contents
- 통계와 머신러닝
- 지도학습 살펴보기
- 비지도학습 살펴보기
summary
- 통계와 머신러닝
👉 통계와 머신러닝의 관계성
- 머신러닝이란?
:데이터를 기반으로 예측 모델을 학습시키는 알고리즘 기반의 접근법- 목적:
어진 데이터를 통해 패턴을 학습하여 미래 데이터를 예측하거나 분류하는 것 - 종류: 지도학습(분류, 회귀), 비지도학습(클러스터링, 차원 축소), 강화학습
- 목적:
- 통계적 가설검정과 머신러닝

즉, 두가지의 방법론은 상호보완적! - 통계적 가설검정이 머신러닝을 보완하는 경우
- 머신러닝 모델의 피처 선택(컬럼 선택)에서 유의미한 변수를 찾기 위해 통계적 가설검정 사용
- 데이터 분포, 이상치 처리 등 데이터 전처리에 유용한 통계적 기법을 제공
- 머신러닝이 가설검정을 보완하는 경우
- 비선형 데이터의 관계를 처리링하거나 대규모 데이터에서 가설 검정의 한계를 보완
- 예를 들어, 통계적 가설검정은 변수 간 독립성을 가정하고 진행되지만, 머신러닝은 이러한 제약 없이 상관 및 연관성을 탐지합니다.
- 두가지 방법론의 융합(심화 프로젝트에서 해야 하는 부분)
- 통계적 가설검정을 사용해 데이터 탐색 및 초기 분석을 수행한 후, 머신러닝을 통해 예측 성능을 극대화
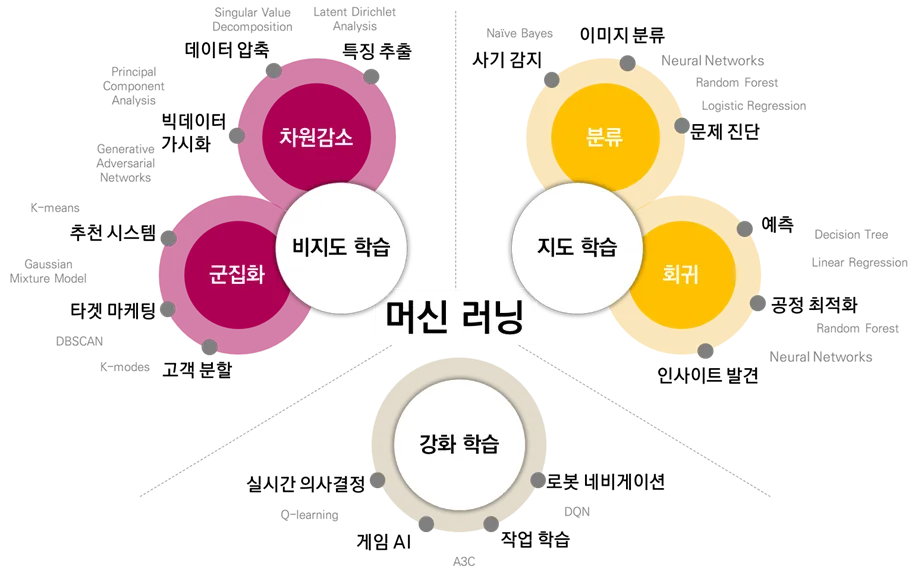
👉 머신러닝의 종류
-
지도 학습
:정답이 있는 데이터(labelled data)를 활용해 훈련 데이터로부터 프로그램 등을 학습시켜서 결과에 대한 예측을 만들어내는 기계 학습(Machine Learning)의 한 방법.
