파이썬 라이브러리를 활용해 데이터 분석하기
사용한 파일: flight_data_homework.csv
데이터 불러오기
Python 라이브러리를 활용하여, 구글 드라이브의 CSV 파일을 데이터프레임으로 읽어오는 코드를 작성해주세요.
테이블의 행과 열 개수를 확인해주세요.
테이블의 처음 5줄을 확인해주세요.
1)먼저, 필요한 라이브러리 불러오기.
import pandas as pd
import numpy as np
from datetime import datetime, timedelta2)데이터 불러오기.
df = pd.read_csv("/content/drive/MyDrive/코랩랩/flight_data_homework.csv")
df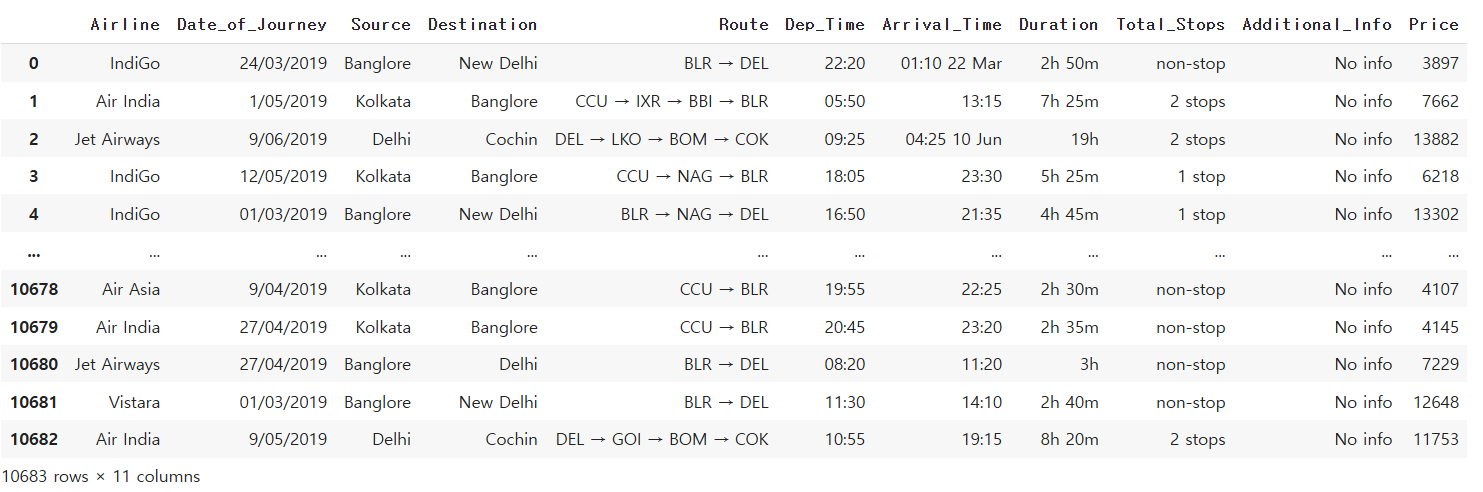
3)테이블 열과 행 갯수
df.shape(10683, 11)
4)처음 5 줄만 출력하기
df.head()
- 결측치 처리
각 컬럼별 결측치 개수를 구해주세요.
결측치가 있는 행을 모두 제거해주세요.
1)컬럼별 결측치 확인
df.isnull().sum()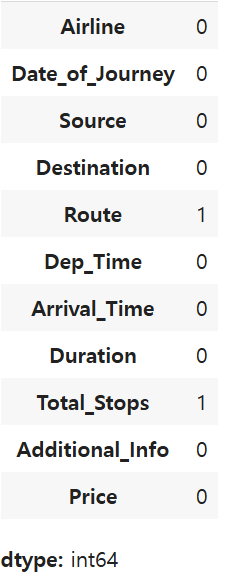
route와 total_stops에 결측치 확인!
