contents
- 이상치, 결측치란?
- 결측치 파헤쳐보기
- 이상치 파헤쳐보기
summary
- 이상치, 결측치란?
🚩 이상치: 전체 데이터 범위에서 벗어난 아주 작은 값이나 큰 값.
🚩 결측치: 데이터 수집 과정에서 측정되지 않거나 누락된 데이터.
*데이터를 분석을 위한 EDA 시, 필수적으로 진행되어야 한다.
-Data Cleaning 또는 데이터 정제.
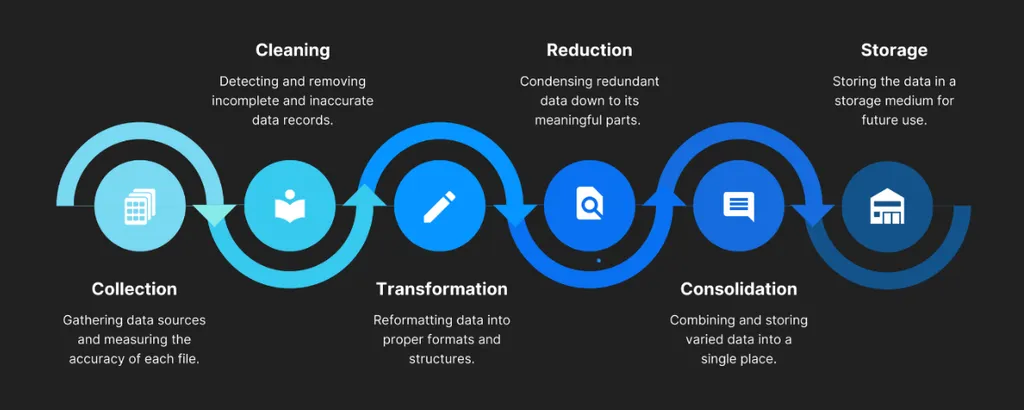
- 결측치 파헤쳐보기
:말 그대로 데이터의 누락된 부분
데이터 처리 과정
수집-로우데이터-테이블로 저장.
[raw data]

로우 데이터들은 규칙에 맞게 CLUSTER 에 할당되고, RDBMS 를 통해 테이블로 저장!
이 과정에서 데이터가 누락될 수 있고, 이러한 데이터들을 알맞게 처리하는 과정이 필요하다.
- 결측치 처리 - 제거
:결측치가 존재하는 행 또는 열을 제거한다.
# 컬럼별 결측치 식별
df3.isnull().sum()
->각 컬럼별로 몇개의 결측치가 있는지 확인할 수 있다.
# 결측치 제거1 - 열 제거하기 (굉장히 위험한 행위)
df3 = df3.drop('Unnamed: 4', axis=1)
# 결측치 제거2 - 결측치가 있는 행들은 모두 제거(가장 많이 사용!)
df3.dropna()
# 같은 표현
df3.dropna(axis=0, how='any')
# 결측치 제거3 - 결측치가 있는 열을 모두 제거
# 열로 제거하면 컬럼이 제거되는 현상이 발생하므로 매우 위험합니다.
# df3.dropna(axis=1)
->데이터의 컬럼이 다 널이 경우는 사용할 수 있다.
# 결측치 제거4 - 전체 행이 결측값인 경우만 삭제하고 싶은 경우
# how='all'을 사용해줍니다.
df3.dropna(how='all')
# 결측치 제거5 - 결측치 제거 후 결과를 바로 저장하고 싶을 때
# inplace=True 조건을 넣어줍니다.
df3.dropna(inplace=True)
-> 전처리 이후 새로 선언해줘야하는데 inplace의 경우는 그러한 과정을 생략할 수 있다.
(이전의 데이터가 갱신되는것이다.)
이전의데이터 프레임을 더이상보지 않을경우 사용.
# drop 이후 결측치가 잘 제거되었는지 체크가 필요하겠죠?
df3.isnull().sum()- 결측치 처리 - 대체
- 최빈값: 범주형 변수에 주로 사용됩니다. **데이터가 가장 많이 도출된 값으로 대체해 줄 수 있다.
-중앙값, 평균값:** 수치형 변수에 주로 사용합니다. 결측치에 평균값이나 중앙값을 넣어준다.
-그 외에 행 기준으로 바로 위나 아래의 값을, 또는 group by 연산의 결과로 대체할 수 있다.
# 결측치 대체: 최빈값
# mode 는 최빈값을 의미
# df3 의 Interaction type 컬럼을 fillna함수를 이용하여 채워주되, mode() 함수를 사용하여 최빈값으로 넣어줌
# mode 함수는 시리즈를 output으로 가집니다.
# 따라서,[0]을 통해 시리즈 중 단일값을 가져와야 합니다.
df3 = df3['Interaction type'].fillna(df3['Interaction type'].mode()[0])
->시리즈로 출력되기에 [0]을 넣어준다.
