
기술 컨퍼런스, 기술 블로그, 아티클, 강의 등 다양한 자료로 학습한 내용과 인사이트를 기록하는 시리즈입니다.
검색 서비스 정의
1.1 검색 요구사항 특징
- 검색의 목표
- 사용자 쿼리(검색어)를 입력으로 받아서, 사용자가 의도한 검색 결과를 최상위에 노출하는 것
- 주요 기능도 1개, 주요 입력도 1개
- 대부분의 검색 스펙은 어떤 타입의 쿼리까지 지원하는 가에 있다.
1.2 검색 요구사항의 예
- 음차변환
- 오타교정 (간남역 → 강남역)
- 유의어 검색 (US → 미국)
- 부분쿼리 검색
- 다국어 쿼리 검색
- 카테고리 검색
1.3 검색 데이터 분석
- 검색 엔지니어 업무에서 가장 많은 시간을 차지
- 양질의 데이터와 데이터의 양은 검색 품질과 직결된다.
- 저품질 데이터는 양질의 데이터로 정제해야 한다.
- 데이터의 품질이 개발 난이도를 결정한다.
- 분석해야 할 검색 데이터
- 사용자 쿼리: 어떤 타입의 사용자 쿼리가 많이 요구되는지, 어떤 쿼리들이 들어올 수 있는지
- 검색 대상이 되는 문서: 국내 특허, 해외 특허
검색 서비스 원리
2.2.1 인덱스텀 추출(term extraction)
- 적절한 인덱스텀이 없으면, 예상되는 쿼리에 대해서 검색이 되지 않는다.
- 적절한 인덱스텀이란?
- 문서의 언어와 문자 환경에 적합 (한국어 체계에 맞게)
- 예상되는 사용자 쿼리의 특징에 적합
- 검색 결과를 구성하기에 적합
- 텀을 추출하는 방법
- 공백 단위 구분 추출
- n-gram 추출
- Edge n-gram 추출
- min: 2, max:4, sep: “” 일 때, [서울, 서울에, 서울에서, 부산, 부산가, 부산가는]
- 형태소 분석기 추출
- 형태소 분석기의 종류나 설정에 따라서 결과가 다름
- 품사에 따른 분리 또는 사전 기반에 따른 분리가 가능(텀, 품사, 사전)
- NLU를 사용한 추출
- 적절한 인덱스텀 추출의 중요성
- 공백 분리: “서울에서 부산가는”은 되는데, “서울 부산”은 안 된다.
- 형태소 분석기: “서울에서 부산까지”와 “서울 부산”이 모두 된다.
2.2.2 Inverted File 생성
- Inverted File
- 인덱스텀과 인덱스텀이 존재하는 문서의 DocId 목록 매핑의 집합
- Lexicon
- 인덱스텀을 빨리 찾을 수 있도록 텀들의 목록을 모아서 관리하는 사전
- 빠른 탐색에 최적화되어야 함
- Posting
- 인덱스텀이 위치하는 문서 식별자(DocId) 1개
- 메모리와 보조기억장치를 최대한 효율적으로 사용
2.3 쿼리 처리(query processing)
- 쿼리의 종류
- Boolean 쿼리, 근접(Proximity) 쿼리, 자연어 쿼리 등이 있다.
- 대부분의 사용자들은 알아서 처리해주는 자연어 쿼리를 원한다.
- 쿼리 처리 단계
- 쿼리텀 추출(Term Extraction)
- 추출된 쿼리텀으로 Inverted File에서 포스팅 찾기
- 쿼리 연산 수행 및 검색 결과 목록 생성
- 문서 점수화 및 정렬
2.3.1 쿼리텀 추출
- 인덱스텀 추출과 거의 유사한 기준으로 추출해야 한다.
- 다른 기준으로 텀을 추출하면 문서와 동일한 쿼리로 검색해도 검색이 안 될 수 있다.
- “경기 성남시 정자동”의 예
- 인덱스텀은 형태소 분석기로 분리해서 “경기”, “성남”, “정자”로 생성
- 쿼리텀은 공백으로 분리해서 “경기”, “성남시”, “정자동”으로 생성
- 이 경우, “경기 성남시 정자동”으로 검색해도 해당 문서가 검색되지 않는다.
2.3.2 포스팅 찾기
- Inverted File에서 각 쿼리텀에 대한 포스팅을 찾는다.
- inverted File은 메모리에 있고, 탐색 속도가 매우 빠르다.
2.3.3 쿼리 연산
- 쿼리텀에 매칭되는 포스팅으로 쿼리 연산을 수행한다.
- Boolean 쿼리, 근접 쿼리 등 각 쿼리의 성격에 따라서 다른 연산 과정을 수행한다.
- 일반적으로 자연어 쿼리는 모든 쿼리텀을 AND 검색한 문서를 찾는다.
- 최적화된 쿼리 처리
- 한 개의 쿼리텀에 대한 포스팅 리스트의 크기는 최악의 경우 전체 문서의 집합의 크기와 같다. 이 경우, 쿼리 처리 속도가 급격하게 느려진다.
- 메모리 사용과 수행 속도를 최적화한 쿼리 처리가 중요하다.
2.3.4 점수화 및 정렬
- Relevancy (정확도)
- 입력된 쿼리텀들과 문서가 얼마나 일치하는 지를 나타내는 함수
- Relevancy를 구하는 알고리즘은 검색의 특성이나 도메인에 따라서 다양하다.
- 기본적인 Relevancy 알고리즘으로는 문서 유사도를 구하는 TF-IDF와 BM25가 있다.
- 이외에도 벡터 모델, 확률 모델 등이 있따.
- 랭킹 모델링
- Relevancy 점수를 계산하는 방법을 정하는 과정이 랭킹 모델링이다.