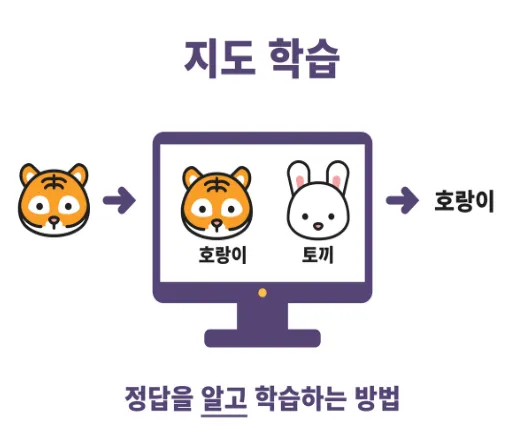
;훈련 데이터와 정답을 주고서 프로그램을 학습시키며, 학습 후 검증 데이터를 통해 적절하게 학습되었는지 모델을 검증하는 과정을 거친다.
예시)학생이 학교에서 수업을 듣고(훈련 데이터로부터의 학습), 시험을 통해 평가(모델 검증)받는 것.
→ 문제와 정답을 모두 알고있는 상태에서 시행 -
비지도 학습
:정답이 없는 데이터(Unlabelled data)를 분석함으로써 그 안에 숨어있는 패턴을 찾아내거나 데이터를 그룹화시키는 알고리즘.
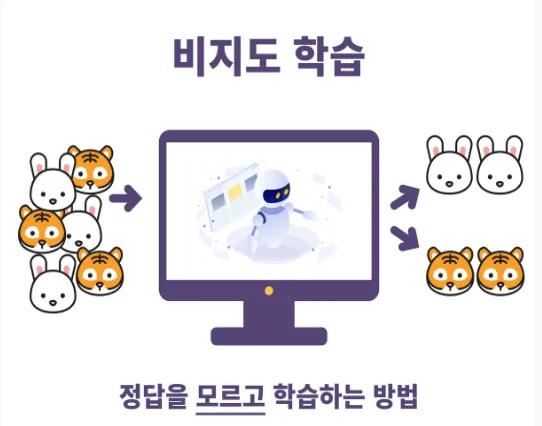
;데이터 간의 유사성이나 차이점을 분석해서 적절한 해결책을 만들어내는 것을 목표로한다.오직 입력되는 데이터만을 이용해 컴퓨터를 학습시키는 방법이다.
→ 정답을 알 수 없는 상태에서 시행
👉 지도학습과 비지도학습의 차이점
- 지도 학습과 비지도 학습의 가장 큰 차이점 : "Label"
:두 접근 방식의 주요 차이점은 ”데이터 세트에 label이 지정되어 있는지 아닌지”이다.
지도 학습은 label이 지정된 입력 및 출력 데이터를 사용!
:지도 학습에서 알고리즘은 label된 데이터 세트를 이용해 반복적으로 데이터를 예측하고 정답(label)과의 오차를 줄여나가며 학습.
-> 지도 학습 모델은 비지도 학습 모델보다 더 정확한 경향이 있지만 데이터에 적절하게 레이블을 지정하려면 사전에 “데이터분석가의 주관” 개입이 필요
예)시간, 기상 조건 등을 기반으로 통근 시간을 예측할 수 있지만 먼저 비가 오는 날씨가 운전 시간을 연장한다는 것을 알기 위해 훈련이 필요하다.
비지도 학습은 label이 지정되지 않은 데이터의 고유한 구조를 발견하기 위해 자체적으로 작동.
:결과의 유효성을 검사하려면 여전히 “데이터분석가의 주관” 개입이 보다 적극적으로 필요!
예)온라인 쇼핑객이 구매했던 제품들을 분석해 다른 온라인 쇼핑객에게 구매할 만한 물건을 추천해 줄 수 있겠지만, 데이터 분석을 통해서 추천 엔진이 추천해 준 항목들이 타당한지 검증해야 한다.
-
지도 학습과 비지도 학습의 또 다른 차이점들
지도 학습 모델은 훈련하는 데 시간이 많이 걸릴 수 있으며 입력 및 출력 변수에 대한 label에는 전문 지식이 필요하다.
한편, 비지도 학습 방법은 출력 변수를 검증하기 위해 사람이 개입하지 않을 경우, 부정확한 결과를 가질 수 있다.
