현생이 몹시도 다망하여 올해는 더 이상 공부한 내용을 진득히 정리할 시간이 없다고 생각했었다.
다행히도, 2021년을 딱 1주 남겨두고 조금은 여유가 생겨 공부한 내용을 정리할 수 있게 되었다.
1. 포스팅의 목적
이번 포스팅의 목적은 CUDA Programming Model - Memory Hierarchy를 명확히 이해해보는 것이다.
포스팅 내내 앞선 CUDA Thread Hierarchy에서 사용했던 표현들을 동일하게 사용할 것이므로, 원한다면 앞선 포스팅을 먼저 읽고 오는 것이 도움이 될 수 있다.
넓은 안목에서 이해하려는 노력을 하였고, 따라서 일부 비약이 있거나 지엽적인 부분에서 사실과 다른 곳이 있을 수 있다.
2. Programming Model: Memory Hierarchy
각론을 펼치기에 앞서 우선 포스팅에 등장할 키워드들을 쭉 나열해보도록 하겠다.
RegisterLocal MemoryShared MemoryConstant MemoryGlobal Memory
설명없는 나열이었지만, 여느 컴퓨터 아키텍처와 비슷하게 이름만으로도 나름 추정이 가능한 부분이 있으리라!
이제 위에서 나열하였던 각 부분에 대하여 보다 상세하게 살펴보도록 할텐데, 정리하여 기술하는 과정에서 주의하였던 점을 하나 밝히고자 한다.
보통 일반적인 CPU 아키텍쳐에서 Memory Hierarchy를 배우면 "Core 1에는 L1 Cache 12KB가 있어!"와 같이 하드웨어적으로 그 위치와 용량을 정확히 특정할 수 있게 된다.
하지만, 필자가 지금 정리하고자 하는 내용은 CUDA Programming Model로서의 Memory Hierarchy이다.
즉, 하드웨어적인 위치와 용량을 파악하는 것보다는 프로그래밍을 잘 할 수 있도록 "1개 Block에서 사용할 수 있는 Register의 양은 얼마일까?" 와 같이 Programming Model(Block) 관점에서 파악하는 것이 더욱 중요하다.
따라서, 아래 기술에서는 "1개 SM에 Register 몇 개"와 같이 하드웨어적인 내용을 논하기 보다는 "1개 Block에 Register 몇 개"와 같이 Programming Model을 염두에 둔 설명을 진행하는 것을 더 중요한 목표로 삼는다.
2.1. Register
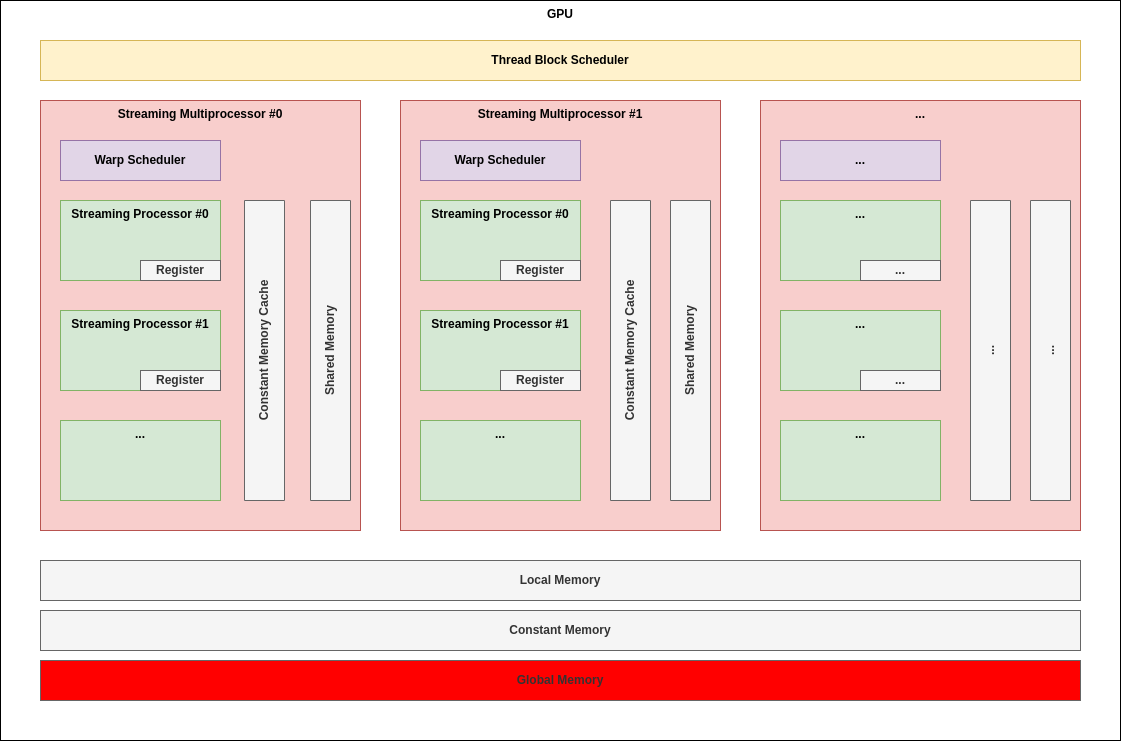
GPU 내에서 가장 접근이 빠른 메모리이다.
