기계학습의 종류
- 지도학습
입출력 쌍의 데이터로 학습해서 새로운 입력에 대한 출력을 결정하는 패턴 추출 - 비지도학습
출력에 대한 정보 없는 데이터로만 학습 및 패턴 추출 - 반지도학습
일부 학습 데이터만 출력값만 주어지고 패턴 추출 - 강화학습
출력에 대한 정확한 정보는 없지만,평가정보는 주어지는 문제에 대해 각 상태에서의 행동 결정
기계학습 대상
- 분류
- 과적합 학습 문제
- 학습 데이터가 적은 경우 성능평가
- 불균형 데이터 문제
- 이진 분류기 성능 평가
- 회귀
- 군집화
- 밀도 추정
- 차원축소
- 이상치 탐지
- 반지도 학습
지도학습
분류
- 출력이 정해진 부류 중의 하나로 결정
- 일반화 능력이 좋은 것
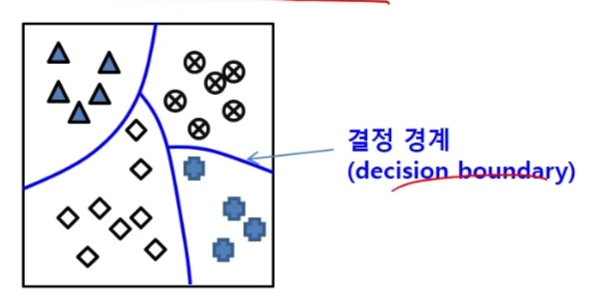
- 학습
학습 데이터를 잘 분류할 수 있는 함수 찾기, 수학적 함수일 수도 규칙일 수도 있다. - 분류기 학습 알고리즘
- 데이터 구분
- 학습 데이터
많을 수록 유리 - 테스트 데이터
객관적인 평가를 위해 학습에 사용되지 않은 데이터 권장 - 검증 데이터 (옵션)
- 학습 데이터
- 과적합
- 학습데이터에 대해 지나치게 잘 학습된 경우
- 학습되지 않은 데이터에 대해서는 좋지 않은 성능을 보임
- 회피 방법
- 학습과정에서 별도의 검증데이터에 대한 성능 평가 - 오류가 증가하는 시점에서 중지
- 부적합
- 학습 데이터가 충분히 학습되지 않음
- 분류기 성능 평가
- 정확도
- 얼마나 정확하게 분류하는가
- 정확도 = 맞게 분류한 데이터 수 / 전체 데이터 개수
- 정확도
- 데이터가 부족한 경우 성능평가
- K-겹 교차검증 (K-fold cross-validation) 사용
- 전체 데이터를 K 등분
- 각 등분을 한번씩 테스트 데이터로 사용 후 평균값을 선택

