
OUTER JOIN
데이터 누락 확인, 선택적인 관련 데이터 검색, 존재하지 않는 값에 대한 기본값처리, 다양한 조인 유형 적용등의 이유로 사용
- LEFT, RIGHT, FULL
- 어떤 테이블을 기준으로 잡느냐에 따라 추출 데이터의 값이 다르기 때문에 데이터 최적화를 이루기 위해 기준점이 되는 테이블을 잘 잡아야된다.
LEFT
- FROM [테이블A] LEFT JOIN [테이블B]
- A테이블 기준으로 B테이블 값을 추출한다
SELECT e.last_name, e.department_id, d.department_name
FROM employees e
LEFT OUTER JOIN departments d
ON d.department_id = e.department_id;RIGHT
- FROM [테이블A] RIGHT JOIN [테이블B]
- B테이블 기준으로 A테이블 값을 추출한다
SELECT e.last_name, e.department_id, d.department_name
FROM employees e
RIGHT OUTER JOIN departments d
ON d.department_id = e.department_id; FULL
CROSS JOIN
SELECT e.last_name, d.department_name
FROM employees e
CROSS JOIN departments d;
SELECT COUNT(*)
FROM ( SELECT last_name, department_name
FROM employees
CROSS JOIN departments); SELF JOIN + || 용한 문자열형태 출력
SELECT e1.last_name, e1.manager_id, e2.employee_id, e2.last_name
FROM employees e1, employees e2
WHERE e1.manager_id = e2.employee_id;
SELECT e1.last_name || ' works for ' || e2.last_name as "사원명 works for 매니저명"
FROM employees e1, employees e2
WHERE e1.manager_id = e2.employee_id;집합
-
UNION, UNION ALL, INTERSECT, EXCEPT(MINUS)
-
UNION
- 중복을 제거한 유일한 값을 가진 행이 출력
- 여러 개의 SQL문에 대한 합집합
- 중복을 제거하기 위해 정렬하고 제거하는 과정에서 연산이 필요하기에 잘 사용X
-
UNION ALL
- 여러 개의 SQL문에 대한 합집합
- 중복된 행도 출력
-
INTERSECT
- 여러 개의 SQL문에 대한 교집합
- (=연결된 두 개의 쿼리문에서 동일하게 존재하는 데이터만 조회한다는 의미)
- 중복을 제거하고 1개의 행으로 출력
- 연결된 쿼리문은 칼럼 개수와 데이터 유형이 동일해야 오류 발생 X
-
EXCEPT (MINUS)
- 위의 SQL 문 집합에서 아래 SQL문 집합을 뺀 것
- 중복이 제거된 상태로 출력
-
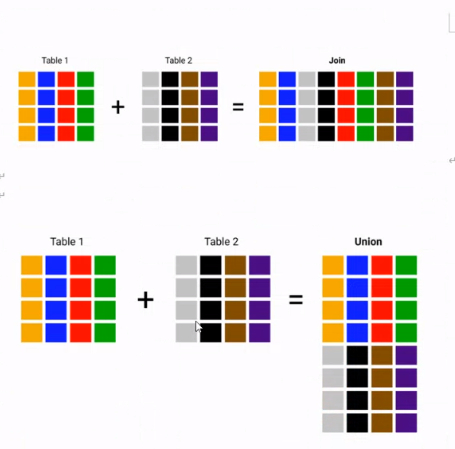
UNION과 JOIN 비교
-
공통점
- 하나 이상의 테이블에서 특정한 컬럼을 검색할 때 사용
-
차이점
- JOIN : WHERE 조건으로 두 개 이상의 테이블에서 원하는 컬럼을 선택하여 조회
- UNION : 두 개 이상의 SELECT 문을 사용하여 그 검색 결과 합침
UNION
UNION ALL
SELECT employee_id, job_id
FROM employees
UNION ALL
SELECT employee_id, job_id