2)결측치 제거2 -결측치가 있는 행들은 모두 제거 및 확인
df.dropna(inplace=True) #데이터갱신저장
#컬럼별 결측치 다시 확인.
df.isnull().sum()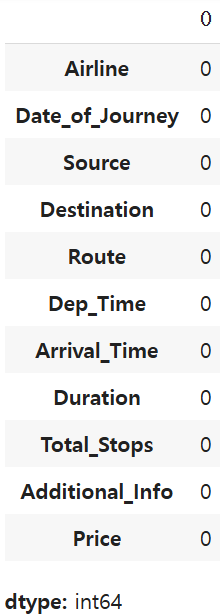
모든 결측치가 제거 된것을 확인 할 수 있다.
- 조건에 맞는 데이터 추출하기
데이터프레임의 Destination 컬럼 기준 price의 평균값과 중앙값을 동시에 구해주세요. 단, 값은 모두 소수점 첫번째 자리까지 표현해주세요.
#데이터 값 실수. 소수점 첫째자리까지 표시
pd.options.display.float_format = '{:.1f}'.format
dfmm = df.groupby("Destination")[['Price']].agg(['mean','median'])
dfmm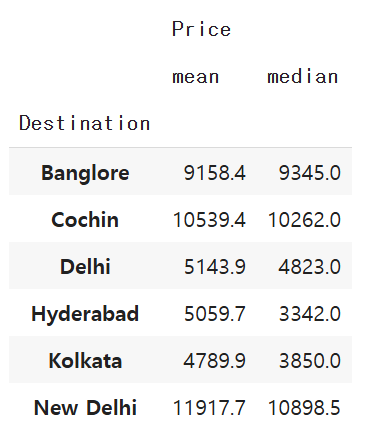
*새로운 방법
df1.groupby('Destination')['Price'].agg(['mean', 'median']).round(1)좀 더 간단한 방법이 있었다....ㅠㅜ
