[Salesforce] Data Loader and Data Import Wizard

Salesforce의 Lightning 플랫폼에서 앱을 구축하고 유지 관리할 때, 사용자 생성 데이터를 외부 데이터 관리 시스템이나 스프레드시트로부터 Salesforce로 가져오거나 (Import), 혹은 Salesforce에서 데이터를 내보내야 (Export) 하는 상황이 발생할 수 있습니다.
이러한 데이터 이전 작업은 신규 사용자, 연락처, 리드 등의 데이터를 Salesforce 내부 시스템으로 통합하고자 할 때 필요합니다.
Data Import in Salesforce

Salesforce 제공 도구를 통해 데이터를 Salesforce에 쉽게 가져올 수 있습니다. 지원되는 데이터 소스에는 쉼표로 구분된 텍스트 형식(.csv)으로 데이터를 저장할 수 있는 모든 프로그램이 포함됩니다. Salesforce에서 데이터를 Import할때 가능한 3가지 옵션은 다음과 같습니다:
-
Insert(삽입): Salesforce에 새로운 레코드를 생성합니다. 이 작업은 주로 새 데이터 세트를 Salesforce 조직에 추가할 때 사용됩니다.
-
Update(업데이트): 레코드 ID 또는 외부 ID를 활용하여 Salesforce의 기존 레코드를 수정합니다. 이 작업은 이미 Salesforce에 존재하는 레코드의 정보를 최신 정보로 변경할 필요가 있는 경우에 사용됩니다.
-
Upsert(업서트): 삽입과 업데이트를 결합한 작업입니다. 기존 레코드를 수정하고 조직에 레코드가 없는 경우 새 레코드를 생성합니다. 이 작업은 데이터를 가져올 때 기존 레코드와 새 레코드가 혼합된 상황에서 유용하게 사용될 수 있으며, 레코드가 이미 존재하는지 여부에 관계없이 데이터를 세일즈포스에 정확히 맞추고 싶을 때 사용됩니다.
Ways of Importing, Exporting Data

Salesforce에서 데이터를 가져오고 내보내는 일은 주로 다음 세 가지 방법이 있습니다
-
데이터 로더(Data Loader):
- 데이터 로더는 대량의 데이터(최대 500만 개의 레코드)를 가져오거나 내보낼 수 있는 클라이언트 프로그램입니다. 데이터 로더는 CSV 파일을 사용하여 Salesforce로 데이터를 가져오거나 데이터를 내보낼(export) 때 사용됩니다.
- 사용자는 '삽입(Insert)', '업데이트(Update)', '업서트(Upsert)', '삭제(Delete)', 그리고 '내보내기(Export)'와 같은 다양한 작업을 선택할 수 있습니다.
-
데이터 가져오기 마법사(Data Import Wizard):
- 데이터 가져오기 마법사는 Salesforce 내장 도구로, 사용자가 Salesforce에 데이터를 쉽게 가져올 수 있게 해줍니다. 이 도구를 사용하면 최대 50,000개의 레코드를 가져올 수 있으며, 사용자, 연락처, 계정, 리드, 그리고 사용자가 설정한 맞춤 객체 등과 같은 여러 가지 표준 객체를 위한 데이터를 가져올 수 있습니다.
- 데이터 가져오기 마법사는 '삽입', '업데이트', 그리고 '업서트' 작업을 지원합니다.
-
데이터 내보내기(Data Export):
- Salesforce에서는 데이터의 정기적인 백업이나 특정 시점에서의 데이터 세트가 필요할 경우를 위해 데이터를 내보낼 수 있는 기능을 제공합니다. 이 기능은 '설정' 메뉴를 통해 접근할 수 있으며, 사용자는 원하는 시기에 맞춤 설정을 통해 데이터를 내보낼 수 있습니다.
- 내보낸 데이터는 CSV 파일로 다운로드 할 수 있으며, 모든 표준과 맞춤 객체 데이터를 포함시킬 수 있습니다.
Data Loader

데이터 로더(Data Loader)는 Salesforce에서 제공하는 독립 실행형 응용 프로그램입니다. 데이터 로더를 사용하려면 소프트웨어를 사용자의 로컬 컴퓨터에 설치해야 합니다.
설치(Windows 기준)
Setup의 Quick Find에서 Data Loader를 검색해서 접근할 수 있습니다. Downloads를 누르면 리다이렉트 됩니다.

해당 화면에서 Download로 시작하는 링크를 눌러 압축파일을 다운 받을 수 있습니다.
압축파일을 해제하면 install batch파일을 통해 설치할 수도 있고 dataloader-60.0.2 JAR파일을 통해 그냥 실행할 수도 있습니다.
Insert
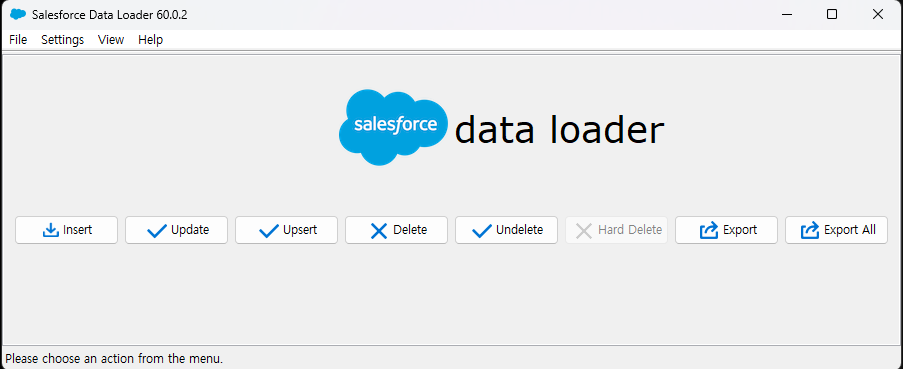
JAR파일을 실행하면 위와 같은 화면을 볼 수 있습니다. Insert 메뉴를 눌러 데이터 삽입을 해보겠습니다.
로그인

기능을 하나를 클릭하면 위와 같이 로그인을 먼저 요구합니다. 로그인 방법은 OAuth를 선택하고 지금 Environment를 선택해야 합니다. 각 환경은 아래와 같이 구분할 수 있습니다.
-
Production 환경
- 실제 운영 환경을 의미합니다. 여기에 있는 데이터는 실제 조직에서 사용되는 중요한 데이터이며, 이 환경에서는 최종 사용자에게 서비스되는 기능이나 데이터를 관리합니다. Production 환경에 접속하려면 실제 운영 중인 Salesforce 조직의 계정 정보를 사용해야 합니다.
-
Sandbox 환경
- 복제된 운영 환경이며, 테스트, 개발, 교육 등의 목적으로 사용됩니다. Sandbox 환경은 Production 환경의 영향을 주지 않으면서 여러 시나리오를 테스트하거나 개발할 수 있는 격리된 환경을 제공합니다. 이 환경에서 실험하거나 개발한 내용을 최종적으로 Production 환경에 배포하기 전에 검증할 수 있습니다.
-
Developer Edition
- 개발자가 Salesforce 플랫폼을 배우고 실험하기 위해 무료로 제공되는 버전입니다. 개발자는 이 환경에서 Salesforce 앱 개발, 통합 프로젝트, 테스트 등을 자유롭게 진행할 수 있습니다. Developer Edition 환경은 기본적으로 개별 개발자가 사용하는 독립된 환경이라고 볼 수 있습니다.
지금 실습하는 환경은 Developer Edition이고 해당 환경으로 접속하려면 Production을 선택해야 합니다.

