
📑 Paper
Jaegle, A., et al., "Perceiver io: a general architecture for structured inputs & outputs," Proc. of the 10th International Conference on Learning Representations (ICLR 2022), Online, 2022.
✨ Contribution 정리
1. General-purpose architecture Perceiver IO를 제안
- 다양한 modality의 input과 output
- Latent network로 인해, complexity가 input과 output의 크기에 선형적임
0. Introduction
많은 연구에서는 single task의 input과 output을 처리하기 위해 맞춤형 시스템을 구축하는 데 중점을 둠
- input/output이 다양해지면 complexity가 급격히 증가
(예시) 주어진 입력이 이미지고, 출력이 자연어라면 이미지를 처리하는 모델과 언어 모델을 두어 따로 처리 - 각 task의 input/output 구조는 데이터 처리 방식에 제약을 가하기 때문에, 새로운 설정에 적용하는 것이 어려움
본 연구에서는, 임의의 task들에 대하여 임의의 정보를 쉽게 통합·변환하기 위한 General-purpose architecture를 제안
1.1 Perceiver
네트워크 구조의 수정없이 다양한 modality의 input을 다룰 수 있는 architecture
asymmetric attention mechanism을 통해 input을 반복적으로 걸러내기 때문에 매우 큰 input을 다룰 수 있음

1) The Perceiver architecture
아래 2개의 모듈로 이루어져 있다.
① A Cross-attention module
latent array 와 byte array(pixel array) 를 latent array로 매핑
→ 고차원의 byte array를 저차원의 attention bottleneck에 사영
Attention bottleneck
은 보다 매우 작은 값으로,
