가장 높은 f1 score 구하기
📌 F1-score의 의미
-
F1-score는 정밀도(Precision)와 재현율(Recall)의 조화 평균.
- 정밀도: 모델이 양성(1, 생존)을 예측한 것 중 실제 양성인 비율
- 재현율: 실제 양성인 것 중에서 모델이 정확히 예측한 비율
-
F1-score는 불균형 데이터에서 모델 성능을 측정하는 데 유용. 타이타닉 데이터의 Survived 변수는 0(사망)과 1(생존)의 비율이 균등하지 않을 가능성이 높기 때문에, F1-score를 기준으로 성능을 평가하는 것이 더 적합.
-
F1-score가 높은 경우
F1-score가 높다는 것은 양성 클래스(생존자)를 예측하는 데 있어 정밀도와 재현율이 모두 높음을 의미. 따라서 F1-score는 좋은 성능 지표로 간주된다. -
파일 불러오기
import pandas as pd
titanic_df = pd.read_csv('train.csv')
titanic_df.head(3)
- 전처리
- 결측치 처리
- Age: 평균, 중앙값 또는 KNN Imputation 등을 사용하여 채운다.
- Embarked: 최빈값으로 대체.
#결측치 처리
# Age 결측값 채우기
titanic_df['Age'].fillna(titanic_df['Age'].median(), inplace=True)
# Embarked 결측값 채우기
titanic_df['Embarked'].fillna(titanic_df['Embarked'].mode()[0], inplace=True)- 범주형 변수 변환
Sex와 Embarked는 로지스틱 회귀에 사용할 수 있도록 더미 변수로 변환해야 한다.
# 범주형 변수 처리
titanic_df = pd.get_dummies(titanic_df, columns=['Sex', 'Embarked'], drop_first=True)pd.get_dummies()란?
pd.get_dummies()는 범주형 변수를 더미 변수(dummy variable)로 변환하는 데 사용.
더미 변수는 각 범주의 값을 0과 1로 변환하여 모델이 처리할 수 있도록 만든다.
이 과정을 통해 범주형 데이터를 수치형 데이터로 변환할 수 있다.
📌코드 설명
(1) columns=['Sex', 'Embarked']
이 코드에서 Sex와 Embarked라는 범주형 변수를 더미 변수로 변환.
Sex: 'male', 'female'
Embarked: 'C', 'Q', 'S'
(2) drop_first=True
drop_first=True는 첫 번째 범주를 기준 변수(reference)로 설정하고 해당 더미 변수를 제거.
이는 다중공선성(Multicollinearity) 문제를 방지하기 위해 사용.
결과적으로, 첫 번째 범주는 다른 범주로 나타낼 수 있기 때문에 제거해도 정보가 손실되지 않는다.
📌변환 결과
-
Sex 변수 변환
원래 범주: 'male', 'female'
drop_first=True로 인해 'female'을 기준으로 두고 제거.
남성인 경우: Sex_male = 1,
여성인 경우: Sex_male = 0
즉, Sex_male 하나의 더미 변수만 남는다. -
Embarked 변수 변환
원래 범주: 'C', 'Q', 'S'
drop_first=True로 인해 'C'를 기준으로 두고 제거.
나머지 두 범주는:
Embarked_Q: Q에서 탑승한 경우 1, 아니면 0
Embarked_S: S에서 탑승한 경우 1, 아니면 0
📌이 방식의 장점
- 다중공선성 방지:
모든 범주를 더미 변수로 만들면 각 범주가 서로 종속적인 관계를 가지게 된다.
drop_first=True로 기준 범주를 제거하면 이런 문제를 예방할 수 있다. - 모델 효율성:
불필요한 변수를 줄여 모델 계산 효율을 높인다.
➕추가 설명: drop_first=False로 하면?
만약 drop_first=False로 설정하면 모든 범주에 대해 더미 변수를 생성.
예를 들어:
Sex: Sex_female, Sex_male 두 개의 변수가 생성.
Embarked: Embarked_C, Embarked_Q, Embarked_S 세 개의 변수가 생성.