-> 둘 중 어떤것이 더 좋은지 알수 는 없지만, 데이터의 구조나 사용분야에 맞게 적합한 방식을 선택하는 것이 가장 중요하다. -
목표
- 지도 학습: 새로운 데이터의 결과를 예측하는 것
- 비지도 학습: 많은 양의 새로운 데이터에 대한 통찰력을 얻는 것
-
활용
- 지도학습: 감정 분석, 일기 예보 및 가격 예측에 이상적
- 비지도 학습: 이상 감지, 추천 엔진, 고객 페르소나 및 의료 영상에 매우 적합
-
복잡성
- 지도학습: 일반적으로 R 또는 Python과 같은 프로그램을 사용하여 계산되는 비교적 복잡성이 낮은 머신러닝 방법.((하지만, 실제 현업에서는 지도학습도 굉장히 복잡하게 진행)
- 비지도 학습: 대량의 분류되지 않은 데이터로 작업하기 위한 다양한 통계적 지식 및 관련 라이브러리가 필요.비지도 학습 모델은 의도한 결과를 생성하기 위해 대규모 훈련 세트가 필요하기 때문에 계산적으로 복잡하다.
- 지도학습 살펴보기
👉 지도학습은 “분류”와 “회귀”로 나뉩니다.
분류) 내일은 날씨가 추울 것이다.
회귀) 내일은 온도가 35.0℃일 것이다.
;회귀 모델은 예측값으로 연속적인 값을 출력하고, 분류 모델은 예측값으로 이산적인 값을 출력.
예시)어떤 사람의 키와 몸무게를 데이터로 얻어 그 사람의 허리 둘레를 예측하는 모델은 회귀 모델이고, 입력으로 받은 사진이 어떤 동물인지 종류를 예측하는 모델은 분류 모델이다.
👉 지도학습에 사용되는 기법
- 선형 회귀(Linear Regression)
- 로지스틱 회귀(Logistic Regression)
- 나이브 베이즈(Naive Bayes)
- K-최근접 이웃(k-Nearest Neighbors)
- 서포트 벡터 머신(SVM, Support Vector Machine)
- 의사결정 트리(Decision Tree)
- 랜덤 포레스트(Random Forest)
- 인공신경망(Neural Network)
👉 RFM(분류) 분석
:고객분류기법으로 고객을 R, F, M 이라는 특성에 따라 분류하고, 특성에 맞춰서 구매기회 창출 및 서비스를 발전시키는 것을 목표로 가지고 있다.
1️⃣Recency(최근성)
:비즈니스의 종류(물건,정보,서비스등)에 따라 다르지만, 보통 RFM분석에서는 최근에 구매한 고객일수록 더 가치있는 고객으로 점수가 매겨진다. 구매시기가 오래되었다면, 재구매율이 보통 떨어지기 때문!
2️⃣Frequency(빈도)
:자주 구매하는 고객일수록, 비즈니스에 큰 도움이 되고 재방문율이 높다고 할 수 있다.빈도수가 높을수록 가치있는 고객으로 점수가 매겨진다.
3️⃣Monetary(구매금액)
:구매빈도가 적더라도, 큰 금액을 지출하는 고객이 회사입장에서는 매출에 더 도움이 될 수도 있다. 구매금액이 높을수록 가치있는 고객으로 점수가 매겨진다.
기준 세우기 예시
- Recency: 2024-01-01 을 기준으로 한 달 이내에 구매기록이 있으면 ‘recent’ 아니면 ‘past’
- Frequency: 구매횟수가 5회 이상 ‘high’ , 3~5회 ‘mid’, 나머지 ‘low’
- Monetary: 누적 구매금액 500 달러 이상 ‘high’ 아니면 ‘low’
⚠️ 실전에서 RFM 적용 시 고려할 점⚠️
비즈니스의 성격에 따라, 상황에 따라 알맞은 기준을 세우는 과정이 필요.
