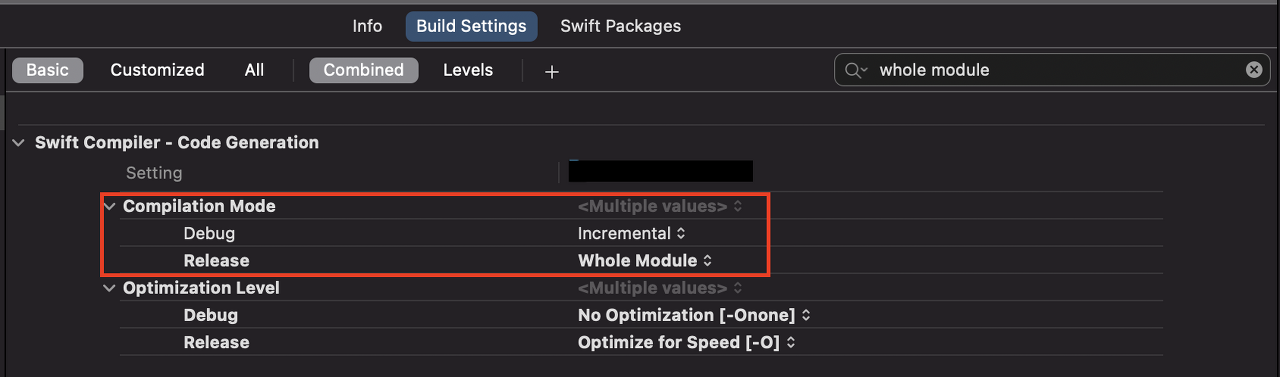
WMO 사용법
Xcode -> Build Settings -> Swift Compiler -> Compilation Mode -> Release = Whole Module
Xocde 8부터는 자동으로 켜져있다고 한다.
Class의 성능 향상 방법
Method Dispatch babbab2
COW(Copy On Write)는 어떤 방식으로 동작하는지 설명하시오.
COW
: 데이터 복사 시 실제로 값을 복사하지 않고, 동일한 값을 참조하다가 데이터 변경이 발생될 시에 복사해 값을 변경하는 기법이다.
값을 복사할 당시에는 같은 주소를 가리키다가 복사된 인스턴스의 데이터가 변경될 때 주소가 변경된다.
따라서 처음 값을 변경할 경우에 약간의 오버헤드가 발생된다. 그에 비해 2번째 변경 이후로는 오버헤드가 발생되지 않는다.