- K-겹 교차검증 (K-fold cross-validation) 사용
- 불균형 데이터 문제
- 특정 부류에 속한 학습 데이터 수가 편파적임
- 가중치를 고려한 정확도 사용
- 인공적으로 부족한 데이터 생성
- 이진 분류기의 성능 평가
- 이진 분류기
두 개의 부류만 갖는 데이터 분류기
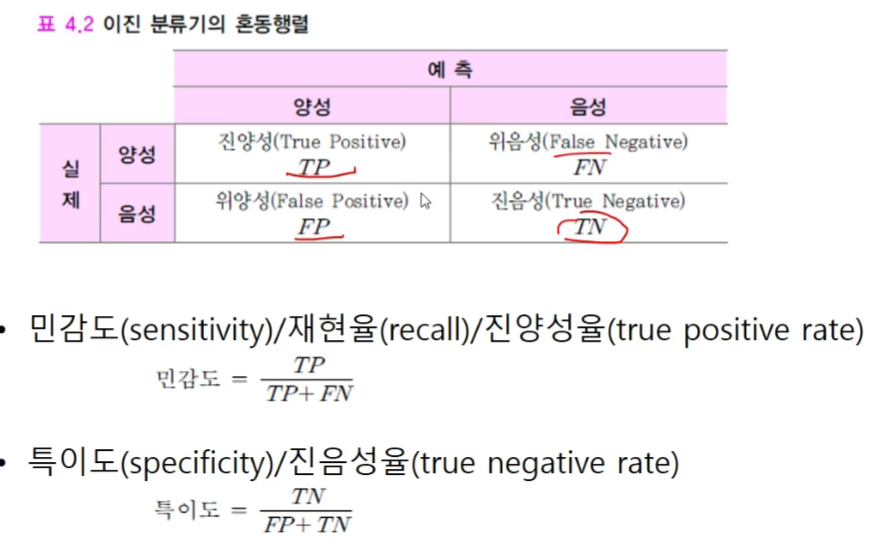
- 이진 분류기
- 일반화 능력이 좋은 것
회귀분석
- 회귀
- 학습 데이터에 부합하는 출력값이 실수인 함수를 찾는 문제
- 성능
- 오차 = 예측값과 실제값의 차이
테스트 데이터들에 대한 (예측값 - 실제값)^2의 평균이나 평균의 제곱근
- 오차 = 예측값과 실제값의 차이
- 과적합과 부적합
- 지나치게 복합한 모델, 단순한 모델을 사용하면 발생
- 과적합 대응 방법
모델의 복잡도를 성능 평가에 반영
- 로지스틱 회귀 -> 이진 분류 문제시 사용
경사 하강법 사용 학습
비지도학습
- 결과 정보가 없는 데이터들에 대해서 특정 패턴을 찾는 것
- 데이터에 잠재한 구조, 계층 구조 찾기
- 문서들을 주제애 따라 구조화
- 로그 정보를 사용해서 사용패턴 찾기
- 숨겨진 사용자 집단 찾기
- 군집화
- 밀도추정
- 차원축소
- 이상치 탐지
군집화
- 유사성에 따라 데이터를 분할
- 일반 군집화
- 데이터는 하나의 군집에만 소속
- 퍼지 군집화
- 데이터가 여러 군집에 부분적으로 소속
- 소속 정도의 합은 1
- 성능 평가
- 군집 내의 분산, 군집 간의 거리
밀도 추정
- 부류별 데이터를 만들어 냈을 것으로 추정되는 확률분포 찾기
- 모수적 밀도 추정
- 분포가 특정 수학적 함수의 형태를 가진다고 가정
- 주어진 데이터가 잘 반영되게끔 함수의 파라미터 결정
- 비모수적 밀도 추정
- 특정 함수를 가정하지 않고, 주어진 데이터를 이용해서 밀도함수의 형태 표현
차원축소
- 고차원의 데이터를 정보 손실을 최소화해서 저차원으로 변환
- 차원의 저주
- 차원이 커질수록 데이터간의 거리가 유사해지는 경향
- 차원이 증가함에 따라 학습데이터의 갯수가 기하급수적으로 증가
- 주성분 분석
- 분산이 큰 소수의 축들을 기준으로 데이터를 사상(Projection)해서 저차원으로 변환
이상치 탐지
- 이상치
- 다른 데이터와 크게 달라 다른 메커니즘에 의해 생성된 것인지 의심스러운 데이터
- 잡음
- 제거 대상
- 점 이상치
다른 데이터와 비교해서 차이가 큰 데이터 - 상황적 이상치
상화에 맞지 않는 데이터 - 집단적 이상치
여러데이터를 모아서 보면 비정상으로 보이는 데이터 집단
반지도 학습
- 입력에 결과값이 없는 미분류 데이터를 함께 지도 학습에 사용
- 분류된 데이터는 높은 획득 비용, 미분류는 낮은 획득 비용
- 분류 경계가 인접한 미분류 데이터들이 동일한 집단에 소속하도록 학습
- 같은 군집에 속하면 가능한 동일한 분류에 소속하도록 학습
- 분류 데이터를 먼저 학습하고 그 뒤에 미분류 데이터를 학습
- 반지도 학습의 가정
- 평활성 가정
가까이 있는 점들은 서로 같은 부류에 속할 가능성 높음 - 군집 가정
같은 군집에 속하는 데이터는 동일한 분류일 가능성 높음 - 매니폴드 가정
잘 안쓰임
- 평활성 가정
결정트리
- 트리 형태로 의사결정 지식을 표현
- 내부 노드 -> 비교 속성
- 간선 -> 속성 값
- 단말 노드 -> 부류, 대표값
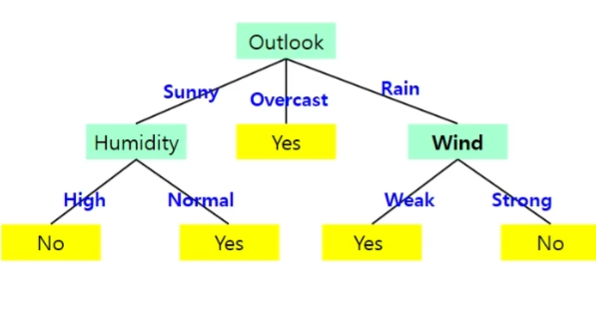
- ID3 결정 트리 알고리즘
- 모든 데이터를 포함한 하나의 노드로 구성된 트리에서 시작
- 반복적인 노드 분할 과정을 거침
- 분할 속성 선택
- 분할한 결과가 가능하면 동질적인 것으로
- 엔트로피 -> 동질적인 정도를 측정하는 척도
- 정보이득 -> 특정 속성을 분할한 후 각 부분집합의 정보량의 가중평균
- 정보 이득이 클수록 우수한 분할 속성
- 속성값이 많으면 데이터 집합을 많은 부분집합으로 분할
- 분할한 결과가 가능하면 동질적인 것으로
- 속성값에 따라 서브트리 생성
- 데이터를 속성 값에 따라 분배
- 분할 속성 선택
- 회귀를 위한 결정트리
- 분류를 위한 결정트리와의 차이점
- 단말노드가 부류가 아닌 수치값
- 해당조건을 만족하는 것들이 가지는 대표값
- 분할 속성 선택
- 표준편차 축소를 최대로 하는 속성 선택
- 분류를 위한 결정트리와의 차이점
KNN
- (입력, 출력)가 있는 데이터들이 주어질 때 새로운 입력 결과 추정시 결과를 아는 최근접한 K개의 데이터에 대한 결과정보 이용
- 거리계산 시
- 수치 데이터 -> 유클리디언 거리 사용
- 범주형 데이터 -> 응용분야에 맞춰 사용
- 효율적인 근접이웃 선택
- 데이터 갯수가 많아지면 계산시간이 증가됨으로 색인 자료구조 사용
- 결과 추정
- 분류
- 출력이 범주형 값
- 다수결 투표 사용
- 회귀분석
- 출력이 수치형 값
- 평균 -> 최근접 K개의 평균
- 가중합 -> 거리에 반비례하는 가중치 사용
- 분류
- 특징
- 학습단계에서는 데이터만 저장, 새로운 데이터가 주어지면 저장된 데이터 이용
군집화 알고리즘
- 데이터를 유사한 것 끼리 모으는 것
- 계층적 군집화
- 군집화 결과가 계층적인 구조임
- 병합형 계층적 군집화
- 각 데이터가 하나의 군집으로 구성, 가까이에 있는 군집들과 계속 결합
- 분리형 계층적 군집화
- 모든 데이터를 포함한 군집에서 유사성을 바탕으로 군집을 분리
- 분할 군집화
- 계층을 나누지 않고 유사한 것끼리 분리
단순 베이즈 분류기
- 부류 결정지식을 조건부 확률로 결정
신경망
- 인간 두뇌에 대한 계산적 모델을 통해 인공지능을 구현하려는 분야
- 퍼셉트론 -> 신경세포의 계산 모델
- 초기의 퍼셉트론