Login 버튼을 누르면 팝업창이 뜨면서 브라우저 페이지가 열리게 됩니다. 코드를 입력하고 Connect 버튼을 누릅니다.
이미 로그인 되어있는 상태라서 계정을 선택할 수 있게 되어있습니다.
계정을 선택하면 권한허용을 묻습니다. 권한을 허용하면 로그인이 성공합니다.
Object 및 CSV 파일 선택

로그인이 성공하면 데이터를 삽입할 Object와 CSV파일을 제공할 수 있습니다. 선택한 CSV파일은 아래와 같은 데이터를 포함하고 있습니다.
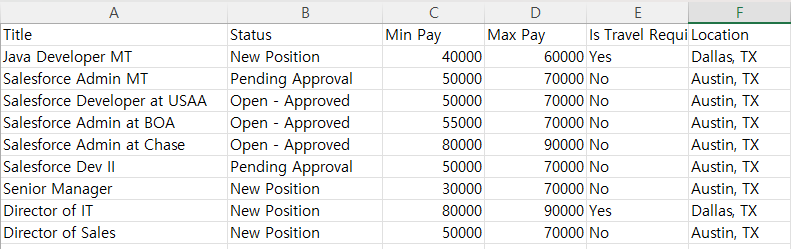
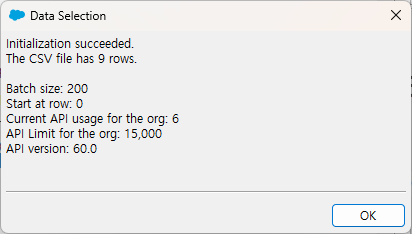
Next를 누르면 Initialization이 성공했다는 알림창이 나오면서 파일이 몇개의 로우를 갖고 있는지와 Insert 작업 관련된 정보들이 나옵니다.
(Optional) Relate using lookup field
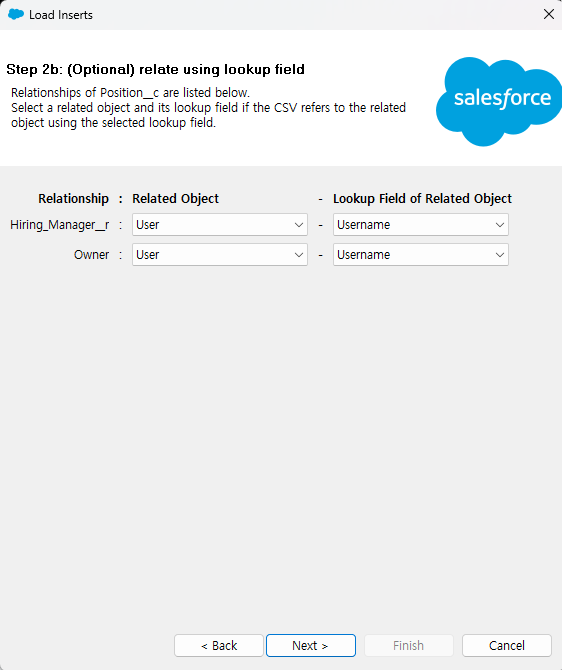
위에서 선택한 Object가 다른 Object와 관계를 맺고있는 Lookup Relation field의 리스트를 보여줍니다. Insert할 레코드들도 Lookup 관계를 맺어주기 위해 관계된 Object와 Field를 선택했습니다.
Mapping
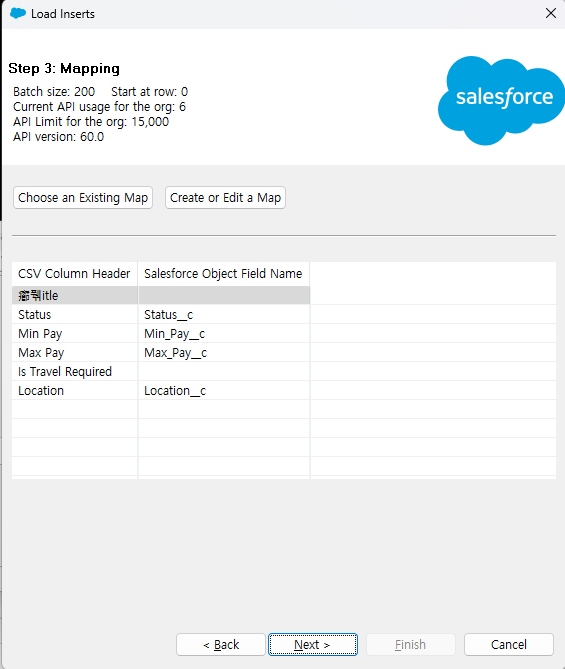
선택한 CSV파일의 칼럼과 선택한 Position Object의 필드를 맵핑하는 화면입니다.
Choose an Existing Map은 이미 맵핑한 내용이 담긴 파일이 있는 경우 선택할 수 있습니다.
없을 경우 Create or Edit a Map을 통해 맵핑하거나 맵핑한 내용을 파일로 저장할 수 있습니다. 첫 맵핑이므로 Create or Edit a Map을 눌러 맵핑해보겠습니다.
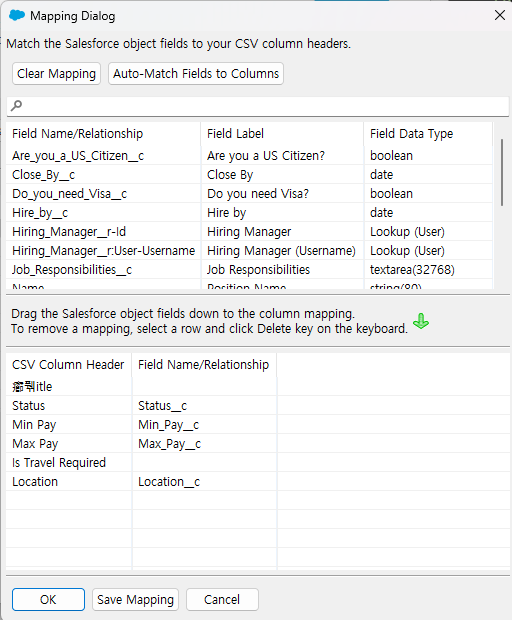
상단의 섹션은 Position Object의 필드이고 아래는 CSV파일의 칼럼과 필드를 맵핑하는 섹션입니다.
Auto-Match Fields to Columns를 누르면 자동으로 맵핑 가능한 필드들이 채워집니다. 자동을 맵핑되지 않는 경우 위에서 맞는 필드를 드래그앤드랍하여 맵핑할 수 있습니다.
Save Mapping을 눌러 맵핑한 내역을 파일로 저장할 수 있습니다.
Finish
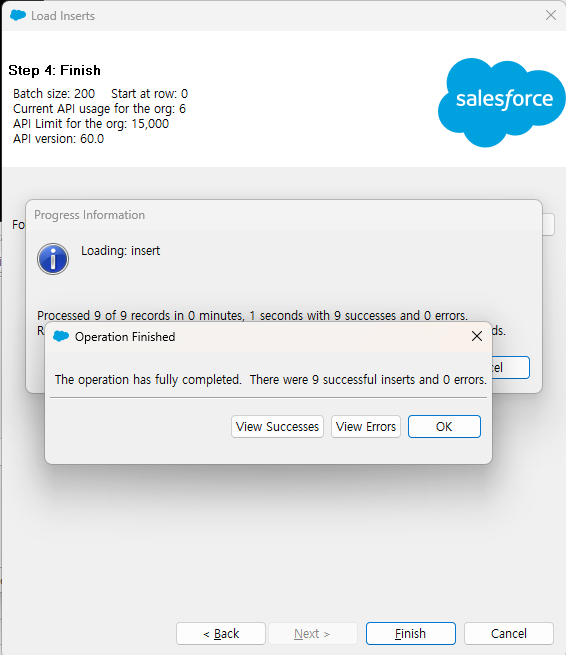
결과를 저장할 폴더를 선택하고 Finish를 누르면 작업이 진행되고 결과 알림창이 뜹니다. 9개의 레코드가 정상적으로 성공되었습니다.
지정한 폴더에 가보면 Insert에 성공한 레코드와 error 레코드의 목록이 파일로 저장된 것을 볼 수 있습니다.
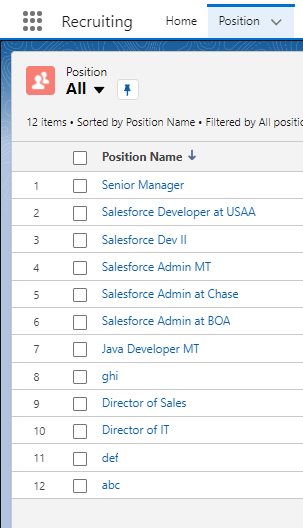
Recruiting App의 Position 페이지를 통해 새로운 레코드들이 정상적으로 등록된 것을 확인할 수 있습니다.
CSV파일의 레코드가 유효하지 않아서 실패할 경우

