컴퓨터의 메모리를 비유로 설명하는 많은 예가 있지만, 말 그대로 메모리는 정보를 저장하는 공간이며 메모리는 세포의 배열로 이루어져 있다고 상상하면 될 듯 하다.. 각 세포는 정보를 담고 있는데 일반적으로 이 정보의 크기는 1바이트(8비트)이다. 각 세포는 특정 주소를 갖고 있는데, 이 주소로 가면 세포가 가진 정보를 읽거나 다른 값을 쓸 수 있다. 하지만 세포에 저장하려는 값이 한 세포의 크기은 1바이트 보다 크면 어떻게 될까? 그때 고려해야 할 사항이 정보가 메모리에 저장되는 순서를 결정하는 것이다.
- 리틀 엔디안 vs 빅 엔디안
이 두 용어의 목적은 바이트가 메모리에 저장되는 순서를 결정하는 것이다.
Big-endian은 가장 큰 값을 가장 낮은 스토리지 주소에 저장하고 little-endian은 그 반대이다.
예)
decimalValue: Int16 = 20306 // 01001111 01010010이 비트를 1바이트 크기로 분할하면,
firstPart = 01001111
secondPart = 01010010이 값들을 메모리에 할당하려면 두 개의 스토리지가 필요.
- 빅 엔디안 방식의 메모리 할당
메모리 주소 주소와 관련된 값
oxooooooo112856f55 01001111
0x0000000112856f56 01010010- 리틀 엔디안 방식의 메모리 할당
메모리 주소 주소와 관련된 값
oxooooooo112856f55 01010010
0x0000000112856f56 01001111빅 엔디안 방식은 왼쪽에서 오른쪽으로 읽기에 읽는 이에게 좀 더 자연스러운 방식이지만, 단점은 숫자를 늘리기 힘들다. 일반적인 바이너리 시스템은 숫자가 증가하면 왼쪽에 추가되기 때문. 예를 들어,
bin: 1111 == dex: 15
bin: 0001 1111 == dec: 31바이너리 시스템은 증가하는 수가 왼쪽 끝에 추가되기 때문에, 빅 엔디안 방식을 사용 시 메모리에 숫자를 증가시키면 빅 엔디안 표기법에 따라 모든 주소 값을 다시 써야한다.
리틀 엔디안은 빅 엔디안과 반대로 증가하는 수가 오른쪽 끝에 추가된다.
또 다른 예로 빅 엔디안과 리틀 엔디안 방식을 설명하자면,
1) decimalValue = 255 // bin: 1111 1111
2) decimalValue += 256 // bin: 0000 0001 1111 1111, dec: 511- 빅 엔디안
1) decimalValue
메모리 주소 주소와 관련된 값
oxooooooo112856f55 111111112) decimalValue
메모리 주소 주소와 관련된 값
oxooooooo112856f55 00000001
oxooooooo112856f56 11111111빅 엔디안 사용 시 메모리 주소와 관련된 값을 증가시키면, 메모리 주소가 새롭게 할당되는 것을 볼 수 있다. 기존 oxooooooo112856f55 주소의 11111111 값의 숫자가 증가되자, 값 00000001로 다시 쓰여지고 값 11111111은 주소 oxooooooo112856f56으로 할당되었다.
- 리틀 엔디안
1) decimalValue
메모리 주소 주소와 관련된 값
oxooooooo112856f55 111111112) decimalValue
메모리 주소 주소와 관련된 값
oxooooooo112856f55 11111111
oxooooooo112856f56 00000001리틀 엔디안 방식 사용 시 메모리 주소와 관련된 값을 증가시키면 새로운 메모리 주소에 새 값이 할당된다.
- XCode에서 메모리 저장 방식 확인하기
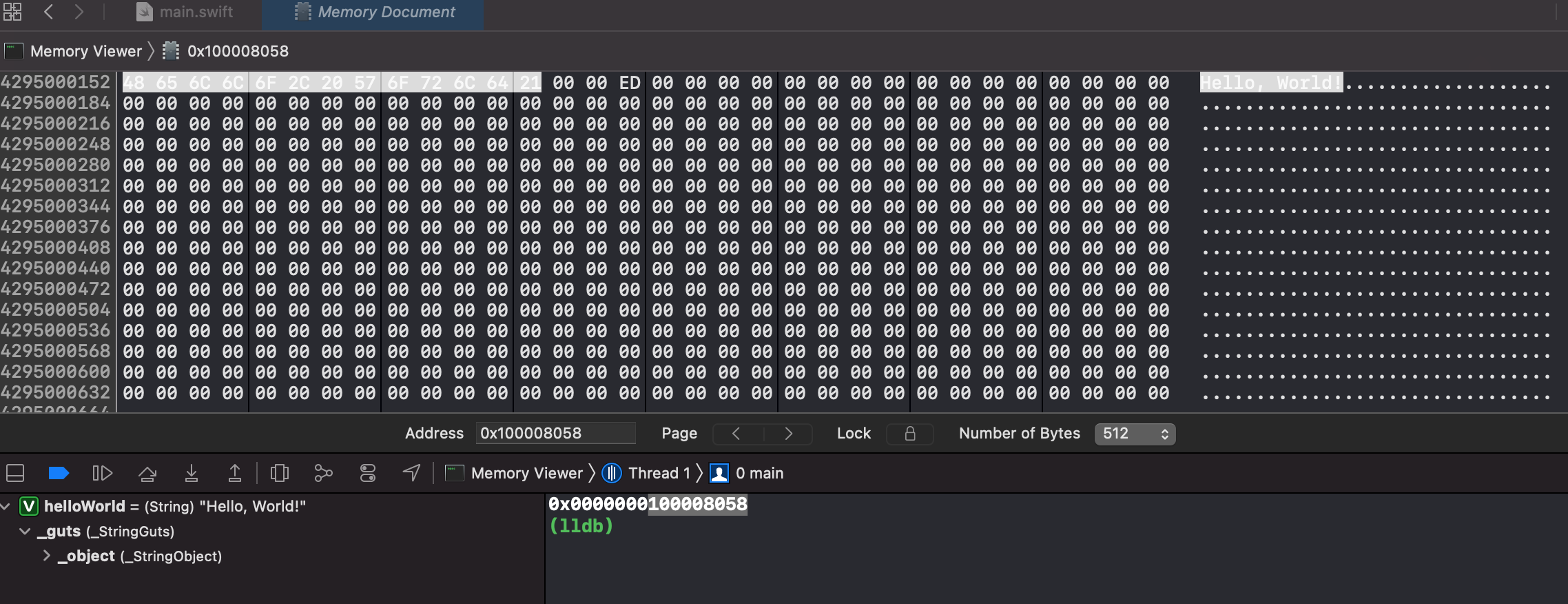
Hello, World! 라는 문자열을 변수를 메모리에 담고 주소를 확인해보았다. H의 ASCII코드인 48부터 !인 21까지 13바이트가 리틀 엔디안 방식으로 저장이 되었고, 실제로 64비트 시스템의 문자열 크기는 2바이트이기에 충분히 메모리에 잘 담겨 있는 것을 볼 수 있다. 테스트 해보니 문자열이 2바이트가 넘어가니 주소가 문자열 다음부터 할당되는 것이 아닌 것을 확인했다.(이 부분을 더 파봐야..)
참조 :
https://dev.to/michalrogowski/memory-management-swift-266b
(메모리를 보며, clas와 struct 재사용을 설명하는 파트가 추가로 더 있으므로 공부 필요..)