['Interaction type']컬럼의 .mode()최빈값을 .fillna빈곳에 채워줘!
# 결측치 대체: 평균값
df['sw'] = df['sw'].fillna(df['sw'].mean())
df.isnull().sum()
# 결측치 대체: 중간값
# inplace=True 로 하면 원본 데이터가 바뀌게 됩니다.
df['sw'] = df['sw'].fillna(df['sw'].median())
df.isnull().sum()
->평균과 중간값은 항상 같이 봐야함.
# 결측치 대체: 바로 위 값으로 대체(method='ffill')
df['sw'] = df['sw'].fillna(method='ffill')
df.isnull().sum()
# 결측치 대체: 바로 아래 값으로 대체(method='bfill')
df['sw'] = df['sw'].fillna(method='bfill')
#df.isnull().sum()
# 결측치 대체: group by 값으로 대체
# 사전 데이터 확인
df.groupby('Is Amazon Seller')['sw'].median()
# group by한 데이터를 데이터프레임의 컬럼으로 추가하기 위해
#그룹별로 다른 값을 대체하고 싶을때 사용한다.
# transform 함수 사용
df['sw'] = df['sw'].fillna(df.groupby('Is Amazon Seller')['sw'].transform('median'))
df.isnull().sum()
->df['sw'].fillna(df.groupby('기준컬럼')['계산할 컬럼'].transform('계산방식'))- 이상치 파헤쳐보기
: 이상치에 대한 기준이 없고, 처리 방식에 따라 이상치의 갯수가 변한다.(정해진 정답이 없음)
*특히 비지도학습으로 데이터 분석을 진행할때는 통계적 기법과 데이터분석가의 주관이 적절히 조화를 이루며 분석을 진행해야한다.
- 이상치 식별: Z-Score(StandardScaler)
:평균으로부터 얼마나 떨어져 있는가? 를 통한 이상치 판별. (전제:데이터의 분포가 정규 분포를 이룰 때, 데이터의 표준 편차를 이용해 이상치를 탐지하는 방법). python의 scikit-learn라이브러리가 이를 지원한다.
*정규분포
보통의 분포: 대칭분포!
-각 데이터(행) 마다 Z-score 를 구한다. Z 값은 X에서 평균을 뺀 데이터를 표준편차로 나눈 값이며, 표준 점수라고 부른다.
-표준 점수는 평균으로부터 얼마나 멀리 떨어져 있는지를 보여주며, 일반적으로 -3에서 3 사이의 값을 가지고 있다. ±3 이상이면 이상치로 간주한다.
-Z-Score : 0 해당 데이터는 평균과 같음을 의미. (=평균에서 떨어진 거리가 0)
-Z-Score > 0 : 해당 데이터 평균보다 큼. Z-Score가 1이면, 해당 데이터 포인트는 평균보다 1 표준편차만큼 더 큰 값임을 의미.
-Z-Score > 0 : 해당 데이터는 평균보다 작음. Z-Score가 -1이면, 해당 데이터 포인트는 평균보다 1 표준편차만큼 더 작음을 의미.