- 초기의 퍼셉트론
- OR연산

- 선형 분리 가능 문제에서는 문제없이 작동하지만
- 선형 분리 불가 문제 - XOR 문제에서는 작동안함
- 해결책으로 다층 퍼셉트론 사용
- 다층 퍼셉트론 (MLP)
- 학습
- 입,출력의 학습데이터에서 출력값 (계산값)의 차이(오차)를 최소가 되도록 가중치를 결정하는 것
- 알고리즘 -> 오차 역전파 알고리즘
- 출력 방법 -> 시그모이드 함수 이용
- 학습
딥러닝
딥러닝 신경망
- 다수의 은닉층 포함
- 특징 추출과 학습을 함께 진행
- 데이터로부터 효과적인 특징을 학습을 통해 추출 -> 우수한 성능
기울기 소멸 문제
- 은닉층이 많은 MLP에서 출력층에서 아래 층으로 갈수록 전달되는
오차가 크게 줄어 학습이 되지 않는 현상 - 시그모이드나 쌍곡 탄젠트 대신 ReLU(Rectified Linear Unit) 함수 사용
- ReLU 함수 사용과 함수 근사
- 함수를 부분적인 평면 타일들로 근사하는 형해
- 출력이 0이상인 것에 계산되는 결과
- 입력의 선형변환(입력과 가중치 행렬의 곱으로 표현)의 결과

- 입력의 선형변환(입력과 가중치 행렬의 곱으로 표현)의 결과
가중치 초기화
- 신경망의 성능에 큰 영향을 주는 요소
- 보통 가중치의 초기값으로 0에 가까운 무작위 값 사용
- 개선된 가중치 초기화 방법