CSV파일에 유효하지 않은 값이 있는경우 어떻게 되는지 확인하고자 위와 같은 값을 포함한 파일을 생성했습니다.
첫번째 항목은 Min Pay가 Max Pay보다 큰 값을 포함하고 있는데 이는 기존에 설정해놓은 Validation Rule에 해당되어 Insert가 되지 않아야 합니다.
두번째 항목은 Status 필드는 Picklist 타입의 필드인데 Picklist Value에 포함되지 않은 AAA라는 값을 넣었기 때문에 Insert가 되지 않아야 합니다.
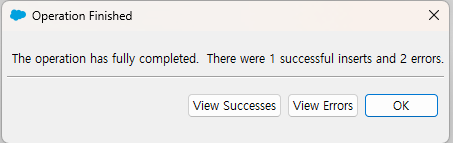
해당 파일을 Insert 해보니 1개가 성공하고 2개는 실패했다고 합니다.

에러 파일을 조회해보니 Validation Rule을 위반한 레코드는 ERROR 칼럼에 사전에 정의한 에러메시지가 표시되고 필드 제한사항을 어긴 레코드도 그에 맞는 에러메세지를 표기하는걸 볼 수 있습니다.
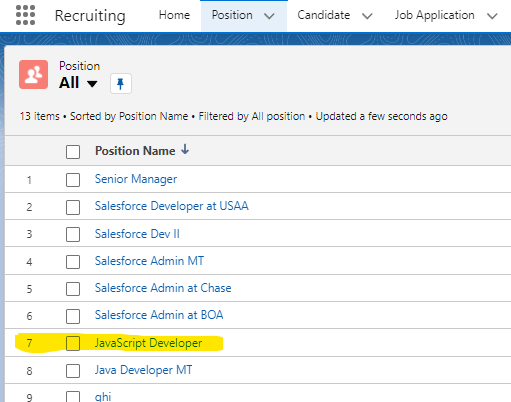
앱에서 레코드를 조회해보니 유효한 값이 었던 레코드는 정상적으로 삽입되었습니다.
이를 통해 Data Loader를 통해 데이터를 Insert할 때 유효하지 않은 값들은 건너뛰고 진행한다는 것을 알 수 있습니다.
Update
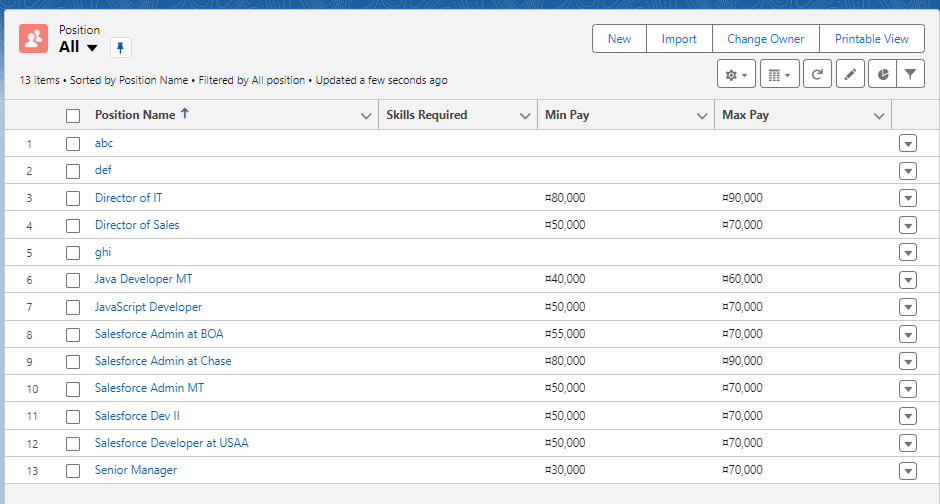
현재 존재하는 Position 레코드들은 SKills Required 필드의 값이 비어있습니다. 해당 필드들을 Data Loader의 Update 기능을 통해 수정해보도록 하겠습니다.
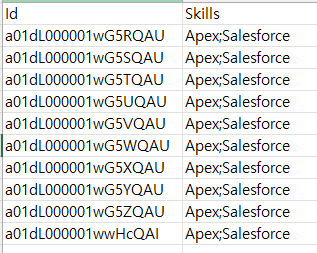
위와 같이 업데이트할 데이터를 포함한 파일을 준비했습니다. Skills Required필드는 Multi-select 필드이기 때문에 다수의 값을 넣기위해서는 ;으로 구분했습니다. 업데이트를 위해서는 Record ID가 필요합니다.
Record ID란
Salesforce의 Record ID는 Salesforce 데이터베이스 내에서 각 레코드(데이터 엔트리)를 고유하게 식별하는 키입니다. 이 ID는 대부분 Salesforce 기능 및 API들과 상호 작용할 때 중요한 역할을 합니다.