이 경우 다중공선성 문제가 생길 수 있으므로 보통 drop_first=True를 사용하는 것이 일반적이다.
- 불필요한 변수 제거
PassengerId, Name, Ticket, Cabin은 모델에 유의미한 영향을 미치지 않으므로 제거.
titanic_df.drop(['PassengerId', 'Name', 'Ticket', 'Cabin'], axis=1, inplace=True)- 정규화 (Optional)
로지스틱 회귀에서 Fare 같은 연속형 변수의 범위를 정규화하면 학습이 안정적임.
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
titanic_df['Fare'] = scaler.fit_transform(titanic_df[['Fare']])
titanic_df
📌로지스틱 회귀 및 변수 중요도 확인
(1) 데이터 분할
학습/테스트 데이터로 나눈다.
- X_train: 훈련 데이터에서 독립 변수 부분. 모델 학습에 사용.
- X_test: 테스트 데이터에서 독립 변수 부분. 학습된 모델의 평가에 사용.
- y_train: 훈련 데이터에서 종속 변수 부분. X_train과 함께 모델 학습에 사용.
- y_test: 테스트 데이터에서 종속 변수 부분. X_test와 함께 모델의 예측 성능을 확인하는 데 사용.
from sklearn.model_selection import train_test_split
X = titanic_df.drop('Survived', axis=1) # X: 독립 변수(예측 변수)
y = titanic_df['Survived'] # y: 종속 변수(목표 변수)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)(2) 모델 학습 및 평가
LogisticRegression을 사용하여 F1 스코어를 확인.
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import f1_score
model = LogisticRegression(max_iter=1000)
model.fit(X_train, y_train)
get_att(model)클래스 종류 [0 1]
독립변수 갯수 8
들어간 독립변수(x)의 이름 ['Pclass' 'Age' 'SibSp' 'Parch' 'Fare' 'Sex_male' 'Embarked_Q'
'Embarked_S']
가중치 [[-0.93883239 -0.03056962 -0.29502744 -0.10812937 0.12649473 -2.59200285
-0.11203042 -0.40004226]]
바이어스 [4.62000069]
y_pred = model.predict(X_test)
f1 = f1_score(y_test, y_pred)
print(f"F1 Score: {f1:.4f}")F1 Score: 0.7639
➕F1 스코어비교해보기
# X변수가 Fare
get_metrics(y_true, y_pred_1)
# X변수가 Fare, Pclass, Sex
get_metrics(y_true, y_pred_2)
# X변수가 'Pclass' 'Age' 'SibSp' 'Parch' 'Fare' 'Sex_male' 'Embarked_Q','Embarked_S'
get_metrics(y_test, y_pred)정확도 0.6655443322109988
f1-score 0.354978354978355
정확도 0.7867564534231201
f1-score 0.7121212121212122
정확도 0.8100558659217877
f1-score 0.7638888888888888
# 각 데이터별 Y=1인 확률 뽑아내기(생존할 확률)
model.predict_proba(X)array([[0.90200092, 0.09799908],
[0.08915252, 0.91084748],
[0.36660401, 0.63339599],
...,
[0.49651776, 0.50348224],
[0.42831206, 0.57168794],
[0.87446646, 0.12553354]])
😊정확도와 f1-score모두 높아진것을 확인할 수 있다!
해석
-
X변수가 Fare
정확도: 0.67
f1-score: 0.35 -
X변수가 Fare, Pclass, Sex
정확도: 0.79
f1-score: 0.71 -
X변수가 'Pclass' 'Age' 'SibSp' 'Parch' 'Fare' 'Sex_male' 'Embarked_Q','Embarked_S'
정확도: 0.81
f1-score: 0.76
결과를 보면 다중로지스틱 회귀의 정확도와 f1스코어가 더 좋아진 것을 확인할 수 있다.
🤔그렇다면 왜 다중로지스틱 회귀가 더 좋은 결과를 보여줄까?