대표적으로 서비스마다 다르게 적용이 가능한 요소들은 아래와 같다.
- Recency, Frequency, Monetary를 각각 몇 단계로 나눌 것인가
- Frequency, Monetary를 집계하는 기간을 어떻게 설정할 것인가
- 비지도학습 살펴보기
👉 비지도학습은 “군집화”입니다.
:크게 군집화(비슷한 특성끼리 묶음)와 차원 축소로 나뉜다고 하지만, 실상 현업에서는 두가지가 연결되어 하나의 프로젝트로 진행된다.
정답이 없는 상태에서 분석을 시작하므로, 다양한 분석기법이 제외되거나 추가될 수 있다.
다만, 전반적인 프로세스는 존재!
1) 기간 선정
2) K값(군집갯수), 초기 컬럼(피쳐) 선정
3) 이상치 기준선정 및 제외
4) 표준화
5) 차원 축소
6) PCA PLOT 으로 군집 밀도 확인
7) 2~7번 과정을 반복하며 최적의 결과 도출
8) 모델링(Random Forest)
9) 데이터 적재 및 자동화 설정
👉 비지도학습에 사용되는 기법
- 군집(Clustering)
- K-means 클러스터링
- 위계적 군집분석
- 가우시안 혼합모형(Gaussian Mix Texture Model)
- 주성분 분석(PCA)
- LLE(Locally Linear Embedding)
- Isomap
- MDS(Multi Dimensional Scaling
- t-SNE(t-distributed Stochastic Neighbor Embedding)
key point
통계와 머신러닝은 서로 밀접한 관계가 있고 상호보완이 가능하기에 둘다 알아두면 좋다!
그리고 꼭 통계적 검정을 먼저 진행 할 필요는 없다. 머신러닝을 활용한 결과를 검증하기 위해 통계적 검정을 실행 해 볼 수 있다.
가상시나리오
도메인: OTT 플랫폼
- 배경: OTT 플랫폼은 사용자 행동 데이터를 기반으로 맞춤형 추천 시스템을 개선하고, 사용자 이탈(구독 취소)을 방지하고자 한다.
- 목표:
클러스터링(비지도학습): 시청 데이터를 기반으로 유사한 사용자 그룹(클러스터)을 식별.- 이탈 예측(지도학습): 사용자의 과거 행동 데이터를 바탕으로 구독을 계속 유지할지, 이탈할지 예측하는 모델을 만든다.
- 통계적 검증: 사용자 행동 및 구독 여부 간의 연관성을 통계적으로 분석하여 가설을 검증.
📌주요 가설:
- 사용자 그룹화:
"사용자의 시청 패턴(예: 장르 선호도, 시청 시간대 등)은 유사한 행동 그룹으로 나눌 수 있다."
비지도학습(클러스터링)을 사용해 확인. - 이탈 요인:
"시청 시간, 특정 장르 선호도, 가격 민감도 등은 구독 이탈에 영향을 미친다."
지도학습(이탈 예측 모델)과 통계적 분석을 통해 확인. - 클러스터별 이탈률 차이:
"클러스터에 따라 구독 이탈률이 유의미하게 다르다."
클러스터와 이탈 여부 간의 연관성을 검증(카이제곱 검정, ANOVA 등).
📌분석 흐름
- 데이터 준비
- 데이터: OTT 플랫폼 사용자 데이터 (가상 데이터)
- 사용자 ID: 고유 사용자 식별자
- 시청 시간: 주별 총 시청 시간
- 장르 선호도: 시청한 콘텐츠 장르 비율 (액션, 코미디, 드라마 등)
- 시청 시간대: 콘텐츠를 주로 소비한 시간대
- 구독 여부: 1(유지), 0(이탈)
- 구독 플랜: 구독 요금제 유형 (예: 기본, 스탠다드, 프리미엄)
- 가격 민감도: 과거 가격 변동에 따른 행동 데이터
1단계: 비지도학습 - 클러스터링
- 목표:
사용자의 시청 행동 데이터를 기반으로 유사한 사용자 그룹(클러스터)을 생성. - 방법:
- 데이터 전처리:
장르 선호도와 시청 시간 등의 데이터를 정규화. - 차원 축소(PCA):
고차원 데이터를 시각화하거나 클러스터링을 돕기 위해 주요 특징으로 압축. - 클러스터링:
K-Means 또는 DBSCAN으로 사용자 그룹화. - 클러스터 특성 분석:
각 클러스터의 주요 특징(장르 선호도, 시청 시간 등) 도출.