레코드 ID는 위와 같이 개별 레코드를 조회한 URL에서도 확인할 수 있습니다.
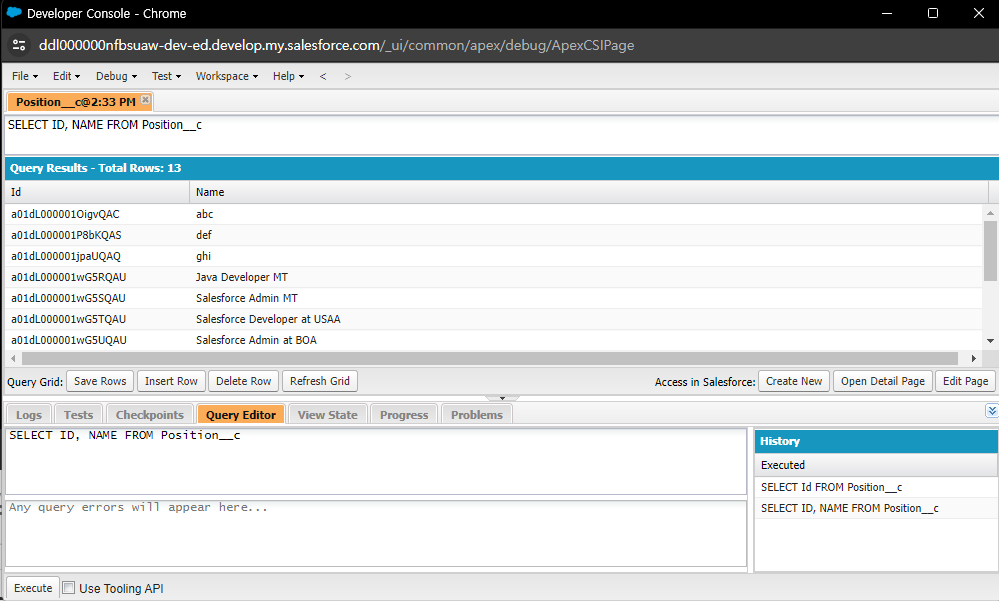
저는 Developer Console에서 쿼리를 통해 조회하여 파일에 기입했습니다.
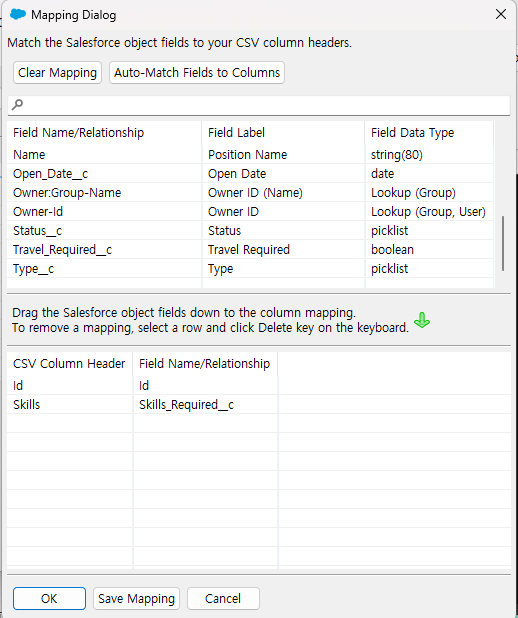
이후 Insert 때와 마찬가지로 필드와 컬럼을 맵핑했습니다.
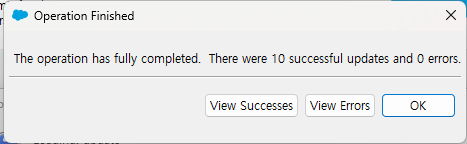
10개의 업데이트가 성공적으로 수행되었다는 알림을 확인했습니다.
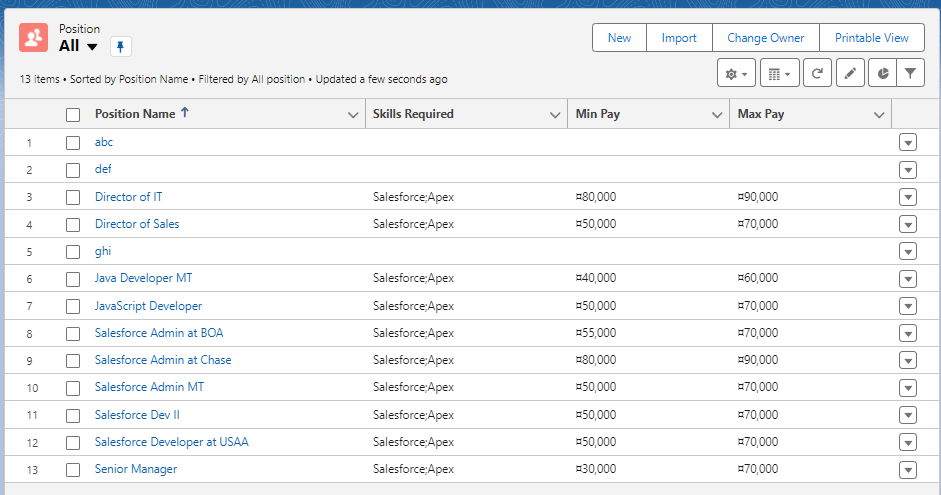
앱에서도 레코드 리스트에서 필드의 값이 정상적으로 업데이트 된 것을 확인할 수 있습니다.
Delete
Update와 마찬가지로 레코드를 삭제하기 위해서는 어떤 레코드를 삭제할지 식별하기위해 Record ID가 필요합니다.
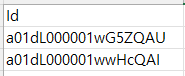
삭제할때는 Record ID 외 다른 값은 필요하지 않기에 지울 2개의 레코드에 대한 값만 준비했습니다.
이전과 동일하게 칼럼과 필드를 맵핑해주었습니다.
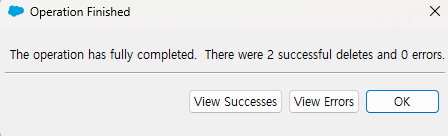
성공적으로 삭제되었다는 알림을 확인했습니다.
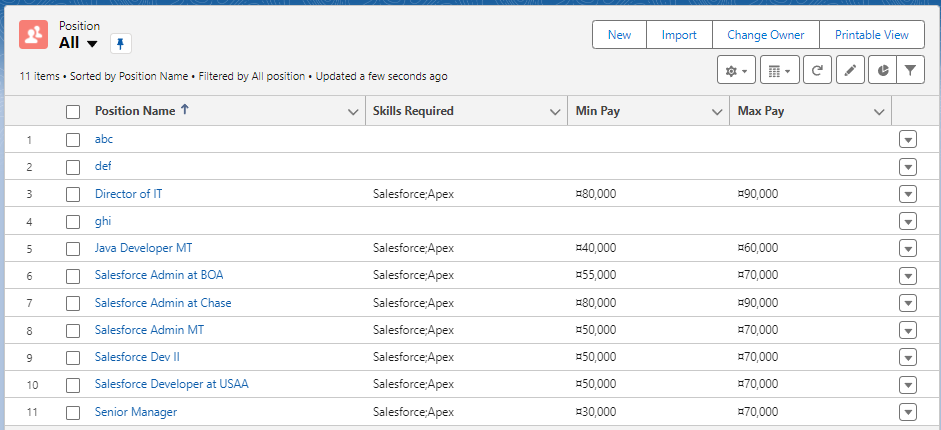
앱에서 Record 목록을 조회하니 2개의 레코드가 정상삭제되었습니다.
Export
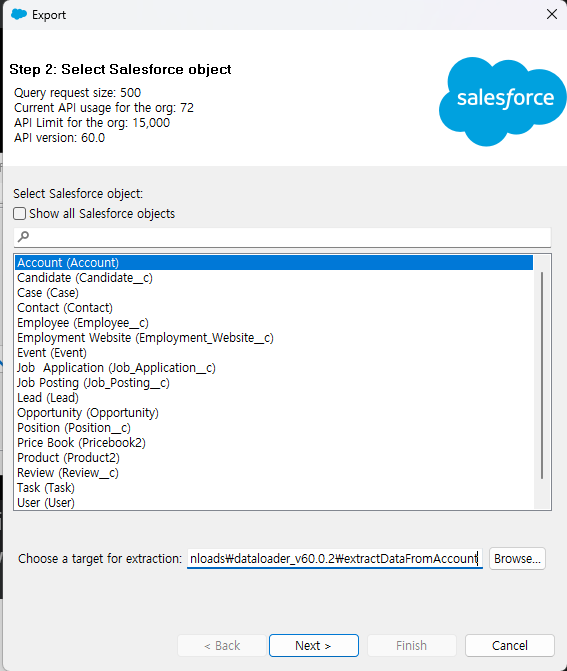
Export 아이콘을 클릭하면 어느 Object의 데이터를 추출할지 선택하고, 타겟을 지정해서 어느 위치와 파일명으로 추출할지 선택할 수 있습니다.
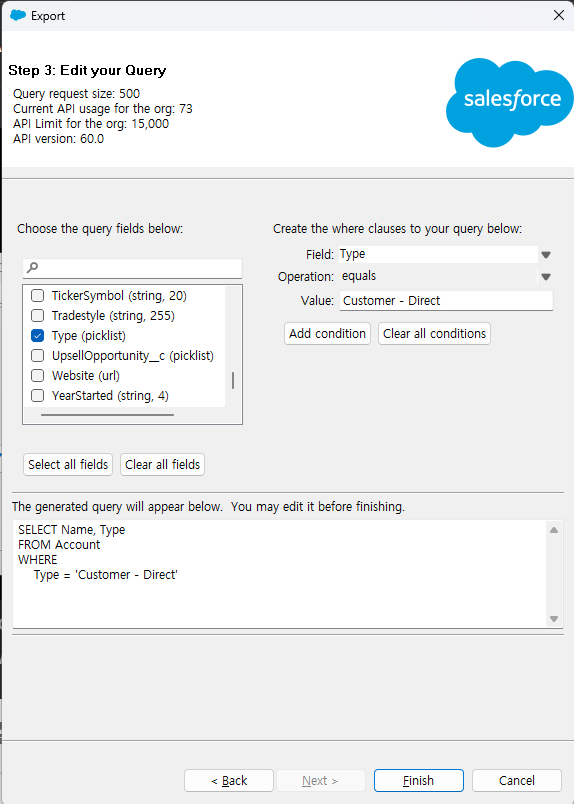
다음 스텝에서는 추출할 데이터를 쿼리를 통해 정의할 수 있습니다. 직접 쿼리를 작성할 수도 있지만, 편리하게도 선택한 Object의 필드를 편하게 조회할수 있고 체크하면 자동으로 SELECT문에 포함하여 쿼리를 생성해줍니다.
또, 각 필드별로 WHERE 조건을 지정할 수도 있습니다. 오른쪽 섹션에서 조건을 지정한 필드를 선택하고 연산자와 값을 입력후 Add condition을 클릭하면 쿼리에 WHERE문이 추가됩니다.

