♣ 오늘 LMS 노드 9는 어제에 이어서 pandas, matplotlib, numpy와 같은 파이썬 라이브러리를 활용한 데이터 분석에 대해서 이어서 학습하는 노드입니다. 데이터 분석 과정에서 대부분의 비중을 차지하는 데이터 전처리에 대해 다루고 있는 노드입니다.
♣ 데이터 전처리가 데이터 분석과정에서 매우 중요한 만큼 다른 노드에 비해 좀 더 꼼꼼히 읽고 정리하느라 오늘 LMS노드는 9.4절의 내용까지만 정리했음을 알려드려요!
Sequence 1. LMS (9.1~9.4절)
A. 결측치 (Missing Data)
- 데이터 전처리 : 모델에 데이터를 투입하기 전까지의 전 과정을 아울러 이른다.
- 전처리가 충분히 되지 않았거나 잘못된 데이터를 사용하는 경우 분석 결과의 질이나 신뢰도뿐만 아니라 예측 모델에 대한 정확도도 떨어질 수 있으므로, 데이터 분석에 있어 전처리는 필수 코스이다.
- 주로 사용되는 용어들 : 결측치, 중복된 데이터, 이상치, 정규화, 원-핫 인코딩, 구간화
- 현실에서 다루는 데이터에는 결측치가 포함되는 경우가 꽤 있다. 데이터를 수집하는 과정에서 누락되지 않는 것이 가장 Best이긴 하나, 결측치가 존재한다면 처리하는 과정이 필요하다.
- 결측치 처리 방법 2가지 : 결측치가 있는 데이터 삭제, 결측치를 공통의 값으로 대체
- 결측치를 처리할 때에는 분석하고자 하는 데이터의 특성에 따라 유연하게 해결하는 것이 좋다.
- 데이터프레임 이름.drop('공지사항', axis=1) : 데이터프레임 내 '공지사항' 컬럼을 삭제하는 메서드
- DataFrame.isnull() : 각 데이터마다 결측치가 있으면 True, 아니면 False로 반환
- DataFrame.any(axis=1) : 행마다 하나라도 True가 있으면 True, 아니면 False로 반환
- (9번 내용에 대한 보충내용) axis=0 : 함수가 열단위로 적용 / axis=1 : 함수가 행단위로 적용
- 아래와 같은 결론이 나오는 이유 : index 191의 경우 일부 항목에 대해서만 결측치여서 replace 방법을 이용하여 어느 정도 해결이 가능하지만, index 196, 197, 198의 경우에는 모든 항목이 결측치이므로 아예 제거하는 것이 효과적인 처리이기 때문
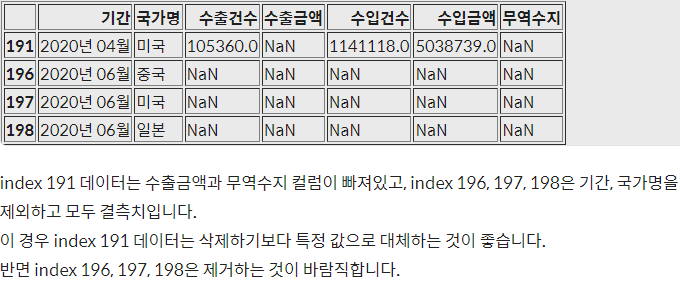
- 아래 코드는 dropna() 메서드를 이용해 결측치를 삭제하고 inplace=True 옵션으로 변경된 내용을 데이터프레임 내부에 바로 적용시킨 것이다.
trade.dropna(how='all', subset=['수출건수', '수출금액', '수입건수', '수입금액', '무역수지'], inplace=True)- (참고) 시계열 데이터 : 통계숫자를 시간의 흐름에 따라 일정한 간격마다 기록한 통계 데이터이다.
- 시계열 특성을 띤 데이터는 앞뒤 데이터를 통해 결측치를 대체할 수 있다.
- 이상 내용은 수치형 데이터의 결측치 삭제 및 대체에 대한 내용으로, 범주형 데이터의 경우 새로운 범주로 대체하거나 결측치가 적은 경우 최빈값으로 대체하거나 시계열 데이터일 경우 앞뒤 데이터를 기반으로 결측치를 대체할 수도 있다.
B. 중복된 데이터
- DataFrame.duplicated() : 중복된 데이터가 있는지 없는지를 불(Boolean) 값으로 반환
- DataFrame.drop_duplicates() : 중복된 데이터를 삭제하는 메서드
- id가 중복인 데이터가 2개인데, 만일 id값이 사람마다 반드시 unique하다는 조건이 붙으면 둘 중 하나는 반드시 삭제해야 한다.
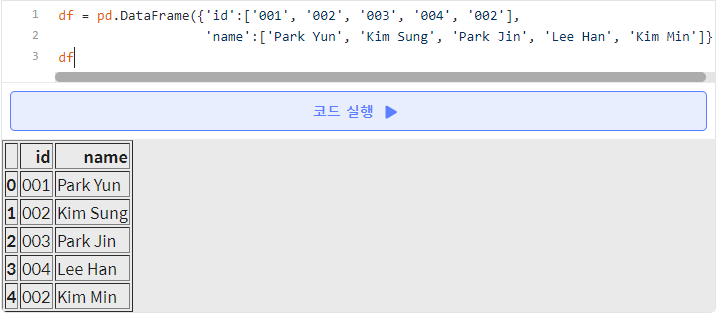
- 보통은 index 값이 클수록 가장 나중에 들어온 데이터이다.
- id가 중복된 경우에는 가장 나중의 값만을 남긴다.