3_2.데이터프레임의 Airline, Total_Stops 기준 Route 컬럼을 중복값 없이 추출해주시고, 인덱스를 재정렬해주세요. 이를 df2 라는 dataframe 으로 받아주세요.
#첫번째 시도
df.groupby(["Airline","Total_Stops"])['Route'].drop_duplicates(subset=['Route'])Airline, Total_Stops 기준 Route 컬럼이라는 말이 이해가 안가서 그룹으로 묶어서 했지만,에러!
#두번째 시도
df.drop_duplicates(subset=['Route'])이걸 원하는 것은 아닐거라고 생각.
단순히 Route에 있는 중복값만 제거.
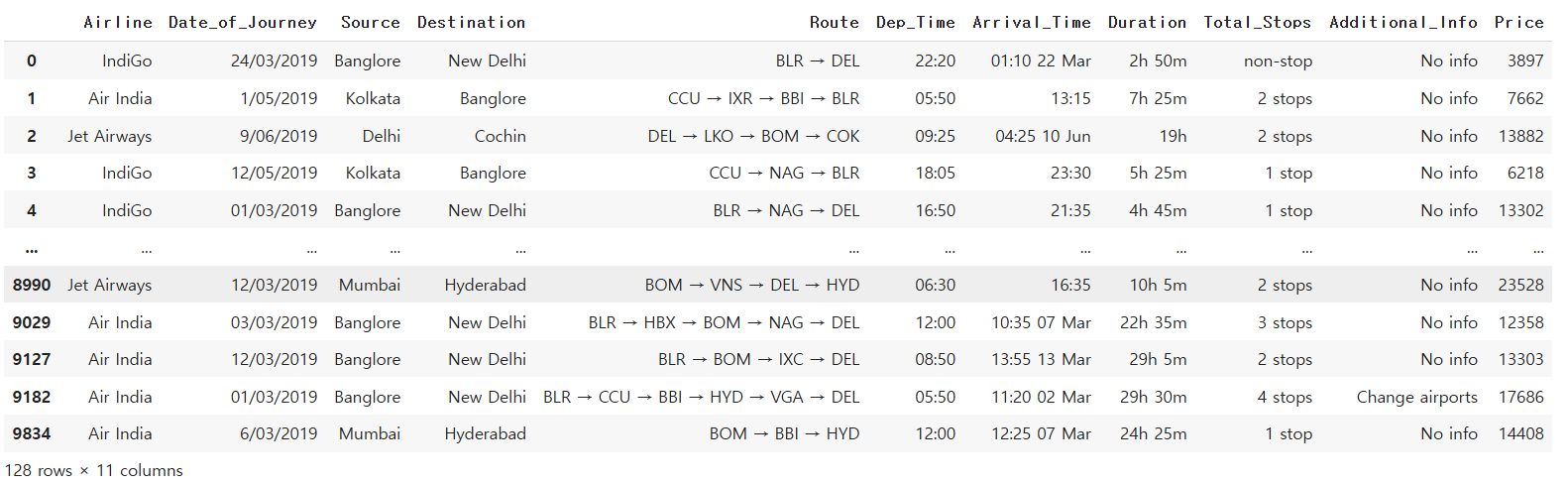
#세번째 시도
df2 = df.drop_duplicates(subset=['Airline', 'Total_Stops', 'Route']).reset_index(drop=True)
df2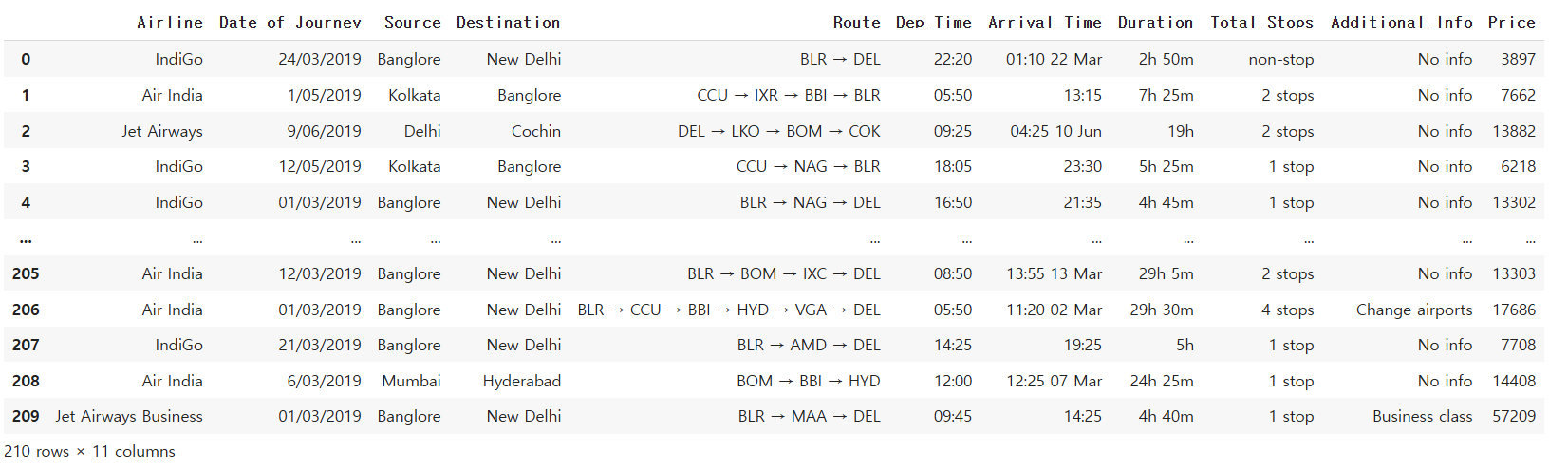
그냥 Route에 있는 중복값만 제거할경우 128개의 행이 나오고 세가지를 모두 넣어주면 210행이 나온다.
