
문자열을 검색하려면?
문자열을 검색하는 상황에서 '패턴매칭'이 많이 사용됩니다.
String에서 찾고자 하는 특정 String을 패턴이라고 하며 이 패턴을 찾는 방법이 바로 패턴매칭입니다. 쉽게 문자열 검색이라고 생각합시다!
크게 브루트포스 알고리즘과 KMP 알고리즘을 사용합니다.
브루트 포스의 경우 말 그대로 고지식한 알고리즘으로 문자열의 맨 앞부터 맨 끝까지, 찾고자 하는 문자열과 하나 하나 비교하는 것입니다.
하지만, 브로트 포스는 최악의 경우 본문 문자열의 길이가 M이고 패턴의 길이가 N이라면 시간복잡도가 O(MN) 이 됩니다. 각 문자열의 길이가 길어진다면 분명 코딩테스트에서 시간초과가 날 것입니다.
그래서 우리는 좀 더 비교 횟수를 줄여 현명하게 패턴을 찾을 필요가 있습니다.
KMP 알고리즘은 그런 면에서 많이 이용되는 문자열 검색 알고리즘입니다.
KMP
KMP의 원리는 한 마디로 "불일치가 발생하기 직전까지 같았던 부분은 다시 비교하지 않고 패턴 매칭을 진행한다." 입니다.
이를 통해서 비교 횟수를 줄이고 검색의 효율을 높이는 것이 목적입니다.
KMP의 시간 복잡도는 최악의 경우에도 O(N+M) 를 보장합니다.
예제 문제를 보며 이해해봅시다.
https://www.acmicpc.net/problem/1786
S = "abc abcdab abcdabcdabde"
W = "abcdabd"
일때, i는 S에서 몇 번째 글자를 시작점으로 두고 W와 비교하는지 이며 j는 W의 몇 번째 글자를 비교하고 있는지 입니다.
(1) i=j=0
 처음 세 글자는 같다가 네 번째 글자(j=3)부터 다르게 됩니다. 여기서 브루트 포스 였다면 다음과 같이 i=1부터 다시 비교를 시작했을 것입니다.
처음 세 글자는 같다가 네 번째 글자(j=3)부터 다르게 됩니다. 여기서 브루트 포스 였다면 다음과 같이 i=1부터 다시 비교를 시작했을 것입니다. 하지만, KMP는 그렇게 비교하는 것은 멍청한 짓이라고 합니다. KMP에 따르면 i=1이 아닌 다음처럼 i=3 부터 비교해도 상관이 없다고 합니다.
하지만, KMP는 그렇게 비교하는 것은 멍청한 짓이라고 합니다. KMP에 따르면 i=1이 아닌 다음처럼 i=3 부터 비교해도 상관이 없다고 합니다. 
"왜?"
왜냐하면, W의 구조를 보면 처음 세 글자가 반복되는 글자가 하나도 없네요! 그런데 i=0일 때 S,W의 첫 세 글자가 일치했다는 것은 i=1, i=2일 때는 첫 글자부터 절대 일치할 수 없다는 것을 의미합니다. 일리가 있군요! 그럼 i=3 일때는 공백이므로 그 다음으로 넘어가보죠.
(2) i=4