- 다중 로지스틱 회귀가 더 좋은 이유
(1) 더 많은 정보 활용
: 단일 변수(Fare)는 생존 여부를 예측하기에 제한된 정보를 제공한다. 예를 들어, 단지 요금이 높다고 해서 생존 가능성이 높아지는 것은 아니며, 다른 변수들이 중요한 영향을 미칠 수 있다. - 다중 변수(Pclass, Sex, Fare)는 다양한 생존 요인을 포함:
Pclass: 사회적 지위(1등급일수록 생존 확률이 높음)
Sex: 성별(여성이 생존 확률이 더 높음)
Fare: 요금(일부 상관관계는 존재)
(2) 변수 간 상호작용
다중 로지스틱 회귀는 각 변수와 목표 변수 간의 관계뿐만 아니라, 변수들 간의 상호작용도 모델링에 포함할 수 있다. - Fare와 Pclass 또는 Fare와 Sex가 결합되어 더 풍부한 정보를 제공할 가능성이 높다.
(3) 모델이 가진 제한적인 가정
단일 변수 모델은 하나의 독립 변수만 사용하므로, 생존 여부를 설명하는 데 필요한 정보의 손실이 큼. 반면 다중 로지스틱 회귀는 더 많은 독립 변수를 고려하므로 예측의 다양성과 정확도를 높일 수 있다.
➕가장 중요한 변수 찾기.
importance = pd.Series(model.coef_[0], index=X.columns)
print(importance.sort_values(ascending=False))importance = pd.Series(model.coef_[0], index=X.columns)
print(importance.sort_values(ascending=False))
➕추가: 하이퍼파라미터 튜닝
F1 점수를 더 높이기 위해 GridSearchCV로 최적의 하이퍼파라미터를 찾는 방법:
- param_grid는 로지스틱 회귀 모델의 하이퍼파라미터를 정의한 딕셔너리.
- 여기서 C는 정규화 강도를 조절하는 하이퍼파라미터:
C는 규제의 역수입니다. - 작은 값(C=0.01)은 강한 규제를 적용(단순 모델),
- 큰 값(C=100)은 약한 규제를 적용(복잡한 모델).
- [0.01, 0.1, 1, 10, 100] 리스트는 테스트할 C 값들을 나타낸다.
📌 GridSearchCV 작동 방식 요약
1. 하이퍼파라미터 조합 생성:
{C: 0.01}, {C: 0.1}, {C: 1}, {C: 10}, {C: 100}의 5가지 조합.
2. 교차 검증:
각 조합에 대해 훈련 데이터 Xtrain과 y_train에서 모델을 학습하고 교차 검증으로 평가.
3. 최적 조합 선택:
F1-score가 가장 높은 조합을 선택.
4. 결과 저장:
best_score와 bestparams에 저장.
from sklearn.model_selection import GridSearchCV
param_grid = {'C': [0.01, 0.1, 1, 10, 100]}
grid = GridSearchCV(LogisticRegression(max_iter=1000), param_grid, scoring='f1')
grid.fit(X_train, y_train)
# GridSearchCV는 하이퍼파라미터 조합별로 학습과 평가를 수행하여, 가장 높은 F1-score를 제공하는 조합을 찾는다.
print("Best F1 Score:", grid.best_score_)
print("Best Parameters:", grid.best_params_)Best F1 Score: 0.7074065137578791
Best Parameters: {'C': 10}
- C와 규제
규제(Regularization)는 모델이 너무 복잡해지는 것을 방지하고 과적합을 막기 위해 사용.- C가 작을수록 규제가 강하고, 클수록 규제가 약해진다:
C=0.01: 단순한 모델 (규제가 강함)
C=10: 상대적으로 복잡한 모델 (규제가 약함) - 여기서 C=10이 최적값으로 선택된 것은, 모델이 복잡성을 적절히 유지하면서도 데이터를 잘 설명했음을 의미.
- C가 작을수록 규제가 강하고, 클수록 규제가 약해진다:
결과 해석
회귀 계수의 의미
계수가 양수인 변수는 해당 변수의 값이 증가할수록 Survived = 1 (생존)일 가능성이 높아짐을 의미.