- 스터디 이후 새로운 방법 습득
df2 = df1.groupby(['Airline', 'Total_Stops'])['Route'].nunique().reset_index()그룹바이로 하다가 포기했었는데, 이런 방법으로 풀이가 가능했다!
nunique()
*문제 변경
데이터프레임의 Airline, Total_Stops 기준 Route 컬럼을 중복값 없이 그 수를 count 해주시고, 인덱스를 재정렬해주세요. 이를 df2 라는 dataframe 으로 받아주세요.
df = pd.read_csv("/content/drive/MyDrive/코랩랩/flight_data_homework.csv")
df2 = df.groupby(['Airline', 'Total_Stops'])['Route'].nunique().reset_index()
df2
- 조건에 맞는 데이터 추출하기2
피벗테이블을 구현하여 출발지와 도착지를 기준으로 한 Airline을 카운트해주세요. 그리고, 카운트 값을 기준으로 내림차순 정렬해주세요.
#첫번째 시도
pivot = df.pivot_table(df,index=['Source','Destination'], columns='Airline',values='Airline', aggfunc='count')
pivot에러가 나옴. Airline의 중복.
(index=, columns='',values='', aggfunc='')의 형태를 유지해야한다는 생각에 답이 나오지 않음.
#두번째 시도
df3=df.groupby(['Source','Destination'])['Airline'].count()
df3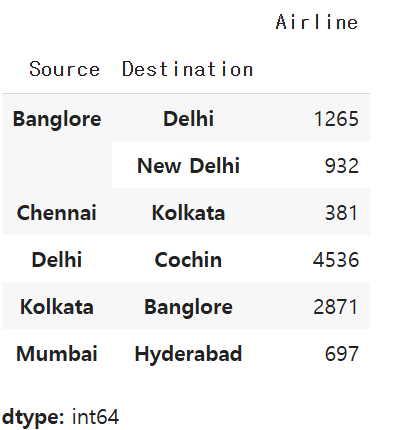
이런 스타일의 테이블이 나와야한다고 생각하며서 계속 조합을 바꿔봄.
pivot_table = pivot_table.rename(columns={'Airline': 'Airline_Count'})
pivot_table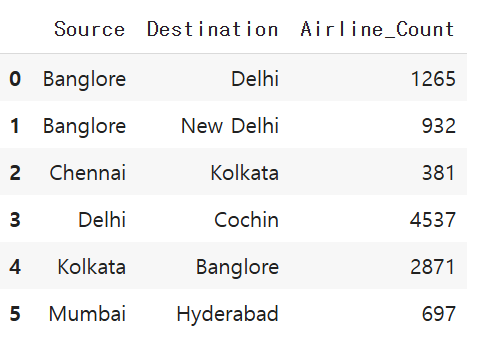
내림차순 정렬이 필요!
pivot_table = pivot_table.sort_values(by='Airline_Count', ascending=False).reset_index(drop=True)
pivot_table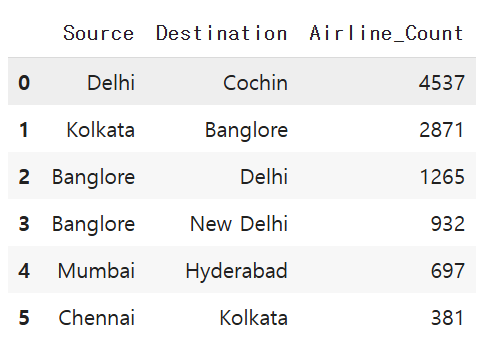
Airline 컬럼이 Air India 이고, Price 컬럼이 7000 이상인 데이터를 필터링 해주세요.