- 입력 데이터를 제한적 볼츠만 머신을 학습시킨 결과의 가중치 사용
- 인접 층간의 가중치를 직교 행렬로 초기화
과적합 문제
- 완화 기법
- 규제화
- 드롭아웃
- 일정 확률로 노드를 무작위로 선택, 선택된 노드의 앞뒤로 연결된 가중치 연결선은 없는것으로 간주하고 학습
- 주기마다 새로운 노드를 선택해서 학습
- 추론 할 때는 드롭아웃을 하지 않음
- 하나의 신경망안에 다수의 부분 신경망이 학습한 것과 같은 효과
- 배치 정규화
컨볼루션 신경망 (CNN)
- 동물의 시각피질의 구조에서 영감을 받아 만든 딥러닝 신경망 모델
- 특정 영역에 대한 자극만 수용
- 계층적인 정보처리 -> 정보가 계층적으로 처리되어 가면서 추상적인 특징을 추출
- 영상 분류, 문자 인식 등 인식문제에서 높은 성능
- 순서
- 전반부 -> 컨볼루션 연산을 수행해 특징 추출
- 후반부 -> 특징을 이용해서 분류
- 컨볼루션
- 일정 영역의 값들에 대해 가중치를 적용하여 하나의 값을 만드는 연산

- 스트라이드
- 커널을 다음 연산으로 옮기는 칸 수
- 패딩
- 컨볼루션 결과의 크기를 조정하기 위해 입력 배열의 외각의 둘레를 확장하고 0 으로 채움
- 컬러 영상의 컨볼루션
- 원본 = R+G+B 채널의 합
- RGB에 모두 필터를 적용해서 결과를 냄
- 특징 지도
- 필터로 표현되는 특징이 데이터 영역에 얼마나 강하게 존재하는지 평가하는 역할
- 필터의 적용 결과로 만들어지는 2차원 행렬
- 특징지도의 원소값
- 필터에 표현된 특징을 대응하는 위치에 포함하고 있는 정도
- K개의 필터를 적용하면 K개의 2차원 특징지도 생성
- 일정 영역의 값들에 대해 가중치를 적용하여 하나의 값을 만드는 연산
- 풀링
- 일정 크기의 블록을 통합해 하나의 대푯값으로 대체
- 최대값 폴링 -> 블록내 원소들 중 최대값이 대표, 과적합 발생 가능 (가장 많이 사용)
- 평균값 폴링 -> 원소들의 평균값이 대표, 강한 특징의 영향이 상대적으로 약화, 특징의 상쇄 가능
- 확률적 폴링 -> 원소가 원소값의 크기에 비례하는 선택 확률을 갖도록하고 확률에 따라 원소 하나를 선택
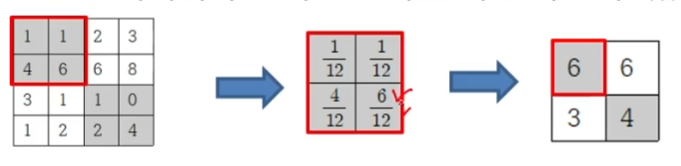
- 동일한 입력이라도 결과가 다를 수 있어, 학습시에만 사용
- 역할
- 중간 연산 과정에서 만들어지는 특징지도들의 크기 축소
- 다음 단계에서 사용될 메모리 크기와 계산량 감소
- 일정 영역내 특징들을 결합, 위치 변화에 강건한 특징 선택
- 중간 연산 과정에서 만들어지는 특징지도들의 크기 축소
- 구조
- 특징 추출을 위한 컨볼루션 부분 -> 아래 3가지를 반복
- 컨볼루션 연산을 하는 Conv층
- ReLU 연산을 하는 ReLU
- (옵션) 풀링 연산
- 추출된 특징으로 분류 또는 회귀를 수행하는 MLP 부분
- 전방향으로 전체 연결된 FC(Fully Connected)층 반복
- 분류의 경우 마지막 층에 소프트맥스 연산을 추가 -> 출력 값이 0이상이면서 합은 1
- 예시
- 학습을 위한 목적함수
- 부류문제
- 교차 엔트로피
- 회귀 문제
- 적용 가능 학습 알고리즘
- 경사 하강법
- 경사 하강법의 변형
- 부류문제
- 특징 추출을 위한 컨볼루션 부분 -> 아래 3가지를 반복


신입 안드로이드 개발자입니다!