latent array이 Attention 연산의 Query로 주어질 때 결과 값의 크기가 상당히 작아지기 때문에 attention bottleneck이라 부르는 것으로 해석했다.
② A Transformer tower
latent array를 latent array로 매핑
→ deep Transformer로 processing
2) Complexity
cross-attention module은 이고,
latent Transformer은 latent array를 통해 연산을 수행하기 때문에 가 됨
→
3) 한계
classification과 같은 간단한 output space만 다룰 수 있음
1.2 Perceiver IO
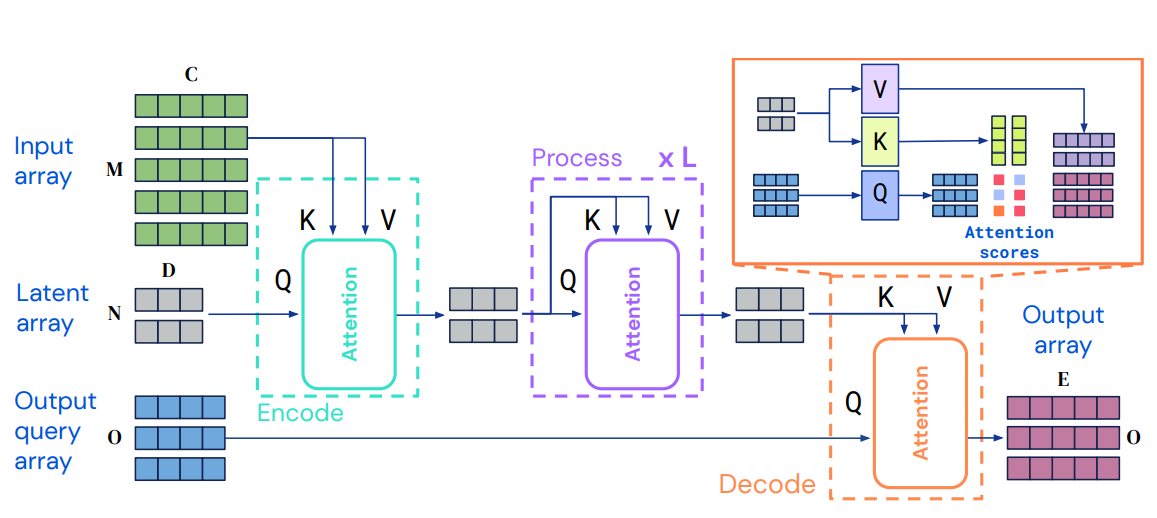
1) A Fully Attentional Read-Process-Write Architecture
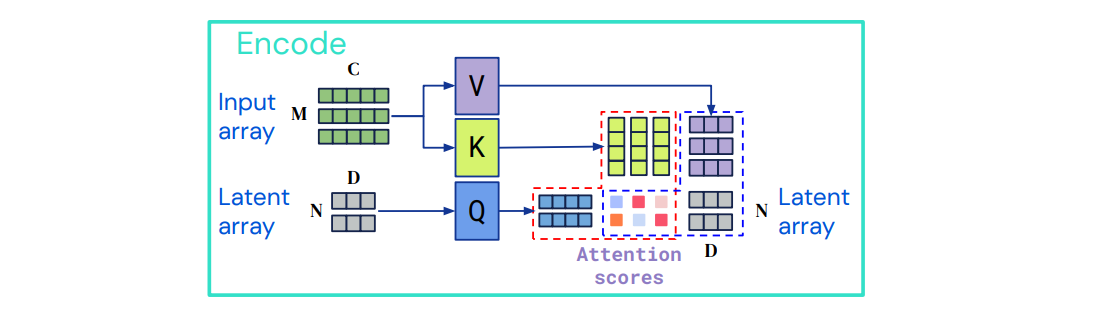
① Encoder (Encode)
- input 을 latent space의 로 매핑하는 단계
- cross attention 수행
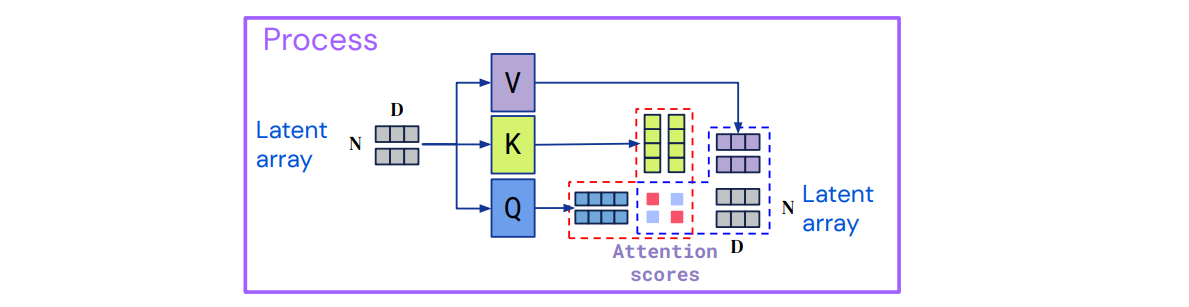
② latent Transformer (Process)
- L개의 processing layer를 거쳐 latent representation을 정제하는 단계
- layer 내에서는 self-attention 연산을 수행하며 input index dimension(=element 개수)을 보존함
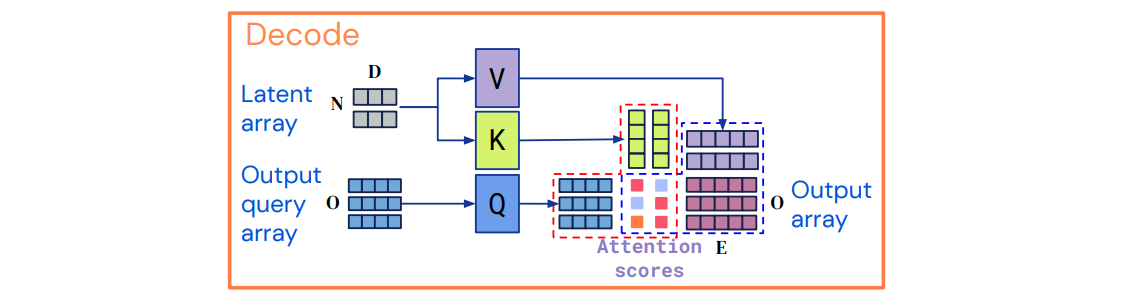
③ Decoder (Decode)
- latent representation 을 output 로 매핑하는 단계
- cross attention 수행
Output Query Array
각 output에 대한 적절한 정보를 포함하는 query array
query arrary는 output과 element 수(index dimension)가 동일해야 한다이러한 query는 직접 디자인하거나 학습된 임베딩 또는 간단한 함수 등이 될 수 있다.
