정의
다양한 독립변수들을 가지고 종속변수를 예측하는 것이다.
변수들간의 상관관계를 통해 종속변수의 값이 예측된다.
방법1. 데이터 세트 분리하여 모델 적용
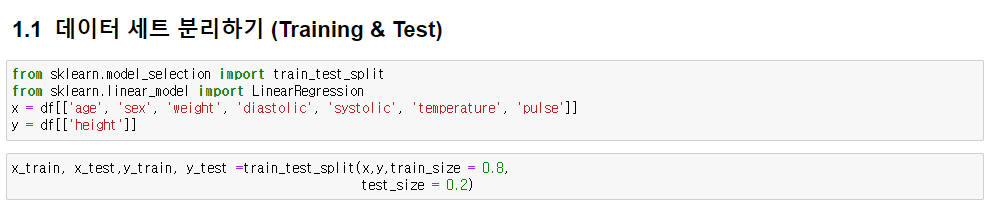
데이터 세트 분리하기 (Training & Test)
가지고 있는 데이터를 모두 사용해서 다중선형회귀 모델을 만들 수도 있지만, 우리는 실제로 생성한 모델이 잘 예측하는지 테스트를 해보기 위해 학습(train) 데이터와 시험(test) 데이터를 분리
데이터 세트 분리는 sklearn에서 train_test_split을 통해 손쉽게 할 수 있다.
아래와 같이 8:2 정도의 비율로 나눠보자.
모델 생성하기
학습데이터인 train데이터를 가지고 모델을 생성

키에 대한 6개의 항목값을 넣어주면 키가 몇인지 예측해주는 것
- 여기에서 6개의 항목값은 위 x값에 넣어준 항목!

x 시험 데이터 x_test를 넣어 예측한 y 값들을 y_predict라고 저장하기
- 추후에 시험 데이터에 있는 실제 정답, 즉
y_test와 비교해보기 위함이다.
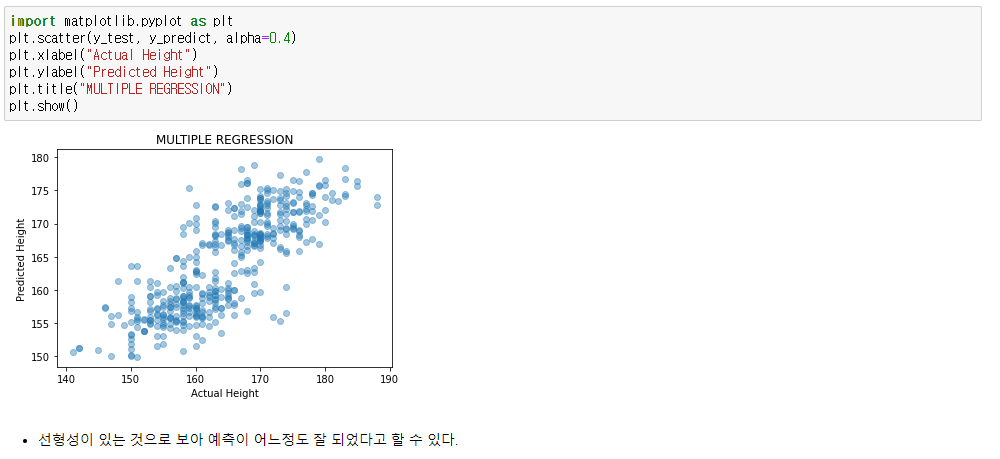
y_predict = linear.predict(x_test)x축은 실제 키, y축은 예측한 키
- 에측을 정확히 했다면 정확한 선으로 일치되어 나올 것이다.
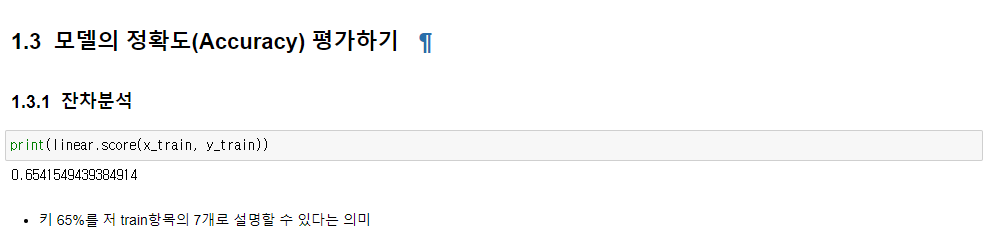
모델 정확도 평가하기
- 결정계수 R²가 클수록 실제값과 예측값이 유사함을 의미하며, 데이터를 잘 설명
방법2. OLS
OLS 검정