- 데이터 전처리:
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
from sklearn.cluster import KMeans
import pandas as pd
# 데이터 로드 및 정규화
data = pd.read_csv("ott_data.csv")
features = ['watch_time', 'action_ratio', 'comedy_ratio', 'drama_ratio']
X = data[features]
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# 차원 축소 (PCA)
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X_scaled)
# 클러스터링 (K-Means)
kmeans = KMeans(n_clusters=4, random_state=42)
data['cluster'] = kmeans.fit_predict(X_pca)
# 클러스터별 시각화
import matplotlib.pyplot as plt
plt.scatter(X_pca[:, 0], X_pca[:, 1], c=data['cluster'], cmap='viridis')
plt.title("User Clusters")
plt.show()2단계: 지도학습 - 이탈 예측
- 목표:
사용자의 과거 행동 데이터를 기반으로 이탈 여부(0, 1)를 예측. - 방법:
- 데이터 준비:
독립 변수(X): 시청 시간, 장르 선호도, 가격 민감도 등.
종속 변수(y): 이탈 여부. - 데이터 분할:
train_test_split로 훈련 데이터와 테스트 데이터 분리. - 모델 학습:
로지스틱 회귀, 랜덤 포레스트, XGBoost 등 지도학습 모델을 사용. - 모델 평가:
정확도(accuracy), F1-score로 성능 평가.
- 데이터 준비:
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, f1_score
# 독립 변수와 종속 변수
X = data[['watch_time', 'action_ratio', 'comedy_ratio', 'drama_ratio', 'price_sensitivity']]
y = data['churn'] # 이탈 여부
# 데이터 분할
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 랜덤 포레스트 모델 학습
model = RandomForestClassifier(random_state=42)
model.fit(X_train, y_train)
# 예측 및 평가
y_pred = model.predict(X_test)
print("Accuracy:", accuracy_score(y_test, y_pred))
print("F1 Score:", f1_score(y_test, y_pred))3단계: 통계적 검증
- 목표:
클러스터와 이탈 여부 간의 상관관계를 검증하여 가설을 확인. - 방법:
- 카이제곱 검정:
클러스터와 이탈 여부 간의 독립성 검정. - ANOVA:
클러스터별 평균 시청 시간의 차이가 유의미한지 검증.
- 카이제곱 검정:
from scipy.stats import chi2_contingency, f_oneway
# 카이제곱 검정
contingency_table = pd.crosstab(data['cluster'], data['churn'])
chi2, p, _, _ = chi2_contingency(contingency_table)
print("Chi-square Test p-value:", p)
# ANOVA
anova = f_oneway(data[data['cluster'] == 0]['watch_time'],
data[data['cluster'] == 1]['watch_time'],
data[data['cluster'] == 2]['watch_time'])
print("ANOVA p-value:", anova.pvalue)4단계: 결과 융합 및 해석
- 클러스터별 주요 행동 특성과 이탈률 분석.
- 이탈 예측 모델의 성능 평가(F1-score, 중요 특징 등).
- 통계 검증 결과로 가설 확인:
"어떤 사용자 그룹이 이탈 가능성이 높은가?"
"어떤 행동이 이탈 여부에 가장 큰 영향을 미치는가?"
결론
위 분석을 통해 OTT 플랫폼의 사용자 행동을 이해하고, 이탈 방지 전략(예: 가격 조정, 특정 장르 추천 등)을 수립할 수 있다.