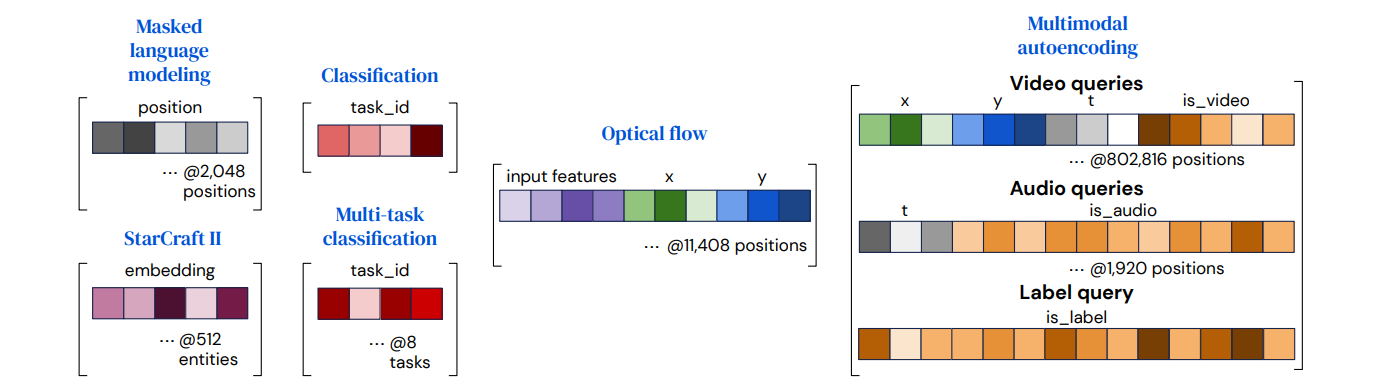
각 Task에 대한 Output Query Array는 어떻게 구성할까
vector들을 결합 (또는 concatenating, adding)함으로써 원하는 output과 관련된 정보를 포함하도록 구성
Simple output (e.g. Classificaiton)
모든 example에 대해 재사용될 수 있으며, scratch로부터 학습될 수 있다.Output with spatial or sequence structure
attention 연산으로 하여금 한 position이 다른 position과 구분될 수 있도록 positional encoding (학습된 positional encoding 또는 Fourier feature)을 포함Output with a multi-task or multimodal structure
query를 각 task (또는 modality)에 대하여 학습시켜 사용함
→ network가 각각의 task (또는 modality)를 구분할 수 있도록 함Other structures
output은 query 위치의 input content를 반영해야 함
(예시) flow의 경우, 쿼리되는 시점에 input feature를 포함하는 것이 좋음
(예시) StarCraft 2의 경우, unit information을 사용하여 model output을 해당 unit과 연결함
2) Perceiver와 다른 점
Perceiver IO는 특정 output의 semantics를 담은 output query를 두어 latent array와 cross-attention을 수행함으로써 output array를 생성함
→ 임의의 크기 및 구조를 가지는 다양한 output을 생성할 수 있음
(= output의 크기와 구조에 제한받지 않음)
3) Complexity
Encoder는 이고, latent Transformer는 , Decoder는 이다.
→.
latent attention은 input과 output의 크기에 독립적이기 때문에,
complexity가 input과 output의 크기에 선형적임
, , 은 각각 input, latent, output array의 index dimension, 는 feature size
Complexity of QKV attention
이고 일 때, 임
2. 실험
2.1 Language
Transformer는 input 길이에 대해 quadratic complexity를 가지기 때문에 tokenization 없이 사용하기 어렵다.