계수가 음수인 변수는 해당 변수의 값이 증가할수록 Survived = 0 (사망)일 가능성이 높아짐을 의미.
예를 들어:
Fare: 0.126495 (양수) → 티켓 요금(Fare)이 높을수록 생존 가능성이 높음.
Sex_male: -2.592003 (음수) → 남성(Sex_male)이면 생존 가능성이 매우 낮음.
- F1 스코어와 변수 중요도
F1 스코어는 모델의 예측 성능(정밀도와 재현율의 조화)을 나타낸다.
특정 변수가 F1 스코어에 얼마나 기여하는지는 변수 간의 상관관계, 데이터 분포, 모델의 학습 방법에 따라 다르다.
따라서, 단순히 회귀 계수의 크기로 F1 스코어에 어떤 변수가 가장 큰 영향을 미치는지 직접적으로 판단할 수는 없다.
가장 중요한 변수 찾기
회귀 계수를 이용해 상대적으로 중요한 변수를 찾으려면 계수의 절대값을 비교. 절대값이 클수록 모델에 더 큰 영향을 미친다고 볼 수 있다.
주어진 계수: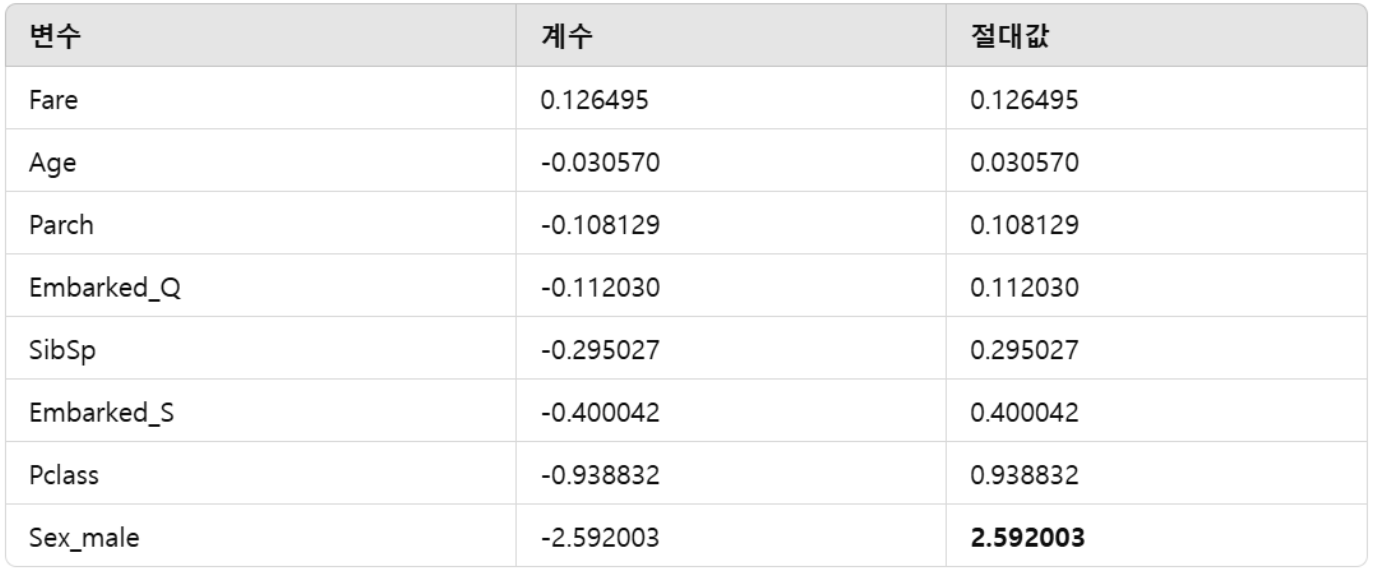
즉, 가장 중요한 변수는 Sex_male (절대값 2.592003)이다.
남성 여부는 생존 여부에 가장 큰 영향을 미친다.
그다음으로 중요한 변수는 Pclass (절대값 0.938832)이다.
티켓 등급(Pclass)이 생존 여부에 큰 영향을 미친다.