mask = ((df['Airline'] == 'Air India') & (df['Price'] >= 7000))
df[mask]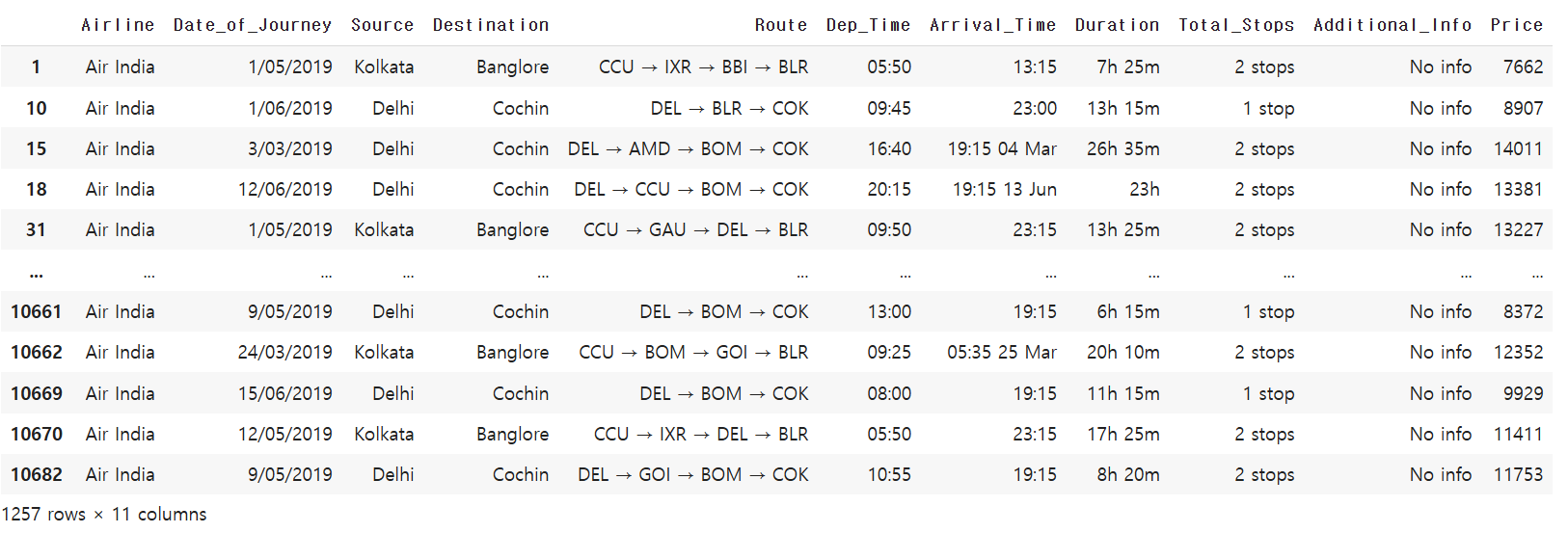
도전 5. 조건에 맞는 데이터 추출하기3
Date_of_Journey 기준 수요일에 예약된 경우의 평균 가격을 구해주세요.
# Date_of_Journey를 날짜 형식으로 변환 후 요일 추출
df['Date_of_Journey'] = pd.to_datetime(df['Date_of_Journey'], format='%d/%m/%Y')
df['Day_of_Week'] = df['Date_of_Journey'].dt.day_name()
# 수요일에 예약된 경우의 평균 가격 계산
wed_avg_price = df[df['Day_of_Week'] == 'Wednesday']['Price'].mean()
print("수요일 예약의 평균 가격:", wed_avg_price)수요일 예약의 평균 가격: 9277.51418951419
*rrule 함수의 byweekday property사용한 코드
#문자열 형식을 활용하지 않을 경우, 라이브러리 import 예시
from dateutil.rrule import rrule, WEEKLY
#문자열 형식을 활용할 경우, 라이브러리 import 예시(월요일, 화요일, 일요일 사용)
from dateutil.rrule import rrule, WEEKLY, WE
# Date_of_Journey를 날짜 형식으로 변환 후 요일 추출
df['Date_of_Journey'] = pd.to_datetime(df['Date_of_Journey'], format='%d/%m/%Y')
# 수요일만 추출
wed_dates = [dt for dt in df['Date_of_Journey'] if dt in rrule(freq=WEEKLY, byweekday=WE, dtstart=df['Date_of_Journey'].min())]
df_wed = df[df['Date_of_Journey'].isin(wed_dates)]
# 수요일에 예약된 경우의 평균 가격 계산
wed_avg_price = df_wed['Price'].mean()
print("수요일 예약의 평균 가격:", wed_avg_price)수요일 예약의 평균 가격: 9277.51418951419
*반복문을 사용해 풀기.