이번에는 W의 첫 여섯 글자가 맞다가, j=6일 때 어긋납니다.
오! 그렇다면 방금 세 글자가 일치했을 때, 세 칸을 넘어갔으니 이번엔 여섯 칸을 건너뛰면 될까요?
하지만, KMP는 말합니다.
"아니 아니 그럼 안되지. 만약 S= 'abcdabcdabc'면 어떻할건데?? 그럼 i=0, j=6일 때 어긋나서 i=6으로 건너뛰면 찾을 수 없잖아..!"
왜 이번에는 안될까요? 그 이유는 W의 구조에 반복되는 문자열이 있기 때문입니다. W의 처음 여섯 글자 'abcdab'를 보면 아까와 달리 'ab'가 시작과 끝에 반복됩니다.
(3) i=8
KMP는 이번에는 섣불리 여섯 칸을 건너뛰는 것이 아니라 네 칸만 뛰어서 i=8로 가라네요. 그 이유는 W의 처음 여섯 글자에서 'ab'가 앞뒤로 반복되니 S의 네 칸을 건너뛰면 저 반복 구조에 의해 W의 첫 두 글자 'ab'는 이미 일치하는 것을 알 수 있기 때문이죠. 따라서, j=0~1인 구간을 건너뛰고 j=2일때부터 비교해도 됩니다.
(4) i=10
그러나 j=2가 되자마자 어긋났고 i를 증가시켜야 하는데 이번에 비교한 W의 첫 두 글자 'ab'에는 반복되는 글자가 없으므로 이번엔 i를 2칸 건너뛰어도 됩니다.
(5) i=11
그 다음, i=11이 되었고 이번 역시 j=6일 때 어긋나게 됩니다.
(6) i=15
아까와 같이 i=15, j=2인 지점부터 비교를 해봅시다.
이렇게 S에서 W를 찾았습니다. 여기서 보면, KMP가 말한대로 i=17로 6칸을 건너뛰었다면 W를 찾을 수 없었겠네요!
접두부, 접미부, 경계
우리는 접두부와 접미부, 경계의 의미를 먼저 알아야합니다.
 단, 접두부와 접미부는 전체 문자열이 될 수는 없습니다.
단, 접두부와 접미부는 전체 문자열이 될 수는 없습니다.
경계란 다음같이 '접두부'와 '접미부'가 같을 때, 그 접두부 혹인 접미부입니다. 이제 접두부, 접미부, 경계의 의미를 알았으니 알고리즘의 순서를 알아봅시다.
이제 접두부, 접미부, 경계의 의미를 알았으니 알고리즘의 순서를 알아봅시다.
KMP 알고리즘의 순서
(1) 본문이 되는 문자열이 있고, 찾으려는 패턴을 처음에 둡니다.
(2) 일부가 일치하지 않는다면, 불일치한 부분을 제외한 직적까지 일치하는 패턴에서 최대 길이의 경계를 찾습니다.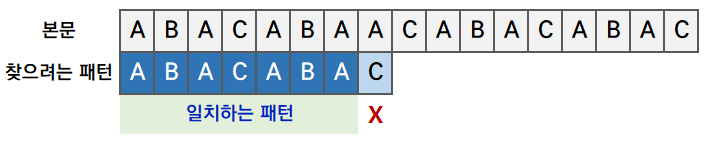

(3) 선택한 경계에서 접두부, 접미부를 파악하고 찾으려는 패턴을 접미부의 시작 문자열까지 이동시킵니다.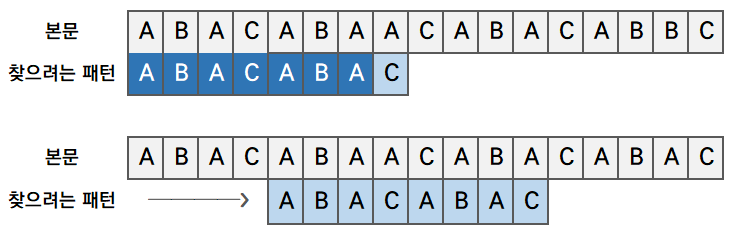
그리고 1번부터 과정을 다시 반복합니다.
※만약, 2번에서 경계를 찾지 못하거나, 모두 불일치할 경우에는 처음 불일치했던 부분까지 패턴을 이동시킵니다. 그리고 1번부터 반복합니다.
여기서 매번 움직일 때마다 경계를 찾으려면 접두부, 접미부를 반복적으로 분석해야 하며, 이는 KMP 알고리즘의 효율성을 떨어뜨립니다.
그래서 참고할 수 있는 이동 경로 테이블을 만들어야합니다.
이동경로 테이블
이동경로 테이블은 얼마나 이동시켜야하는지(건너뛰는지)를 알 수 있게 하는 테이블입니다.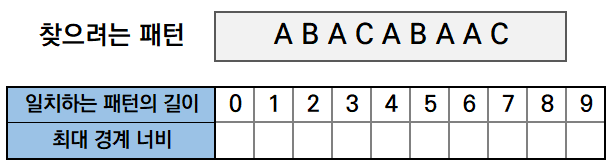
- 일치하는 패턴의 길이: 본문과 찾으려는 패턴을 맨 앞에서부터 비교해 어느 지점에서 불일치가 발생했다면, 그 직전까지 일치하는 패턴의 길이
- 최대 경계 너비: 본문과 패턴 간에 일치하는 부분에서 경계를 찾고, 그들 중 최대의 길이 값

