Documents
프로즈미러는 그 자신의 자료구조를 content document를 표현하기 위해 정의합니다. document는 에디터의 다른부분이 동작하는 중심에 있기 때문에, 그것들을 이해하기 위해서라도 꼭 알아야합니다.
Structure
프로즈미러의 document는 노드이고, 이 노드는 0개 혹은 그 이상의 자식 노드들을 갖습니다.
이는 브라우저 DOM과 굉장히 비슷합니다. 특히 재귀적이고 트리구조인 점이요. 그러나 inline content를 담는 방식이 DOM과 다릅니다.
HTML에서는 markup과 함께하는 paragraph는 트리로 표현됩니다.

그러나 프로즈미러에서는 inline content는 평평한 순열로 표현됩니다. 마크업이 노드의 메타데이터로써 붙게되죠.

이건 우리가 그런 텍스트를 다루는데 있어서 사고하는 방식과 더욱 비슷합니다. 이는 paragraph안의 position을 트리보다는 문자 오프셋으로 표현할 수 있게 합니다. 그리고 이것은 content의 스타일을 바꾸거나 쪼개는 등의 일을 행할 때 당황스러운 트리 조작을 행하지 않아도 되도록 합니다.
이는 또한 각 document가 딱 하나의 알맞은 표현방식을 갖고있음을 의미합니다. 같은 mark를 가지는 인접한 text 노드는 항상 뭉쳐집니다. 그리고 빈 text 노드는 허용되지 않습니다. mark가 표시되는 순서는 schema로부터 정의됩니다.
그렇기 때문에 프로즈미러 document는 블록 노드의 트리이며, 대부분의 리프 노드는 text를 포함하는 노드인 textblock이 됩니다. 여러분은 또한 단순히 비어있는 리프 노드를 가질 수도 있습니다. 예를 들면 horizontal rule 혹은 video같은것입니다.
노드 오브젝트는 document에서 그들이 갖는 역할을 반영하는 다양한 프로퍼티를 가집니다.
- isBlock과 isInline은 주어진 노드가 block인지 inline 노드인지 알려줍니다.
- inlineContent는 inline 노드를 content로 갖는 노드에 대해서는 true입니다.
- isTextblock은 inline content가 있는 블록 노드에 대해서는 true입니다.
- isLeaf는 노드가 어떠한 content도 허용하지 않는다는 것을 의미합니다.
그래서 일반적인 "paragraph" 노드는 textblock일 것이고, blockquote는 block element가 될것이며, 이는 다른 블록으로 이루어져 있을것입니다. Text, hard breaks, 그리고 inline image는 inline 리프 노드이며, horizontal rule 노드나 video 노드는 블록 리프 노드의 예제입니다.
이 스키마는 어떤 것이 어디에 표시되어야할지를 명확히해주는 constraints가 됩니다. 심지어 노드가 block content를 허용하더라도, 그 노드가 모든 블록 노드를 허용한다는 뜻은 아닙니다.
Identity and persistence
DOM 트리와 ProseMirror의 또 다른 중요한 차이점은, 노드의 행동을 표현하는 object의 차이입니다. DOM에서는 노드가 mutable 오브젝트로써 identity를 갖고, 이는 노드가 단 하나의 parent 노드에만 나타난다는 뜻입니다. 그리고 그 노드 오브젝트는 업데이트될 때 mutate됩니다.
프로즈미러에서는 반면, 노드는 그저 값일 뿐입니다. 그리고 이것에 접근할 때는, 여러분이 단순한 숫자 3을 표현하는 것과 같습니다. 3은 다양한 자료 구조에 동시에 등장하고, 이것은 현재 자료구조에 대한 parent-link가 없습니다. 만약 3에 1을 더하면 4가 되며, 원본 3에 대해서는 어떤 변화도 가하지 않습니다.
그렇기 때문에 이것은 프로즈미러 document의 한 조각일 뿐입니다. 그들은 변화하지 않고, 단순히 starting value로써 사용되고, 컴퓨팅되어 수정되면서 document 조각이 됩니다. 그들은 어떤 자료구조가 어떤 부분에 속해있는지 알지 못하고, 다양한 구조의 부분이 될수도 있으며, 같은 구조에 여러번 등장할 수도 있습니다. 그들은 stateful한 object가 아니라, 그저 value일 뿐입니다.
이는 여러분이 document를 업데이트할 때 마다, 여러분은 새로운 document value를 가질 뿐입니다. 이 docuement value는 모든 변화하지 않은 sub-node들을 가지므로, 비교적 만들기 쉽습니다.