wd_list = []
for i in pd.to_datetime(flight['Date_of_Journey']) :
wd_list.append(i.weekday() == 2)
# sum(flight[wd_list]['Price']) / len(flight[wd_list]['Price'])
flight[wd_list]['Price'].mean()도전 6. 조건에 맞는 데이터 추출하기4
출발 시간(Dep_Time) 컬럼을 기준으로 lambda 함수를 활용하여 아침, 오후, 저녁, 밤 비행기로 항공편(Airline)을 분류하고 그 개수를 count 해주세요.
아침: 5시 이상 12시 미만
낮: 12시 이상 18시 미만
오후: 18시 이상 24시 미만
밤: 24시 이상 5시 미만(즉, 위의 세가지가 아닌 경우)
# Dep_Time 컬럼을 datetime 형식으로 변환
df['Dep_Time'] = pd.to_datetime(df['Dep_Time'], format='%H:%M', errors='coerce')
# 시간대 분류와 카운트
df['Flight_Period'] = df['Dep_Time'].apply(lambda x: '아침' if 5 <= x.hour < 12
else '낮' if 12 <= x.hour < 18
else '오후' if 18 <= x.hour < 24
else '밤')
# 항공편별 개수
period_count = df.groupby(['Airline', 'Flight_Period']).size().unstack(fill_value=0) #unstack() 함수는 표 형태로 보기 쉽게해줌.
period_count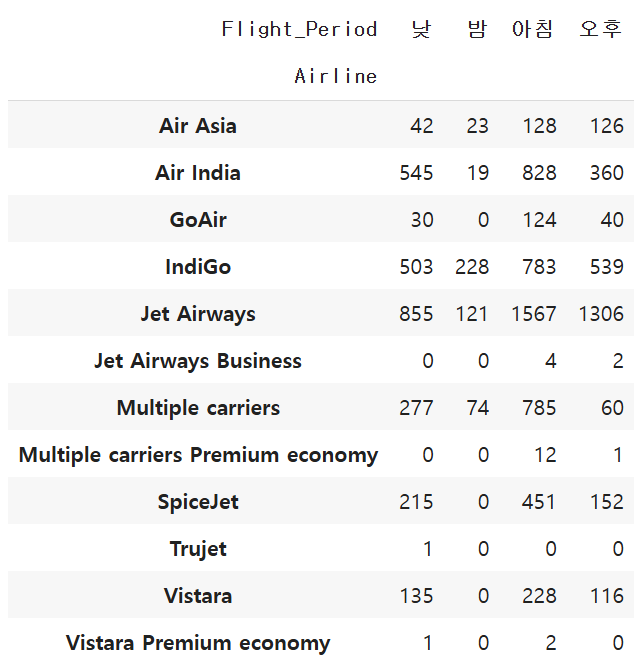
key points
*rrule : dateutil 의 강력한 규칙 기반 날짜 생성 클래스
:rrule은 dateutil 라이브러리에서 제공하는 규칙 기반의 날짜 생성을 위한 클래스. 이 클래스를 사용하면 반복적인 날짜 패턴을 정의하고 이를 기반으로 날짜를 생성할 수 있다.
from datetime import datetime
from dateutil.rrule import rrule, DAILY
# 시작 날짜
start_date = datetime(2022, 1, 1)
# 매일 반복하는 규칙 생성
daily_rule = rrule(DAILY, dtstart=start_date, count=5)
# 생성된 날짜 출력
for date in daily_rule:
print(date.strftime('%Y-%m-%d'))->이 코드는 2022년 1월 1일부터 시작해서 매일을 5번 생성하여 출력
2022-01-01
2022-01-02
2022-01-03
2022-01-04
2022-01-05
+반복적인 주기를 만들 수도 있다.