Finish를 클릭해보면 7개의 레코드가 정상추출 되었다고 합니다.
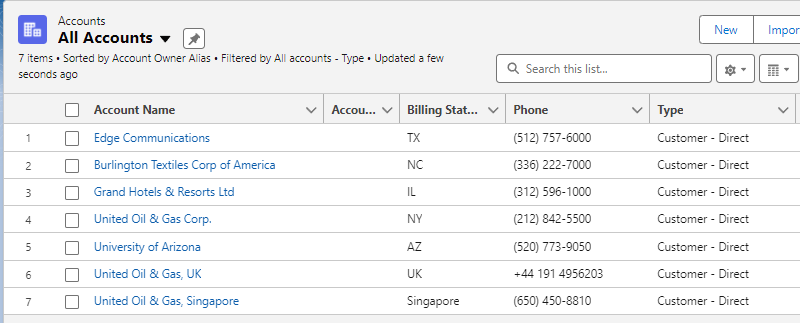
앱에서 필터를 통해 Type이 'Customer - Direct'인 레코드가 7개인 것을 보아 조건에 맞는 데이터를 정상적으로 추출한 것을 알 수 있습니다.
Data Import Wizard

Data Import Wizard의 주요한 차이점만 짚어보자면 다음과 같습니다.
- Data Loader는 모든 Standard Object와 Custom Object를 지원하는 반면에, Data Import Wizard는 Standard Object중
Accounts,Contacts,Leads,Solutions,Campaign Members,Person Accounts만을 지원합니다. - Data Import Wizard는 한번에 최대 50,000건의 레코드를 import할 수 있습니다. 그 이상의 레코드에 대한 작업이 필요한 경우 Data Loader를 쓰는 것이 좋습니다.
- Data Import Wizard는 데이터를 Export하는 기능을 지원하지 않습니다. 데이터 추출이 필요할 경우 Data Loader를 사용해야 합니다.