여기에는 많은 장점이 있습니다. 이는 에디터가 update 도중 어중간한 위치의 state를 갖지 못하게 합니다. 새로운 state는 새로운 document와 함께, 즉시 swap됩니다. 이는 document에 대해 뭔가 수학적으로 생각하기 편하게 만듭니다. 이는 값이 자꾸 바뀌는 도중이라면 매우 어렵겠죠. 이는 collaborative editing을 가능하게 하고, 효율적인 DOM update 알고리즘을 실행하게합니다.
이러한 노드들은 스탠다드한 JavaScript Object로 표현되기 때문에, 그리고 명시적으로 성능을 프리징하기 때문에(?) 실제로 이를 변화하는 것은 가능합니다. 그러나 그렇게 하는것은 허락되지 않습니다. 그리고 모든걸 망가뜨릴 것입니다. 왜냐하면 그들은 다양한 구조에 대해 공유되기 때문입니다. 그러니까 조심하세요! 그리고 이는 또한 노드 오브젝트의 부분인 어레이나 일반 오브젝트에 대해서도 마찬가지입니다. 예를 들어 노드의 attributes를 저장하는데 사용되거나, fragments의 자식 노드 어레이에 있는 것들이요.
Data structures
document에 대한 object structure는 다음과 같습니다:
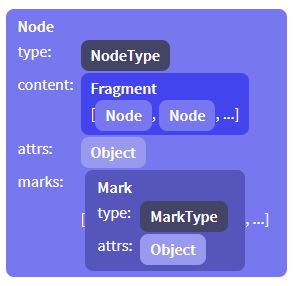
각 노드는 노드 클래스의 인스턴스로 대표됩니다. 이는 하나의 type으로 태그되고, 이는 노드의 이름, 적절한 attributes 등등을 정의합니다. 노드 타입(그리고 mark type)은 스키마 별로 한번씩 만들어지며, 그들이 속한 스키마의 이름을 알고있습니다.
노드의 콘텐트는 Fragment의 인스턴스에 저장되어있고, Fragment는 노드의 순서를 기억합니다. 심지어 content를 허용하지 않거나, 없는 노드의 경우에도 이 필드는 채워져있습니다(공유되는 비어있는 fragment와 함께)
몇몇 노드 타입은 각노트에 별도로 저장되는 attributes를 허용합니다. 예를들어 이미지노드는 alt text와 이미지 url을 저장하기 위해 이를 이용합니다.
그리고, 인라인 노드는 active marks의 집합을 보관하고있고(emphasis 혹은 link와 같은), 이는 Mark인스턴스의 배열로 표현됩니다.
document는 그냥 노드입니다. document의 content는 top-level 노드의 자식 노드들로 표현됩니다. 일반적으로, 이는 block 노드의 시리즈를 포함하고, 이중 일부는 인라인 콘텐트를 포함하는 textblock입니다. 그러나 top-level 노드는 또한 그 자체가 textblock일 수도 있습니다. 그러면 document는 inline content만을 포함합니다.
어떤 종류의 노드가 어디에 허용되는지는 document의 스키마에 의해 결정됩니다. programmatically 하게 노드를 생성하기 위해, 여러분은 스키마를 통해야만 합니다, 예를 들어 노드와 텍스트 메서드를 이용하여.
import {schema} from "prosemirror-schema-basic"
// (The null arguments are where you can specify attributes, if necessary.)
let doc = schema.node("doc", null, [
schema.node("paragraph", null, [schema.text("One.")]),
schema.node("horizontal_rule"),
schema.node("paragraph", null, [schema.text("Two!")])
])Indexing
프로즈미러 노드는 두 종류의 인덱싱을 지원합니다-그들은 개별 노드를 오프셋으로 나누어 트리로 취급합니다, 혹은 token의 flat sequence로 취급합니다.
첫번째 방법은 여러분에게 DOM과 비슷하게 접근하도록 합니다-단일 노드와 상호작용하고, child 메서드나 childCount를 이용하여 document를 scan through하면서 직접적으로 자식 노드들에 접근합니다. (모든 노드를 보고싶다면 descendants 혹은 nodesBetween을 사용합니다.)
두번째 방법은 document의 특정 위치를 언급할 때 더 유용합니다. 이것은 어떤 document의 위치든 int로 표현되게 허용합니다 - token sequence의 인덱스로써. 이 토큰들은 실제로 메모리에 오브젝트로써 존재하지는 않는데, 그들은 그냥 counting convention일 뿐입니다. 그러나 이 document의 트리 모양은 각 노드가 각자의 사이즈를 알고있다는 사실과 함께, position 접근비용을 싸게 만듭니다.