tokenization은 유지 보수하기 힘들며, 기술적인 overhead 및 불필요한 complexity를 일으킨다 (Bostrom & Durrett, 2020; Clark et al., 2022)
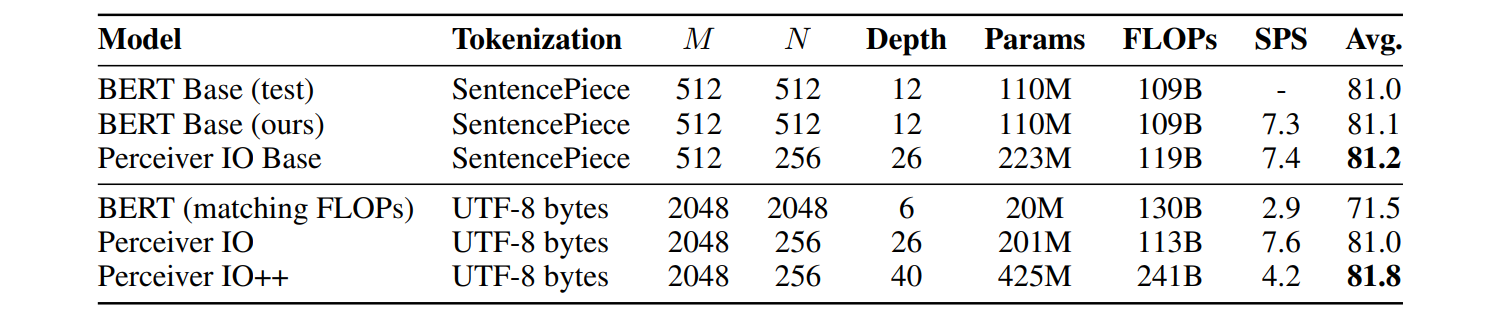
이 실험에서는 파라미터의 수 대신 FLOPs(FLoating point OPerations)를 비교했는데,
FLOPs가 파라미터의 수보다 훈련 시간과 직접적인 관계가 있기 때문이라고 한다.
-
Tokenization이 제외됐을 때 Perceiver IO가 byte-level BERT를 능가함
Tokenization이 제외됨으로써 더 긴 시퀀스를 다룰 수 있음
fixed, handcrafted vocabulary를 사용하지 않고 raw byte input을 사용함 -
SentencePiece tokenization을 사용했을 때, Perceiver IO가 BERT를 능가함
Perceiver IO는 더 작은 latent size를 가짐으로써 더 깊은 network를 학습할 수 있음 -
bytes Perceiver IO가 tokenization을 사용한 BERT와 비슷함
handcrafted tokenizer에 기반한 강력한 baseline에 견줄만함
❶ (참고) byte-level Perceiver IO vs concurrent CANINE (Clark et al.(2022))
-
Clark et al.(2022)은 Unicode codepoint를 hash embedding에 매핑하는 반면, byte-level Perceiver IO는 raw UTF-8 byte를 직접 임베딩함
-
upsampling 전략의 차이로 인해 Clark et al.(2022)는 input 길이에 대해 quadratic complexity를 가지게 됨
❷ Multitask Perceiver IO
multitask query를 사용하고, GLUE의 8가지 task에 대해 한꺼번에 finetuning 수행 (UTF-8 byte model 사용)
BERT의 [CLS]와 같은 역할을 하는 token 추가했을 때,
Shared input token : 모든 task에 동일한 token 사용
Task-specific input tokens: 각 task마다 다른 token을 사용
-
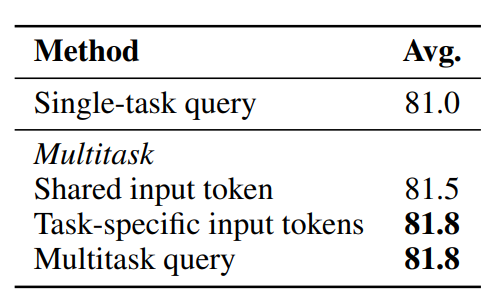
multitask가 single task보다 높은 성능을 보임
-
token을 공유한 것(Shared input token)보다 task-specific token을 사용하는 것(Task-specific input tokens)이 더 높은 성능을 보임
-
Multitask query가 task-specific token을 사용하는 것과 일치함
Multitask query는 [CLS] token에 의존하지 않음으로써 input으로부터 output을 얻을 수 있기 때문에 더 generic한 방법임
2.2 Optical flow
Optical flow : 같은 scene의 두 개의 이미지가 주어졌을 때 (동영상의 연속된 두 개의 frame 등), 첫 이미지에서 각 pixel의 이동을 추정.
❶ Optical flow가 어려운 이유
- Optical flow는 대응 관계를 찾는 데 의존함
단일 프레임은 flow에 대한 정보를 제공하지 않고, 매우 다른 이미지가 동일한 flow를 생성할 수 있음 - Flow는 annotation 하기 어려움
- 사실적인 이미지와 높은 퀄리티의 ground-truth를 가진 몇몇의 데이터셋은 작고 편향됨
따라서, Optical flow을 위한 algorithm은 아래의 단계를 완수해야 한다.