Data Import Wizard는 Data loader와 달리 별도 설치할 필요가 없습니다. Setup의 Quick Find에서 Data Import Wizard를 검색해서 선택하면 위와 같은 화면을 볼수 있고, Launch Wizard!버튼을 눌러 실행할 수 있습니다.
Insert
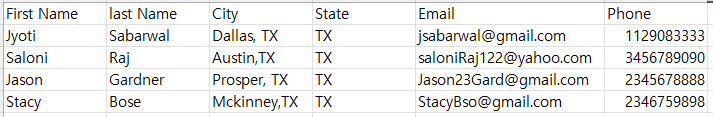
채용할 포지션에 지원할 지원자의 레코드를 관리하는 오브젝트인 Candidate에 Data Import Wizard를 통해 데이터를 생성해보도록 하겠습니다. 삽입할 데이터는 위와 같습니다.
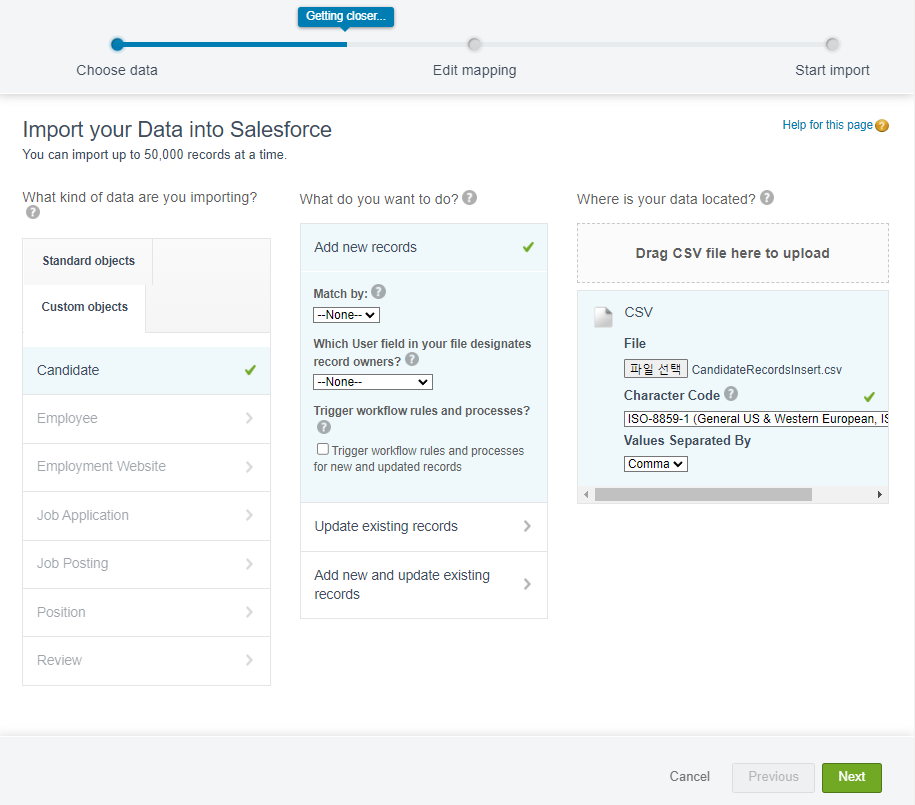
Wizard를 실행하면 위와 같이 데이터를 삽입할 오브젝트를 선택하고, 실행할 동작을 선택하고, 삽입할 레코드가 담긴 CSV파일을 제공하는 화면이 나옵니다.
Candidate Object를 선택하고 Add new records를 선택하니 아래 세가지 옵션이 제공됩니다.
Match By
- Unique values in your data (for example, ID values or email values) help Salesforce determine whether to add new records or update existing records.
- ID나 Email같은 유니크한 필드를 선택하면 기존에 존재하는 레코드인지에 따라 기존 레코드를 업데이트하거나 새로운 값을 생성합니다.
Which User field in your file designates record owners?
- Custom object records are owned by users. Choose the field that designates the owners of the records you'll import. If you choose None, Salesforce will assign you as the owner of all records created from this import.
- Custom Object의 레코드들은 소유자가 존재합니다. Insert할 파일에 레코드의 소유자를 지정할 필드가 있다면 해당 옵션을 통해 지정할 수 있고, 없다면 지금 로그인한 사용자를 소유자로 지정합니다.
Trigger workflow rules and processes?
- Trigger workflow rules and processes when their criteria are met by the imported records.
- 사전에 정의한 워크플로우나 프로세스가 있고, 삽입한 데이터에 의해 조건이 충족되면 해당 프로세스들을 실행할 지 선택할 수 있습니다.
지금은 해당 사항이 없기 때문에 해당 옵션들을 선택하지 않고 진행했습니다.
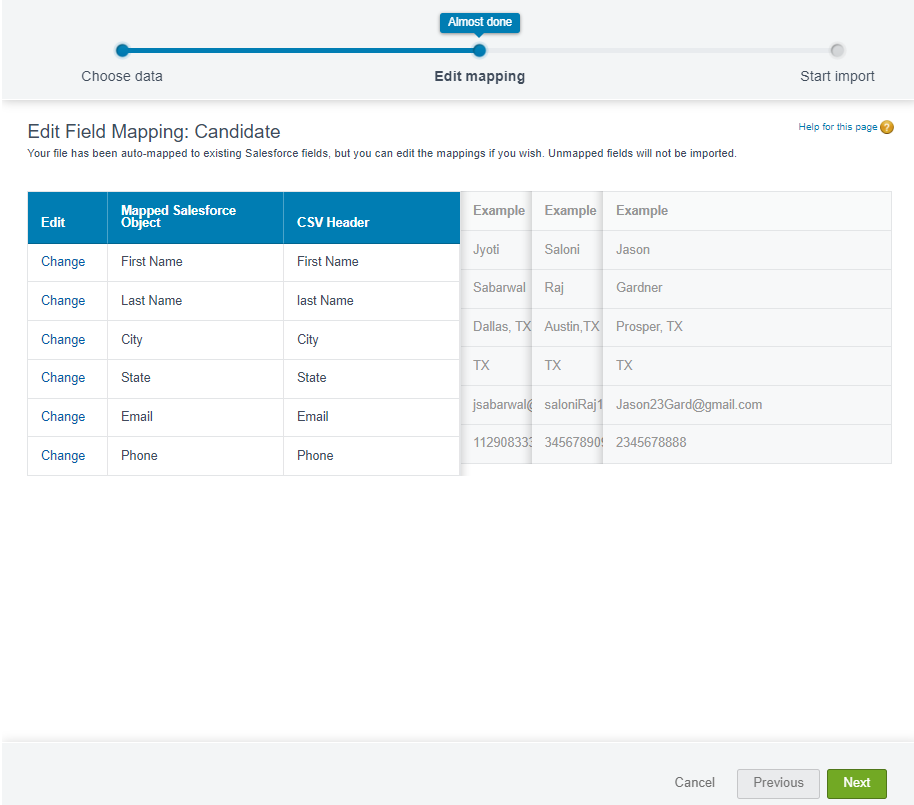
Data Loader를 사용했을때와 마찬가지로 Obejct의 필드와 CSV 파일의 칼럼을 맵핑하는 단계입니다. 필드명과 칼럼명을 동일하게 설정하니 자동으로 맵핑된 것 을 볼 수 있습니다. 변경이 필요한경우 Change 버튼을 눌러 맵핑을 수정할 수 있습니다.
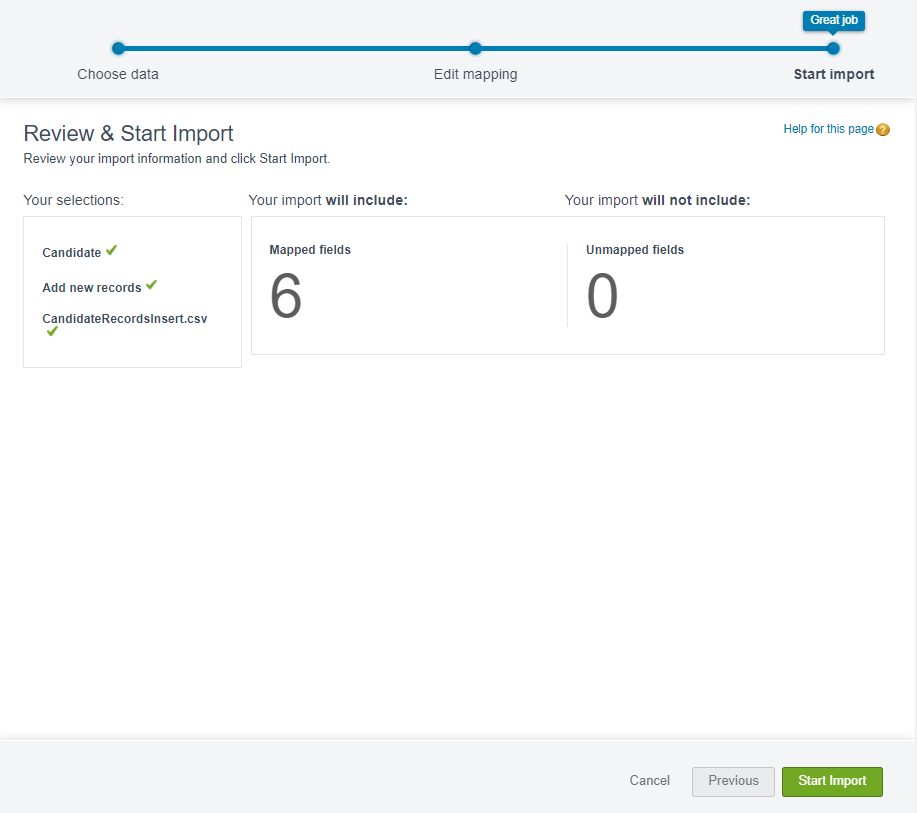
지정한 내용을 리뷰하고 Start Import를 눌러줍니다.
Import가 시작되었다는 알림창이 뜨고 OK를 클릭하면 상태를 알수 있는 결과창으로 넘어갑니다.
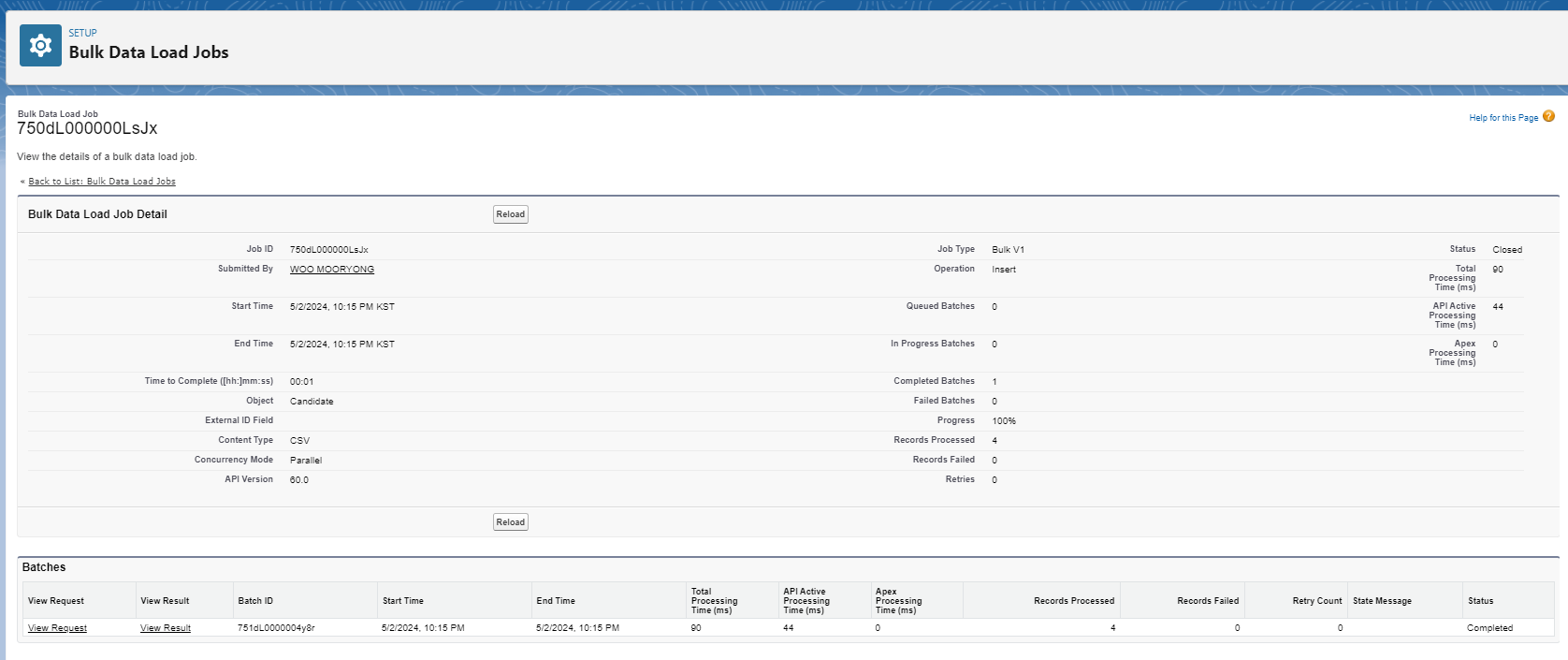
결과창에서는 다양한 세부내용들을 확인할 수 있습니다. Record Processed 4, Record Failed 0으로 4개 레코드가 정상 삽입된 것으로 보입니다.
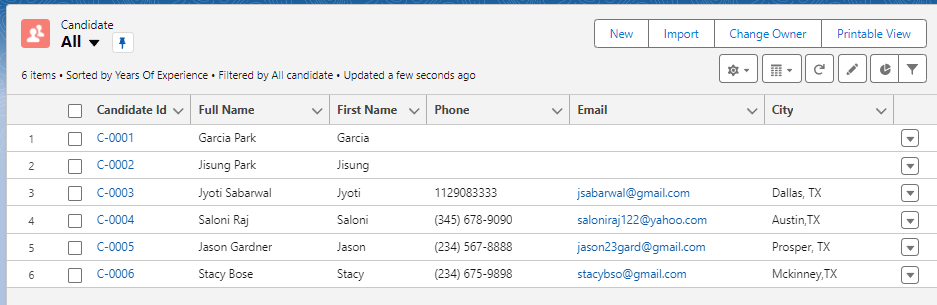
앱에서 레코드 목록이 정상 조회되는 것을 확인할 수 있습니다. C-0001,C-0002 레코드는 전화번호, 이메일, City 필드가 비어있습니다. 다음으로는 Update 기능을 통해 해당 값들을 채워주도록 하겠습니다.
Update