★ 참고자료 : 데이터프레임 결측치 삭제,중복
C. 이상치 (Outlier)
- 대부분이 차지하는 값의 범위를 벗어나 극도로 크거나 작은 수치를 나타내는 데이터를 말한다.
- 이상치를 찾아내는 가장 간단하지만 자주 사용되는 방법 : 평균과 표준편차를 이용한 Z-score 방법이다.
- trade.loc[outlier(trade, '찾고자 하는 컬럼', z)] 코드에서 z의 값은 기준치이며, 이 값이 클수록 이상치와 그 개수가 적어질 수 있다.
- IQR을 활용한 이상치 처리 - 상자그림 : 이상치 확인 (그림에서 박스를 벗어난 점들이 이상치에 해당되는 점들이다.)
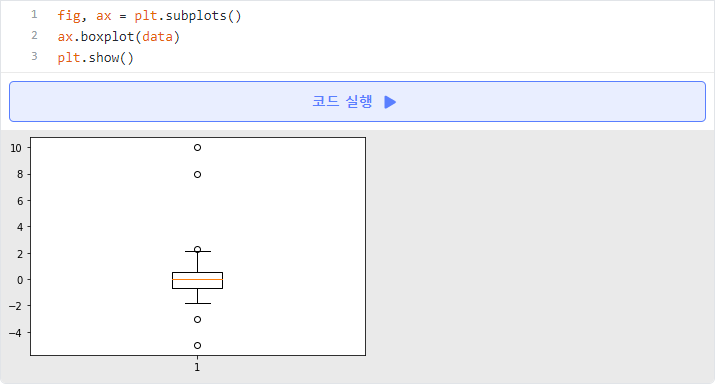
- IQR(Interquartile range) : 사분위범위수, 데이터의 중간 50% 범위를 말한다.
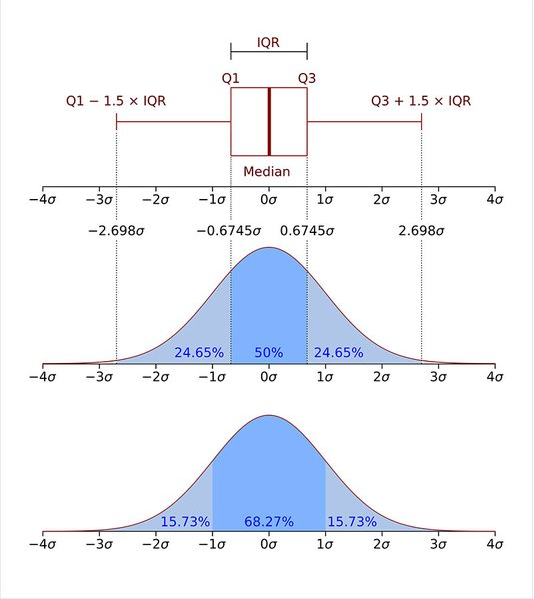
- IQR 계산 공식 : Q3-Q1 (Q3는 제 3사분위수, Q1은 제 1사분위수이다.)
- 아래 그림과 같이 Q1-1.5IQR 보다 왼쪽이거나 Q3+1.5IQR 보다 오른쪽에 있는 수치들을 이상치라고 판단한다.
- 이상치 처리 예시코드 해석
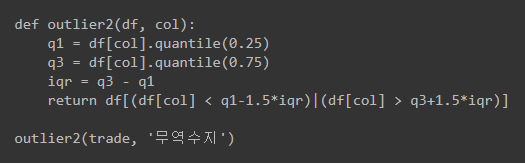
- df, col에 대해 정의된 함수 outlier2에 대하여 Q1, Q3, IQR의 식이 주어졌을 때 이상치 조건을 만족하는 것을 모두 찾는다.
Sequence 2. Python Master
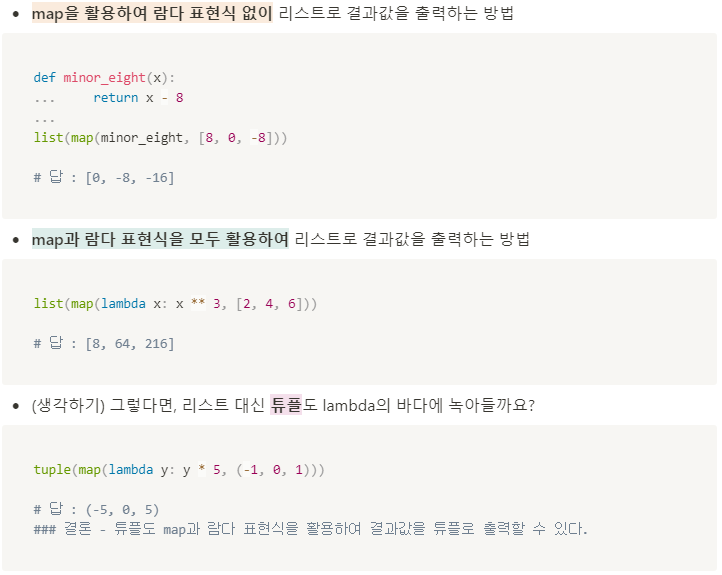
♣ 파이썬마스터 같은 경우에는 33장 클로저 부분에서 다소 어려움을 느끼면서 이야기 조각만 남긴 채 끝이 났고, 저도 정리하려다 시간이 부족해서 그냥 내일 다시 정리하기로 했습니다..ㅠ 그래서 32장 람다표현식 부분을 열심히 팠다는 건 안 비밀..?



날개를 달고 날아오르자!