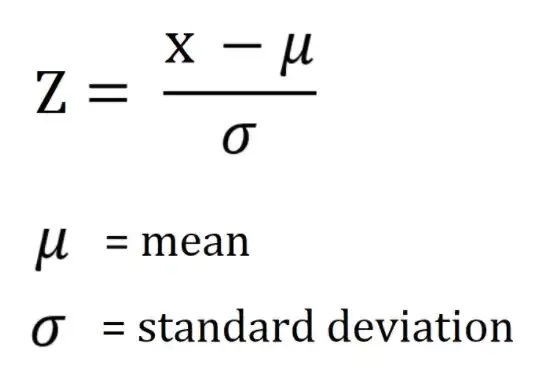
# df 의 Shipping Weight를 기준으로 다양한 이상치 감지 기법을 적용해 보겠습니다.
df = pd.read_csv("p.csv")
# string -> float -> int
df['sw'] = df['Shipping Weight'].str.split().str[0]
df['sw'] = pd.to_numeric(df['sw'] , errors='coerce').fillna(0.0).astype(int)
# z-score 를 적용할 컬럼 선정
df1 = df[['sw']]
# 표준화 진행
# 표준화 : 평균을 0으로, 표준 편차를 1로
# 데이터를 0을 중심으로 양쪽으로 데이터를 분포시키는 방법
# 표준화를 하게 되면 각 데이터들은 평균을 기준으로 얼마나 떨여져 있는지를 나타내는 값으로 변환
scale_df = StandardScaler().fit_transform(df1)
merge_df = pd.concat([df1, pd.DataFrame(StandardScaler().fit_transform(df1))],axis=1)
merge_df.columns = ['Shipping Weight', 'zscore']
# 이상치 감지
# Z-SCORE 기반, -3 보다 작거나 3보다 큰 경우를 이상치로 판별
mask = ((merge_df['zscore']<-3) | (merge_df['zscore']>3))
# mask 메소드 사용
strange_df = merge_df[mask]
# 총 55 건 탐지
strange_df.count()- 이상치 식별: IQR(Interquartile Range)
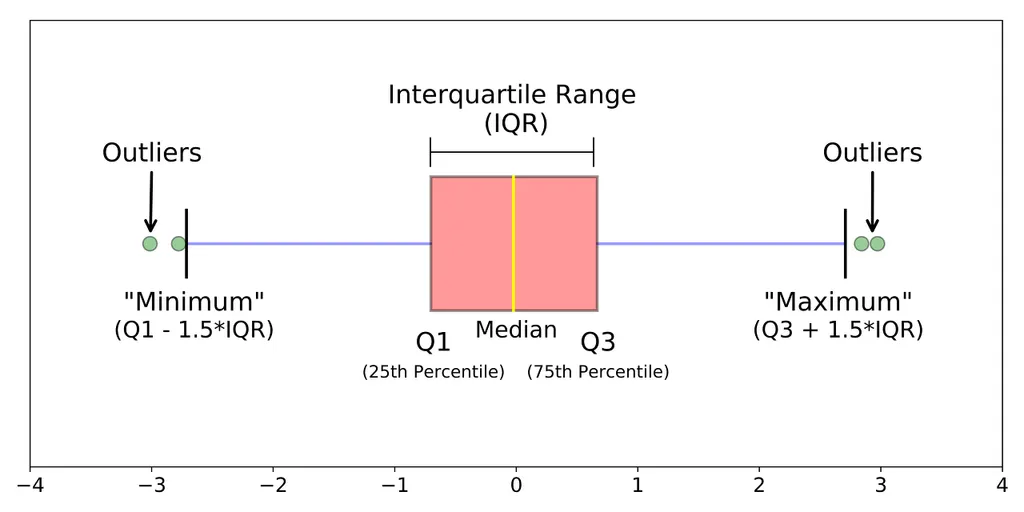
:데이터의 분포가 정규 분포를 이루지 않을 때 사용한다.
-데이터의 25% 지점()과 75% 지점() 사이의 범위()를 사용. 이를 벗어나는 값들은 모두 이상치로 간주.
-이를 그림으로 그린 것이 Box Plot 이며, IQR 밖의 데이터 포인트는 이상치로 표시.
-IQR : (제 3사분위 값) - (제 1사분위 값)
# df 의 Shipping Weight를 기준으로 다양한 이상치 감지 기법을 적용해 보겠습니다.
df = pd.read_csv("p.csv")
# string -> float -> int
df['sw'] = df['Shipping Weight'].str.split().str[0]
df['sw'] = pd.to_numeric(df['sw'] , errors='coerce').fillna(0.0).astype(int)
# 이상치를 감지할 컬럼 선정
df1 = df[['sw']]
# Q3, Q1, IQR 값 구하기
# 백분위수를 구해주는 quantile 함수를 적용하여 쉽게 구할 수 있음
# 데이터프레임 전체 혹은 특정 열에 대하여 모두 적용이 가능
q3 = df1['sw'].quantile(0.75)
q1 = df1['sw'].quantile(0.25)
iqr = q3 - q1
q3, q1, iqr
# 이상치 판별 및 dataframe 저장
# Q3 : 100개의 데이터로 가정 시, 25번째로 높은 값에 해당합니다.
# Q1 : 100개의 데이터로 가정 시, 75번째로 높은 값에 해당합니다.
# IQR : Q3 - Q1의 차이를 의미합니다.
# 이상치 : Q3 + 1.5 * IQR보다 높거나 Q1 - 1.5 * IQR보다 낮은 값을 의미
def is_outlier(df1):
score = df1['sw']
if score > 7 + (1.5 * 6) or score < 1 - (1.5 * 6):
return '이상치'
else:
return '이상치아님'
# apply 함수를 통하여 각 값의 이상치 여부를 찾고 새로운 열에 결과 저장
df1['이상치여부'] = df1.apply(is_outlier, axis = 1) # axis = 1 지정 필수
# IQR 방식으로 구한 이상치 개수는 349 개
df1.groupby('이상치여부').count()*IQR(Interquartile Range)는 정해진 룰이 있기때문에 변경필요없이 그래도 사용한다!