FROM job_history;INTERSECT
- 교집합
SELECT employee_id, job_id
FROM employees e
INTERSECT
SELECT employee_id, job_id
FROM job_history j;MINUS
- 차집합
SELECT employee_id, job_id
FROM employees e
MINUS
SELECT employee_id, job_id
FROM job_history j;SQL PARSING(분석)
Step1. SQL 분석
Step2. SQL 실행
Step3. SQL 실행 (SELECT인 경우)
- STEP1. SQL 분석
- 목적 : SQL의 실행 방법을 나타내는 실행 계획을 수립
- 분석이 필요한 이유
- 실행 전에 문법적인 에러를 검출할 방법 존재X
- 사용해야 하는 테이블/칼럼의 존재 여부도 확인 불가
- 데이터를 어떻게 가져오는지 지정 불가
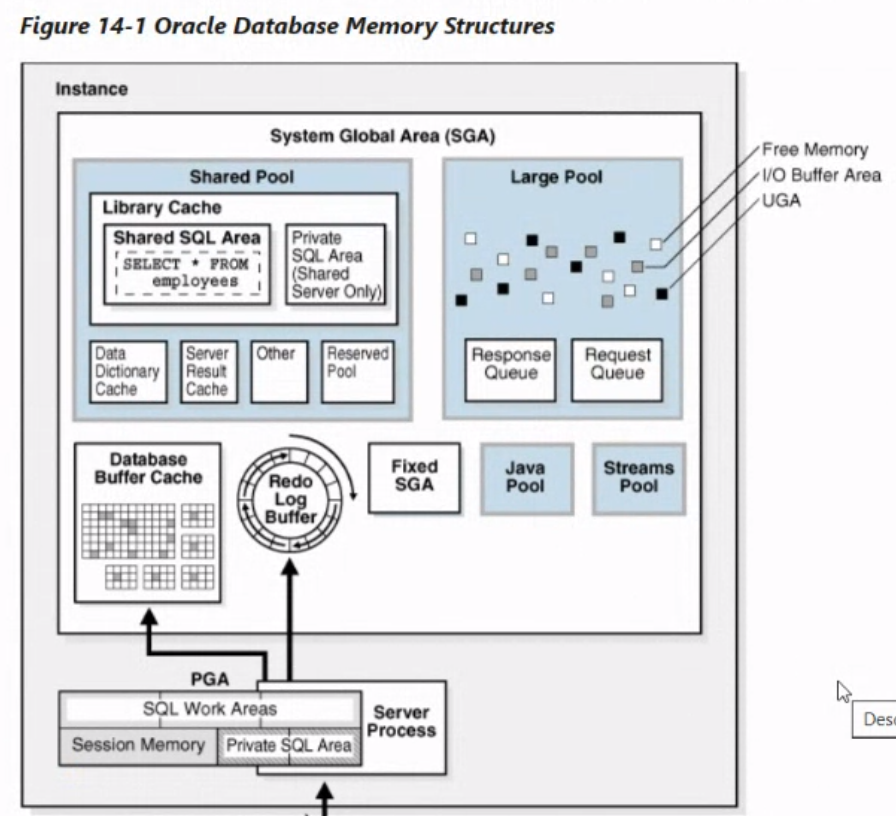
- SOFT PARSING
- SHARED POOL를 확인하고 존재한다면, SOFT PARSE 이루어져, 그대로 가져온 SQL문을 실행한다.
- 캐시 메모리를 확인 하는 것
- HARD PARSING
- SHARED POOL를 확인하고 존재X라면, 바로 실행하지않고, SQL검증을 거치고, 실행 계획을 생성한 뒤 실행한다.
- SQL 검증 : SYNTAX, Semantic 확인
- 실행계획 생성 : SQL를 어떻게 생성할 것인지 단계별로 설계
- Optimizer(옵티마이저) : 다양한 방법으로 최적의 실행방법을 구상해서 실행 시켜주는 엔진
- SHARED POOL를 확인하고 존재X라면, 바로 실행하지않고, SQL검증을 거치고, 실행 계획을 생성한 뒤 실행한다.
TABLE 생성하기
VM 환경에 파일 보내기
scp 파일 user명@localhost(IP): /경로
cmd
scp scott.sql oracle@192.168.56.114:/oracle파일 내용 변경
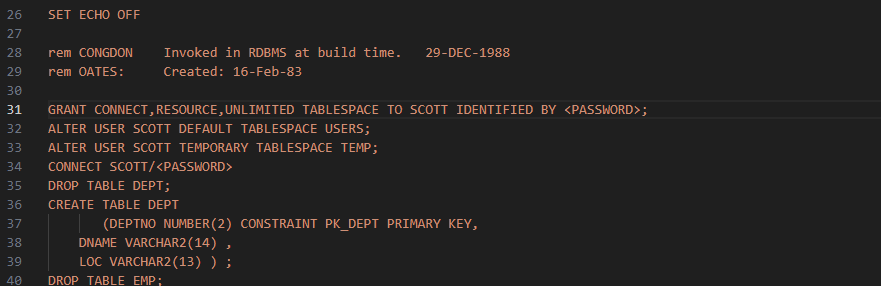
권한주기
관련 파일 위치에서 SQL로 접속해서 부여해야 된다.
<VM환경>
SQL> Show User
SQL> USER is "SYS"
grant plustrace to scott;
grant dba to scott;테이블 생성
권한이 부여가 된 USER로 로그인
SQL> CREATE TABLE EMP0 AS SELECT * FROM EMP;
SQL> CREATE TABLE EMP1 AS SELECT * FROM EMP;
SQL> INSERT INTO EMP1 SELECT * FROM EMP1;
SQL> UPDATE EMP1 SET EMPNO = ROWNUM; (중복 제거)
SQL> COMMIT; (DB에 올리기)
SQL> SELECT * FROM EMP1; ( 확인 )SOFT PARSING 확인
SQL> execute dbms_stats.gather_schema_stats('scott');
SQL> set autotrace on explain (자동으로 기록을 남기는 explain를 킨다)
SQL> SELECT sql_text FROM v$sql
WHERE sql_text='SELECT * FROM emp0';
SQL> SELECT * FROM emp0
SQL> ALTER SYSTEM FLUSH SHARED_POOL; (기록 제거)
SQL> set autotrace off ( 기록 남기는 시스템 종료 )
- 아무것도 없을때

- 데이터가 남았을때


This is my study archive