- 사용자의 의도에 가장 근접한 점수를 모델에 반영하기 위해서 가지고 있는 데이터를 최대한 활용한다.
- 지도 장소검색 랭킹 모델의 예
- 베이지언 확률을 기반으로 한 모델을 사용한다.
- 텀-문서 유사도, 장소 인기도, 사용자의 위치와 대상 장소의 거리
2.3.5 TF-IDF, BM25
- TF (Term Frequency)
- 문서에 인덱스텀이 포함된 개수.
- 문서에 매칭된 텀의 개수가 많을수록 사용자가 원하는 문서일 가능성이 높다.
- TF가 높을수록 높은 점수를 준다.
- IDF (Inverse Document Frequency)
- 인덱스텀이 포함된 문서의 개수다. (포스팅 리스트의 크기)
- 매칭된 텀이 희소할수록, 특정 문서를 잘 대표할 것이다.
- IDF가 낮을수록 높은 점수를 준다.
- Field Lenght
- 문서의 길이다.
- 문서의 길이가 짧은 필드에 매칭된 텀일수록 사용자의 의도에 더 부합하는 문서일 것이다.
- 예를 들어 쿼리텀이 문서의 내용 필드보다는 길이가 짧은 제목 필드에 매칭될수록 높은 점수를 준다.
- Field Length가 낮을수록 높은 점수를 준다.
- BM25 계산식
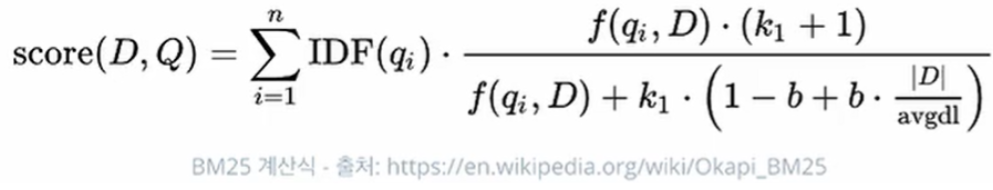
일본 주소검색 서비스 개발
3.1 기술 스택
- 검색 엔진: Lucene
- 검색 프레임워크: Elasticsearch. Solr
- 데이터베이스: PostgreSQL, MongoDB 등
- 대용량 처리: Hadoop + Spark + Scala, pandas 등
- 형태소 분석기
- 한국어: nori, …
- 일본어: kuromoji …
- API 서비스: spring boot 2 + kotlin
- 검색 인프라: ncc(docker + kubernetes)
3.2 데이터 파이프라인 구축
- 원본 데이터 준비
- 데이터 추출/변환/적재(ETL)
- 추출: 원본 데이터에서 필요한 데이터만 뽑아서 저장
- 변환: 추출된 데이터를 인덱스를 만들기에 적절한 형태로 가공
- 적재: 생성된 인덱스를 검색 엔진에 로딩
- 모든 작업에 사람의 개입을 최소화
- 데이터의 최신성 목표에 따른 구축
검색 품질 측정 및 개선
4.1 테스트 데이터와 정답셋
- 데이터가 많을수록 검색 품질이 향상된다.
- 양질의 테스트 데이터
- 경험에 기반한 쿼리 타입 추출
- 검색 로그
- 서비스되고 있는 검색과 비교(우리 서비스의 경우, 키프리스)
- 클릭 로그: 사용자가 어떤 쿼리를 날렸고, 그 쿼리에 따라서 우리가 제공한 데이터 중에 어떤 것을 선택했는지에 대한 로그
- 확보된 데이터는 주기적으로 생성되도록 자동화하는 것
- 지원되지 않는 쿼리 타입을 중심으로 개선점을 도출하는데 사용
- A/B 테스트, 회귀 테스트 등 검색 품질 측정에 활용
- 학습 데이터로 활용해서 검색 품질 개선을 자동화
4.2 품질 측정 기준 지표(KPI) 정의
- 검색 품질을 평가하기 위한 기준 지표를 만든다.
- 검색 품질을 개선하려면, 평가할 수 있어야 한다.
- 매일/매주/매달 KPI 지표를 뽑을 수 있는 파이프라인을 구축한다.
- KPI를 통해서 검색 품질 개선점을 도출한다.
- 품질 측정 기준 지표의 예
- 사용자 클릭 비율
- 검색어 삭제 및 재검색 비율
- 사용자가 상위랭크를 클릭한 비율 점수화
- 검색결과 없음 비율
- 클릭이 발생한 시점에 검색어의 길이
4.3 A/B 테스트 구축
- AS-IS 서비스를 A, TO-BE 서비스를 B로 한다.
- 출시 전 A/B 테스트
- 준비된 정답셋으로 A와 B를 직접 실행해서 비교한다.
- A보다 B의 점수가 낮으면, 출시하지 않는다.
- 출시 후 A/B 테스트
- 서비스의 일부만 부분배포할 수 있는 매커니즘이 필요하다
- 실서비스에 B를 부분배포한 후, 품질 측정 기준 지표로 비교한다.
4.4 검색 품질 개선(…ing)
- 출시 전 개선
- 키프리스 등의 서비스와 품질을 비교하면서, 부족한 부분을 보완
- 출시 후 개선
- 사용자 쿼리/클릭 로그를 기반으로 검색 품질이 자동 개선되도록 구축
- 랭킹 모델에 인기도 반영
배우고 느낀 점, 인사이트
- 검색 기본적인 요구사항
오타교정 - 쿼리텀은 인덱스텀 추출과 거의 유사한 기준으로 추출해야 한다
- 검색 품질 개선 방법
출처

정성과 진심을 담아 흔적을 기록하자💡