
📄Paper : Multitask Prompted Training Enables Zero-Shot Task Generalization
✨ Contribution 정리
1. Massively Multitask prompted training을 통해 unseen task에 대한 Zero-Shot 성능을 개선한 T0 제안
2. Prompt Robustness를 증명하기 위한 Ablation Study 제공
3. 본 연구에 사용한 Prompt 및 Template 공개
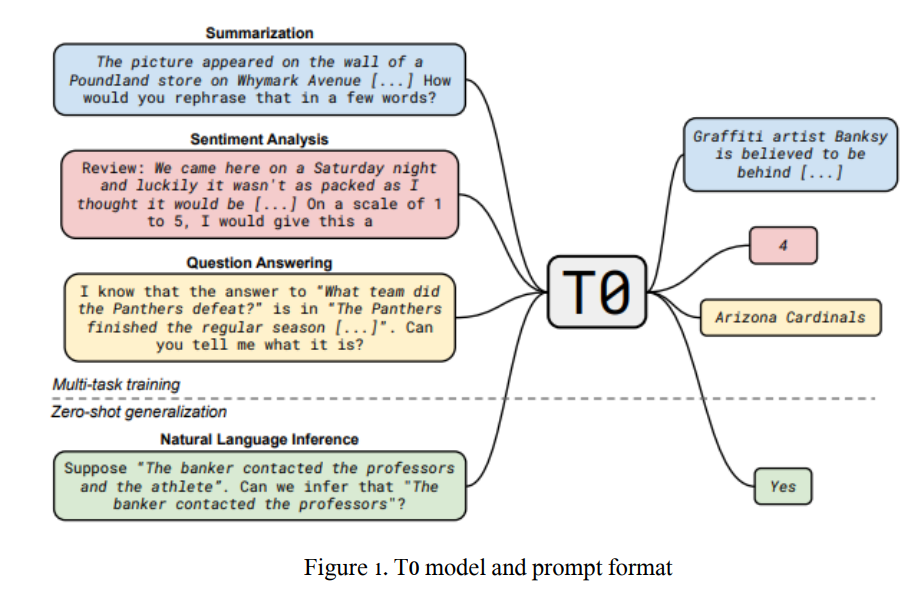
T0 (T-Zero)
여러 unseen task에 대한 zero-shot 성능을 일반화하기 위한 모델
T0는 Transformer encoder-decoder 구조의 모델로,
Classification, Question Answering, Translation 등 여러 task들을 모두 text-to-text task로 접근하는 T5에 기반한 모델이다.
T5 (Text-to-Text Transfer Transformer)
: A huge version of the original encoder-decoder Transformer
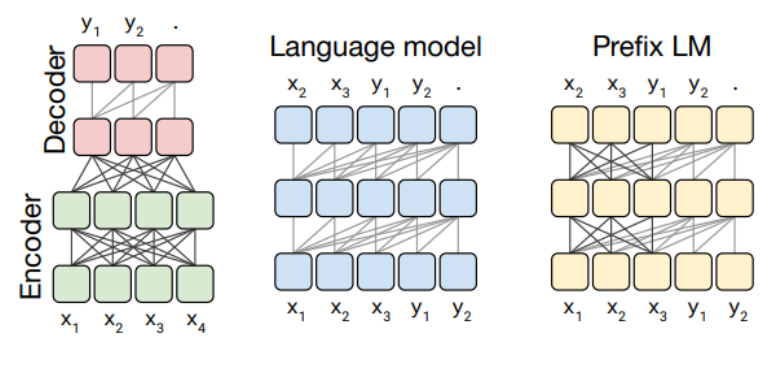
T0 Architecture
본 연구에서는 LM-adapted T5를 사용
prefix가 주어지면, 모델은 주어진 prefix에 대해 정답을 생성하도록 학습

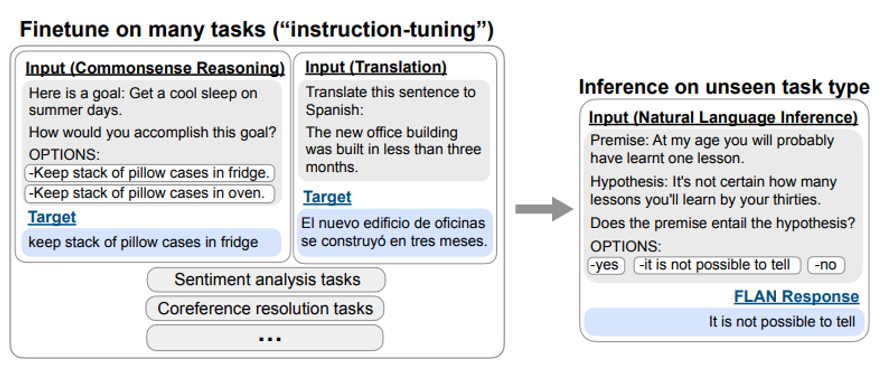
T0 vs FLAN
Google의 FLAN
multitask prompted training을 수행함으로써 zero-shot generalization performance를 개선한 연구
-
Model Architecture
FLAN은 Decoder-only language model인 반면, T0는 Encoder-Decoder Architecture를 가진다. -
Experiment 구성
FLAN은 single heldout task에 대한 성능을 보고하였지만,
T0는 Training task와 Heldout task를 고정하여, Multiple heldout task에 대한 성능을 보고했다.