Programming Model 관점에서 볼 때, 각 Thread가 독립적으로 사용하는 메모리이다.
아키텍쳐와 연관지어 이해할 때에는 아래 그림이 보이는 것처럼 각 SP(Streaming Processor)에 붙어있는 것으로 이해하면 좋다.
주된 용도는 각 Thread가 사용할 Local Variable들을 저장하는 것이다.

2.2. Local Memory
이름 때문에 오개념을 잡기 쉬운데, 실제로 그다지 지역적이지 않다.
Programming Model 관점에서 볼 때, Register와 유사하게 각 Thread가 독립적으로 사용하는 메모리이다.
아키텍처로 살펴볼 때에는 어디까지나 SM 외부에 존재하는 영역으로 후술할 Global Memory의 접근과 비용 관점에서 큰 차이가 없다.
컴파일 타임에 모든 Local Variable이 상주하기에는 Register가 모자르다고 생각되는 경우, Register Spilling이라는 과정에 의해 Local Memory로 일부 이동되는데, 이때 사용되게 된다.
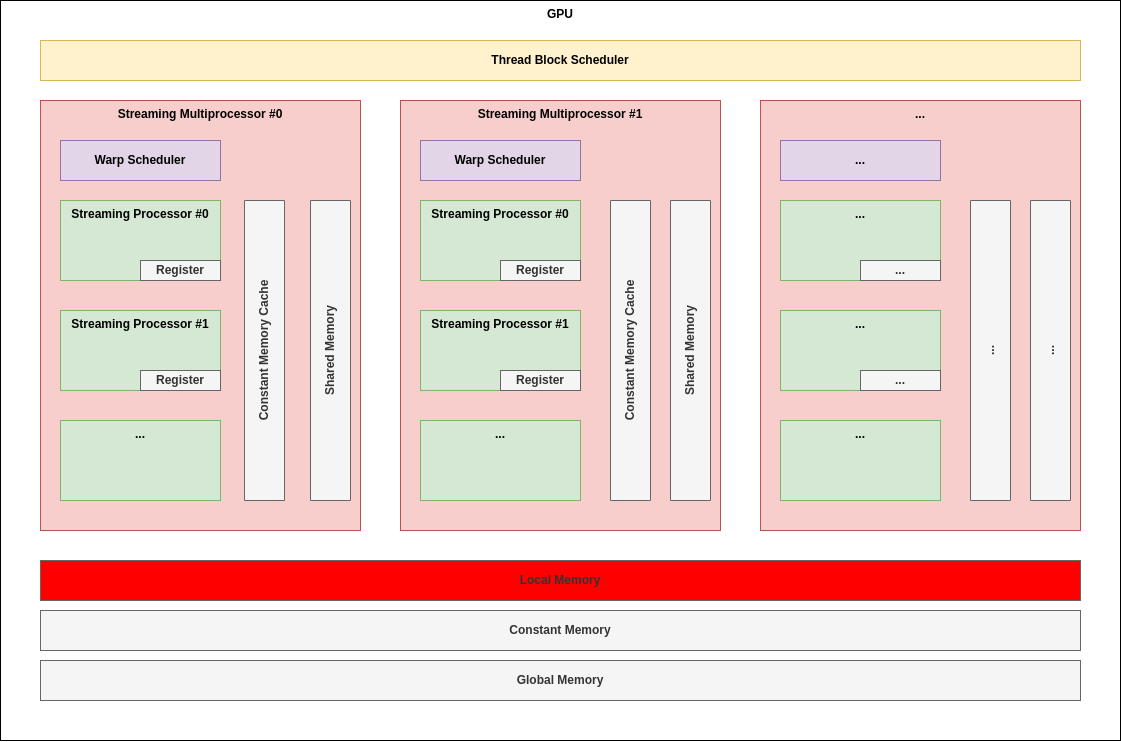
2.3. Shared Memory(Programmable!)
Programming Model 관점에서 볼 때, 하나의 Block 내의 Thread들이 함께 공유하는 메모리이다.
아키텍처 적으로 살펴보면 당연히 각 Block이 할당되는 SM 내에 존재하는 것으로 이해할 수 있다.
이 메모리의 주된 용도는 개발자가 Block 내에 공유하기 원하는 영역을 할당함으로써 Block 내 Thread들이 잘 협력할 수 있도록 하는 것이다.
SM 내에 있으므로 Global Memory를 통한 Thread 간 협력보다는 당연히 더 좋은 효율을 가질 수 밖에 없다.
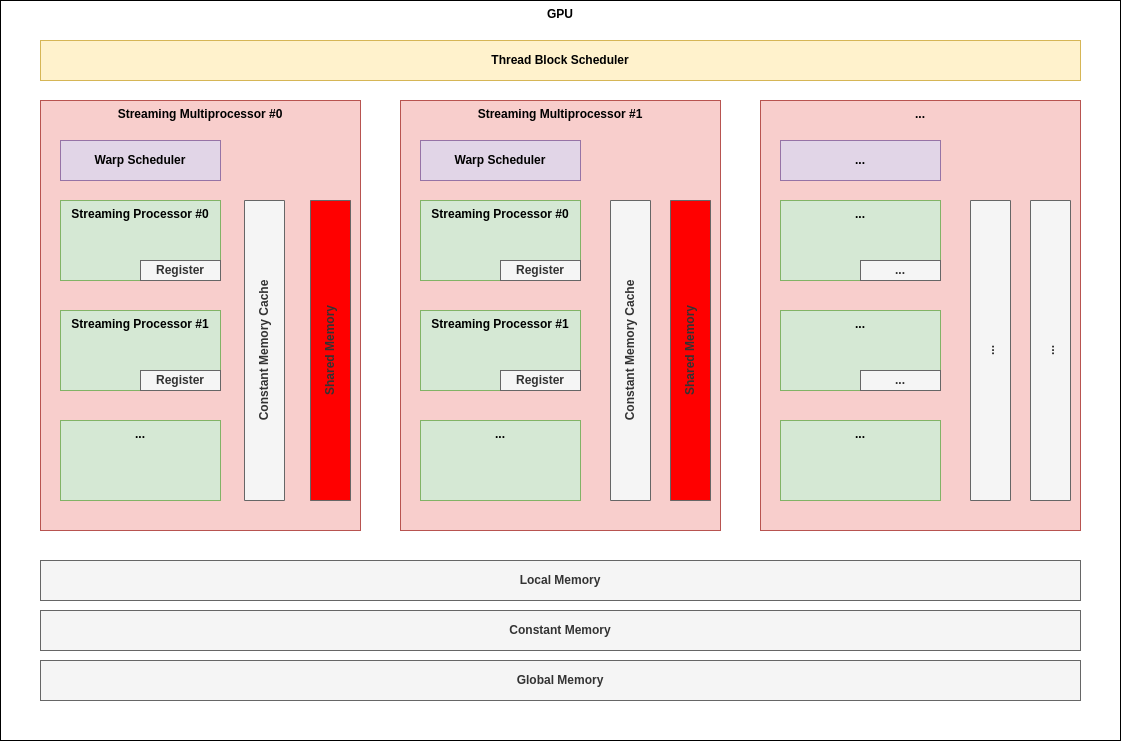
2.4. Constant Memory(Programmable!)
Programming Model 관점에서 볼 때, 모든 Block 내의 모든 Thread(즉, Grid 내의 모든 Thread)가 함께 읽을 수만 있는 RO 메모리이다.