byweekdy 인자에 화요일 (TU) 를 입력하여 매주 화요일만 5번 출력.
from datetime import datetime
from dateutil.rrule import rrule, DAILY, TU
# 시작 날짜
start_date = datetime(2024, 2, 1)
# 매주 화요일만 반복하는 규칙 생성 (최대 5번)
weekly_rule = rrule(DAILY, dtstart=start_date, byweekday=(TU,), count=5)
# 생성된 날짜 출력
for date in weekly_rule:
print(date.strftime('%Y-%m-%d'))->
2024-02-06
2024-02-13
2024-02-20
2024-02-27
2024-03-05
to_datetime 함수의 주요 매개변수(parameter)와 인수(argument), 기본값(default)
pd.to_datetime(arg, errors='raise', utc=False, format=None, unit=None, origin='unix')arg (datetime으로 변환 가능한 데이터)
datetime으로 변환할 데이터. 단일 값이거나 1차원 배열만 가능하다.
errors (인수는 'ignore', 'raise', 'coerce' / 기본값 'raise')
변환 불가능한 데이터를 처리하는 방법을 지정하는 매개변수.
'raise' : 변환할 수 없는 객체를 만나면 에러를 일으킨다.
'coerce' : 변환할 수 없는 객체를 만나면 해당 부분만 NaT으로 바꾸고 변환을 수행한다.
'ignore' : 변환할 수 없는 객체를 만나면 모두 변환하지 않고 그냥 input을 그대로 반환한다.
utc (기본값 False)
시간대(timezone)가 포함된 데이터의 경우 협정 세계시(UTC)로 변환을 지정하는 매개변수 . 기본값은 False이다.
format (str, 기본값 None)
문자열의 날짜 표기 형식을 지정하는 매개변수.
예) 2023년 1월 3일이 '03/01/2023'으로 표현되어 있는 데이터라면 '%d/%m/%Y'로 지정한다.
unit (str, 기본값은 'ns')
Timestamp가 숫자로 주어질 때 숫자의 기본단위. 기본값은 nano second.
origin (scalar, 기본값 'unix')
Timestamp가 숫자로 주어질 때 기준 날짜. unit에서 정한 단위만큼의 숫자를 기준 날짜에서 더한다.
예) origin으로 1970-01-01을 기준으로 정하고 unit가 D라면 숫자1은 기준열부터 1일 지난 후인 1970-01-02를 의미한다.
'unix' : origin 은 1970-01-01.
'julian' : BC 4713년 1월 1일 정오. unit는 'D'여야 한다 Timestamp 로 변환가능한 문자열을 넣어도 된다.
count() 와 size()의 차이
- count(): nan값 제외.
- size(): nan값 포함.

groupby.count() 와 groupby.size()의 차이

그림과 같이 둘의 출력구조가 다르다.
count()는 함수이지만, size()는 데이터프레임의 속성!
즉, count()의결과는 데이터프레임의 형태로 나오지만, size()는 시리즈의 형태로 출력된다.
*.value_counts()와 .nunique() 차이
value_count()
.value_counts()
.value_counts()는 특정 컬럼에서 각 고유 값이 몇 번 나타나는지 계산하여, 이를 내림차순으로 정렬한 시리즈를 반환.
예를 들어, ['apple', 'banana', 'apple', 'apple', 'banana'] 데이터에 .value_counts()를 사용하면 apple: 3, banana: 2와 같은 결과가 나온다.
.nunique()
.nunique()는 특정 컬럼의 고유 값의 개수(중복되지 않는 값의 수)를 반환.
위와 같은 예제에서 .nunique()를 사용하면 apple과 banana가 각 1회씩만 계산되므로 2라는 결과를 반환.
import pandas as pd
data = pd.Series(['apple', 'banana', 'apple', 'apple', 'banana'])
# value_counts() 사용
print(data.value_counts())
# 결과:
# apple 3
# banana 2
# nunique() 사용
print(data.nunique())
# 결과: 2