- algorithm은 point 간의 일치함을 찾아야 한다
- point 간 relative offset을 계산한다
- 대응할 texture가 없는 이미지 부분을 포함한 넓은 영역에 걸쳐 flow를 전파한다
❷ Optical flow를 위한 Architecture
PWCNet, RAFT, GMA는 out-of-domain data일지라도, 각 단계가 정확히 완수되었는지 보장하기 위해 explicit machinery를 사용
대응 관계를 찾기 위해 이미지 전반에 걸쳐 시공간 이웃 내에서 feature를 명시적으로 비교함 → 속도 느림
❸ Perceiver IO on Flow
두 frame을 channel dimension에 따라 연결(concatenating)한 후,
각 pixel 주변의 3 by 3 patch를 추출한다 ( values)
이에 positional encoding을 추가한 후, Perceiver IO 적용
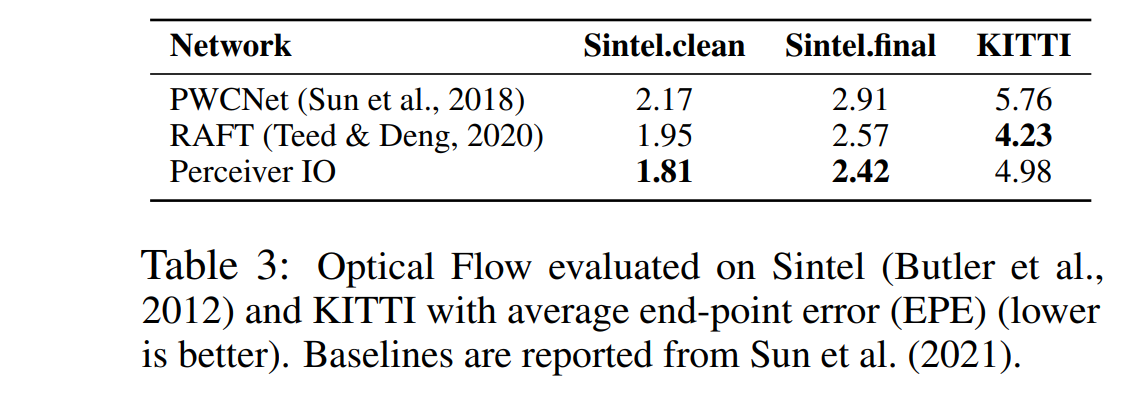
- Sintel에 대해 Perceiver IO가 가장 성능이 좋음
Sintel.final에 대해선 SOTA 달성
2.3 Multimodal autoencoding
Kinetics-700-2020 dataset을 사용하였으며 audio, video, class label으로 구성되어 있음
❶ Traditional autoencoding
convolutional encoder-decoder와 같은 전통적인 모델은 각 modality를 결합하는 방식이 명확히지 않음
~ data dimention이 매우 다르기 때문
~ video-3D, raw audio-1D, class label-0D
❷ Perceiver IO를 이용한 Multimodal autoencoding
- 각 input에 modality-specific embedding으로 패딩 수행
- 2D input array로 직렬화(serialize)
- modality embedding과 positional encoding을 포함하는 query들을 사용하여 output 생성
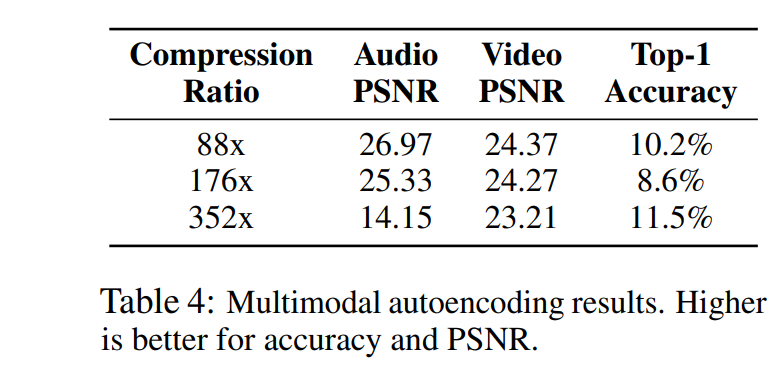
-
video,audio PSNR과 classification 정확도 간의 trade-off 존재
-
class loss에 가중을 두면 video PSNR 20.7으로 유지하면서 top-1 accuracy 45%까지 오름
~ Perceiver IO는 각 modality들을 매우 다른 property로 표현할 수 있음