아키텍처 적으로 살펴보면 Global Memory와 유사하게 SM 밖에 있는데, 전용 Cache를 SM 내에 가지고 있다.
이 메모리의 주된 용도는 개발자가 Grid 내에 공유하기 원하는 영역을 할당함으로써 Grid 내 Thread들이 잘 협력할 수 있도록 하는 것이다.
아무래도 RO 영역이다보니 Caching 성능이 뛰어나므로 Global Memory를 사용하는 것 보다는 높은 Bandwidth를 기대할 수 있다.
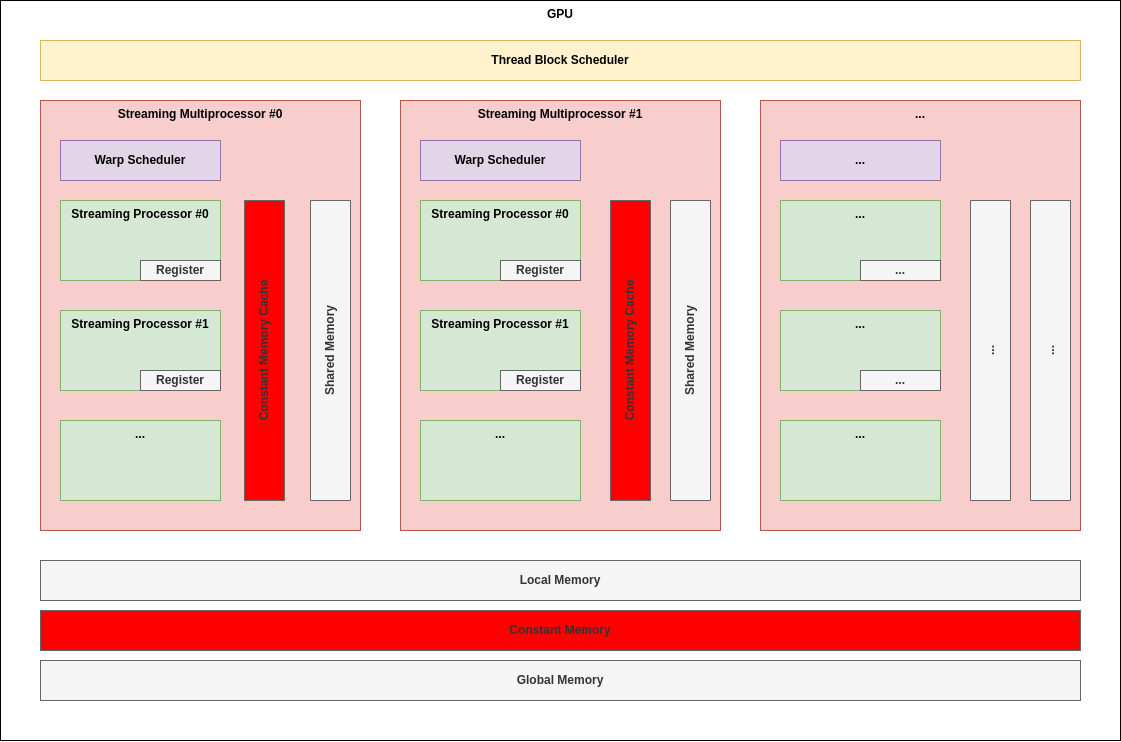
2.5. Global Memory(Programmable!)
Programming Model 관점에서 볼 때, 모든 Block 내의 모든 Thread(즉, Grid 내의 모든 Thread)가 함께 읽고 쓸 수 있는 메모리이다.
아키텍쳐적으로 살펴보면 SM 외부에 존재한다.
이 메모리의 주된 용도는 연산을 원하는 워크로드(즉, cudaMemcpy를 통해 Host -> Device 또는 Device -> Host로 이동하는 데이터)를 저장하기 위하여 사용된다.