업데이트할 레코드들의 식별자와 필드값들을 CSV파일로 준비했습니다.
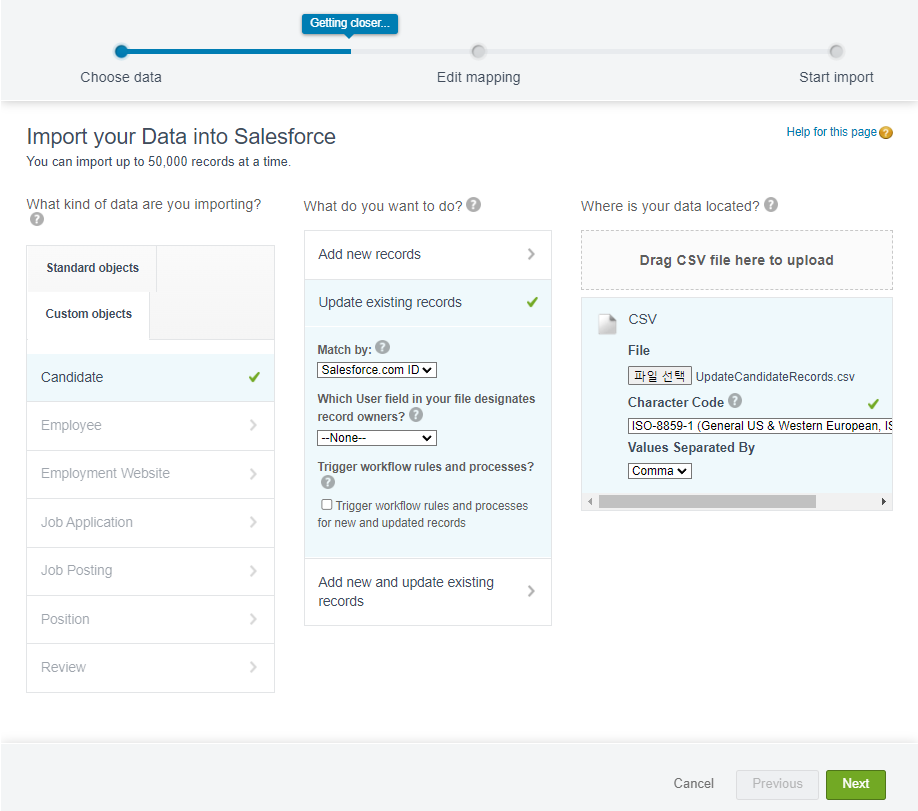
Candidate Object를 선택해주고 Update시엔 식별자값이 꼭 필요하여 파일에 포함했으므로 세일즈포스가 해당 식별자를 인식할 수 있도록 Match by에 Salesforce.com ID를 선택해줬습니다.
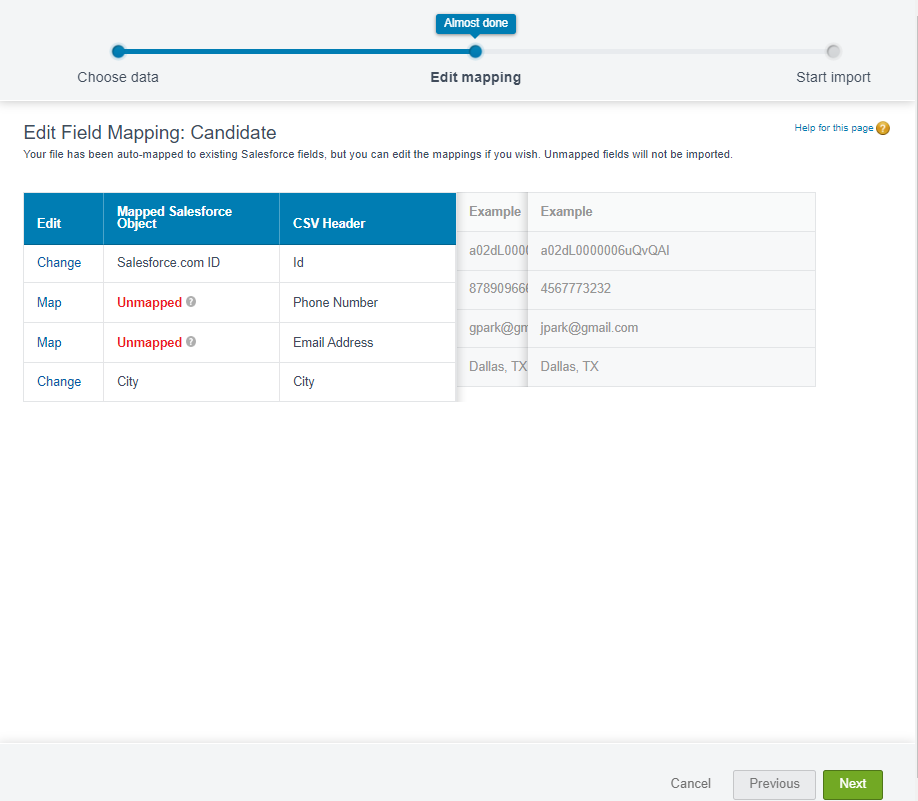
자동 맵핑되지 않은 필드들은 직접 맵핑해주었습니다.
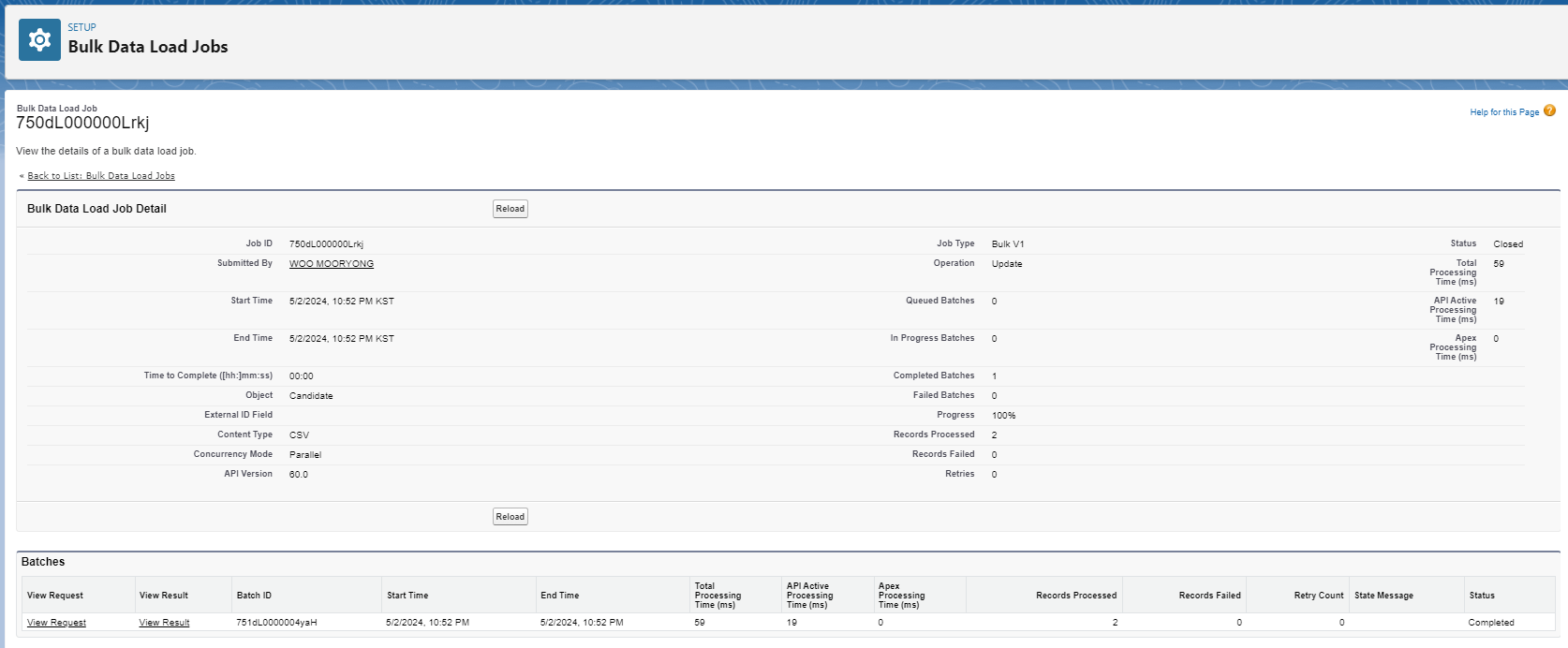
결과창을 통해 정상적으로 업데이트 된 것을 확인할 수 있습니다.
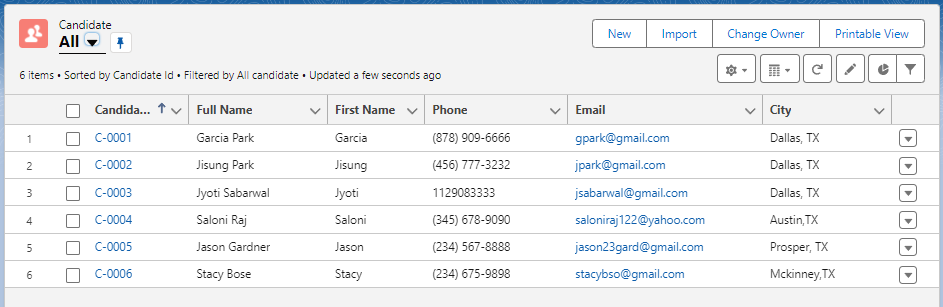
앱에서도 비어있던 필드값들이 업데이트 된 것을 확인할 수 있습니다.
Difference between Data Import Wizard and Data Loader
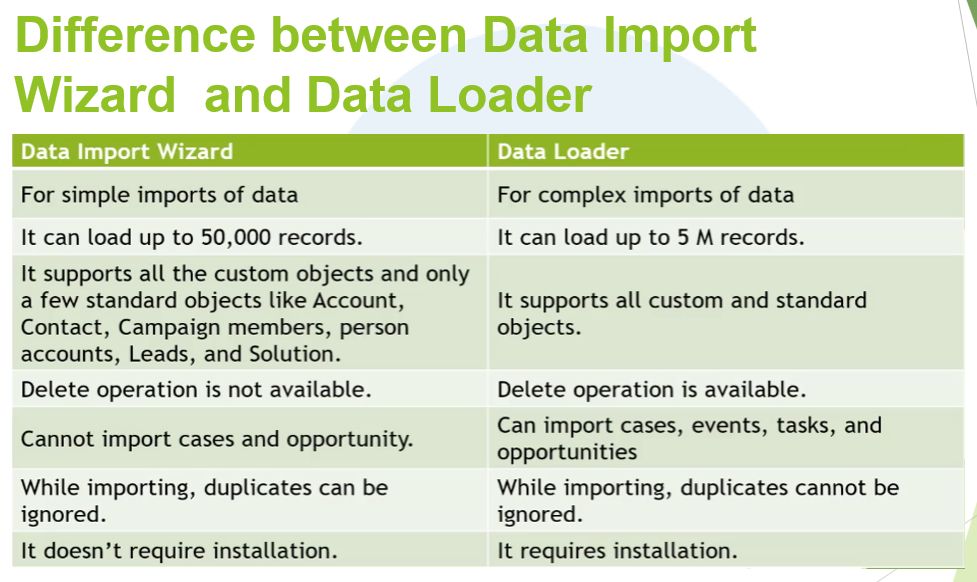
Data Loader와 Data Import Wizard간의 차이를 다시 한번 정리해보겠습니다.
- Data Import Wizard는 한번에 최대 50,000개의 레코드만 작업할 수 있는 반면 Data Loader는 최대 5백만개의 레코드를 작업할 수 있습니다.
- Data Loader는 모든 Standard, Custom Object를 지원하는 반면에 Data Import Wizard는 Custom Object와 일부 Standard Object만 지원합니다.
- Data Import Wizard는 Delete작업은 지원하지 않습니다.
- Data Import Wizard는 기존에 존재하는 중복 데이터를 인지하고 무시하여 사용자가 중복을 관리하지 않아도 됩니다. Data Loader는 중복 레코드에 대해 별도 예외처리나 필터링을 하지 않기 때문에 사용자가 직접 중복데이터를 관리해야 합니다.
Important Points to Remember