-
document의 시작은, 첫번째 content의 바로 앞은 위치가 0입니다.
-
leaf 노드가 아닌 노드에 들어가거나 떠나는 것은 1개의 토큰으로 간주합니다. 그래서 만약 document가 paragraph로 시작한다면, paragraph의 시작은 position 1으로 간주합니다.
-
각 텍스트 노드의 글자는 1개의 토큰으로 간주합니다. 그러니까 만약 paragraph가 document의 시작에 위치하고, 단어 "hi"를 포함한다면, position 2는 h 뒤이고, position 3은 "i" 뒤입니다. position 4는 모든 paragraph 뒤입니다.
-
content를 허용하지 않는 리프 노드는(이미지 같은 것), 또한 하나의 토큰으로 간주합니다.
그래서 만약 HTML로 표현했을 때 document가 다음과 같다면.
<p>One</p>
<blockquote><p>Two<img src="..."></p></blockquote>토큰 순서는 다음과 같습니다.
0 1 2 3 4 5
<p> O n e </p>5 6 7 8 9 10 11 12 13
<blockquote> <p> T w o <img> </p> </blockquote>각 노드는 전체 노드의 사이즈를 알려주는 nodeSize 프로퍼티를 가지고있습니다. 그리고 여러분도 .content.size로 접근 가능합니다. 바깥 document node에 대해서는, 열린 토큰과 닫힌 토큰은 document의 일부로 간주되지 않습니다.(왜냐하면 여러분의 커서를 document에 둘 수 없기 때문입니다.) 그러니까 document의 사이즈는 doc.content.size이지, doc.nodeSize가 아닙니다.
이러한 position을 수동으로 해석하는 것은 많은 수고가 듭니다. Node.resolve를 이용하면 더 위치에 대한 descriptive한 자료구조를 얻을 수 있습니다. 이 자료구조는 위치의 parent node가 무엇인지, parent가 어떤 offset에 위치하고있는지, 어떤 조상이 parent를 가지고 있는지 등을 알려줍니다.
Take care to distinguish between child indices (as per childCount), document-wide positions, and node-local offsets (sometimes used in recursive functions to represent a position into the node that's currently being handled).
Slices
복사-붙여넣기나, 드래그-드롭같은것을 다루기 위해선 document의 slice에 대해 얘기해야할것 같습니다. 예를 들어 두 위치 사이의 content를 말하는게 slice입니다. 이런 slice는 full 노드 혹은 fragment에 대해 open인지 아닌지에 따라 조금 달라집니다.
예를 들어, 만약 여러분이 한 paragraph의 중간에서부터 다음 paragraph의 중간까지 선택한다면, 두 paragraph를 선택한것이 되고, 첫번째 문단은 open start가 되고, 두번째 파트는 open end가 된다. 반면, 만약 여러분이 paragraph를 노드선택한다면, closed 노드를 선택한것이 된다. 만약 노드의 full content처럼 취급된다면, open 노드의 content는 일종의 스키마 constraint 위반일지 모른다, 왜냐하면 몇몇 필수 노드들이 slice 바깥에 존재하기 때문이다.
Slice 자료구조는 그러한 slice를 표현하기 위해 존재한다. 이들은 양 사이드의 open depth의 fragment를 저장한다. 여러분은 slice 메소드를 노드에 적용하여 document를 잘라낼 수 있다.
// doc holds two paragraphs, containing text "a" and "b"
let slice1 = doc.slice(0, 3) // The first paragraph
console.log(slice1.openStart, slice1.openEnd) // → 0 0
let slice2 = doc.slice(1, 5) // From start of first paragraph
// to end of second
console.log(slice2.openStart, slice2.openEnd) // → 1 1Changing
노드와 fragment가 지속성이 있기 때문에, 그들을 mutate해서는 안된다.
대부분의 경우 document update를 위해선 transformation을 사용해야한다. 직접적으로 node를 건드리면 안된다. 그리고 이건 변화의 기록을 남길것이다, document가 editor state의 부분으로 존재하기 위해선 필수적인 것이다.
만약 document의 업데이트된 버전을 수동으로 하길 원한다면, 몇몇 helper 메소드들이 Node와 Fragment type에 존재한다. 전체 document의 업데이트된 버전을 만들기 위해서는, Node.replace를 통해 새로운 content의 slice로 교체할 수 있다. node를 얕게 업데이트하려면, copy 메소드를 사용하여 새로운 content를 가진 비슷한 노드를 만들어낼 수 있다. Fragment는 또한 다양한 업데이트 메소드를 가지고 있다, 예를 들면 replaceChild나 append와 같은것들.