테이블 만들기 예시
ABACABAAC를 가지고 테이블을 만들어 봅시다.
-
일치하는 패턴의 길이: 0
- 본문과 패턴이 처음부터 다르면, 패턴은 한 칸만 이동시켜야 하므로, 이동거리 공식에 의해 최대 경계 너비값을 -1로 설정합니다.
-
일치하는 패턴의 길이: 1
- A에서 경계를 찾을 수 없으므로 최대 경계 너비값은 0
-
일치하는 패턴의 길이: 2
- AB에서 경계를 찾을 수 없으므로 최대 경계 너비값 = 0
-
일치하는 패턴의 길이: 3
- ABA에서 경계는 A하나만 나오므로 최대 경계 너비값 = 1
-
일치하는 패턴의 길이: 4
- ABAC에서 경계를 찾을 수 없으므로 최대경계 너비값 = 0
-
일치하는 패턴의 길이: 5
- ABACA에서 경계는 A하나만 나오므로 최대 경계 너비값 = 1
-
일치하는 패턴의 길이: 6
- ABACAB에서 경계는 AB로 최대 경계 너비값 = 2
-
일치하는 패턴의 길이: 7
- ABACABA에서 최대 경계는 ABA로 너비값 = 3
-
일치하는 패턴의 길이: 8
- ABACABAA에서 A하나만 나오며 최대 경계 너비값 = 1
-
일치하는 패턴의 길이: 9
- 찾으려는 패턴 9글자가 일치하므로 찾기 완료!
- 하지만, 그 뒤에도 찾으려는 패턴과 일치하는 경우가 더 있을 수 있으므로 마찬가지로 최대 경계 너비를 계산해 채움.
- ABACABAAC에서 경계를 찾을 수 없으므로 최대 경계 너비값 = 0
이제 테이블을 이용해 패턴 매칭을 진행해 봅시다.
- 일치하는 패턴의 길이가 7이므로, 표에서 최대 경계 너비값은 3
이동 거리는 일치하는 패턴길이 - 최대 경계너비 = 7-3 = 4입니다.

- 4칸 이동 후에도 일치하는 부분길이가 7이므로 4칸 이동

- 이제 모두 일치하므로 패턴매칭을 완료합니다.
이제 다시 1786번 찾기 문제로 넘어와 코드를 작성해 봅시다.
우선 우리는 이동경로 테이블을 만들어야 합니다.
t = input() # 전체 문자열
p = input() # 패턴
move = [0] * len(p) #이동경로 테이블로 초기 값 0으로 초기화
result = [] # 어디서 패턴매칭이 이뤄졌는 지
count = 0 # 몇 번 나오는 지
j = 0
#1글자일때는 어처피 아무것도 안 겹칠때와 같으므로 1부터 비교 시작
for i in range(1, len(p)):
#현재 글자가 불일치하면 move 값을 따라감
while j > 0 and p[i] != p[j]:
j = move[j-1]
#현재 글자가 일치하면
if p[i] == p[j]:
j += 1 # 경계의 너비
move[i] = j
위에서 구한 이동경로 테이블을 가지고 패턴매칭(문자열 검색)을 시도합니다.
j = 0
# 이동경로 테이블 구할때와 비슷하지만 t에서 검색을 함
for i in range(len(t)):
while j>0 and t[i] != p[j]:
j = move[j-1]
if t[i] == p[j]:
if j == (len(p)-1): # 문자가 일치하고 찾는 패턴의 마지막이면 이게 최대임
# 문제에서 1부터 시작이므로 i-len(p)+1에 1 더해줌
result.append(i-len(p)+2)
count += 1
j = move[j]
else:
j += 1
#문제에서 원하는 대로 출력
print(count)
for i in result:
print(i, end=' ')[백준 추천문제]
1786(찾기)
9253(스페셜 저지)
1305(광고)
4354(문자열 제곱)
2401(최대 문자열 붙여넣기)
11585(속타는 저녁 메뉴)
1893(시저 암호)
7575(바이러스)
[참고]
https://blog.naver.com/PostView.naver?blogId=kks227&logNo=220917078260&parentCategoryNo=&categoryNo=299&viewDate=&isShowPopularPosts=false&from=postList
https://chanhuiseok.github.io/posts/algo-14/