Data Loader나 Data Import Wizard를 사용할때 다음과 같은 주의사항이 있습니다.
-
Multi-Select Picklists:
- Multi-Select 필드에 여러가지 값을 넣을땐 파일내에서 각 값들을 세미콜론
;으로 구분해야 합니다.
- Multi-Select 필드에 여러가지 값을 넣을땐 파일내에서 각 값들을 세미콜론
-
Checkboxes:
- 체크박스 필드의 값은 boolean타입이므로 1 또는 0으로 기입해야 합니다.
-
Default Values:
- Picklist, Multi-Select Picklist, Checkbox 필드들에 대해서 값을 맵핑하지 않으면 해당 필드의 기본값이(있는 경우) 자동으로 삽입됩니다.
-
Date/Time Fields:
- import하려는 날짜/시간 데이터 형식이 Salesforce의 로케일 설정에 맞도록 해야합니다.
-
Formula Fields:
- 수식필드는 read-only이기 때문에 import될 수 없습니다.
-
Field Validation Rules:
- Validation Rules는 데이터가 import 되기 전에 수행됩니다. 따라서, Validation Rule에 저촉되는 레코드는 import되지 않습니다.
-
Universally Required Fields:
- 데이터 무결성 유지를 위해 필수항목으로 지정된 필드는 꼭 포함해야 합니다.