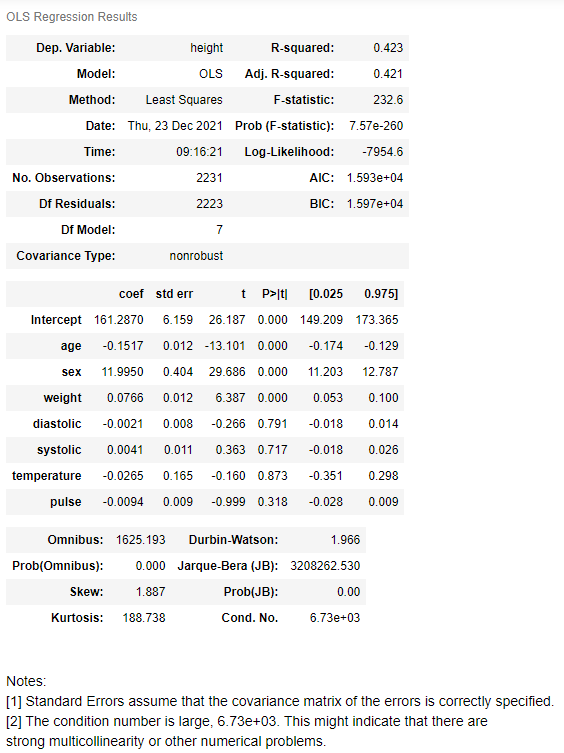
- R-squred, Adj.R-squred : 보통 설명력이라고 말하는 값인데 주어진 데이터를 현재 모형이 얼마나 잘 설명하고 있는지를 나타내는 지수입니다. 단 R-squared는 독립변수가 추가될 수 록 증가하는 값이라 Adj.R-squared 값을 더 많이 봅니다. 보통 0.7이상인 경우 설명력이 높다고 봅니다.
- Prob(F-statistics) : 모형에 대한 p-value 로 통상 0.05이하인 경우 통계적으로 유의하다고 판단합니다.
- P>[t] : 각 독립변수의 계수에 대한 p-value로 해당 독립변수가 유의미한지 판단합니다.
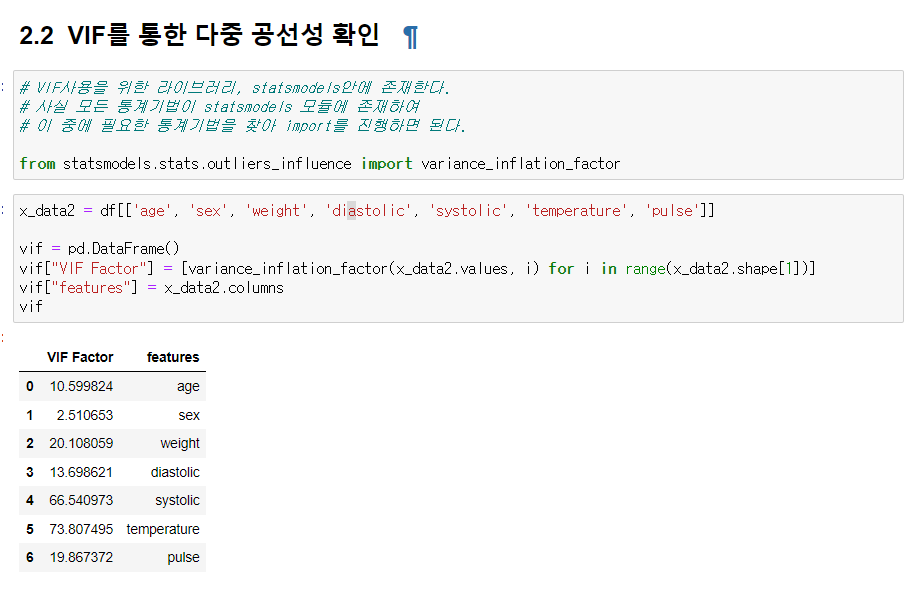
VIF를 통한 다중 공선성 확인
- VIF는 variance inflation factor의 줄임말로, 다중공선성을 확인할 때 쓰는 지표 중 하나다. variance inflation factor는 말그대로 "분산팽창요인"이다. 보통은 VIF가 10보다 크면 다중공선성이 있다고 판단한다. 하지만, 다른 과정을 함께 거쳐주는 것이 다중공선성 문제 확인의 신뢰성을 높인다.
mse값 도출