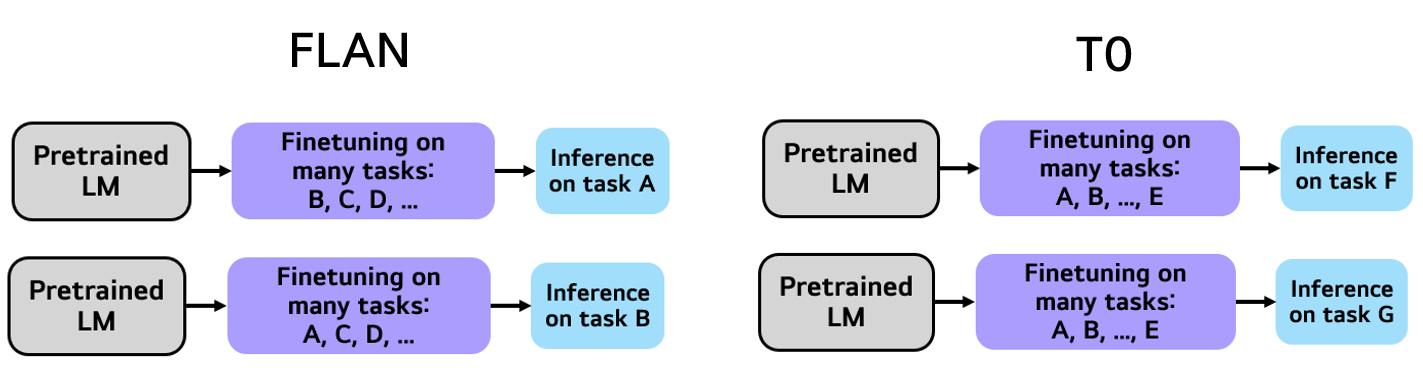
- Model Scale
8B 크기 이하의 FLAN은 instruction tuning 이전보다 더 낮은 성능을 보이는 반면,
T0는 3B 크기에서도 T5+LM (Baseline)을 능가하는 성능을 보임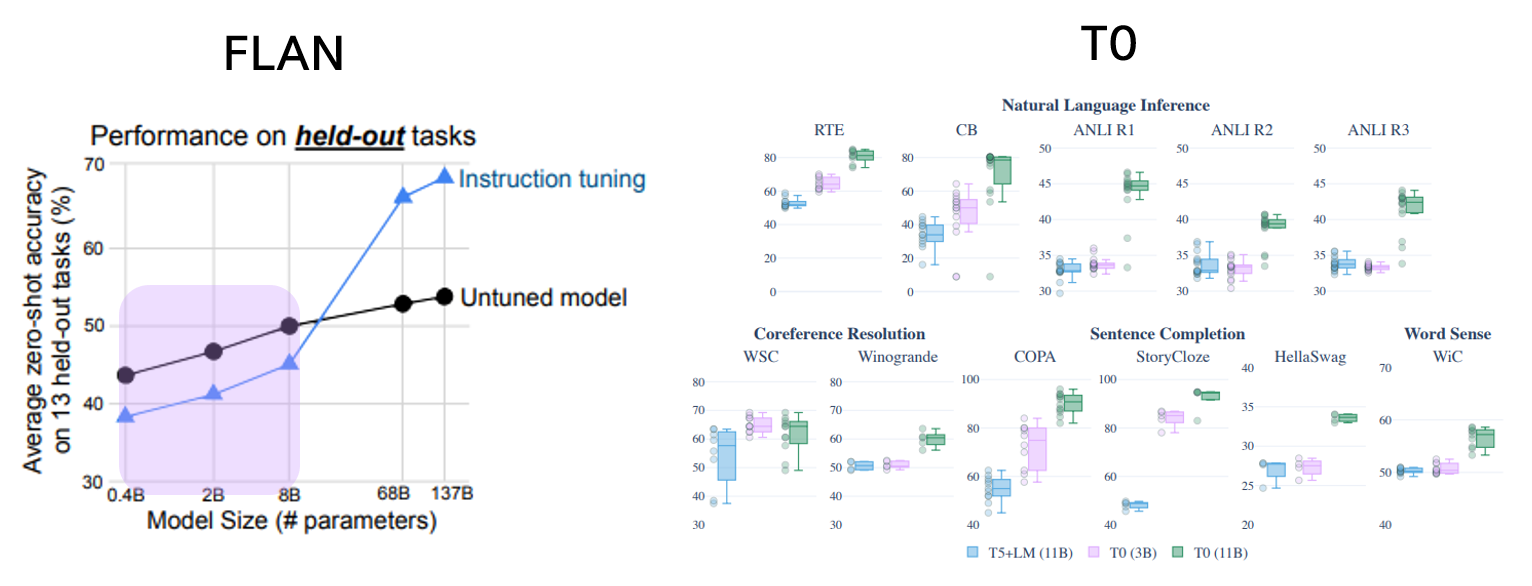
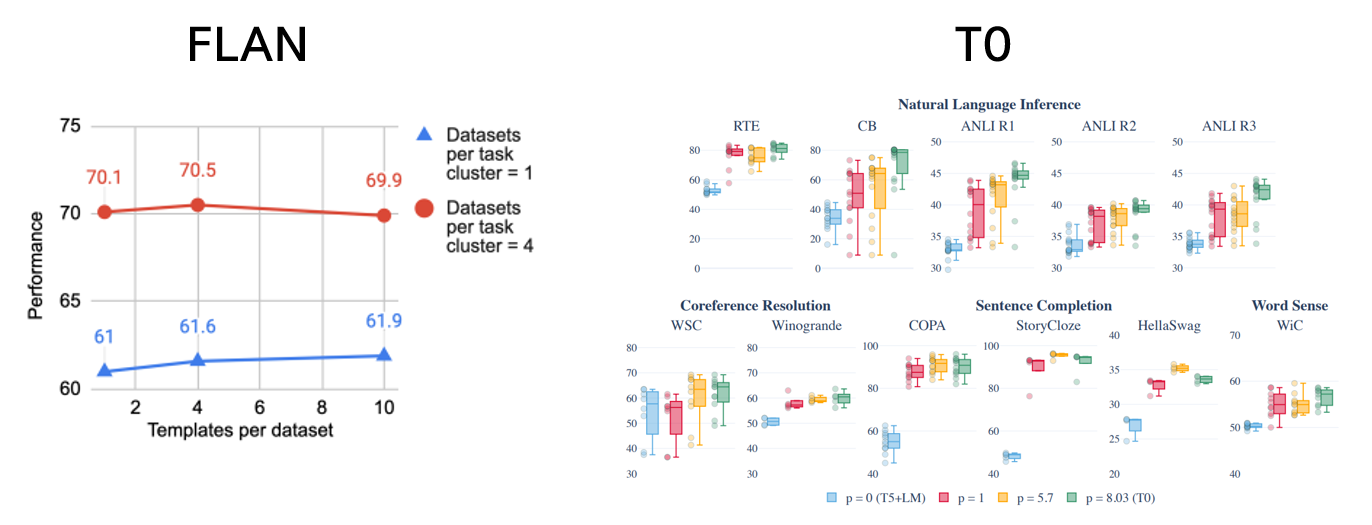
- Prompt
FLAN은 한 줄 이내의 문장으로 이루어진 prompt 사용,
Prompt의 개수가 증가했을 때, 성능에 큰 차이가 없었다.
T0는 36명의 contributor마다 각자의 방식으로 자유롭게 template을 구성했으며,
prompt의 개수가 증가할 때, 성능이 개선되는 모습을 보였다.
🌱 세미나 자료
-
딥러닝논문읽기모임 발표영상 (Youtube)
-
세미나 자료


열심히 배우는 내가 되자
T0에 대한 글 잘 읽었습니다.
몇가지 공유드리고 싶은 말씀 전달합니다.
FLAN(아마 Finetuned Language Models are Zero-Shot Learners)에 대해 언급하신 부분에서 multitask prompted training이라고 표현하셨는데, FLAN에서 제시된 개념은 Instruction Tuning으로 prompt tuning과는 다른 실제 gradient update가 있는 finetuning입니다. 또, 후속연구(Scaling Instruction-Finetuned Language Models)에서는 decoer-only인 LaMDA기반 뿐 아니라 encoder-decoder 구조인T5기반 모델에 대해서도 연구가 있었습니다.
감사합니다.