- 선택영역
-
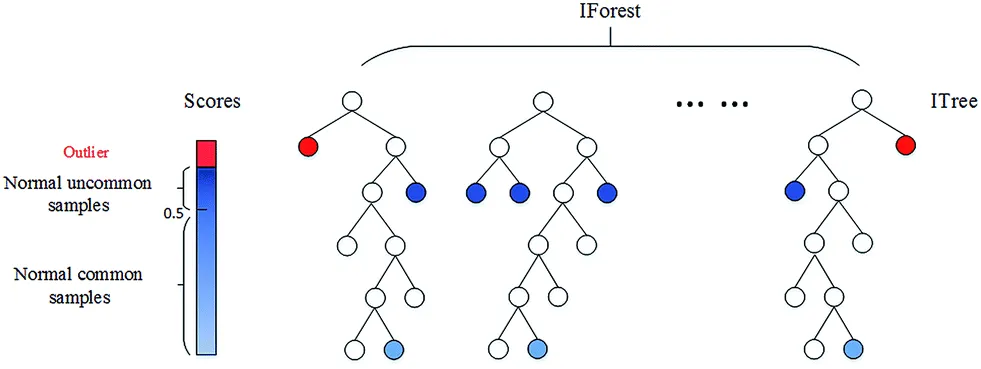
이상치 식별: Isolation Forest
-머신러닝 기법 중 하나로, 컬럼 갯수가 많을 때 이상치를 판별하기 용이.
-데이터셋을 결정트리 형태로 표현.
하지만 이상치의 경우, 이 어디에도 속하지 않을 확률이 높아 구분되지 않는다.
-한 번 분리될 때 마다 경로 길이가 부여되며, 트리에서 몇 번을 분리해야 하는지 (데이터까지의 경로 길이)를 기준으로 데이터가 이상치인지 아닌지를 판단하게 된다!
-즉 이상치는 다른 관측치에 비해 짧은 경로 길이를 가진 데이터! 😎
경로 길이로 점수는 0 에서 1 사이로 산출되며, 결과가 1 에 가까울수록 이상치로 간주.
-
이상치 식별: DBScan
:밀도 기반의 클러스터링 알고리즘으로 어떠한 클러스터에도 포함되지 않는 데이터를 이상치로 탐지하는 방법. 복잡한 구조의 데이터에서 이상치를 판별하는 데 유용.
-주로 지리 데이터 분석, 이미지 데이터 분석의 이상치 기법으로 사용.
-각 데이터의 밀도를 기반으로 군집을 형성시키고, 설정된 거리 내에 설정된 최소 개수의 다른 포인트가 있을 경우, 해당 포인트는 핵심 포인트로 간주.
-핵심 포인트들이 서로 연결되어 군집을 형성하며, 이와 연결되지 않은 포인트는 이상치로 분류.
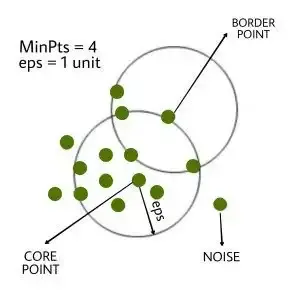
즉, 어떤 군집에도 포함되지 않는 것을 이상치로 본다고 이해. -
이상치 처리(제거랑 분리를 제일 많이 사용)
🚩 제거
:이상치가 데이터 오류나 적절하지 않은 값일 경우 제거. 하지만 이 방식은 데이터의 표본 크기를 줄일 수 있다는 점을 꼭 기억!
🚩 대체
-로그 변환: 데이터에 로그 변환을 적용하여 극단적인 값을 완화할 수 있다.
- 상한값과 하한값: 하한값과 상한값을 결정한 후 하한값보다 적으면 하한값으로 대체, 상한값보다 크면 상한값으로 대체할 수 있다.
- 평균 절대 편차: 중위수로부터 n편차 큰 값을 대체. (자주 사용하지 않음)
🚩 분리
:이상치를 별도의 그룹으로 분리하여 분석할 수 있으며, 이상치가 데이터에 중요한 정보를 포함하고 있을 때 유용.
즉, 새로운 데이터프레임을 생성하여 이상치를 저장해둔다고 이해.
key points
파이썬을 활용한 데이터 전처리!
데이터 전처리는 가장 중요한 과정이고, 가장 많은 소요시간을 소비하는 과정으로 중요한데, 오늘은 이상치와 결측치의 개념과 그들을 제거하는 방법에 대해 배웠다.
별 어려운 내용은 없었고, adsp를 공부하면서 필요가 있는 정보일까하는 생각을 많이했는데 데이터 분석을 하기위해 알아야하는 개념으로 나오는 지식들이라 배운게 나름 유용했다.
